Implements of masked seq2seq pre-training for language generation.
This commit is contained in:
parent
24be3f82ad
commit
065f32e0e5
|
|
@ -0,0 +1,592 @@
|
|||

|
||||
|
||||
<!-- TOC -->
|
||||
|
||||
- [MASS: Masked Sequence to Sequence Pre-training for Language Generation Description](#googlenet-description)
|
||||
- [Model architecture](#model-architecture)
|
||||
- [Dataset](#dataset)
|
||||
- [Features](#features)
|
||||
- [Script description](#script-description)
|
||||
- [Data Preparation](#Data-Preparation)
|
||||
- [Tokenization](#Tokenization)
|
||||
- [Byte Pair Encoding](#Byte-Pair-Encoding)
|
||||
- [Build Vocabulary](#Build-Vocabulary)
|
||||
- [Generate Dataset](#Generate-Dataset)
|
||||
- [News Crawl Corpus](#News-Crawl-Corpus)
|
||||
- [Gigaword Corpus](#Gigaword-Corpus)
|
||||
- [Cornell Movie Dialog Corpus](#Cornell-Movie-Dialog-Corpus)
|
||||
- [Configuration](#Configuration)
|
||||
- [Training & Evaluation process](#Training-&-Evaluation-process)
|
||||
- [Weights average](#Weights-average)
|
||||
- [Learning rate scheduler](#Learning-rate-scheduler)
|
||||
- [Model description](#model-description)
|
||||
- [Performance](#performance)
|
||||
- [Results](#results)
|
||||
- [Training Performance](#training-performance)
|
||||
- [Inference Performance](#inference-performance)
|
||||
- [Environment Requirements](#environment-requirements)
|
||||
- [Platform](#Platform)
|
||||
- [Requirements](#Requirements)
|
||||
- [Get started](#get-started)
|
||||
- [Pre-training](#Pre-training)
|
||||
- [Fine-tuning](#Fine-tuning)
|
||||
- [Inference](#Inference)
|
||||
- [Description of random situation](#description-of-random-situation)
|
||||
- [others](#others)
|
||||
- [ModelZoo Homepage](#modelzoo-homepage)
|
||||
|
||||
<!-- /TOC -->
|
||||
|
||||
|
||||
# MASS: Masked Sequence to Sequence Pre-training for Language Generation Description
|
||||
|
||||
[MASS: Masked Sequence to Sequence Pre-training for Language Generation](https://www.microsoft.com/en-us/research/uploads/prod/2019/06/MASS-paper-updated-002.pdf) was released by MicroSoft in June 2019.
|
||||
|
||||
BERT(Devlin et al., 2018) have achieved SOTA in natural language understanding area by pre-training the encoder part of Transformer(Vaswani et al., 2017) with masked rich-resource text. Likewise, GPT(Raddford et al., 2018) pre-trains the decoder part of Transformer with masked(encoder inputs are masked) rich-resource text. Both of them build a robust language model by pre-training with masked rich-resource text.
|
||||
|
||||
Inspired by BERT, GPT and other language models, MicroSoft addressed [MASS: Masked Sequence to Sequence Pre-training for Language Generation](https://www.microsoft.com/en-us/research/uploads/prod/2019/06/MASS-paper-updated-002.pdf) which combines BERT's and GPT's idea. MASS has an important parameter k, which controls the masked fragment length. BERT and GPT are specicl case when k equals to 1 and sentence length.
|
||||
|
||||
[Introducing MASS – A pre-training method that outperforms BERT and GPT in sequence to sequence language generation tasks](https://www.microsoft.com/en-us/research/blog/introducing-mass-a-pre-training-method-that-outperforms-bert-and-gpt-in-sequence-to-sequence-language-generation-tasks/)
|
||||
|
||||
[Paper](https://www.microsoft.com/en-us/research/uploads/prod/2019/06/MASS-paper-updated-002.pdf): Song, Kaitao, Xu Tan, Tao Qin, Jianfeng Lu and Tie-Yan Liu. “MASS: Masked Sequence to Sequence Pre-training for Language Generation.” ICML (2019).
|
||||
|
||||
|
||||
# Model architecture
|
||||
|
||||
The overall network architecture of MASS is shown below, which is Transformer(Vaswani et al., 2017):
|
||||
|
||||
MASS is consisted of 6-layer encoder and 6-layer decoder with 1024 embedding/hidden size, and 4096 intermediate size between feed forward network which has two full connection layers.
|
||||
|
||||
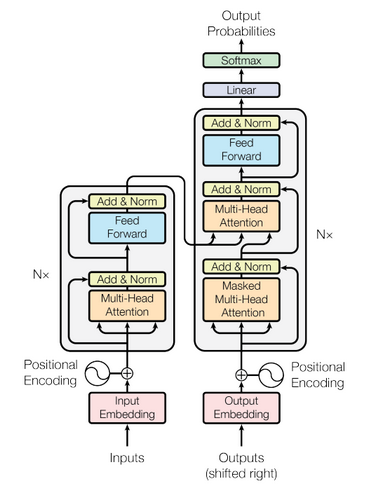
|
||||
|
||||
|
||||
# Dataset
|
||||
|
||||
Dataset used:
|
||||
- monolingual English data from News Crawl dataset(WMT 2019) for pre-training.
|
||||
- Gigaword Corpus(Graff et al., 2003) for Text Summarization.
|
||||
- Cornell movie dialog corpus(DanescuNiculescu-Mizil & Lee, 2011).
|
||||
|
||||
Details about those dataset could be found in [MASS: Masked Sequence to Sequence Pre-training for Language Generation](https://www.microsoft.com/en-us/research/uploads/prod/2019/06/MASS-paper-updated-002.pdf).
|
||||
|
||||
|
||||
# Features
|
||||
|
||||
Mass is designed to jointly pre train encoder and decoder to complete the task of language generation.
|
||||
First of all, through a sequence to sequence framework, mass only predicts the blocked token, which forces the encoder to understand the meaning of the unshielded token, and encourages the decoder to extract useful information from the encoder.
|
||||
Secondly, by predicting the continuous token of the decoder, the decoder can build better language modeling ability than only predicting discrete token.
|
||||
Third, by further shielding the input token of the decoder which is not shielded in the encoder, the decoder is encouraged to extract more useful information from the encoder side, rather than using the rich information in the previous token.
|
||||
|
||||
|
||||
# Script description
|
||||
|
||||
MASS script and code structure are as follow:
|
||||
|
||||
```text
|
||||
├── mass
|
||||
├── README.md // Introduction of MASS model.
|
||||
├── config
|
||||
│ ├──config.py // Configuration instance definition.
|
||||
│ ├──config.json // Configuration file.
|
||||
├── src
|
||||
│ ├──dataset
|
||||
│ ├──bi_data_loader.py // Dataset loader for fine-tune or inferring.
|
||||
│ ├──mono_data_loader.py // Dataset loader for pre-training.
|
||||
│ ├──language_model
|
||||
│ ├──noise_channel_language_model.p // Noisy channel language model for dataset generation.
|
||||
│ ├──mass_language_model.py // MASS language model according to MASS paper.
|
||||
│ ├──loose_masked_language_model.py // MASS language model according to MASS released code.
|
||||
│ ├──masked_language_model.py // Masked language model according to MASS paper.
|
||||
│ ├──transformer
|
||||
│ ├──create_attn_mask.py // Generate mask matrix to remove padding positions.
|
||||
│ ├──transformer.py // Transformer model architecture.
|
||||
│ ├──encoder.py // Transformer encoder component.
|
||||
│ ├──decoder.py // Transformer decoder component.
|
||||
│ ├──self_attention.py // Self-Attention block component.
|
||||
│ ├──multi_head_attention.py // Multi-Head Self-Attention component.
|
||||
│ ├──embedding.py // Embedding component.
|
||||
│ ├──positional_embedding.py // Positional embedding component.
|
||||
│ ├──feed_forward_network.py // Feed forward network.
|
||||
│ ├──residual_conn.py // Residual block.
|
||||
│ ├──beam_search.py // Beam search decoder for inferring.
|
||||
│ ├──transformer_for_infer.py // Use Transformer to infer.
|
||||
│ ├──transformer_for_train.py // Use Transformer to train.
|
||||
│ ├──utils
|
||||
│ ├──byte_pair_encoding.py // Apply BPE with subword-nmt.
|
||||
│ ├──dictionary.py // Dictionary.
|
||||
│ ├──loss_moniter.py // Callback of monitering loss during training step.
|
||||
│ ├──lr_scheduler.py // Learning rate scheduler.
|
||||
│ ├──ppl_score.py // Perplexity score based on N-gram.
|
||||
│ ├──rouge_score.py // Calculate ROUGE score.
|
||||
│ ├──load_weights.py // Load weights from a checkpoint or NPZ file.
|
||||
│ ├──initializer.py // Parameters initializer.
|
||||
├── vocab
|
||||
│ ├──all.bpe.codes // BPE codes table(this file should be generated by user).
|
||||
│ ├──all_en.dict.bin // Learned vocabulary file(this file should be generated by user).
|
||||
├── scripts
|
||||
│ ├──run.sh // Train & evaluate model script.
|
||||
│ ├──learn_subword.sh // Learn BPE codes.
|
||||
│ ├──stop_training.sh // Stop training.
|
||||
├── requirements.txt // Requirements of third party package.
|
||||
├── train.py // Train API entry.
|
||||
├── eval.py // Infer API entry.
|
||||
├── tokenize_corpus.py // Corpus tokenization.
|
||||
├── apply_bpe_encoding.py // Applying bpe encoding.
|
||||
├── weights_average.py // Average multi model checkpoints to NPZ format.
|
||||
├── news_crawl.py // Create News Crawl dataset for pre-training.
|
||||
├── gigaword.py // Create Gigaword Corpus.
|
||||
├── cornell_dialog.py // Create Cornell Movie Dialog dataset for conversation response.
|
||||
|
||||
```
|
||||
|
||||
|
||||
## Data Preparation
|
||||
|
||||
The data preparation of a natural language processing task contains data cleaning, tokenization, encoding and vocabulary generation steps.
|
||||
|
||||
In our experiments, using [Byte Pair Encoding(BPE)](https://arxiv.org/abs/1508.07909) could reduce size of vocabulary, and relieve the OOV influence effectively.
|
||||
|
||||
Vocabulary could be created using `src/utils/dictionary.py` with text dictionary which is learnt from BPE.
|
||||
For more detail about BPE, please refer to [Subword-nmt lib](https://www.cnpython.com/pypi/subword-nmt) or [paper](https://arxiv.org/abs/1508.07909).
|
||||
|
||||
In our experiments, vocabulary was learned based on 1.9M sentences from News Crawl Dataset, size of vocabulary is 45755.
|
||||
|
||||
Here, we have a brief introduction of data preparation scripts.
|
||||
|
||||
|
||||
### Tokenization
|
||||
Using `tokenize_corpus.py` could tokenize corpus whose text files are in format of `.txt`.
|
||||
|
||||
Major parameters in `tokenize_corpus.py`:
|
||||
|
||||
```bash
|
||||
--corpus_folder: Corpus folder path, if multi-folders are provided, use ',' split folders.
|
||||
--output_folder: Output folder path.
|
||||
--tokenizer: Tokenizer to be used, nltk or jieba, if nltk is not installed fully, use jieba instead.
|
||||
--pool_size: Processes pool size.
|
||||
```
|
||||
|
||||
Sample code:
|
||||
```bash
|
||||
python tokenize_corpus.py --corpus_folder /{path}/corpus --output_folder /{path}/tokenized_corpus --tokenizer {nltk|jieba} --pool_size 16
|
||||
```
|
||||
|
||||
|
||||
### Byte Pair Encoding
|
||||
After tokenization, BPE is applied to tokenized corpus with provided `all.bpe.codes`.
|
||||
|
||||
Apply BPE script can be found in `apply_bpe_encoding.py`.
|
||||
|
||||
Major parameters in `apply_bpe_encoding.py`:
|
||||
|
||||
```bash
|
||||
--codes: BPE codes file.
|
||||
--src_folder: Corpus folders.
|
||||
--output_folder: Output files folder.
|
||||
--prefix: Prefix of text file in `src_folder`.
|
||||
--vocab_path: Generated vocabulary output path.
|
||||
--threshold: Filter out words that frequency is lower than threshold.
|
||||
--processes: Size of process pool (to accelerate). Default: 2.
|
||||
```
|
||||
|
||||
Sample code:
|
||||
```bash
|
||||
python tokenize_corpus.py --codes /{path}/all.bpe.codes \
|
||||
--src_folder /{path}/tokenized_corpus \
|
||||
--output_folder /{path}/tokenized_corpus/bpe \
|
||||
--prefix tokenized \
|
||||
--vocab_path /{path}/vocab_en.dict.bin
|
||||
--processes 32
|
||||
```
|
||||
|
||||
|
||||
### Build Vocabulary
|
||||
Support that you want to create a new vocabulary, there are two options:
|
||||
1. Learn BPE codes from scratch, and create vocabulary with multi vocabulary files from `subword-nmt`.
|
||||
2. Create from an existing vocabulary file which lines in the format of `word frequency`.
|
||||
3. *Optional*, Create a small vocabulary based on `vocab/all_en.dict.bin` with method of `shink` from `src/utils/dictionary.py`.
|
||||
4. Persistent vocabulary to `vocab` folder with method `persistence()`.
|
||||
|
||||
Major interface of `src/utils/dictionary.py` are as follow:
|
||||
|
||||
1. `shrink(self, threshold=50)`: Shrink the size of vocabulary by filter out words frequency is lower than threshold. It returns a new vocabulary.
|
||||
2. `load_from_text(cls, filepaths: List[str])`: Load existed text vocabulary which lines in the format of `word frequency`.
|
||||
3. `load_from_persisted_dict(cls, filepath)`: Load from a persisted binary vocabulary which was saved by calling `persistence()` method.
|
||||
4. `persistence(self, path)`: Save vocabulary object to binary file.
|
||||
|
||||
Sample code:
|
||||
```python
|
||||
from src.utils import Dictionary
|
||||
|
||||
vocabulary = Dictionary.load_from_persisted_dict("vocab/all_en.dict.bin")
|
||||
tokens = [1, 2, 3, 4, 5]
|
||||
# Convert ids to symbols.
|
||||
print([vocabulary[t] for t in tokens])
|
||||
|
||||
sentence = ["Hello", "world"]
|
||||
# Convert symbols to ids.
|
||||
print([vocabulary.index[s] for s in sentence])
|
||||
```
|
||||
|
||||
For more detail, please refer to the source file.
|
||||
|
||||
|
||||
### Generate Dataset
|
||||
As mentioned above, three corpus are used in MASS mode, dataset generation scripts for them are provided.
|
||||
|
||||
#### News Crawl Corpus
|
||||
Script can be found in `news_crawl.py`.
|
||||
|
||||
Major parameters in `news_crawl.py`:
|
||||
|
||||
```bash
|
||||
Note that please provide `--existed_vocab` or `--dict_folder` at least one.
|
||||
A new vocabulary would be created in `output_folder` when pass `--dict_folder`.
|
||||
|
||||
--src_folder: Corpus folders.
|
||||
--existed_vocab: Optional, persisted vocabulary file.
|
||||
--mask_ratio: Ratio of mask.
|
||||
--output_folder: Output dataset files folder path.
|
||||
--max_len: Maximum sentence length. If a sentence longer than `max_len`, then drop it.
|
||||
--suffix: Optional, suffix of generated dataset files.
|
||||
--processes: Optional, size of process pool (to accelerate). Default: 2.
|
||||
```
|
||||
|
||||
Sample code:
|
||||
|
||||
```bash
|
||||
python news_crawl.py --src_folder /{path}/news_crawl \
|
||||
--existed_vocab /{path}/mass/vocab/all_en.dict.bin \
|
||||
--mask_ratio 0.5 \
|
||||
--output_folder /{path}/news_crawl_dataset \
|
||||
--max_len 32 \
|
||||
--processes 32
|
||||
```
|
||||
|
||||
|
||||
#### Gigaword Corpus
|
||||
Script can be found in `gigaword.py`.
|
||||
|
||||
Major parameters in `gigaword.py`:
|
||||
|
||||
```bash
|
||||
--train_src: Train source file path.
|
||||
--train_ref: Train reference file path.
|
||||
--test_src: Test source file path.
|
||||
--test_ref: Test reference file path.
|
||||
--existed_vocab: Persisted vocabulary file.
|
||||
--output_folder: Output dataset files folder path.
|
||||
--noise_prob: Optional, add noise prob. Default: 0.
|
||||
--max_len: Optional, maximum sentence length. If a sentence longer than `max_len`, then drop it. Default: 64.
|
||||
--format: Optional, dataset format, "mindrecord" or "tfrecord". Default: "tfrecord".
|
||||
```
|
||||
|
||||
Sample code:
|
||||
|
||||
```bash
|
||||
python gigaword.py --train_src /{path}/gigaword/train_src.txt \
|
||||
--train_ref /{path}/gigaword/train_ref.txt \
|
||||
--test_src /{path}/gigaword/test_src.txt \
|
||||
--test_ref /{path}/gigaword/test_ref.txt \
|
||||
--existed_vocab /{path}/mass/vocab/all_en.dict.bin \
|
||||
--noise_prob 0.1 \
|
||||
--output_folder /{path}/gigaword_dataset \
|
||||
--max_len 64
|
||||
```
|
||||
|
||||
|
||||
#### Cornell Movie Dialog Corpus
|
||||
Script can be found in `cornell_dialog.py`.
|
||||
|
||||
Major parameters in `cornell_dialog.py`:
|
||||
|
||||
```bash
|
||||
--src_folder: Corpus folders.
|
||||
--existed_vocab: Persisted vocabulary file.
|
||||
--train_prefix: Train source and target file prefix. Default: train.
|
||||
--test_prefix: Test source and target file prefix. Default: test.
|
||||
--output_folder: Output dataset files folder path.
|
||||
--max_len: Maximum sentence length. If a sentence longer than `max_len`, then drop it.
|
||||
--valid_prefix: Optional, Valid source and target file prefix. Default: valid.
|
||||
```
|
||||
|
||||
Sample code:
|
||||
|
||||
```bash
|
||||
python cornell_dialog.py --src_folder /{path}/cornell_dialog \
|
||||
--existed_vocab /{path}/mass/vocab/all_en.dict.bin \
|
||||
--train_prefix train \
|
||||
--test_prefix test \
|
||||
--noise_prob 0.1 \
|
||||
--output_folder /{path}/cornell_dialog_dataset \
|
||||
--max_len 64
|
||||
```
|
||||
|
||||
|
||||
## Configuration
|
||||
Json file under the path `config/` is the template configuration file.
|
||||
Almost all of the options and arguments needed could be assigned conveniently, including the training platform, configurations of dataset and model, arguments of optimizer etc. Optional features such as loss scale and checkpoint are also available by setting the options correspondingly.
|
||||
For more detailed information about the attributes, refer to the file `config/config.py`.
|
||||
|
||||
## Training & Evaluation process
|
||||
For training a model, the shell script `run.sh` is all you need. In this scripts, the environment variable is set and the training script `train.py` under `mass` is executed.
|
||||
You may start a task training with single device or multiple devices by assigning the options and run the command in bash:
|
||||
```bash
|
||||
sh run.sh [--options]
|
||||
```
|
||||
|
||||
The usage is shown as bellow:
|
||||
```text
|
||||
Usage: run.sh [-h, --help] [-t, --task <CHAR>] [-n, --device_num <N>]
|
||||
[-i, --device_id <N>] [-j, --hccl_json <FILE>]
|
||||
[-c, --config <FILE>] [-o, --output <FILE>]
|
||||
[-v, --vocab <FILE>]
|
||||
|
||||
options:
|
||||
-h, --help show usage
|
||||
-t, --task select task: CHAR, 't' for train and 'i' for inference".
|
||||
-n, --device_num device number used for training: N, default is 1.
|
||||
-i, --device_id device id used for training with single device: N, 0<=N<=7, default is 0.
|
||||
-j, --hccl_json rank table file used for training with multiple devices: FILE.
|
||||
-c, --config configuration file as shown in the path 'mass/config': FILE.
|
||||
-o, --output assign output file of inference: FILE.
|
||||
-v, --vocab set the vocabulary"
|
||||
```
|
||||
Notes: Be sure to assign the hccl_json file while running a distributed-training.
|
||||
|
||||
The command followed shows a example for training with 2 devices.
|
||||
```bash
|
||||
sh run.sh --task t --device_num 2 --hccl_json /{path}/rank_table.json --config /{path}/config.json
|
||||
```
|
||||
ps. Discontinuous device id is not supported in `run.sh` at present, device id in `rank_table.json` must start from 0.
|
||||
|
||||
|
||||
If use a single chip, it would be like this:
|
||||
```bash
|
||||
sh run.sh --task t --device_num 1 --device_id 0 --config /{path}/config.json
|
||||
```
|
||||
|
||||
|
||||
## Weights average
|
||||
|
||||
```python
|
||||
python weights_average.py --input_files your_checkpoint_list --output_file model.npz
|
||||
```
|
||||
|
||||
The input_files is a list of you checkpoints file. To use model.npz as the weights, add its path in config.json at "existed_ckpt".
|
||||
```json
|
||||
{
|
||||
...
|
||||
"checkpoint_options": {
|
||||
"existed_ckpt": "/xxx/xxx/model.npz",
|
||||
"save_ckpt_steps": 1000,
|
||||
...
|
||||
},
|
||||
...
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
## Learning rate scheduler
|
||||
|
||||
Two learning rate scheduler are provided in our model:
|
||||
|
||||
1. [Polynomial decay scheduler](https://towardsdatascience.com/learning-rate-schedules-and-adaptive-learning-rate-methods-for-deep-learning-2c8f433990d1).
|
||||
2. [Inverse square root scheduler](https://ece.uwaterloo.ca/~dwharder/aads/Algorithms/Inverse_square_root/).
|
||||
|
||||
LR scheduler could be config in `config/config.json`.
|
||||
|
||||
For Polynomial decay scheduler, config could be like:
|
||||
```json
|
||||
{
|
||||
...
|
||||
"learn_rate_config": {
|
||||
"optimizer": "adam",
|
||||
"lr": 1e-4,
|
||||
"lr_scheduler": "poly",
|
||||
"poly_lr_scheduler_power": 0.5,
|
||||
"decay_steps": 10000,
|
||||
"warmup_steps": 2000,
|
||||
"min_lr": 1e-6
|
||||
},
|
||||
...
|
||||
}
|
||||
```
|
||||
|
||||
For Inverse square root scheduler, config could be like:
|
||||
```json
|
||||
{
|
||||
...
|
||||
"learn_rate_config": {
|
||||
"optimizer": "adam",
|
||||
"lr": 1e-4,
|
||||
"lr_scheduler": "isr",
|
||||
"decay_start_step": 12000,
|
||||
"warmup_steps": 2000,
|
||||
"min_lr": 1e-6
|
||||
},
|
||||
...
|
||||
}
|
||||
```
|
||||
|
||||
More detail about LR scheduler could be found in `src/utils/lr_scheduler.py`.
|
||||
|
||||
|
||||
# Model description
|
||||
|
||||
The MASS network is implemented by Transformer, which has multi-encoder layers and multi-decoder layers.
|
||||
For pre-training, we use the Adam optimizer and loss-scale to get the pre-trained model.
|
||||
During fine-turning, we fine-tune this pre-trained model with different dataset according to different tasks.
|
||||
During testing, we use the fine-turned model to predict the result, and adopt a beam search algorithm to
|
||||
get the most possible prediction results.
|
||||
|
||||
|
||||

|
||||
|
||||
|
||||
## Performance
|
||||
|
||||
### Results
|
||||
|
||||
#### Fine-Tuning on Text Summarization
|
||||
The comparisons between MASS and two other pre-training methods in terms of ROUGE score on the text summarization task
|
||||
with 3.8M training data are as follows:
|
||||
|
||||
| Method | RG-1(F) | RG-2(F) | RG-L(F) |
|
||||
|:---------------|:--------------|:-------------|:-------------|
|
||||
| MASS | Ongoing | Ongoing | Ongoing |
|
||||
|
||||
#### Fine-Tuning on Conversational ResponseGeneration
|
||||
The comparisons between MASS and other baseline methods in terms of PPL on Cornell Movie Dialog corpus are as follows:
|
||||
|
||||
| Method | Data = 10K | Data = 110K |
|
||||
|--------------------|------------------|-----------------|
|
||||
| MASS | Ongoing | Ongoing |
|
||||
|
||||
#### Training Performance
|
||||
|
||||
| Parameters | Masked Sequence to Sequence Pre-training for Language Generation |
|
||||
|:---------------------------|:--------------------------------------------------------------------------|
|
||||
| Model Version | v1 |
|
||||
| Resource | Ascend 910, cpu 2.60GHz, 56cores;memory, 314G |
|
||||
| uploaded Date | 05/24/2020 |
|
||||
| MindSpore Version | 0.2.0 |
|
||||
| Dataset | News Crawl 2007-2017 English monolingual corpus, Gigaword corpus, Cornell Movie Dialog corpus |
|
||||
| Training Parameters | Epoch=50, steps=XXX, batch_size=192, lr=1e-4 |
|
||||
| Optimizer | Adam |
|
||||
| Loss Function | Label smoothed cross-entropy criterion |
|
||||
| outputs | Sentence and probability |
|
||||
| Loss | Lower than 2 |
|
||||
| Accuracy | For conversation response, ppl=23.52, for text summarization, RG-1=29.79. |
|
||||
| Speed | 611.45 sentences/s |
|
||||
| Total time | --/-- |
|
||||
| Params (M) | 44.6M |
|
||||
| Checkpoint for Fine tuning | ---Mb, --, [A link]() |
|
||||
| Model for inference | ---Mb, --, [A link]() |
|
||||
| Scripts | [A link]() |
|
||||
|
||||
|
||||
#### Inference Performance
|
||||
|
||||
| Parameters | Masked Sequence to Sequence Pre-training for Language Generation |
|
||||
|:---------------------------|:-----------------------------------------------------------|
|
||||
| Model Version | V1 |
|
||||
| Resource | Huawei 910 |
|
||||
| uploaded Date | 05/24/2020 |
|
||||
| MindSpore Version | 0.2.0 |
|
||||
| Dataset | Gigaword corpus, Cornell Movie Dialog corpus |
|
||||
| batch_size | --- |
|
||||
| outputs | Sentence and probability |
|
||||
| Accuracy | ppl=23.52 for conversation response, RG-1=29.79 for text summarization. |
|
||||
| Speed | ---- sentences/s |
|
||||
| Total time | --/-- |
|
||||
| Model for inference | ---Mb, --, [A link]() |
|
||||
|
||||
|
||||
# Environment Requirements
|
||||
|
||||
## Platform
|
||||
|
||||
- Hardware(Ascend)
|
||||
- Prepare hardware environment with Ascend processor. If you want to try Ascend, please send the [application form](https://obs-9be7.obs.cn-east-2.myhuaweicloud.com/file/other/Ascend%20Model%20Zoo%E4%BD%93%E9%AA%8C%E8%B5%84%E6%BA%90%E7%94%B3%E8%AF%B7%E8%A1%A8.docx) to ascend@huawei.com. Once approved, you could get the resources for trial.
|
||||
- Framework
|
||||
- [MindSpore](http://10.90.67.50/mindspore/archive/20200506/OpenSource/me_vm_x86/)
|
||||
- For more information, please check the resources below:
|
||||
- [MindSpore tutorials](https://www.mindspore.cn/tutorial/zh-CN/master/index.html)
|
||||
- [MindSpore API](https://www.mindspore.cn/api/zh-CN/master/index.html)
|
||||
|
||||
## Requirements
|
||||
|
||||
```txt
|
||||
nltk
|
||||
numpy
|
||||
subword-nmt
|
||||
rouge
|
||||
```
|
||||
|
||||
https://www.mindspore.cn/tutorial/zh-CN/master/advanced_use/network_migration.html
|
||||
|
||||
|
||||
# Get started
|
||||
MASS pre-trains a sequence to sequence model by predicting the masked fragments in an input sequence. After this, downstream tasks including text summarization and conversation response are candidated for fine-tuning the model and for inference.
|
||||
Here we provide a practice example to demonstrate the basic usage of MASS for pre-training, fine-tuning a model, and the inference process. The overall process is as follows:
|
||||
1. Download and process the dataset.
|
||||
2. Modify the `config.json` to config the network.
|
||||
3. Run a task for pre-training and fine-tuning.
|
||||
4. Perform inference and validation.
|
||||
|
||||
## Pre-training
|
||||
For pre-training a model, config the options in `config.json` firstly:
|
||||
- Assign the `pre_train_dataset` under `dataset_config` node to the dataset path.
|
||||
- Choose the optimizer('momentum/adam/lamb' is available).
|
||||
- Assign the 'ckpt_prefix' and 'ckpt_path' under `checkpoint_path` to save the model files.
|
||||
- Set other arguments including dataset configurations and network configurations.
|
||||
- If you have a trained model already, assign the `existed_ckpt` to the checkpoint file.
|
||||
|
||||
Run the shell script `run.sh` as followed:
|
||||
|
||||
```bash
|
||||
sh run.sh -t t -n 1 -i 1 -c /mass/config/config.json
|
||||
```
|
||||
Get the log and output files under the path `./run_mass_*/`, and the model file under the path assigned in the `config/config.json` file.
|
||||
|
||||
## Fine-tuning
|
||||
For fine-tuning a model, config the options in `config.json` firstly:
|
||||
- Assign the `fine_tune_dataset` under `dataset_config` node to the dataset path.
|
||||
- Assign the `existed_ckpt` under `checkpoint_path` node to the existed model file generated by pre-training.
|
||||
- Choose the optimizer('momentum/adam/lamb' is available).
|
||||
- Assign the `ckpt_prefix` and `ckpt_path` under `checkpoint_path` node to save the model files.
|
||||
- Set other arguments including dataset configurations and network configurations.
|
||||
|
||||
Run the shell script `run.sh` as followed:
|
||||
```bash
|
||||
sh run.sh -t t -n 1 -i 1 -c config/config.json
|
||||
```
|
||||
Get the log and output files under the path `./run_mass_*/`, and the model file under the path assigned in the `config/config.json` file.
|
||||
|
||||
## Inference
|
||||
If you need to use the trained model to perform inference on multiple hardware platforms, such as GPU, Ascend 910 or Ascend 310, you can refer to this [Link](https://www.mindspore.cn/tutorial/zh-CN/master/advanced_use/network_migration.html).
|
||||
For inference, config the options in `config.json` firstly:
|
||||
- Assign the `test_dataset` under `dataset_config` node to the dataset path.
|
||||
- Assign the `existed_ckpt` under `checkpoint_path` node to the model file produced by fine-tuning.
|
||||
- Choose the optimizer('momentum/adam/lamb' is available).
|
||||
- Assign the `ckpt_prefix` and `ckpt_path` under `checkpoint_path` node to save the model files.
|
||||
- Set other arguments including dataset configurations and network configurations.
|
||||
|
||||
Run the shell script `run.sh` as followed:
|
||||
|
||||
```bash
|
||||
sh run.sh -t i -n 1 -i 1 -c config/config.json -o {outputfile}
|
||||
```
|
||||
|
||||
# Description of random situation
|
||||
|
||||
MASS model contains dropout operations, if you want to disable dropout, please set related dropout_rate to 0 in `config/config.json`.
|
||||
|
||||
|
||||
# others
|
||||
The model has been validated on Ascend environment, not validated on CPU and GPU.
|
||||
|
||||
|
||||
# ModelZoo Homepage
|
||||
[Link](https://gitee.com/mindspore/mindspore/tree/master/mindspore/model_zoo)
|
||||
|
|
@ -0,0 +1,84 @@
|
|||
# Copyright 2020 Huawei Technologies Co., Ltd
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
# ============================================================================
|
||||
"""Apply bpe script."""
|
||||
import os
|
||||
import argparse
|
||||
from multiprocessing import Pool, cpu_count
|
||||
|
||||
from src.utils import Dictionary
|
||||
from src.utils import bpe_encode
|
||||
|
||||
parser = argparse.ArgumentParser(description='Apply BPE.')
|
||||
parser.add_argument("--codes", type=str, default="", required=True,
|
||||
help="bpe codes path.")
|
||||
parser.add_argument("--src_folder", type=str, default="", required=True,
|
||||
help="raw corpus folder.")
|
||||
parser.add_argument("--output_folder", type=str, default="", required=True,
|
||||
help="encoded corpus output path.")
|
||||
parser.add_argument("--prefix", type=str, default="", required=False,
|
||||
help="Prefix of text file.")
|
||||
parser.add_argument("--vocab_path", type=str, default="", required=True,
|
||||
help="Generated vocabulary output path.")
|
||||
parser.add_argument("--threshold", type=int, default=None, required=False,
|
||||
help="Filter out words that frequency is lower than threshold.")
|
||||
parser.add_argument("--processes", type=int, default=2, required=False,
|
||||
help="Number of processes to use.")
|
||||
|
||||
if __name__ == '__main__':
|
||||
args, _ = parser.parse_known_args()
|
||||
|
||||
if not (args.codes and args.src_folder and args.output_folder):
|
||||
raise ValueError("Please enter required params.")
|
||||
|
||||
source_folder = args.src_folder
|
||||
output_folder = args.output_folder
|
||||
codes = args.codes
|
||||
|
||||
if not os.path.exists(codes):
|
||||
raise FileNotFoundError("`--codes` is not existed.")
|
||||
if not os.path.exists(source_folder) or not os.path.isdir(source_folder):
|
||||
raise ValueError("`--src_folder` must be a dir and existed.")
|
||||
if not os.path.exists(output_folder) or not os.path.isdir(output_folder):
|
||||
raise ValueError("`--output_folder` must be a dir and existed.")
|
||||
if not isinstance(args.prefix, str) or len(args.prefix) > 128:
|
||||
raise ValueError("`--prefix` must be a str and len <= 128.")
|
||||
if not isinstance(args.processes, int):
|
||||
raise TypeError("`--processes` must be an integer.")
|
||||
|
||||
available_dict = []
|
||||
args_groups = []
|
||||
for file in os.listdir(source_folder):
|
||||
if args.prefix and not file.startswith(args.prefix):
|
||||
continue
|
||||
if file.endswith(".txt"):
|
||||
output_path = os.path.join(output_folder, file.replace(".txt", "_bpe.txt"))
|
||||
dict_path = os.path.join(output_folder, file.replace(".txt", ".dict"))
|
||||
available_dict.append(dict_path)
|
||||
args_groups.append((codes, os.path.join(source_folder, file),
|
||||
output_path, dict_path))
|
||||
|
||||
kernel_size = 1 if args.processes <= 0 else args.processes
|
||||
kernel_size = min(kernel_size, cpu_count())
|
||||
pool = Pool(kernel_size)
|
||||
for arg in args_groups:
|
||||
pool.apply_async(bpe_encode, args=arg)
|
||||
pool.close()
|
||||
pool.join()
|
||||
|
||||
vocab = Dictionary.load_from_text(available_dict)
|
||||
if args.threshold is not None:
|
||||
vocab = vocab.shrink(args.threshold)
|
||||
vocab.persistence(args.vocab_path)
|
||||
print(f" | Vocabulary Size: {len(vocab)}")
|
||||
|
|
@ -0,0 +1,20 @@
|
|||
# Copyright 2020 Huawei Technologies Co., Ltd
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
# ============================================================================
|
||||
"""MASS model configuration."""
|
||||
from .config import TransformerConfig
|
||||
|
||||
__all__ = [
|
||||
"TransformerConfig"
|
||||
]
|
||||
|
|
@ -0,0 +1,54 @@
|
|||
{
|
||||
"dataset_config": {
|
||||
"epochs": 20,
|
||||
"batch_size": 192,
|
||||
"pre_train_dataset": "",
|
||||
"fine_tune_dataset": "",
|
||||
"test_dataset": "",
|
||||
"valid_dataset": "",
|
||||
"dataset_sink_mode": false,
|
||||
"dataset_sink_step": 100
|
||||
},
|
||||
"model_config": {
|
||||
"random_seed": 100,
|
||||
"save_graphs": false,
|
||||
"seq_length": 64,
|
||||
"vocab_size": 45744,
|
||||
"hidden_size": 1024,
|
||||
"num_hidden_layers": 6,
|
||||
"num_attention_heads": 8,
|
||||
"intermediate_size": 4096,
|
||||
"hidden_act": "relu",
|
||||
"hidden_dropout_prob": 0.2,
|
||||
"attention_dropout_prob": 0.2,
|
||||
"max_position_embeddings": 64,
|
||||
"initializer_range": 0.02,
|
||||
"label_smoothing": 0.1,
|
||||
"beam_width": 4,
|
||||
"length_penalty_weight": 1.0,
|
||||
"max_decode_length": 64,
|
||||
"input_mask_from_dataset": true
|
||||
},
|
||||
"loss_scale_config": {
|
||||
"init_loss_scale": 65536,
|
||||
"loss_scale_factor": 2,
|
||||
"scale_window": 200
|
||||
},
|
||||
"learn_rate_config": {
|
||||
"optimizer": "adam",
|
||||
"lr": 1e-4,
|
||||
"lr_scheduler": "poly",
|
||||
"poly_lr_scheduler_power": 0.5,
|
||||
"decay_steps": 10000,
|
||||
"decay_start_step": 12000,
|
||||
"warmup_steps": 4000,
|
||||
"min_lr": 1e-6
|
||||
},
|
||||
"checkpoint_options": {
|
||||
"existed_ckpt": "",
|
||||
"save_ckpt_steps": 2500,
|
||||
"keep_ckpt_max": 50,
|
||||
"ckpt_prefix": "ckpt",
|
||||
"ckpt_path": "checkpoints"
|
||||
}
|
||||
}
|
||||
|
|
@ -0,0 +1,232 @@
|
|||
# Copyright 2020 Huawei Technologies Co., Ltd
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
# ============================================================================
|
||||
"""Configuration class for Transformer."""
|
||||
import os
|
||||
import json
|
||||
import copy
|
||||
from typing import List
|
||||
|
||||
import mindspore.common.dtype as mstype
|
||||
|
||||
|
||||
def _is_dataset_file(file: str):
|
||||
return "tfrecord" in file.lower() or "mindrecord" in file.lower()
|
||||
|
||||
|
||||
def _get_files_from_dir(folder: str):
|
||||
_files = []
|
||||
for file in os.listdir(folder):
|
||||
if _is_dataset_file(file):
|
||||
_files.append(os.path.join(folder, file))
|
||||
return _files
|
||||
|
||||
|
||||
def get_source_list(folder: str) -> List:
|
||||
"""
|
||||
Get file list from a folder.
|
||||
|
||||
Returns:
|
||||
list, file list.
|
||||
"""
|
||||
_list = []
|
||||
if not folder:
|
||||
return _list
|
||||
|
||||
if os.path.isdir(folder):
|
||||
_list = _get_files_from_dir(folder)
|
||||
else:
|
||||
if _is_dataset_file(folder):
|
||||
_list.append(folder)
|
||||
return _list
|
||||
|
||||
|
||||
PARAM_NODES = {"dataset_config",
|
||||
"model_config",
|
||||
"loss_scale_config",
|
||||
"learn_rate_config",
|
||||
"checkpoint_options"}
|
||||
|
||||
|
||||
class TransformerConfig:
|
||||
"""
|
||||
Configuration for `Transformer`.
|
||||
|
||||
Args:
|
||||
random_seed (int): Random seed.
|
||||
batch_size (int): Batch size of input dataset.
|
||||
epochs (int): Epoch number.
|
||||
dataset_sink_mode (bool): Whether enable dataset sink mode.
|
||||
dataset_sink_step (int): Dataset sink step.
|
||||
lr_scheduler (str): Whether use lr_scheduler, only support "ISR" now.
|
||||
lr (float): Initial learning rate.
|
||||
min_lr (float): Minimum learning rate.
|
||||
decay_start_step (int): Step to decay.
|
||||
warmup_steps (int): Warm up steps.
|
||||
dataset_schema (str): Path of dataset schema file.
|
||||
pre_train_dataset (str): Path of pre-training dataset file or folder.
|
||||
fine_tune_dataset (str): Path of fine-tune dataset file or folder.
|
||||
test_dataset (str): Path of test dataset file or folder.
|
||||
valid_dataset (str): Path of validation dataset file or folder.
|
||||
ckpt_path (str): Checkpoints save path.
|
||||
save_ckpt_steps (int): Interval of saving ckpt.
|
||||
ckpt_prefix (str): Prefix of ckpt file.
|
||||
keep_ckpt_max (int): Max ckpt files number.
|
||||
seq_length (int): Length of input sequence. Default: 64.
|
||||
vocab_size (int): The shape of each embedding vector. Default: 46192.
|
||||
hidden_size (int): Size of embedding, attention, dim. Default: 512.
|
||||
num_hidden_layers (int): Encoder, Decoder layers.
|
||||
num_attention_heads (int): Number of hidden layers in the Transformer encoder/decoder
|
||||
cell. Default: 6.
|
||||
intermediate_size (int): Size of intermediate layer in the Transformer
|
||||
encoder/decoder cell. Default: 4096.
|
||||
hidden_act (str): Activation function used in the Transformer encoder/decoder
|
||||
cell. Default: "relu".
|
||||
init_loss_scale (int): Initialized loss scale.
|
||||
loss_scale_factor (int): Loss scale factor.
|
||||
scale_window (int): Window size of loss scale.
|
||||
beam_width (int): Beam width for beam search in inferring. Default: 4.
|
||||
length_penalty_weight (float): Penalty for sentence length. Default: 1.0.
|
||||
label_smoothing (float): Label smoothing setting. Default: 0.1.
|
||||
input_mask_from_dataset (bool): Specifies whether to use the input mask that loaded from
|
||||
dataset. Default: True.
|
||||
save_graphs (bool): Whether to save graphs, please set to True if mindinsight
|
||||
is wanted.
|
||||
dtype (mstype): Data type of the input. Default: mstype.float32.
|
||||
max_decode_length (int): Max decode length for inferring. Default: 64.
|
||||
hidden_dropout_prob (float): The dropout probability for hidden outputs. Default: 0.1.
|
||||
attention_dropout_prob (float): The dropout probability for
|
||||
Multi-head Self-Attention. Default: 0.1.
|
||||
max_position_embeddings (int): Maximum length of sequences used in this
|
||||
model. Default: 512.
|
||||
initializer_range (float): Initialization value of TruncatedNormal. Default: 0.02.
|
||||
"""
|
||||
|
||||
def __init__(self,
|
||||
random_seed=74,
|
||||
batch_size=64, epochs=1,
|
||||
dataset_sink_mode=True, dataset_sink_step=1,
|
||||
lr_scheduler="", optimizer="adam",
|
||||
lr=1e-4, min_lr=1e-6,
|
||||
decay_steps=10000, poly_lr_scheduler_power=1,
|
||||
decay_start_step=-1, warmup_steps=2000,
|
||||
pre_train_dataset: str = None,
|
||||
fine_tune_dataset: str = None,
|
||||
test_dataset: str = None,
|
||||
valid_dataset: str = None,
|
||||
ckpt_path: str = None,
|
||||
save_ckpt_steps=2000,
|
||||
ckpt_prefix="CKPT",
|
||||
existed_ckpt="",
|
||||
keep_ckpt_max=20,
|
||||
seq_length=128,
|
||||
vocab_size=46192,
|
||||
hidden_size=512,
|
||||
num_hidden_layers=6,
|
||||
num_attention_heads=8,
|
||||
intermediate_size=4096,
|
||||
hidden_act="relu",
|
||||
hidden_dropout_prob=0.1,
|
||||
attention_dropout_prob=0.1,
|
||||
max_position_embeddings=64,
|
||||
initializer_range=0.02,
|
||||
init_loss_scale=2 ** 10,
|
||||
loss_scale_factor=2, scale_window=2000,
|
||||
beam_width=5,
|
||||
length_penalty_weight=1.0,
|
||||
label_smoothing=0.1,
|
||||
input_mask_from_dataset=True,
|
||||
save_graphs=False,
|
||||
dtype=mstype.float32,
|
||||
max_decode_length=64):
|
||||
|
||||
self.save_graphs = save_graphs
|
||||
self.random_seed = random_seed
|
||||
self.pre_train_dataset = get_source_list(pre_train_dataset) # type: List[str]
|
||||
self.fine_tune_dataset = get_source_list(fine_tune_dataset) # type: List[str]
|
||||
self.valid_dataset = get_source_list(valid_dataset) # type: List[str]
|
||||
self.test_dataset = get_source_list(test_dataset) # type: List[str]
|
||||
|
||||
if not isinstance(epochs, int) and epochs < 0:
|
||||
raise ValueError("`epoch` must be type of int.")
|
||||
|
||||
self.epochs = epochs
|
||||
self.dataset_sink_mode = dataset_sink_mode
|
||||
self.dataset_sink_step = dataset_sink_step
|
||||
|
||||
self.ckpt_path = ckpt_path
|
||||
self.keep_ckpt_max = keep_ckpt_max
|
||||
self.save_ckpt_steps = save_ckpt_steps
|
||||
self.ckpt_prefix = ckpt_prefix
|
||||
self.existed_ckpt = existed_ckpt
|
||||
|
||||
self.batch_size = batch_size
|
||||
self.seq_length = seq_length
|
||||
self.vocab_size = vocab_size
|
||||
self.hidden_size = hidden_size
|
||||
self.num_hidden_layers = num_hidden_layers
|
||||
self.num_attention_heads = num_attention_heads
|
||||
self.hidden_act = hidden_act
|
||||
self.intermediate_size = intermediate_size
|
||||
self.hidden_dropout_prob = hidden_dropout_prob
|
||||
self.attention_dropout_prob = attention_dropout_prob
|
||||
self.max_position_embeddings = max_position_embeddings
|
||||
self.initializer_range = initializer_range
|
||||
self.label_smoothing = label_smoothing
|
||||
|
||||
self.beam_width = beam_width
|
||||
self.length_penalty_weight = length_penalty_weight
|
||||
self.max_decode_length = max_decode_length
|
||||
self.input_mask_from_dataset = input_mask_from_dataset
|
||||
self.compute_type = mstype.float16
|
||||
self.dtype = dtype
|
||||
|
||||
self.scale_window = scale_window
|
||||
self.loss_scale_factor = loss_scale_factor
|
||||
self.init_loss_scale = init_loss_scale
|
||||
|
||||
self.optimizer = optimizer
|
||||
self.lr = lr
|
||||
self.lr_scheduler = lr_scheduler
|
||||
self.min_lr = min_lr
|
||||
self.poly_lr_scheduler_power = poly_lr_scheduler_power
|
||||
self.decay_steps = decay_steps
|
||||
self.decay_start_step = decay_start_step
|
||||
self.warmup_steps = warmup_steps
|
||||
|
||||
self.train_url = ""
|
||||
|
||||
@classmethod
|
||||
def from_dict(cls, json_object: dict):
|
||||
"""Constructs a `TransformerConfig` from a Python dictionary of parameters."""
|
||||
_params = {}
|
||||
for node in PARAM_NODES:
|
||||
for key in json_object[node]:
|
||||
_params[key] = json_object[node][key]
|
||||
return cls(**_params)
|
||||
|
||||
@classmethod
|
||||
def from_json_file(cls, json_file):
|
||||
"""Constructs a `TransformerConfig` from a json file of parameters."""
|
||||
with open(json_file, "r") as reader:
|
||||
return cls.from_dict(json.load(reader))
|
||||
|
||||
def to_dict(self):
|
||||
"""Serializes this instance to a Python dictionary."""
|
||||
output = copy.deepcopy(self.__dict__)
|
||||
return output
|
||||
|
||||
def to_json_string(self):
|
||||
"""Serializes this instance to a JSON string."""
|
||||
return json.dumps(self.to_dict(), indent=2, sort_keys=True) + "\n"
|
||||
|
|
@ -0,0 +1,110 @@
|
|||
# Copyright 2020 Huawei Technologies Co., Ltd
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
# ============================================================================
|
||||
"""Generate Cornell Movie Dialog dataset."""
|
||||
import os
|
||||
import argparse
|
||||
from src.dataset import BiLingualDataLoader
|
||||
from src.language_model import NoiseChannelLanguageModel
|
||||
from src.utils import Dictionary
|
||||
|
||||
parser = argparse.ArgumentParser(description='Generate Cornell Movie Dialog dataset file.')
|
||||
parser.add_argument("--src_folder", type=str, default="", required=True,
|
||||
help="Raw corpus folder.")
|
||||
parser.add_argument("--existed_vocab", type=str, default="", required=True,
|
||||
help="Existed vocabulary.")
|
||||
parser.add_argument("--train_prefix", type=str, default="train", required=False,
|
||||
help="Prefix of train file.")
|
||||
parser.add_argument("--test_prefix", type=str, default="test", required=False,
|
||||
help="Prefix of test file.")
|
||||
parser.add_argument("--valid_prefix", type=str, default=None, required=False,
|
||||
help="Prefix of valid file.")
|
||||
parser.add_argument("--noise_prob", type=float, default=0., required=False,
|
||||
help="Add noise prob.")
|
||||
parser.add_argument("--max_len", type=int, default=32, required=False,
|
||||
help="Max length of sentence.")
|
||||
parser.add_argument("--output_folder", type=str, default="", required=True,
|
||||
help="Dataset output path.")
|
||||
|
||||
if __name__ == '__main__':
|
||||
args, _ = parser.parse_known_args()
|
||||
|
||||
dicts = []
|
||||
train_src_file = ""
|
||||
train_tgt_file = ""
|
||||
test_src_file = ""
|
||||
test_tgt_file = ""
|
||||
valid_src_file = ""
|
||||
valid_tgt_file = ""
|
||||
for file in os.listdir(args.src_folder):
|
||||
if file.startswith(args.train_prefix) and "src" in file and file.endswith(".txt"):
|
||||
train_src_file = os.path.join(args.src_folder, file)
|
||||
elif file.startswith(args.train_prefix) and "tgt" in file and file.endswith(".txt"):
|
||||
train_tgt_file = os.path.join(args.src_folder, file)
|
||||
elif file.startswith(args.test_prefix) and "src" in file and file.endswith(".txt"):
|
||||
test_src_file = os.path.join(args.src_folder, file)
|
||||
elif file.startswith(args.test_prefix) and "tgt" in file and file.endswith(".txt"):
|
||||
test_tgt_file = os.path.join(args.src_folder, file)
|
||||
elif args.valid_prefix and file.startswith(args.valid_prefix) and "src" in file and file.endswith(".txt"):
|
||||
valid_src_file = os.path.join(args.src_folder, file)
|
||||
elif args.valid_prefix and file.startswith(args.valid_prefix) and "tgt" in file and file.endswith(".txt"):
|
||||
valid_tgt_file = os.path.join(args.src_folder, file)
|
||||
else:
|
||||
continue
|
||||
|
||||
vocab = Dictionary.load_from_persisted_dict(args.existed_vocab)
|
||||
|
||||
if train_src_file and train_tgt_file:
|
||||
BiLingualDataLoader(
|
||||
src_filepath=train_src_file,
|
||||
tgt_filepath=train_tgt_file,
|
||||
src_dict=vocab, tgt_dict=vocab,
|
||||
src_lang="en", tgt_lang="en",
|
||||
language_model=NoiseChannelLanguageModel(add_noise_prob=args.noise_prob),
|
||||
max_sen_len=args.max_len
|
||||
).write_to_tfrecord(
|
||||
path=os.path.join(
|
||||
args.output_folder, "train_cornell_dialog.tfrecord"
|
||||
)
|
||||
)
|
||||
|
||||
if test_src_file and test_tgt_file:
|
||||
BiLingualDataLoader(
|
||||
src_filepath=test_src_file,
|
||||
tgt_filepath=test_tgt_file,
|
||||
src_dict=vocab, tgt_dict=vocab,
|
||||
src_lang="en", tgt_lang="en",
|
||||
language_model=NoiseChannelLanguageModel(add_noise_prob=0.),
|
||||
max_sen_len=args.max_len
|
||||
).write_to_tfrecord(
|
||||
path=os.path.join(
|
||||
args.output_folder, "test_cornell_dialog.tfrecord"
|
||||
)
|
||||
)
|
||||
|
||||
if args.valid_prefix:
|
||||
BiLingualDataLoader(
|
||||
src_filepath=os.path.join(args.src_folder, valid_src_file),
|
||||
tgt_filepath=os.path.join(args.src_folder, valid_tgt_file),
|
||||
src_dict=vocab, tgt_dict=vocab,
|
||||
src_lang="en", tgt_lang="en",
|
||||
language_model=NoiseChannelLanguageModel(add_noise_prob=0.),
|
||||
max_sen_len=args.max_len
|
||||
).write_to_tfrecord(
|
||||
path=os.path.join(
|
||||
args.output_folder, "valid_cornell_dialog.tfrecord"
|
||||
)
|
||||
)
|
||||
|
||||
print(f" | Vocabulary size: {vocab.size}.")
|
||||
|
|
@ -0,0 +1,75 @@
|
|||
# Copyright 2020 Huawei Technologies Co., Ltd
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
# ============================================================================
|
||||
"""Evaluation api."""
|
||||
import argparse
|
||||
import pickle
|
||||
import numpy as np
|
||||
|
||||
from mindspore.common import dtype as mstype
|
||||
|
||||
from config import TransformerConfig
|
||||
from src.transformer import infer
|
||||
from src.utils import ngram_ppl
|
||||
from src.utils import Dictionary
|
||||
from src.utils import rouge
|
||||
|
||||
parser = argparse.ArgumentParser(description='Evaluation MASS.')
|
||||
parser.add_argument("--config", type=str, required=True,
|
||||
help="Model config json file path.")
|
||||
parser.add_argument("--vocab", type=str, required=True,
|
||||
help="Vocabulary to use.")
|
||||
parser.add_argument("--output", type=str, required=True,
|
||||
help="Result file path.")
|
||||
|
||||
|
||||
def get_config(config):
|
||||
config = TransformerConfig.from_json_file(config)
|
||||
config.compute_type = mstype.float16
|
||||
config.dtype = mstype.float32
|
||||
return config
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
args, _ = parser.parse_known_args()
|
||||
vocab = Dictionary.load_from_persisted_dict(args.vocab)
|
||||
_config = get_config(args.config)
|
||||
result = infer(_config)
|
||||
with open(args.output, "wb") as f:
|
||||
pickle.dump(result, f, 1)
|
||||
|
||||
ppl_score = 0.
|
||||
preds = []
|
||||
tgts = []
|
||||
_count = 0
|
||||
for sample in result:
|
||||
sentence_prob = np.array(sample['prediction_prob'], dtype=np.float32)
|
||||
sentence_prob = sentence_prob[:, 1:]
|
||||
_ppl = []
|
||||
for path in sentence_prob:
|
||||
_ppl.append(ngram_ppl(path, log_softmax=True))
|
||||
ppl = np.min(_ppl)
|
||||
preds.append(' '.join([vocab[t] for t in sample['prediction']]))
|
||||
tgts.append(' '.join([vocab[t] for t in sample['target']]))
|
||||
print(f" | source: {' '.join([vocab[t] for t in sample['source']])}")
|
||||
print(f" | target: {tgts[-1]}")
|
||||
print(f" | prediction: {preds[-1]}")
|
||||
print(f" | ppl: {ppl}.")
|
||||
if np.isinf(ppl):
|
||||
continue
|
||||
ppl_score += ppl
|
||||
_count += 1
|
||||
|
||||
print(f" | PPL={ppl_score / _count}.")
|
||||
rouge(preds, tgts)
|
||||
|
|
@ -0,0 +1,84 @@
|
|||
# Copyright 2020 Huawei Technologies Co., Ltd
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
# ============================================================================
|
||||
"""Generate Gigaword dataset."""
|
||||
import os
|
||||
import argparse
|
||||
|
||||
from src.dataset import BiLingualDataLoader
|
||||
from src.language_model import NoiseChannelLanguageModel
|
||||
from src.utils import Dictionary
|
||||
|
||||
parser = argparse.ArgumentParser(description='Create Gigaword fine-tune Dataset.')
|
||||
parser.add_argument("--train_src", type=str, default="", required=False,
|
||||
help="train dataset source file path.")
|
||||
parser.add_argument("--train_ref", type=str, default="", required=False,
|
||||
help="train dataset reference file path.")
|
||||
parser.add_argument("--test_src", type=str, default="", required=False,
|
||||
help="test dataset source file path.")
|
||||
parser.add_argument("--test_ref", type=str, default="", required=False,
|
||||
help="test dataset reference file path.")
|
||||
parser.add_argument("--noise_prob", type=float, default=0., required=False,
|
||||
help="add noise prob.")
|
||||
parser.add_argument("--existed_vocab", type=str, default="", required=False,
|
||||
help="existed vocab path.")
|
||||
parser.add_argument("--max_len", type=int, default=64, required=False,
|
||||
help="max length of sentences.")
|
||||
parser.add_argument("--output_folder", type=str, default="", required=True,
|
||||
help="dataset output path.")
|
||||
parser.add_argument("--format", type=str, default="tfrecord", required=False,
|
||||
help="dataset format.")
|
||||
|
||||
if __name__ == '__main__':
|
||||
args, _ = parser.parse_known_args()
|
||||
|
||||
vocab = Dictionary.load_from_persisted_dict(args.existed_vocab)
|
||||
|
||||
if args.train_src and args.train_ref:
|
||||
train = BiLingualDataLoader(
|
||||
src_filepath=args.train_src,
|
||||
tgt_filepath=args.train_ref,
|
||||
src_dict=vocab, tgt_dict=vocab,
|
||||
src_lang="en", tgt_lang="en",
|
||||
language_model=NoiseChannelLanguageModel(add_noise_prob=args.noise_prob),
|
||||
max_sen_len=args.max_len
|
||||
)
|
||||
if "tf" in args.format.lower():
|
||||
train.write_to_tfrecord(
|
||||
path=os.path.join(args.output_folder, "gigaword_train_dataset.tfrecord")
|
||||
)
|
||||
else:
|
||||
train.write_to_mindrecord(
|
||||
path=os.path.join(args.output_folder, "gigaword_train_dataset.mindrecord")
|
||||
)
|
||||
|
||||
if args.test_src and args.test_ref:
|
||||
test = BiLingualDataLoader(
|
||||
src_filepath=args.test_src,
|
||||
tgt_filepath=args.test_ref,
|
||||
src_dict=vocab, tgt_dict=vocab,
|
||||
src_lang="en", tgt_lang="en",
|
||||
language_model=NoiseChannelLanguageModel(add_noise_prob=0),
|
||||
max_sen_len=args.max_len
|
||||
)
|
||||
if "tf" in args.format.lower():
|
||||
test.write_to_tfrecord(
|
||||
path=os.path.join(args.output_folder, "gigaword_test_dataset.tfrecord")
|
||||
)
|
||||
else:
|
||||
test.write_to_mindrecord(
|
||||
path=os.path.join(args.output_folder, "gigaword_test_dataset.mindrecord")
|
||||
)
|
||||
|
||||
print(f" | Vocabulary size: {vocab.size}.")
|
||||
|
|
@ -0,0 +1,58 @@
|
|||
# Copyright 2020 Huawei Technologies Co., Ltd
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
# ============================================================================
|
||||
"""Generate News Crawl corpus dataset."""
|
||||
import argparse
|
||||
|
||||
from src.utils import Dictionary
|
||||
from src.utils.preprocess import create_pre_training_dataset
|
||||
|
||||
parser = argparse.ArgumentParser(description='Create News Crawl Pre-Training Dataset.')
|
||||
parser.add_argument("--src_folder", type=str, default="", required=True,
|
||||
help="Raw corpus folder.")
|
||||
parser.add_argument("--existed_vocab", type=str, default="", required=True,
|
||||
help="Existed vocab path.")
|
||||
parser.add_argument("--mask_ratio", type=float, default=0.4, required=True,
|
||||
help="Mask ratio.")
|
||||
parser.add_argument("--output_folder", type=str, default="", required=True,
|
||||
help="Dataset output path.")
|
||||
parser.add_argument("--max_len", type=int, default=32, required=False,
|
||||
help="Max length of sentences.")
|
||||
parser.add_argument("--suffix", type=str, default="", required=False,
|
||||
help="Add suffix to output file.")
|
||||
parser.add_argument("--processes", type=int, default=2, required=False,
|
||||
help="Size of processes pool.")
|
||||
|
||||
if __name__ == '__main__':
|
||||
args, _ = parser.parse_known_args()
|
||||
if not (args.src_folder and args.output_folder):
|
||||
raise ValueError("Please enter required params.")
|
||||
|
||||
if not args.existed_vocab:
|
||||
raise ValueError("`--existed_vocab` is required.")
|
||||
|
||||
vocab = Dictionary.load_from_persisted_dict(args.existed_vocab)
|
||||
|
||||
create_pre_training_dataset(
|
||||
folder_path=args.src_folder,
|
||||
output_folder_path=args.output_folder,
|
||||
vocabulary=vocab,
|
||||
prefix="news.20", suffix=args.suffix,
|
||||
mask_ratio=args.mask_ratio,
|
||||
min_sen_len=10,
|
||||
max_sen_len=args.max_len,
|
||||
dataset_type="tfrecord",
|
||||
cores=args.processes
|
||||
)
|
||||
print(f" | Vocabulary size: {vocab.size}.")
|
||||
|
|
@ -0,0 +1,5 @@
|
|||
nltk
|
||||
jieba
|
||||
numpy
|
||||
subword-nmt
|
||||
files2rouge
|
||||
|
|
@ -0,0 +1,20 @@
|
|||
#!/bin/bash
|
||||
# Copyright 2020 Huawei Technologies Co., Ltd
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
# ============================================================================
|
||||
|
||||
src_folder_path=$1 # source text folder path.
|
||||
|
||||
cd $src_folder_path || exit
|
||||
cat *.txt | subword-nmt learn-bpe -s 46000 -o all.bpe.codes
|
||||
|
|
@ -0,0 +1,169 @@
|
|||
#!/usr/bin/env bash
|
||||
# Copyright 2020 Huawei Technologies Co., Ltd
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
# ============================================================================
|
||||
|
||||
export DEVICE_ID=0
|
||||
export RANK_ID=0
|
||||
export RANK_SIZE=1
|
||||
|
||||
options=`getopt -u -o ht:n:i:j:c:o:v: -l help,task:,device_num:,device_id:,hccl_json:,config:,output:,vocab -- "$@"`
|
||||
eval set -- "$options"
|
||||
echo $options
|
||||
|
||||
echo_help()
|
||||
{
|
||||
echo "Usage:"
|
||||
echo "bash train.sh [-h] [-t t|i] [-n N] [-i N] [-j FILE] [-c FILE] [-o FILE] [-v FILE]"
|
||||
echo "options:"
|
||||
echo " -h --help show usage"
|
||||
echo " -t --task select task, 't' for training and 'i' for inference"
|
||||
echo " -n --device_num training with N devices"
|
||||
echo " -i --device_id training with device i"
|
||||
echo " -j --hccl_json set the rank table file"
|
||||
echo " -c --config set the configuration file"
|
||||
echo " -o --output set the output file of inference"
|
||||
echo " -v --vocab set the vocabulary"
|
||||
}
|
||||
|
||||
set_hccl_json()
|
||||
{
|
||||
while [ -n "$1" ]
|
||||
do
|
||||
if [[ "$1" == "-j" || "$1" == "--hccl_json" ]]
|
||||
then
|
||||
export MINDSPORE_HCCL_CONFIG_PATH=$2 #/data/wsc/hccl_2p_01.json
|
||||
export RANK_TABLE_FILE=$2 #/data/wsc/hccl_2p_01.json
|
||||
break
|
||||
fi
|
||||
shift
|
||||
done
|
||||
}
|
||||
set_device_id()
|
||||
{
|
||||
while [ -n "$1" ]
|
||||
do
|
||||
if [[ "$1" == "-i" || "$1" == "--device_id" ]]
|
||||
then
|
||||
if [[ $2 -ge 0 && $2 -le 7 ]]
|
||||
then
|
||||
export DEVICE_ID=$2
|
||||
fi
|
||||
break
|
||||
fi
|
||||
shift
|
||||
done
|
||||
}
|
||||
|
||||
while [ -n "$1" ]
|
||||
do
|
||||
case "$1" in
|
||||
-h|--help)
|
||||
echo_help
|
||||
shift
|
||||
;;
|
||||
-t|--task)
|
||||
echo "task:"
|
||||
if [ "$2" == "t" ]
|
||||
then
|
||||
task=train
|
||||
elif [ "$2" == "i" ]
|
||||
then
|
||||
task=infer
|
||||
fi
|
||||
shift 2
|
||||
;;
|
||||
-n|--device_num)
|
||||
echo "device_num"
|
||||
if [ $2 -eq 1 ]
|
||||
then
|
||||
set_device_id $options
|
||||
elif [ $2 -gt 1 ]
|
||||
then
|
||||
export HCCL_FLAG=1
|
||||
export DEPLOY_MODE=0
|
||||
|
||||
export RANK_SIZE=$2
|
||||
set_hccl_json $options
|
||||
fi
|
||||
shift 2
|
||||
;;
|
||||
-i|--device_id)
|
||||
echo "set device id"
|
||||
export DEVICE_ID=$2
|
||||
shift 2
|
||||
;;
|
||||
-c|--config)
|
||||
echo "config";
|
||||
configurations=$2
|
||||
shift 2
|
||||
;;
|
||||
-o|--output)
|
||||
echo "output";
|
||||
output=$2
|
||||
shift 2
|
||||
;;
|
||||
-v|--vocab)
|
||||
echo "vocab";
|
||||
vocab=$2
|
||||
shift 2
|
||||
;;
|
||||
--)
|
||||
shift
|
||||
break
|
||||
;;
|
||||
*)
|
||||
shift
|
||||
;;
|
||||
esac
|
||||
done
|
||||
|
||||
for((i=0; i < $RANK_SIZE; i++))
|
||||
do
|
||||
if [ $RANK_SIZE -gt 1 ]
|
||||
then
|
||||
echo $RANK_SIZE
|
||||
export RANK_ID=$i
|
||||
export DEVICE_ID=$[i]
|
||||
fi
|
||||
echo "Working on device $i"
|
||||
|
||||
file_path=$(cd "$(dirname $0)" || exit; pwd)
|
||||
cd $file_path || exit
|
||||
cd ../ || exit
|
||||
|
||||
rm -rf ./run_mass_$DEVICE_ID
|
||||
mkdir ./run_mass_$DEVICE_ID
|
||||
|
||||
cp train.py ./run_mass_$DEVICE_ID
|
||||
cp eval.py ./run_mass_$DEVICE_ID
|
||||
cp $configurations ./run_mass_$DEVICE_ID
|
||||
|
||||
if [ $vocab ]
|
||||
then
|
||||
cp $vocab ./run_mass_$DEVICE_ID
|
||||
fi
|
||||
|
||||
cd ./run_mass_$DEVICE_ID || exit
|
||||
env > log.log
|
||||
echo $task
|
||||
if [ "$task" == "train" ]
|
||||
then
|
||||
python train.py --config ${configurations##*/} >>log.log 2>&1 &
|
||||
elif [ "$task" == "infer" ]
|
||||
then
|
||||
python eval.py --config ${configurations##*/} --output ${output} --vocab ${vocab##*/} >>log_infer.log 2>&1 &
|
||||
fi
|
||||
cd ../
|
||||
done
|
||||
|
|
@ -0,0 +1,44 @@
|
|||
# Copyright 2020 Huawei Technologies Co., Ltd
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
# ============================================================================
|
||||
"""Source of mass model."""
|
||||
from .dataset import load_dataset
|
||||
from .dataset import bi_data_loader
|
||||
from .dataset import mono_data_loader
|
||||
from .transformer import TransformerDecoder
|
||||
from .transformer import TransformerEncoder
|
||||
from .transformer import Transformer
|
||||
from .transformer import TransformerNetworkWithLoss
|
||||
from .transformer import LabelSmoothedCrossEntropyCriterion
|
||||
from .transformer import TransformerTrainOneStepWithLossScaleCell
|
||||
from .transformer import TransformerTraining
|
||||
from .transformer import infer
|
||||
from .language_model import LooseMaskedLanguageModel
|
||||
from .language_model import MaskedLanguageModel
|
||||
from .language_model import NoiseChannelLanguageModel
|
||||
|
||||
__all__ = [
|
||||
"load_dataset",
|
||||
"bi_data_loader",
|
||||
"mono_data_loader",
|
||||
"Transformer",
|
||||
"infer",
|
||||
"TransformerTraining",
|
||||
"TransformerNetworkWithLoss",
|
||||
"TransformerTrainOneStepWithLossScaleCell",
|
||||
"LabelSmoothedCrossEntropyCriterion",
|
||||
"LooseMaskedLanguageModel",
|
||||
"MaskedLanguageModel",
|
||||
"NoiseChannelLanguageModel"
|
||||
]
|
||||
|
|
@ -0,0 +1,24 @@
|
|||
# Copyright 2020 Huawei Technologies Co., Ltd
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
# ============================================================================
|
||||
"""Dataset module."""
|
||||
from .bi_data_loader import BiLingualDataLoader
|
||||
from .mono_data_loader import MonoLingualDataLoader
|
||||
from .load_dataset import load_dataset
|
||||
|
||||
__all__ = [
|
||||
"load_dataset",
|
||||
"BiLingualDataLoader",
|
||||
"MonoLingualDataLoader"
|
||||
]
|
||||
|
|
@ -0,0 +1,102 @@
|
|||
# Copyright 2020 Huawei Technologies Co., Ltd
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
# ============================================================================
|
||||
"""Base class of data loader."""
|
||||
import os
|
||||
import collections
|
||||
import numpy as np
|
||||
|
||||
from mindspore.mindrecord import FileWriter
|
||||
from .schema import SCHEMA
|
||||
|
||||
|
||||
class DataLoader:
|
||||
"""Data loader for dataset."""
|
||||
_SCHEMA = SCHEMA
|
||||
|
||||
def __init__(self, max_sen_len=66):
|
||||
self._examples = []
|
||||
self._max_sentence_len = max_sen_len
|
||||
|
||||
def _load(self):
|
||||
raise NotImplementedError
|
||||
|
||||
def padding(self, sen, padding_idx, dtype=np.int64):
|
||||
"""Padding <pad> to sentence."""
|
||||
if sen.shape[0] > self._max_sentence_len:
|
||||
return None
|
||||
new_sen = np.array([padding_idx] * self._max_sentence_len,
|
||||
dtype=dtype)
|
||||
new_sen[:sen.shape[0]] = sen[:]
|
||||
return new_sen
|
||||
|
||||
def write_to_mindrecord(self, path, shard_num=1, desc=""):
|
||||
"""
|
||||
Write mindrecord file.
|
||||
|
||||
Args:
|
||||
path (str): File path.
|
||||
shard_num (int): Shard num.
|
||||
desc (str): Description.
|
||||
"""
|
||||
if not os.path.isabs(path):
|
||||
path = os.path.abspath(path)
|
||||
|
||||
writer = FileWriter(file_name=path, shard_num=shard_num)
|
||||
writer.add_schema(self._SCHEMA, desc)
|
||||
if not self._examples:
|
||||
self._load()
|
||||
|
||||
writer.write_raw_data(self._examples)
|
||||
writer.commit()
|
||||
print(f"| Wrote to {path}.")
|
||||
|
||||
def write_to_tfrecord(self, path, shard_num=1):
|
||||
"""
|
||||
Write to tfrecord.
|
||||
|
||||
Args:
|
||||
path (str): Output file path.
|
||||
shard_num (int): Shard num.
|
||||
"""
|
||||
import tensorflow as tf
|
||||
if not os.path.isabs(path):
|
||||
path = os.path.abspath(path)
|
||||
output_files = []
|
||||
for i in range(shard_num):
|
||||
output_file = path + "-%03d-of-%03d" % (i + 1, shard_num)
|
||||
output_files.append(output_file)
|
||||
# create writers
|
||||
writers = []
|
||||
for output_file in output_files:
|
||||
writers.append(tf.io.TFRecordWriter(output_file))
|
||||
|
||||
if not self._examples:
|
||||
self._load()
|
||||
|
||||
# create feature
|
||||
features = collections.OrderedDict()
|
||||
for example in self._examples:
|
||||
for key in example:
|
||||
features[key] = tf.train.Feature(int64_list=tf.train.Int64List(value=example[key].tolist()))
|
||||
tf_example = tf.train.Example(features=tf.train.Features(feature=features))
|
||||
for writer in writers:
|
||||
writer.write(tf_example.SerializeToString())
|
||||
for writer in writers:
|
||||
writer.close()
|
||||
for p in output_files:
|
||||
print(f" | Write to {p}.")
|
||||
|
||||
def _add_example(self, example):
|
||||
self._examples.append(example)
|
||||
|
|
@ -0,0 +1,142 @@
|
|||
# Copyright 2020 Huawei Technologies Co., Ltd
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
# ============================================================================
|
||||
"""Bilingual data loader."""
|
||||
import numpy as np
|
||||
|
||||
from src.utils import Dictionary
|
||||
from .base import DataLoader
|
||||
from ..language_model.base import LanguageModel
|
||||
from ..language_model.noise_channel_language_model import NoiseChannelLanguageModel
|
||||
|
||||
|
||||
class BiLingualDataLoader(DataLoader):
|
||||
"""Loader for bilingual data."""
|
||||
|
||||
def __init__(self, src_filepath: str, tgt_filepath: str,
|
||||
src_dict: Dictionary, tgt_dict: Dictionary,
|
||||
src_lang: str, tgt_lang: str,
|
||||
language_model: LanguageModel = NoiseChannelLanguageModel(add_noise_prob=0),
|
||||
max_sen_len=66,
|
||||
merge_dict=True):
|
||||
super(BiLingualDataLoader, self).__init__(max_sen_len)
|
||||
self._src_filepath = src_filepath
|
||||
self._tgt_filepath = tgt_filepath
|
||||
self._src_dict = src_dict
|
||||
self._tgt_dict = tgt_dict
|
||||
self.src_lang = src_lang
|
||||
self.tgt_lang = tgt_lang
|
||||
self._lm = language_model
|
||||
self.max_sen_len = max_sen_len
|
||||
self.share_dict = merge_dict
|
||||
self._merge_dict()
|
||||
|
||||
def _merge_dict(self):
|
||||
if self.share_dict:
|
||||
merged_dict = self._src_dict.merge_dict(self._tgt_dict,
|
||||
new_dict=True)
|
||||
self._src_dict = merged_dict
|
||||
self._tgt_dict = merged_dict
|
||||
|
||||
@property
|
||||
def src_dict(self):
|
||||
return self._src_dict
|
||||
|
||||
@property
|
||||
def tgt_dict(self):
|
||||
return self._tgt_dict
|
||||
|
||||
def _load(self):
|
||||
_min_len = 9999999999
|
||||
_max_len = 0
|
||||
unk_count = 0
|
||||
tokens_count = 0
|
||||
count = 0
|
||||
with open(self._src_filepath, "r") as _src_file:
|
||||
print(f" | Processing corpus {self._src_filepath}.")
|
||||
print(f" | Processing corpus {self._tgt_filepath}.")
|
||||
with open(self._tgt_filepath, "r") as _tgt_file:
|
||||
_min, _max = 9999999, -1
|
||||
for _, _pair in enumerate(zip(_src_file, _tgt_file)):
|
||||
src_tokens = [
|
||||
self._src_dict.index(t)
|
||||
for t in _pair[0].strip().split(" ") if t
|
||||
]
|
||||
tgt_tokens = [
|
||||
self._tgt_dict.index(t)
|
||||
for t in _pair[1].strip().split(" ") if t
|
||||
]
|
||||
src_tokens.append(self._src_dict.eos_index)
|
||||
tgt_tokens.append(self._tgt_dict.eos_index)
|
||||
opt = self._lm.emit(
|
||||
sentence=np.array(src_tokens, dtype=np.int64),
|
||||
target=np.array(tgt_tokens, dtype=np.int64),
|
||||
mask_symbol_idx=self._src_dict.mask_index,
|
||||
bos_symbol_idx=self._tgt_dict.bos_index
|
||||
)
|
||||
src_len = opt["sentence_length"]
|
||||
tgt_len = opt["tgt_sen_length"]
|
||||
|
||||
_min_len = min(_min_len, opt["sentence_length"], opt["tgt_sen_length"])
|
||||
_max_len = max(_max_len, opt["sentence_length"], opt["tgt_sen_length"])
|
||||
|
||||
if src_len > self.max_sen_len or tgt_len > self.max_sen_len:
|
||||
continue
|
||||
|
||||
src_padding = np.zeros(shape=self.max_sen_len, dtype=np.int64)
|
||||
tgt_padding = np.zeros(shape=self.max_sen_len, dtype=np.int64)
|
||||
for i in range(src_len):
|
||||
src_padding[i] = 1
|
||||
for j in range(tgt_len):
|
||||
tgt_padding[j] = 1
|
||||
|
||||
tokens_count += opt["encoder_input"].shape[0]
|
||||
tokens_count += opt["decoder_input"].shape[0]
|
||||
tokens_count += opt["decoder_output"].shape[0]
|
||||
unk_count += np.where(opt["encoder_input"] == self._src_dict.unk_index)[0].shape[0]
|
||||
unk_count += np.where(opt["decoder_input"] == self._src_dict.unk_index)[0].shape[0]
|
||||
unk_count += np.where(opt["decoder_output"] == self._src_dict.unk_index)[0].shape[0]
|
||||
|
||||
encoder_input = self.padding(opt["encoder_input"],
|
||||
self._src_dict.padding_index)
|
||||
decoder_input = self.padding(opt["decoder_input"],
|
||||
self._tgt_dict.padding_index)
|
||||
decoder_output = self.padding(opt["decoder_output"],
|
||||
self._tgt_dict.padding_index)
|
||||
if encoder_input is None or decoder_input is None or decoder_output is None:
|
||||
continue
|
||||
|
||||
_min = np.min([np.min(encoder_input),
|
||||
np.min(decoder_input),
|
||||
np.min(decoder_output), _min])
|
||||
_max = np.max([np.max(encoder_input),
|
||||
np.max(decoder_input),
|
||||
np.max(decoder_output), _max])
|
||||
|
||||
example = {
|
||||
"src_padding": src_padding,
|
||||
"tgt_padding": tgt_padding,
|
||||
"src": encoder_input,
|
||||
"prev_opt": decoder_input,
|
||||
"prev_padding": tgt_padding,
|
||||
"target": decoder_output
|
||||
}
|
||||
self._add_example(example)
|
||||
count += 1
|
||||
|
||||
print(f" | Shortest len = {_min_len}.")
|
||||
print(f" | Longest len = {_max_len}.")
|
||||
print(f" | Total sen = {count}.")
|
||||
print(f" | Total token num={tokens_count}, "
|
||||
f"{unk_count / tokens_count * 100}% replaced by <unk>.")
|
||||
|
|
@ -0,0 +1,121 @@
|
|||
# Copyright 2020 Huawei Technologies Co., Ltd
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
# ============================================================================
|
||||
"""Dataset loader to feed into model."""
|
||||
import os
|
||||
import mindspore.common.dtype as mstype
|
||||
import mindspore.dataset.engine as de
|
||||
import mindspore.dataset.transforms.c_transforms as deC
|
||||
|
||||
|
||||
def _load_dataset(input_files, batch_size, epoch_count=1,
|
||||
sink_mode=False, sink_step=1, rank_size=1, rank_id=0, shuffle=True):
|
||||
"""
|
||||
Load dataset according to passed in params.
|
||||
|
||||
Args:
|
||||
input_files (list): Data files.
|
||||
batch_size (int): Batch size.
|
||||
epoch_count (int): Epoch count.
|
||||
sink_mode (bool): Whether enable sink mode.
|
||||
sink_step (int): Step to sink.
|
||||
rank_size (int): Rank size.
|
||||
rank_id (int): Rank id.
|
||||
shuffle (bool): Whether shuffle dataset.
|
||||
|
||||
Returns:
|
||||
Dataset, dataset instance.
|
||||
"""
|
||||
if not input_files:
|
||||
raise FileNotFoundError("Require at least one dataset.")
|
||||
|
||||
if not (schema_file and
|
||||
os.path.exists(schema_file)
|
||||
and os.path.isfile(schema_file)
|
||||
and os.path.basename(schema_file).endswith(".json")):
|
||||
raise FileNotFoundError("`dataset_schema` must be a existed json file.")
|
||||
|
||||
if not isinstance(sink_mode, bool):
|
||||
raise ValueError("`sink` must be type of bool.")
|
||||
|
||||
for datafile in input_files:
|
||||
print(f" | Loading {datafile}.")
|
||||
|
||||
ds = de.TFRecordDataset(
|
||||
input_files,
|
||||
columns_list=[
|
||||
"src", "src_padding",
|
||||
"prev_opt", "prev_padding",
|
||||
"target", "tgt_padding"
|
||||
],
|
||||
shuffle=shuffle, num_shards=rank_size, shard_id=rank_id,
|
||||
shard_equal_rows=True, num_parallel_workers=8)
|
||||
|
||||
ori_dataset_size = ds.get_dataset_size()
|
||||
print(f" | Dataset size: {ori_dataset_size}.")
|
||||
repeat_count = epoch_count
|
||||
if sink_mode:
|
||||
ds.set_dataset_size(sink_step * batch_size)
|
||||
repeat_count = epoch_count * ori_dataset_size // ds.get_dataset_size()
|
||||
|
||||
type_cast_op = deC.TypeCast(mstype.int32)
|
||||
ds = ds.map(input_columns="src", operations=type_cast_op)
|
||||
ds = ds.map(input_columns="src_padding", operations=type_cast_op)
|
||||
ds = ds.map(input_columns="prev_opt", operations=type_cast_op)
|
||||
ds = ds.map(input_columns="prev_padding", operations=type_cast_op)
|
||||
ds = ds.map(input_columns="target", operations=type_cast_op)
|
||||
ds = ds.map(input_columns="tgt_padding", operations=type_cast_op)
|
||||
|
||||
ds = ds.rename(
|
||||
input_columns=["src",
|
||||
"src_padding",
|
||||
"prev_opt",
|
||||
"prev_padding",
|
||||
"target",
|
||||
"tgt_padding"],
|
||||
output_columns=["source_eos_ids",
|
||||
"source_eos_mask",
|
||||
"target_sos_ids",
|
||||
"target_sos_mask",
|
||||
"target_eos_ids",
|
||||
"target_eos_mask"]
|
||||
)
|
||||
|
||||
ds = ds.batch(batch_size, drop_remainder=True)
|
||||
ds = ds.repeat(repeat_count)
|
||||
|
||||
ds.channel_name = 'transformer'
|
||||
return ds
|
||||
|
||||
|
||||
def load_dataset(data_files: list, batch_size: int, epoch_count: int,
|
||||
sink_mode: bool, sink_step: int = 1, rank_size: int = 1, rank_id: int = 0, shuffle=True):
|
||||
"""
|
||||
Load dataset.
|
||||
|
||||
Args:
|
||||
data_files (list): Data files.
|
||||
batch_size (int): Batch size.
|
||||
epoch_count (int): Epoch count.
|
||||
sink_mode (bool): Whether enable sink mode.
|
||||
sink_step (int): Step to sink.
|
||||
rank_size (int): Rank size.
|
||||
rank_id (int): Rank id.
|
||||
shuffle (bool): Whether shuffle dataset.
|
||||
|
||||
Returns:
|
||||
Dataset, dataset instance.
|
||||
"""
|
||||
return _load_dataset(data_files, batch_size, epoch_count, sink_mode,
|
||||
sink_step, rank_size, rank_id, shuffle=shuffle)
|
||||
|
|
@ -0,0 +1,109 @@
|
|||
# Copyright 2020 Huawei Technologies Co., Ltd
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
# ============================================================================
|
||||
"""Mono data loader."""
|
||||
import numpy as np
|
||||
|
||||
from src.utils import Dictionary
|
||||
|
||||
from .base import DataLoader
|
||||
from .schema import SCHEMA
|
||||
from ..language_model.base import LanguageModel
|
||||
from ..language_model import LooseMaskedLanguageModel
|
||||
|
||||
|
||||
class MonoLingualDataLoader(DataLoader):
|
||||
"""Loader for monolingual data."""
|
||||
_SCHEMA = SCHEMA
|
||||
|
||||
def __init__(self, src_filepath: str, lang: str, dictionary: Dictionary,
|
||||
language_model: LanguageModel = LooseMaskedLanguageModel(mask_ratio=0.3),
|
||||
max_sen_len=66, min_sen_len=16):
|
||||
super(MonoLingualDataLoader, self).__init__(max_sen_len=max_sen_len)
|
||||
self._file_path = src_filepath
|
||||
self._lang = lang
|
||||
self._dictionary = dictionary
|
||||
self._lm = language_model
|
||||
self.max_sen_len = max_sen_len
|
||||
self.min_sen_len = min_sen_len
|
||||
|
||||
@property
|
||||
def dict(self):
|
||||
return self._dictionary
|
||||
|
||||
def generate_padding_mask(self, sentence, length, exclude_mask=False):
|
||||
"""Generate padding mask vector."""
|
||||
src_padding = np.zeros(shape=self.max_sen_len, dtype=np.int64)
|
||||
if exclude_mask:
|
||||
pos = np.where(sentence == self._dictionary.padding_index)[0]
|
||||
else:
|
||||
pos = np.where((sentence == self._dictionary.padding_index) | (sentence == self._dictionary.mask_index))[0]
|
||||
src_padding[0:length] = 1
|
||||
if pos.shape[0] != 0:
|
||||
src_padding[pos] = 0
|
||||
return src_padding
|
||||
|
||||
def _load(self):
|
||||
_min_len = 9999999999
|
||||
_max_len = 0
|
||||
count = 0
|
||||
with open(self._file_path, "r") as _file:
|
||||
print(f" | Processing corpus {self._file_path}.")
|
||||
for _, _line in enumerate(_file):
|
||||
tokens = [self._dictionary.index(t.replace(" ", ""))
|
||||
for t in _line.strip().split(" ") if t]
|
||||
# In mass code, it doesn't add <BOS> to sen.
|
||||
tokens.append(self._dictionary.eos_index)
|
||||
opt = self._lm.emit(sentence=np.array(tokens, dtype=np.int32),
|
||||
vocabulary=self._dictionary)
|
||||
|
||||
src_len = opt["sentence_length"]
|
||||
_min_len = min(_min_len, opt["sentence_length"], opt["tgt_sen_length"])
|
||||
_max_len = max(_max_len, opt["sentence_length"], opt["tgt_sen_length"])
|
||||
|
||||
if src_len > self.max_sen_len:
|
||||
continue
|
||||
if src_len < self.min_sen_len:
|
||||
continue
|
||||
|
||||
src_padding = self.generate_padding_mask(opt["encoder_input"],
|
||||
opt["sentence_length"],
|
||||
exclude_mask=False)
|
||||
tgt_padding = self.generate_padding_mask(opt["decoder_input"],
|
||||
opt["tgt_sen_length"],
|
||||
exclude_mask=True)
|
||||
|
||||
encoder_input = self.padding(opt["encoder_input"],
|
||||
self._dictionary.padding_index)
|
||||
decoder_input = self.padding(opt["decoder_input"],
|
||||
self._dictionary.padding_index)
|
||||
decoder_output = self.padding(opt["decoder_output"],
|
||||
self._dictionary.padding_index)
|
||||
if encoder_input is None or decoder_input is None or decoder_output is None:
|
||||
continue
|
||||
|
||||
example = {
|
||||
"src": encoder_input,
|
||||
"src_padding": src_padding,
|
||||
"prev_opt": decoder_input,
|
||||
"prev_padding": tgt_padding,
|
||||
"target": decoder_output,
|
||||
"tgt_padding": tgt_padding,
|
||||
}
|
||||
self._add_example(example)
|
||||
count += 1
|
||||
|
||||
print(f" | Shortest len = {_min_len}.")
|
||||
print(f" | Longest len = {_max_len}.")
|
||||
print(f" | Total sen = {count}.")
|
||||
|
|
@ -0,0 +1,24 @@
|
|||
# Copyright 2020 Huawei Technologies Co., Ltd
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
# ============================================================================
|
||||
"""Define schema of mindrecord."""
|
||||
|
||||
SCHEMA = {
|
||||
"src": {"type": "int64", "shape": [-1]},
|
||||
"src_padding": {"type": "int64", "shape": [-1]},
|
||||
"prev_opt": {"type": "int64", "shape": [-1]},
|
||||
"prev_padding": {"type": "int64", "shape": [-1]},
|
||||
"target": {"type": "int64", "shape": [-1]},
|
||||
"tgt_padding": {"type": "int64", "shape": [-1]},
|
||||
}
|
||||
|
|
@ -0,0 +1,26 @@
|
|||
# Copyright 2020 Huawei Technologies Co., Ltd
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
# ============================================================================
|
||||
"""Language model."""
|
||||
from .noise_channel_language_model import NoiseChannelLanguageModel
|
||||
from .masked_language_model import MaskedLanguageModel
|
||||
from .loose_masked_language_model import LooseMaskedLanguageModel
|
||||
from .mass_language_model import MassLanguageModel
|
||||
|
||||
__all__ = [
|
||||
"LooseMaskedLanguageModel",
|
||||
"MassLanguageModel",
|
||||
"MaskedLanguageModel",
|
||||
"NoiseChannelLanguageModel"
|
||||
]
|
||||
|
|
@ -0,0 +1,25 @@
|
|||
# Copyright 2020 Huawei Technologies Co., Ltd
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
# ============================================================================
|
||||
"""Base language model."""
|
||||
|
||||
|
||||
class LanguageModel:
|
||||
"""Define base language model."""
|
||||
|
||||
def __init__(self):
|
||||
pass
|
||||
|
||||
def emit(self, **kwargs):
|
||||
raise NotImplementedError
|
||||
|
|
@ -0,0 +1,130 @@
|
|||
# Copyright 2020 Huawei Technologies Co., Ltd
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
# ============================================================================
|
||||
"""Modified masked language model."""
|
||||
import numpy as np
|
||||
|
||||
from src.utils import Dictionary
|
||||
from .base import LanguageModel
|
||||
|
||||
|
||||
class LooseMaskedLanguageModel(LanguageModel):
|
||||
"""
|
||||
Modified mask operation on sentence.
|
||||
|
||||
If k is assigned, then mask sentence with length k.
|
||||
Otherwise, use mask_ratio.
|
||||
|
||||
Args:
|
||||
k (int): Length of fragment.
|
||||
mask_ratio (float): Mask ratio.
|
||||
"""
|
||||
|
||||
def __init__(self, k: int = None, mask_ratio=0.5,
|
||||
mask_all_prob=None):
|
||||
super(LooseMaskedLanguageModel, self).__init__()
|
||||
self.mask_ratio = mask_ratio
|
||||
self._k = k
|
||||
self._threshold = mask_all_prob
|
||||
|
||||
def emit(self, sentence: np.ndarray, vocabulary: Dictionary):
|
||||
"""
|
||||
Mask mono source sentence.
|
||||
|
||||
A sample used to train model is processed with following step:
|
||||
|
||||
encoder input (source): [x1, x2, x3, x4, x5, x6, x7, x8, </eos>]
|
||||
masked encoder input: [x1, x2, x3, _, _, _, x7, x8, </eos>]
|
||||
decoder input: [ -, x3, x4, x5]
|
||||
| | | |
|
||||
V V V V
|
||||
decoder output: [x3, x4, x5, x6]
|
||||
|
||||
Notes:
|
||||
A simple rule is made that source sentence starts without <BOS>
|
||||
but end with <EOS>.
|
||||
|
||||
Args:
|
||||
vocabulary (Dictionary): Vocabulary.
|
||||
sentence (np.ndarray): Raw sentence instance.
|
||||
|
||||
Returns:
|
||||
dict, an example.
|
||||
"""
|
||||
# If v=0, then u must equal to 0. [u, v)
|
||||
u, v = self._get_masked_interval(sentence.shape[0],
|
||||
self._k, self._threshold)
|
||||
|
||||
encoder_input = sentence.copy()
|
||||
right_shifted_sentence = np.concatenate(([vocabulary.bos_index], sentence[:-1]))
|
||||
|
||||
if u == 0:
|
||||
_len = v - u if v - u != 0 else sentence.shape[0]
|
||||
decoder_input = right_shifted_sentence[:_len]
|
||||
decoder_input[0] = vocabulary.mask_index
|
||||
decoder_output = sentence[:_len].copy()
|
||||
else:
|
||||
decoder_input = right_shifted_sentence[u - 1:v]
|
||||
decoder_input[0] = vocabulary.mask_index
|
||||
decoder_output = sentence[u - 1:v].copy()
|
||||
|
||||
if v == 0:
|
||||
decoder_input[:] = vocabulary.mask_index
|
||||
else:
|
||||
encoder_input[np.arange(start=u, stop=v)] = vocabulary.mask_index
|
||||
|
||||
if u != v and u > 1:
|
||||
padding = np.array([vocabulary.padding_index] * (u - 1), dtype=np.int32)
|
||||
decoder_input = np.concatenate((padding, decoder_input))
|
||||
decoder_output = np.concatenate((padding, decoder_output))
|
||||
|
||||
if decoder_input.shape[0] != decoder_output.shape[0]:
|
||||
raise ValueError("seq len must equal.")
|
||||
|
||||
return {
|
||||
"sentence_length": sentence.shape[0],
|
||||
"tgt_sen_length": decoder_output.shape[0],
|
||||
"encoder_input": encoder_input, # end with </eos>
|
||||
"decoder_input": decoder_input,
|
||||
"decoder_output": decoder_output # end with </eos>
|
||||
}
|
||||
|
||||
def _get_masked_interval(self, length, fix_length=None,
|
||||
threshold_to_mask_all=None):
|
||||
"""
|
||||
Generate a sequence length according to length and mask_ratio.
|
||||
|
||||
Args:
|
||||
length (int): Sequence length.
|
||||
|
||||
Returns:
|
||||
Tuple[int, int], [start position, end position].
|
||||
"""
|
||||
# Can not larger than sequence length.
|
||||
# Mask_length belongs to [0, length].
|
||||
if fix_length is not None:
|
||||
interval_length = min(length, fix_length)
|
||||
else:
|
||||
interval_length = min(length, round(self.mask_ratio * length))
|
||||
|
||||
_magic = np.random.random()
|
||||
if threshold_to_mask_all is not None and _magic <= threshold_to_mask_all:
|
||||
return 0, length
|
||||
|
||||
# If not sequence to be masked, then return 0, 0.
|
||||
if interval_length == 0:
|
||||
return 0, 0
|
||||
# Otherwise, return start position and interval length.
|
||||
start_pos = np.random.randint(low=0, high=length - interval_length + 1)
|
||||
return start_pos, start_pos + interval_length
|
||||
|
|
@ -0,0 +1,128 @@
|
|||
# Copyright 2020 Huawei Technologies Co., Ltd
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
# ============================================================================
|
||||
"""Masked language model."""
|
||||
import numpy as np
|
||||
|
||||
from .base import LanguageModel
|
||||
|
||||
|
||||
class MaskedLanguageModel(LanguageModel):
|
||||
"""
|
||||
Do mask operation on sentence.
|
||||
|
||||
If k is assigned, then mask sentence with length k.
|
||||
Otherwise, use mask_ratio.
|
||||
|
||||
Args:
|
||||
k (int): Length of fragment.
|
||||
mask_ratio (float): Mask ratio.
|
||||
"""
|
||||
|
||||
def __init__(self, k: int = None, mask_ratio=0.5,
|
||||
mask_all_prob=None):
|
||||
super(MaskedLanguageModel, self).__init__()
|
||||
self.mask_ratio = mask_ratio
|
||||
self._k = k
|
||||
self._threshold = mask_all_prob
|
||||
|
||||
def emit(self, sentence: np.ndarray, vocabulary):
|
||||
"""
|
||||
Mask mono source sentence.
|
||||
|
||||
A sample used to train model is processed with following step:
|
||||
|
||||
encoder input (source): [x1, x2, x3, x4, x5, x6, x7, x8, </eos>]
|
||||
masked encoder input: [x1, x2, _, _, _, x6, x7, x8, </eos>]
|
||||
decoder input: [ _, x3, x4]
|
||||
| | |
|
||||
V V V
|
||||
decoder output: [ x3, x4, x5]
|
||||
|
||||
Notes:
|
||||
A simple rule is made that source sentence starts without <BOS>
|
||||
but end with <EOS>.
|
||||
|
||||
Args:
|
||||
vocabulary (Dictionary): Vocabulary.
|
||||
sentence (np.ndarray): Raw sentence instance.
|
||||
|
||||
Returns:
|
||||
dict, an example.
|
||||
"""
|
||||
encoder_input = sentence.copy()
|
||||
seq_len = encoder_input.shape[0]
|
||||
|
||||
# If v=0, then u must equal to 0. [u, v)
|
||||
u, v = self._get_masked_interval(len(encoder_input),
|
||||
self._k, self._threshold)
|
||||
|
||||
if u == 0:
|
||||
_len = v - u if v - u != 0 else seq_len
|
||||
decoder_input = np.array([vocabulary.mask_index] * _len, dtype=np.int32)
|
||||
decoder_input[1:] = encoder_input[:_len - 1].copy()
|
||||
else:
|
||||
decoder_input = np.array([vocabulary.mask_index] * (v - u), dtype=np.int32)
|
||||
decoder_input[1:] = encoder_input[u:v - 1].copy()
|
||||
|
||||
if v == 0:
|
||||
decoder_output = encoder_input.copy()
|
||||
encoder_input[:] = vocabulary.mask_index
|
||||
else:
|
||||
decoder_output = encoder_input[u:v].copy()
|
||||
encoder_input[np.arange(start=u, stop=v)] = vocabulary.mask_index
|
||||
|
||||
if u != v and u > 0:
|
||||
padding = np.array([vocabulary.padding_index] * u, dtype=np.int32)
|
||||
decoder_input = np.concatenate((padding, decoder_input))
|
||||
decoder_output = np.concatenate((padding, decoder_output))
|
||||
|
||||
assert decoder_input.shape[0] == decoder_output.shape[0], "seq len must equal."
|
||||
|
||||
return {
|
||||
"sentence_length": seq_len,
|
||||
"tgt_sen_length": decoder_output.shape[0],
|
||||
"encoder_input": encoder_input, # end with </eos>
|
||||
"decoder_input": decoder_input,
|
||||
"decoder_output": decoder_output # end with </eos>
|
||||
}
|
||||
|
||||
def _get_masked_interval(self, length, fix_length=None,
|
||||
threshold_to_mask_all=None):
|
||||
"""
|
||||
Generate a sequence length according to length and mask_ratio.
|
||||
|
||||
Args:
|
||||
length (int): Sequence length.
|
||||
|
||||
Returns:
|
||||
Tuple[int, int], [start position, end position].
|
||||
"""
|
||||
# Can not larger than sequence length.
|
||||
# Mask_length belongs to [0, length].
|
||||
if fix_length is not None:
|
||||
interval_length = min(length, fix_length)
|
||||
else:
|
||||
interval_length = min(length, round(self.mask_ratio * length))
|
||||
|
||||
_magic = np.random.random()
|
||||
if threshold_to_mask_all is not None and _magic <= threshold_to_mask_all:
|
||||
return 0, length
|
||||
|
||||
# If not sequence to be masked, then return 0, 0.
|
||||
if interval_length == 0:
|
||||
return 0, 0
|
||||
# Otherwise, return start position and interval length.
|
||||
start_pos = np.random.randint(low=0, high=length - interval_length + 1)
|
||||
return start_pos, start_pos + interval_length
|
||||
|
|
@ -0,0 +1,202 @@
|
|||
# Copyright 2020 Huawei Technologies Co., Ltd
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
# ============================================================================
|
||||
"""Masked language model."""
|
||||
import numpy as np
|
||||
|
||||
from .base import LanguageModel
|
||||
|
||||
|
||||
class MassLanguageModel(LanguageModel):
|
||||
"""
|
||||
Do mask operation on sentence.
|
||||
|
||||
If k is assigned, then mask sentence with length k.
|
||||
Otherwise, use mask_ratio.
|
||||
|
||||
In mass paper, mask_ratio:keep_ratio:random_ratio=8:1:1,
|
||||
fragment_ratio=0.5.
|
||||
|
||||
Args:
|
||||
fragment_ratio (float): Masked length of fragment.
|
||||
mask_ratio (float): Total mask ratio.
|
||||
keep_ratio (float): Keep ratio.
|
||||
random_ratio (float): Random replacement ratio.
|
||||
mask_all_prob (float): Mask all ratio.
|
||||
"""
|
||||
|
||||
def __init__(self, fragment_ratio: float = 0.5,
|
||||
mask_ratio: float = 0.8,
|
||||
keep_ratio: float = 0.1,
|
||||
random_ratio: float = 0.1,
|
||||
mask_all_prob=None):
|
||||
if mask_ratio + keep_ratio + random_ratio > 1:
|
||||
raise ValueError("The sum of `mask_ratio`, `keep_ratio` and `random_ratio` must less or equal to 1.")
|
||||
|
||||
super(MassLanguageModel, self).__init__()
|
||||
self.fragment_ratio = fragment_ratio
|
||||
self.keep_ratio = keep_ratio
|
||||
self.random_ratio = random_ratio
|
||||
self._threshold = mask_all_prob
|
||||
|
||||
def emit(self, sentence: np.ndarray, vocabulary):
|
||||
"""
|
||||
Mask mono source sentence.
|
||||
|
||||
A sample used to train model is processed with following step:
|
||||
|
||||
encoder input (source): [x1, x2, x3, x4, x5, x6, x7, x8, </eos>]
|
||||
masked encoder input: [x1, x2, _, _, _, x6, x7, x8, </eos>]
|
||||
decoder input: [ _, x3, x4]
|
||||
| | |
|
||||
V V V
|
||||
decoder output: [ x3, x4, x5]
|
||||
|
||||
Notes:
|
||||
A simple rule is made that source sentence starts without <BOS>
|
||||
but end with <EOS>.
|
||||
|
||||
Args:
|
||||
vocabulary (Dictionary): Vocabulary.
|
||||
sentence (np.ndarray): Raw sentence instance.
|
||||
|
||||
Returns:
|
||||
dict, an example.
|
||||
"""
|
||||
encoder_input = sentence.copy()
|
||||
seq_len = encoder_input.shape[0]
|
||||
|
||||
# If v=0, then u must equal to 0. [u, v)
|
||||
u, v = self._get_masked_interval(
|
||||
len(encoder_input),
|
||||
threshold_to_mask_all=self._threshold
|
||||
)
|
||||
|
||||
if u == 0:
|
||||
_len = v - u if v - u != 0 else seq_len
|
||||
decoder_input = np.array([vocabulary.mask_index] * _len, dtype=np.int32)
|
||||
decoder_input[1:] = encoder_input[:_len - 1].copy()
|
||||
else:
|
||||
decoder_input = np.array([vocabulary.mask_index] * (v - u), dtype=np.int32)
|
||||
decoder_input[1:] = encoder_input[u:v - 1].copy()
|
||||
|
||||
if v == 0:
|
||||
decoder_output = encoder_input.copy()
|
||||
encoder_input[:] = vocabulary.mask_index
|
||||
else:
|
||||
decoder_output = encoder_input[u:v].copy()
|
||||
encoder_input[np.arange(start=u, stop=v)] = vocabulary.mask_index
|
||||
|
||||
if u != v and u > 0:
|
||||
padding = np.array([vocabulary.padding_index] * u, dtype=np.int32)
|
||||
decoder_input = np.concatenate((padding, decoder_input))
|
||||
decoder_output = np.concatenate((padding, decoder_output))
|
||||
|
||||
assert decoder_input.shape[0] == decoder_output.shape[0], "seq len must equal."
|
||||
|
||||
# Get masked tokens positions.
|
||||
src_idx = np.where(encoder_input == vocabulary.mask_index)[0]
|
||||
if src_idx.shape[0] != 0:
|
||||
encoder_input = self._replace(encoder_input.copy(),
|
||||
replacement=sentence,
|
||||
position=src_idx,
|
||||
vocabulary=vocabulary,
|
||||
repl_prob=self.keep_ratio,
|
||||
random_prob=self.random_ratio)
|
||||
|
||||
prev_opt_idx = np.where(decoder_input != vocabulary.padding_index)[0]
|
||||
if prev_opt_idx.shape[0] != 0:
|
||||
decoder_input = self._replace(decoder_input.copy(),
|
||||
replacement=vocabulary.mask_index,
|
||||
position=prev_opt_idx,
|
||||
vocabulary=vocabulary,
|
||||
repl_prob=self.keep_ratio,
|
||||
random_prob=self.random_ratio)
|
||||
|
||||
return {
|
||||
"sentence_length": seq_len,
|
||||
"tgt_sen_length": decoder_output.shape[0],
|
||||
"encoder_input": encoder_input, # end with </eos>
|
||||
"decoder_input": decoder_input,
|
||||
"decoder_output": decoder_output # end with </eos>
|
||||
}
|
||||
|
||||
@staticmethod
|
||||
def _replace(sentence, replacement, position, vocabulary, repl_prob, random_prob):
|
||||
"""
|
||||
Do replacement randomly according to mass paper.
|
||||
|
||||
Args:
|
||||
sentence (np.ndarray): Sentence.
|
||||
replacement (Union[int, np.ndarray]): Replacement char.
|
||||
position (np.ndarray): Position to be replaced.
|
||||
vocabulary (Dictionary): Vocabulary.
|
||||
repl_prob (float): Replace to mask prob.
|
||||
random_prob (float): Replace randomly prob.
|
||||
|
||||
Returns:
|
||||
np.ndarray, a sentence.
|
||||
"""
|
||||
_probs = [repl_prob, random_prob]
|
||||
_repl_len, _random_len = np.floor(
|
||||
np.array(_probs) * position.shape[0]
|
||||
).astype(np.int32)
|
||||
|
||||
if _repl_len + _random_len >= position.shape[0]:
|
||||
return sentence
|
||||
|
||||
if 0 < _repl_len < position.shape[0]:
|
||||
_repl_idx = np.random.choice(a=position, size=_repl_len, replace=False)
|
||||
if isinstance(replacement, np.ndarray):
|
||||
sentence[_repl_idx] = replacement[_repl_idx]
|
||||
else:
|
||||
sentence[_repl_idx] = replacement
|
||||
|
||||
if 0 < _random_len < position.shape[0]:
|
||||
_random_idx = np.random.choice(a=position, size=_random_len, replace=False)
|
||||
sentence[_random_idx] = np.random.randint(
|
||||
low=5, high=vocabulary.size,
|
||||
size=_random_idx.shape[0], dtype=np.int32
|
||||
)
|
||||
|
||||
return sentence
|
||||
|
||||
def _get_masked_interval(self, length, fix_length=None,
|
||||
threshold_to_mask_all=None):
|
||||
"""
|
||||
Generate a sequence length according to length and mask_ratio.
|
||||
|
||||
Args:
|
||||
length (int): Sequence length.
|
||||
|
||||
Returns:
|
||||
Tuple[int, int], [start position, end position].
|
||||
"""
|
||||
# Can not larger than sequence length.
|
||||
# Mask_length belongs to [0, length].
|
||||
if fix_length is not None:
|
||||
interval_length = min(length, fix_length)
|
||||
else:
|
||||
interval_length = min(length, round(self.fragment_ratio * length))
|
||||
|
||||
_magic = np.random.random()
|
||||
if threshold_to_mask_all is not None and _magic <= threshold_to_mask_all:
|
||||
return 0, length
|
||||
|
||||
# If not sequence to be masked, then return 0, 0.
|
||||
if interval_length == 0:
|
||||
return 0, 0
|
||||
# Otherwise, return start position and interval length.
|
||||
start_pos = np.random.randint(low=0, high=length - interval_length + 1)
|
||||
return start_pos, start_pos + interval_length
|
||||
|
|
@ -0,0 +1,72 @@
|
|||
# Copyright 2020 Huawei Technologies Co., Ltd
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
# ============================================================================
|
||||
"""Noise channel language model."""
|
||||
import numpy as np
|
||||
|
||||
from .base import LanguageModel
|
||||
|
||||
|
||||
class NoiseChannelLanguageModel(LanguageModel):
|
||||
"""Do mask on bilingual data."""
|
||||
|
||||
def __init__(self, add_noise_prob: float = 0.1):
|
||||
super(NoiseChannelLanguageModel, self).__init__()
|
||||
self._noisy_prob = add_noise_prob
|
||||
|
||||
def emit(self, sentence: np.ndarray, target: np.ndarray,
|
||||
mask_symbol_idx: int,
|
||||
bos_symbol_idx: int):
|
||||
"""
|
||||
Add noise to sentence randomly.
|
||||
|
||||
For example, given a sentence pair:
|
||||
source sentence: [x1, x2, x3, x4, x5, x6, </eos>]
|
||||
target sentence: [y1, y2, y3, y4, </eos>]
|
||||
|
||||
After do random mask, data is looked like:
|
||||
encoder input (source): [x1, x2, _, x4, x5, _, </eos>]
|
||||
decoder input: [<bos>, y1, y2, y3, y4]
|
||||
| | | | |
|
||||
V V V V V
|
||||
decoder output: [ y1, y2, y3, y4, </eos>]
|
||||
|
||||
Args:
|
||||
sentence (np.ndarray): Raw sentence.
|
||||
target (np.ndarray): Target output (prediction).
|
||||
mask_symbol_idx (int): Index of MASK symbol.
|
||||
bos_symbol_idx (int): Index of bos symbol.
|
||||
|
||||
Returns:
|
||||
dict, an example.
|
||||
"""
|
||||
encoder_input = sentence.copy()
|
||||
tgt_seq_len = target.shape[0]
|
||||
|
||||
for i, _ in enumerate(encoder_input):
|
||||
_prob = np.random.random()
|
||||
if _prob < self._noisy_prob:
|
||||
encoder_input[i] = mask_symbol_idx
|
||||
|
||||
decoder_input = np.empty(shape=tgt_seq_len, dtype=np.int64)
|
||||
decoder_input[1:] = target[:-1]
|
||||
decoder_input[0] = bos_symbol_idx
|
||||
|
||||
return {
|
||||
"sentence_length": encoder_input.shape[0],
|
||||
"tgt_sen_length": tgt_seq_len,
|
||||
"encoder_input": encoder_input, # end with </eos>
|
||||
"decoder_input": decoder_input, # start with <bos>
|
||||
"decoder_output": target # end with </eos>
|
||||
}
|
||||
|
|
@ -0,0 +1,34 @@
|
|||
# Copyright 2020 Huawei Technologies Co., Ltd
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
# ============================================================================
|
||||
"""Transformer model module."""
|
||||
from .transformer import Transformer
|
||||
from .encoder import TransformerEncoder
|
||||
from .decoder import TransformerDecoder
|
||||
from .beam_search import BeamSearchDecoder
|
||||
from .transformer_for_train import TransformerTraining, LabelSmoothedCrossEntropyCriterion, \
|
||||
TransformerNetworkWithLoss, TransformerTrainOneStepWithLossScaleCell
|
||||
from .infer_mass import infer
|
||||
|
||||
__all__ = [
|
||||
"infer",
|
||||
"TransformerTraining",
|
||||
"LabelSmoothedCrossEntropyCriterion",
|
||||
"TransformerTrainOneStepWithLossScaleCell",
|
||||
"TransformerNetworkWithLoss",
|
||||
"Transformer",
|
||||
"TransformerEncoder",
|
||||
"TransformerDecoder",
|
||||
"BeamSearchDecoder"
|
||||
]
|
||||
|
|
@ -0,0 +1,363 @@
|
|||
# Copyright 2020 Huawei Technologies Co., Ltd
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
# ============================================================================
|
||||
"""Beam search decoder."""
|
||||
import numpy as np
|
||||
|
||||
import mindspore.common.dtype as mstype
|
||||
import mindspore.nn as nn
|
||||
from mindspore.ops import operations as P
|
||||
from mindspore.common.tensor import Tensor
|
||||
|
||||
INF = 1. * 1e9
|
||||
|
||||
|
||||
class LengthPenalty(nn.Cell):
|
||||
"""
|
||||
Length penalty.
|
||||
|
||||
Args:
|
||||
weight (float): The length penalty weight.
|
||||
compute_type (mstype): Mindspore data type. Default: mstype.float32.
|
||||
"""
|
||||
|
||||
def __init__(self, weight=1.0, compute_type=mstype.float32):
|
||||
super(LengthPenalty, self).__init__()
|
||||
self.weight = weight
|
||||
|
||||
self.add = P.TensorAdd()
|
||||
self.pow = P.Pow()
|
||||
self.div = P.RealDiv()
|
||||
|
||||
self.five = Tensor(5.0, mstype.float32)
|
||||
self.six = Tensor(6.0, mstype.float32)
|
||||
|
||||
self.cast = P.Cast()
|
||||
|
||||
def construct(self, length_tensor):
|
||||
"""
|
||||
Process source sentence
|
||||
|
||||
Inputs:
|
||||
length_tensor (Tensor): the input tensor.
|
||||
|
||||
Returns:
|
||||
Tensor, after punishment of length.
|
||||
"""
|
||||
length_tensor = self.cast(length_tensor, mstype.float32)
|
||||
output = self.add(length_tensor, self.five)
|
||||
output = self.div(output, self.six)
|
||||
output = self.pow(output, self.weight)
|
||||
return output
|
||||
|
||||
|
||||
class TileBeam(nn.Cell):
|
||||
"""
|
||||
Beam Tile operation.
|
||||
|
||||
Args:
|
||||
beam_width (int): The Number of beam.
|
||||
compute_type (mstype): Mindspore data type. Default: mstype.float32.
|
||||
"""
|
||||
|
||||
def __init__(self, beam_width, compute_type=mstype.float32):
|
||||
super(TileBeam, self).__init__()
|
||||
self.beam_width = beam_width
|
||||
|
||||
self.expand = P.ExpandDims()
|
||||
self.tile = P.Tile()
|
||||
self.reshape = P.Reshape()
|
||||
self.shape = P.Shape()
|
||||
|
||||
def construct(self, input_tensor):
|
||||
"""
|
||||
Process source sentence
|
||||
|
||||
Inputs:
|
||||
input_tensor (Tensor): with shape (N, T, D).
|
||||
|
||||
Returns:
|
||||
Tensor, tiled tensor.
|
||||
"""
|
||||
shape = self.shape(input_tensor)
|
||||
# add an dim
|
||||
input_tensor = self.expand(input_tensor, 1)
|
||||
# get tile shape: [1, beam, ...]
|
||||
# shape = self.shape(input_tensor)
|
||||
tile_shape = (1,) + (self.beam_width,)
|
||||
for _ in range(len(shape) - 1):
|
||||
tile_shape = tile_shape + (1,)
|
||||
# tile
|
||||
output = self.tile(input_tensor, tile_shape)
|
||||
# reshape to [batch*beam, ...]
|
||||
out_shape = (shape[0] * self.beam_width,) + shape[1:]
|
||||
output = self.reshape(output, out_shape)
|
||||
|
||||
return output
|
||||
|
||||
|
||||
class Mod(nn.Cell):
|
||||
"""
|
||||
Mod operation.
|
||||
|
||||
Args:
|
||||
compute_type (mstype): Mindspore data type. Default: mstype.float32.
|
||||
"""
|
||||
|
||||
def __init__(self,
|
||||
compute_type=mstype.float32):
|
||||
super(Mod, self).__init__()
|
||||
self.compute_type = compute_type
|
||||
|
||||
self.floor_div = P.FloorDiv()
|
||||
self.sub = P.Sub()
|
||||
self.multiply = P.Mul()
|
||||
|
||||
def construct(self, input_x, input_y):
|
||||
"""
|
||||
Get the remainder of input_x and input_y.
|
||||
|
||||
Inputs:
|
||||
input_x (Tensor): Divisor.
|
||||
input_y (Tensor): Dividend.
|
||||
|
||||
Returns:
|
||||
Tensor, remainder.
|
||||
"""
|
||||
x = self.floor_div(input_x, input_y)
|
||||
x = self.multiply(x, input_y)
|
||||
x = self.sub(input_x, x)
|
||||
return x
|
||||
|
||||
|
||||
class BeamSearchDecoder(nn.Cell):
|
||||
"""
|
||||
Beam search decoder.
|
||||
|
||||
Args:
|
||||
batch_size (int): Batch size of input dataset.
|
||||
seq_length (int): Length of input sequence.
|
||||
vocab_size (int): The shape of each embedding vector.
|
||||
decoder (Cell): The transformrer decoder.
|
||||
beam_width (int): Beam width for beam search in inferring. Default: 4.
|
||||
length_penalty_weight (float): Penalty for sentence length. Default: 1.0.
|
||||
max_decode_length (int): Max decode length for inferring. Default: 64.
|
||||
sos_id (int): The index of start label <SOS>. Default: 1.
|
||||
eos_id (int): The index of end label <EOS>. Default: 2.
|
||||
compute_type (mstype): Compute type in TransformerAttention.
|
||||
Default: mstype.float32.
|
||||
"""
|
||||
|
||||
def __init__(self,
|
||||
batch_size,
|
||||
seq_length,
|
||||
vocab_size,
|
||||
decoder,
|
||||
beam_width=4,
|
||||
length_penalty_weight=1.0,
|
||||
max_decode_length=64,
|
||||
sos_id=1,
|
||||
eos_id=2):
|
||||
super(BeamSearchDecoder, self).__init__(auto_prefix=False)
|
||||
|
||||
self.batch_size = batch_size
|
||||
self.vocab_size = vocab_size
|
||||
self.beam_width = beam_width
|
||||
self.length_penalty_weight = length_penalty_weight
|
||||
self.max_decode_length = max_decode_length
|
||||
|
||||
self.decoder = decoder
|
||||
|
||||
self.add = P.TensorAdd()
|
||||
self.expand = P.ExpandDims()
|
||||
self.reshape = P.Reshape()
|
||||
self.shape_flat = (-1,)
|
||||
self.shape = P.Shape()
|
||||
|
||||
self.zero_tensor = Tensor(np.zeros([batch_size, beam_width]), mstype.float32)
|
||||
self.ninf_tensor = Tensor(np.full([batch_size, beam_width], -INF), mstype.float32)
|
||||
|
||||
self.select = P.Select()
|
||||
self.flat_shape = (batch_size, beam_width * vocab_size)
|
||||
self.topk = P.TopK(sorted=True)
|
||||
self.floor_div = P.FloorDiv()
|
||||
self.vocab_size_tensor = Tensor(self.vocab_size, mstype.int32)
|
||||
self.real_div = P.RealDiv()
|
||||
self.mod = Mod()
|
||||
self.equal = P.Equal()
|
||||
self.eos_ids = Tensor(np.full([batch_size, beam_width], eos_id), mstype.int32)
|
||||
|
||||
beam_ids = np.tile(np.arange(beam_width).reshape((1, beam_width)), [batch_size, 1])
|
||||
self.beam_ids = Tensor(beam_ids, mstype.int32)
|
||||
|
||||
batch_ids = np.arange(batch_size * beam_width).reshape((batch_size, beam_width)) // beam_width
|
||||
self.batch_ids = Tensor(batch_ids, mstype.int32)
|
||||
|
||||
self.concat = P.Concat(axis=-1)
|
||||
self.gather_nd = P.GatherNd()
|
||||
|
||||
# init inputs and states
|
||||
self.start_ids = Tensor(np.full([batch_size * beam_width, 1], sos_id), mstype.int32)
|
||||
self.init_seq = Tensor(np.full([batch_size, beam_width, 1], sos_id), mstype.int32)
|
||||
|
||||
init_scores = np.tile(np.array([[0.] + [-INF] * (beam_width - 1)]), [batch_size, 1])
|
||||
|
||||
self.init_total_log_probs = Tensor(np.zeros([batch_size, beam_width, 1]), mstype.float32)
|
||||
self.init_scores = Tensor(init_scores, mstype.float32)
|
||||
|
||||
self.init_attention = Tensor(np.zeros([batch_size, beam_width, seq_length, 1]), mstype.float32)
|
||||
self.init_finished = Tensor(np.zeros([batch_size, beam_width], dtype=np.bool))
|
||||
self.init_length = Tensor(np.zeros([batch_size, beam_width], dtype=np.int32))
|
||||
|
||||
self.length_penalty = LengthPenalty(weight=length_penalty_weight)
|
||||
|
||||
self.one = Tensor(1, mstype.int32)
|
||||
self.prob_concat = P.Concat(axis=1)
|
||||
|
||||
def one_step(self, cur_input_ids, enc_states, enc_attention_mask, state_log_probs, state_seq, state_finished,
|
||||
state_length, entire_log_probs):
|
||||
"""
|
||||
Beam search one_step output.
|
||||
|
||||
Inputs:
|
||||
cur_input_ids (Tensor): with shape (batch_size * beam_width, m).
|
||||
enc_states (Tensor): with shape (batch_size * beam_width, T, D).
|
||||
enc_attention_mask (Tensor): with shape (batch_size * beam_width, T, D).
|
||||
state_log_probs (Tensor): with shape (batch_size, beam_width).
|
||||
state_seq (Tensor): with shape (batch_size, beam_width, m).
|
||||
state_finished (Tensor): with shape (batch_size, beam_width).
|
||||
state_length (Tensor): with shape (batch_size, beam_width).
|
||||
entire_log_probs (Tensor): with shape (batch_size, beam_width, vocab_size).
|
||||
|
||||
Return:
|
||||
Update input parameters.
|
||||
"""
|
||||
# log_probs, [batch_size * beam_width, 1, V]
|
||||
log_probs = self.decoder(cur_input_ids, enc_states, enc_attention_mask)
|
||||
# log_probs: [batch_size, beam_width, V]
|
||||
log_probs = self.reshape(log_probs, (self.batch_size, self.beam_width, self.vocab_size))
|
||||
|
||||
# select topk indices, [batch_size, beam_width, V]
|
||||
total_log_probs = self.add(log_probs, self.expand(state_log_probs, -1))
|
||||
|
||||
# mask finished beams, [batch_size, beam_width]
|
||||
# t-1 has finished
|
||||
mask_tensor = self.select(state_finished, self.ninf_tensor, self.zero_tensor)
|
||||
# save the t-1 probability
|
||||
total_log_probs = self.add(total_log_probs, self.expand(mask_tensor, -1))
|
||||
# [batch, beam*vocab]
|
||||
flat_scores = self.reshape(total_log_probs, self.flat_shape)
|
||||
# select topk, [batch, beam]
|
||||
topk_scores, topk_indices = self.topk(flat_scores, self.beam_width)
|
||||
|
||||
# convert to beam and word indices, [batch, beam]
|
||||
beam_indices = self.floor_div(topk_indices, self.vocab_size_tensor)
|
||||
word_indices = self.mod(topk_indices, self.vocab_size_tensor)
|
||||
|
||||
current_word_pro = self.gather_nd(
|
||||
log_probs,
|
||||
self.concat((self.expand(self.batch_ids, -1),
|
||||
self.expand(beam_indices, -1),
|
||||
self.expand(word_indices, -1)))
|
||||
)
|
||||
# [batch, beam]
|
||||
current_word_pro = self.reshape(current_word_pro, (self.batch_size, self.beam_width))
|
||||
|
||||
# mask finished indices, [batch, beam]
|
||||
beam_indices = self.select(state_finished, self.beam_ids, beam_indices)
|
||||
word_indices = self.select(state_finished, self.eos_ids, word_indices)
|
||||
topk_scores = self.select(state_finished, state_log_probs, topk_scores)
|
||||
|
||||
current_word_pro = self.select(state_finished, self.ninf_tensor, current_word_pro)
|
||||
|
||||
# sort according to scores with -inf for finished beams, [batch, beam]
|
||||
# t ends
|
||||
tmp_log_probs = self.select(
|
||||
self.equal(word_indices, self.eos_ids),
|
||||
self.ninf_tensor,
|
||||
topk_scores)
|
||||
|
||||
_, tmp_indices = self.topk(tmp_log_probs, self.beam_width)
|
||||
# update, [batch_size, beam_width, 2]
|
||||
tmp_gather_indices = self.concat((self.expand(self.batch_ids, -1), self.expand(tmp_indices, -1)))
|
||||
# [batch_size, beam_width]
|
||||
beam_indices = self.gather_nd(beam_indices, tmp_gather_indices)
|
||||
word_indices = self.gather_nd(word_indices, tmp_gather_indices)
|
||||
topk_scores = self.gather_nd(topk_scores, tmp_gather_indices)
|
||||
# [batch_size, beam_width]
|
||||
sorted_current_word_pro = self.gather_nd(current_word_pro, tmp_gather_indices)
|
||||
|
||||
# gather indices for selecting alive beams
|
||||
gather_indices = self.concat((self.expand(self.batch_ids, -1), self.expand(beam_indices, -1)))
|
||||
|
||||
# length add 1 if not finished in the previous step, [batch_size, beam_width]
|
||||
length_add = self.add(state_length, self.one)
|
||||
state_length = self.select(state_finished, state_length, length_add)
|
||||
state_length = self.gather_nd(state_length, gather_indices)
|
||||
|
||||
# concat seq
|
||||
seq = self.gather_nd(state_seq, gather_indices)
|
||||
state_seq = self.concat((seq, self.expand(word_indices, -1)))
|
||||
# update the probability of entire_log_probs
|
||||
selected_entire_log_probs = self.gather_nd(entire_log_probs, gather_indices)
|
||||
entire_log_probs = self.concat((selected_entire_log_probs,
|
||||
self.expand(sorted_current_word_pro, -1)))
|
||||
|
||||
# new finished flag and log_probs
|
||||
state_finished = self.equal(word_indices, self.eos_ids)
|
||||
state_log_probs = topk_scores
|
||||
cur_input_ids = self.reshape(state_seq, (self.batch_size * self.beam_width, -1))
|
||||
|
||||
return cur_input_ids, state_log_probs, state_seq, state_finished, state_length, entire_log_probs
|
||||
|
||||
def construct(self, enc_states, enc_attention_mask):
|
||||
"""
|
||||
Process source sentence
|
||||
|
||||
Inputs:
|
||||
enc_states (Tensor): Output of transformer encoder with shape (N, T, D).
|
||||
enc_attention_mask (Tensor): encoder attention mask with shape (N, T, T).
|
||||
|
||||
Returns:
|
||||
Tensor, predictions output and prediction probs.
|
||||
"""
|
||||
cur_input_ids = self.start_ids
|
||||
# beam search states
|
||||
state_log_probs = self.init_scores
|
||||
state_seq = self.init_seq
|
||||
state_finished = self.init_finished
|
||||
state_length = self.init_length
|
||||
entire_log_probs = self.init_total_log_probs
|
||||
|
||||
for _ in range(self.max_decode_length):
|
||||
# run one step decoder to get outputs of the current step
|
||||
# shape [batch*beam, 1, vocab]
|
||||
cur_input_ids, state_log_probs, state_seq, state_finished, state_length, entire_log_probs = self.one_step(
|
||||
cur_input_ids, enc_states, enc_attention_mask, state_log_probs,
|
||||
state_seq, state_finished, state_length, entire_log_probs)
|
||||
|
||||
# add length penalty scores
|
||||
penalty_len = self.length_penalty(state_length)
|
||||
# return penalty_len
|
||||
log_probs = self.real_div(state_log_probs, penalty_len)
|
||||
|
||||
# sort according to scores
|
||||
_, top_beam_indices = self.topk(log_probs, self.beam_width)
|
||||
gather_indices = self.concat((self.expand(self.batch_ids, -1), self.expand(top_beam_indices, -1)))
|
||||
# sort sequence and attention scores
|
||||
predicted_ids = self.gather_nd(state_seq, gather_indices)
|
||||
# take the first one
|
||||
predicted_ids = predicted_ids[::, 0:1:1, ::]
|
||||
|
||||
return predicted_ids, entire_log_probs
|
||||
|
|
@ -0,0 +1,66 @@
|
|||
# Copyright 2020 Huawei Technologies Co., Ltd
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
# ============================================================================
|
||||
"""Components of model."""
|
||||
import mindspore.common.dtype as mstype
|
||||
import mindspore.nn as nn
|
||||
from mindspore.ops import operations as P
|
||||
|
||||
|
||||
class SaturateCast(nn.Cell):
|
||||
"""Cast wrapper."""
|
||||
|
||||
def __init__(self, dst_type=mstype.float32):
|
||||
super(SaturateCast, self).__init__()
|
||||
self.cast = P.Cast()
|
||||
self.dst_type = dst_type
|
||||
|
||||
def construct(self, x):
|
||||
return self.cast(x, self.dst_type)
|
||||
|
||||
|
||||
class LayerNorm(nn.Cell):
|
||||
"""
|
||||
Do layer norm.
|
||||
|
||||
Args:
|
||||
in_channels (int): In channels number of layer norm.
|
||||
return_2d (bool): Whether return 2d tensor.
|
||||
|
||||
Returns:
|
||||
Tensor, output.
|
||||
"""
|
||||
|
||||
def __init__(self, in_channels=None, return_2d=False):
|
||||
super(LayerNorm, self).__init__()
|
||||
self.return_2d = return_2d
|
||||
self.layer_norm = nn.LayerNorm((in_channels,))
|
||||
self.cast = P.Cast()
|
||||
self.get_dtype = P.DType()
|
||||
self.reshape = P.Reshape()
|
||||
self.get_shape = P.Shape()
|
||||
|
||||
def construct(self, input_tensor):
|
||||
shape = self.get_shape(input_tensor)
|
||||
batch_size = shape[0]
|
||||
max_len = shape[1]
|
||||
embed_dim = shape[2]
|
||||
|
||||
output = self.reshape(input_tensor, (-1, embed_dim))
|
||||
output = self.cast(output, mstype.float32)
|
||||
output = self.layer_norm(output)
|
||||
output = self.cast(output, self.get_dtype(input_tensor))
|
||||
if not self.return_2d:
|
||||
output = self.reshape(output, (batch_size, max_len, embed_dim))
|
||||
return output
|
||||
|
|
@ -0,0 +1,76 @@
|
|||
# Copyright 2020 Huawei Technologies Co., Ltd
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
# ============================================================================
|
||||
"""Create mask matrix for inputs."""
|
||||
import numpy as np
|
||||
import mindspore.common.dtype as mstype
|
||||
from mindspore import nn
|
||||
from mindspore.ops import operations as P
|
||||
from mindspore.common.tensor import Tensor
|
||||
|
||||
|
||||
class CreateAttentionMaskFromInputMask(nn.Cell):
|
||||
"""
|
||||
Create attention mask according to input mask.
|
||||
|
||||
Args:
|
||||
config (TransformerConfig): Config class.
|
||||
|
||||
Returns:
|
||||
Tensor, shape of (N, T, T).
|
||||
"""
|
||||
|
||||
def __init__(self, config):
|
||||
super(CreateAttentionMaskFromInputMask, self).__init__()
|
||||
self.input_mask_from_dataset = config.input_mask_from_dataset
|
||||
self.input_mask = None
|
||||
|
||||
assert self.input_mask_from_dataset
|
||||
|
||||
self.cast = P.Cast()
|
||||
self.shape = P.Shape()
|
||||
self.reshape = P.Reshape()
|
||||
self.batch_matmul = P.BatchMatMul()
|
||||
self.multiply = P.Mul()
|
||||
self.shape = P.Shape()
|
||||
# mask future positions
|
||||
ones = np.ones(shape=(config.batch_size, config.seq_length, config.seq_length))
|
||||
self.lower_triangle_mask = Tensor(np.tril(ones), dtype=mstype.float32)
|
||||
|
||||
def construct(self, input_mask, mask_future=False):
|
||||
"""
|
||||
Construct network.
|
||||
|
||||
Args:
|
||||
input_mask (Tensor): Tensor mask vectors with shape (N, T).
|
||||
mask_future (bool): Whether mask future (for decoder training).
|
||||
|
||||
Returns:
|
||||
Tensor, shape of (N, T, T).
|
||||
"""
|
||||
input_shape = self.shape(input_mask)
|
||||
# Add this for infer as the seq_length will increase.
|
||||
shape_right = (input_shape[0], 1, input_shape[1])
|
||||
shape_left = input_shape + (1,)
|
||||
|
||||
input_mask = self.cast(input_mask, mstype.float32)
|
||||
mask_left = self.reshape(input_mask, shape_left)
|
||||
mask_right = self.reshape(input_mask, shape_right)
|
||||
|
||||
attention_mask = self.batch_matmul(mask_left, mask_right)
|
||||
|
||||
if mask_future:
|
||||
attention_mask = self.multiply(attention_mask, self.lower_triangle_mask)
|
||||
|
||||
return attention_mask
|
||||
|
|
@ -0,0 +1,221 @@
|
|||
# Copyright 2020 Huawei Technologies Co., Ltd
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
# ============================================================================
|
||||
"""Decoder of Transformer."""
|
||||
import mindspore.common.dtype as mstype
|
||||
from mindspore import nn
|
||||
|
||||
from .feed_forward_network import FeedForwardNet
|
||||
from .self_attention import SelfAttention
|
||||
from .components import LayerNorm
|
||||
|
||||
|
||||
class DecoderCell(nn.Cell):
|
||||
"""
|
||||
Decoder cells used in Transformer.
|
||||
|
||||
Args:
|
||||
attn_embed_dim (int): Dimensions of attention weight, e.g. Q, K, V.
|
||||
num_attn_heads (int): Attention heads number.
|
||||
intermediate_size (int): Hidden size in FFN.
|
||||
attn_dropout_prob (float): Dropout rate in attention layer. Default: 0.1.
|
||||
initializer_range (float): Initial range. Default: 0.02.
|
||||
dropout_prob (float): Dropout rate between layers. Default: 0.1.
|
||||
hidden_act (str): Activation function in FFN. Default: "relu".
|
||||
compute_type (mstype): Mindspore data type. Default: mstype.float32.
|
||||
|
||||
Returns:
|
||||
Tensor, output with shape (N, T', D).
|
||||
"""
|
||||
|
||||
def __init__(self,
|
||||
attn_embed_dim=768,
|
||||
num_attn_heads=12,
|
||||
intermediate_size=3072,
|
||||
attn_dropout_prob=0.02,
|
||||
initializer_range=0.02,
|
||||
dropout_prob=0.1,
|
||||
hidden_act="relu",
|
||||
compute_type=mstype.float32):
|
||||
super(DecoderCell, self).__init__()
|
||||
self.masked_attn = SelfAttention(
|
||||
attn_embed_dim=attn_embed_dim,
|
||||
num_attn_heads=num_attn_heads,
|
||||
attn_dropout_prob=attn_dropout_prob,
|
||||
initializer_range=initializer_range,
|
||||
dropout_prob=dropout_prob,
|
||||
compute_type=compute_type)
|
||||
self.enc_dec_attn = SelfAttention(
|
||||
attn_embed_dim=attn_embed_dim,
|
||||
num_attn_heads=num_attn_heads,
|
||||
attn_dropout_prob=attn_dropout_prob,
|
||||
initializer_range=initializer_range,
|
||||
dropout_prob=dropout_prob,
|
||||
compute_type=compute_type)
|
||||
self.feed_forward_net = FeedForwardNet(
|
||||
in_channels=attn_embed_dim,
|
||||
hidden_size=intermediate_size,
|
||||
out_channels=attn_embed_dim,
|
||||
hidden_act=hidden_act,
|
||||
initializer_range=initializer_range,
|
||||
hidden_dropout_prob=dropout_prob,
|
||||
compute_type=compute_type)
|
||||
|
||||
def construct(self, queries, attention_mask, encoder_out, enc_attention_mask):
|
||||
"""
|
||||
Construct network.
|
||||
|
||||
Args:
|
||||
queries (Tensor): With shape (N, T', D).
|
||||
attention_mask (Tensor): With shape (N, T', T').
|
||||
encoder_out (Tensor): With shape (N, T, D).
|
||||
enc_attention_mask (Tensor): With shape (N, T, T).
|
||||
|
||||
Returns:
|
||||
Tensor, output.
|
||||
"""
|
||||
attention_output = self.masked_attn(
|
||||
queries, queries, queries,
|
||||
attention_mask
|
||||
)
|
||||
attention_output = self.enc_dec_attn(
|
||||
attention_output, # (N, T', D)
|
||||
encoder_out, encoder_out, # (N, T, D)
|
||||
enc_attention_mask # (N, T, T)
|
||||
)
|
||||
output = self.feed_forward_net(attention_output)
|
||||
return output
|
||||
|
||||
|
||||
class TransformerDecoder(nn.Cell):
|
||||
"""
|
||||
Implements of Transformer decoder.
|
||||
|
||||
Args:
|
||||
attn_embed_dim (int): Dimensions of attention layer.
|
||||
decoder_layers (int): Decoder layers.
|
||||
num_attn_heads (int): Attention heads number.
|
||||
intermediate_size (int): Hidden size of FFN.
|
||||
attn_dropout_prob (float): Dropout rate in attention. Default: 0.1.
|
||||
initializer_range (float): Initial range. Default: 0.02.
|
||||
dropout_prob (float): Dropout rate between layers. Default: 0.1.
|
||||
hidden_act (str): Non-linear activation function in FFN. Default: "relu".
|
||||
compute_type (mstype): Mindspore data type. Default: mstype.float32.
|
||||
|
||||
Returns:
|
||||
Tensor, shape of (N, T', D).
|
||||
"""
|
||||
|
||||
def __init__(self,
|
||||
attn_embed_dim,
|
||||
decoder_layers,
|
||||
num_attn_heads,
|
||||
intermediate_size,
|
||||
attn_dropout_prob=0.1,
|
||||
initializer_range=0.02,
|
||||
dropout_prob=0.1,
|
||||
hidden_act="relu",
|
||||
compute_type=mstype.float32):
|
||||
super(TransformerDecoder, self).__init__()
|
||||
self.num_layers = decoder_layers
|
||||
self.attn_embed_dim = attn_embed_dim
|
||||
|
||||
self.layer0 = DecoderCell(
|
||||
attn_embed_dim=attn_embed_dim,
|
||||
num_attn_heads=num_attn_heads,
|
||||
intermediate_size=intermediate_size,
|
||||
attn_dropout_prob=attn_dropout_prob,
|
||||
initializer_range=initializer_range,
|
||||
dropout_prob=dropout_prob,
|
||||
hidden_act=hidden_act,
|
||||
compute_type=compute_type
|
||||
)
|
||||
self.layer1 = DecoderCell(
|
||||
attn_embed_dim=attn_embed_dim,
|
||||
num_attn_heads=num_attn_heads,
|
||||
intermediate_size=intermediate_size,
|
||||
attn_dropout_prob=attn_dropout_prob,
|
||||
initializer_range=initializer_range,
|
||||
dropout_prob=dropout_prob,
|
||||
hidden_act=hidden_act,
|
||||
compute_type=compute_type
|
||||
)
|
||||
self.layer2 = DecoderCell(
|
||||
attn_embed_dim=attn_embed_dim,
|
||||
num_attn_heads=num_attn_heads,
|
||||
intermediate_size=intermediate_size,
|
||||
attn_dropout_prob=attn_dropout_prob,
|
||||
initializer_range=initializer_range,
|
||||
dropout_prob=dropout_prob,
|
||||
hidden_act=hidden_act,
|
||||
compute_type=compute_type
|
||||
)
|
||||
self.layer3 = DecoderCell(
|
||||
attn_embed_dim=attn_embed_dim,
|
||||
num_attn_heads=num_attn_heads,
|
||||
intermediate_size=intermediate_size,
|
||||
attn_dropout_prob=attn_dropout_prob,
|
||||
initializer_range=initializer_range,
|
||||
dropout_prob=dropout_prob,
|
||||
hidden_act=hidden_act,
|
||||
compute_type=compute_type
|
||||
)
|
||||
self.layer4 = DecoderCell(
|
||||
attn_embed_dim=attn_embed_dim,
|
||||
num_attn_heads=num_attn_heads,
|
||||
intermediate_size=intermediate_size,
|
||||
attn_dropout_prob=attn_dropout_prob,
|
||||
initializer_range=initializer_range,
|
||||
dropout_prob=dropout_prob,
|
||||
hidden_act=hidden_act,
|
||||
compute_type=compute_type
|
||||
)
|
||||
self.layer5 = DecoderCell(
|
||||
attn_embed_dim=attn_embed_dim,
|
||||
num_attn_heads=num_attn_heads,
|
||||
intermediate_size=intermediate_size,
|
||||
attn_dropout_prob=attn_dropout_prob,
|
||||
initializer_range=initializer_range,
|
||||
dropout_prob=dropout_prob,
|
||||
hidden_act=hidden_act,
|
||||
compute_type=compute_type
|
||||
)
|
||||
|
||||
self.layer_preprocess = LayerNorm(in_channels=attn_embed_dim,
|
||||
return_2d=False)
|
||||
|
||||
def construct(self, input_tensor, attention_mask, encoder_out, enc_attention_mask):
|
||||
"""
|
||||
Construct network.
|
||||
|
||||
Args:
|
||||
input_tensor (Tensor): With shape of (N, T', D).
|
||||
attention_mask (Tensor): With shape of (N, T', T').
|
||||
encoder_out (Tensor): With shape of (N, T, D).
|
||||
enc_attention_mask (Tensor): With shape of (N, T, T).
|
||||
|
||||
Returns:
|
||||
Tensor, shape of (N, T', D).
|
||||
"""
|
||||
prev_output = input_tensor
|
||||
prev_output = self.layer0(prev_output, attention_mask, encoder_out, enc_attention_mask)
|
||||
prev_output = self.layer1(prev_output, attention_mask, encoder_out, enc_attention_mask)
|
||||
prev_output = self.layer2(prev_output, attention_mask, encoder_out, enc_attention_mask)
|
||||
prev_output = self.layer3(prev_output, attention_mask, encoder_out, enc_attention_mask)
|
||||
prev_output = self.layer4(prev_output, attention_mask, encoder_out, enc_attention_mask)
|
||||
prev_output = self.layer5(prev_output, attention_mask, encoder_out, enc_attention_mask)
|
||||
|
||||
# Add layer norm, and full connection layer.
|
||||
prev_output = self.layer_preprocess(prev_output)
|
||||
return prev_output
|
||||
|
|
@ -0,0 +1,81 @@
|
|||
# Copyright 2020 Huawei Technologies Co., Ltd
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
# ============================================================================
|
||||
"""Embedding."""
|
||||
import numpy as np
|
||||
import mindspore.common.dtype as mstype
|
||||
from mindspore import nn
|
||||
from mindspore.ops import operations as P
|
||||
from mindspore.common.tensor import Tensor
|
||||
from mindspore.common.parameter import Parameter
|
||||
|
||||
|
||||
class EmbeddingLookup(nn.Cell):
|
||||
"""Embeddings lookup table with a fixed dictionary and size."""
|
||||
|
||||
def __init__(self,
|
||||
vocab_size,
|
||||
embed_dim,
|
||||
use_one_hot_embeddings=False):
|
||||
"""
|
||||
Embeddings lookup table with a fixed dictionary and size.
|
||||
|
||||
Args:
|
||||
vocab_size (int): Size of the dictionary of embeddings.
|
||||
embed_dim (int): The size of word embedding.
|
||||
use_one_hot_embeddings (bool): Whether use one-hot embedding. Default: False.
|
||||
"""
|
||||
super(EmbeddingLookup, self).__init__()
|
||||
self.embedding_dim = embed_dim
|
||||
self.vocab_size = vocab_size
|
||||
self.use_one_hot_embeddings = use_one_hot_embeddings
|
||||
|
||||
init_weight = np.random.normal(0, embed_dim ** -0.5, size=[vocab_size, embed_dim])
|
||||
# 0 is Padding index, thus init it as 0.
|
||||
init_weight[0, :] = 0
|
||||
self.embedding_table = Parameter(Tensor(init_weight),
|
||||
name='embedding_table')
|
||||
self.expand = P.ExpandDims()
|
||||
self.gather = P.GatherV2()
|
||||
self.one_hot = P.OneHot()
|
||||
self.on_value = Tensor(1.0, mstype.float32)
|
||||
self.off_value = Tensor(0.0, mstype.float32)
|
||||
self.array_mul = P.MatMul()
|
||||
self.reshape = P.Reshape()
|
||||
self.get_shape = P.Shape()
|
||||
|
||||
def construct(self, input_ids):
|
||||
"""
|
||||
Construct network.
|
||||
|
||||
Args:
|
||||
input_ids (Tensor): A batch of sentences with shape (N, T).
|
||||
|
||||
Returns:
|
||||
Tensor, word embeddings with shape (N, T, D)
|
||||
"""
|
||||
_shape = self.get_shape(input_ids) # (N, T).
|
||||
_batch_size = _shape[0]
|
||||
_max_len = _shape[1]
|
||||
|
||||
flat_ids = self.reshape(input_ids, (_batch_size * _max_len,))
|
||||
if self.use_one_hot_embeddings:
|
||||
one_hot_ids = self.one_hot(flat_ids, self.vocab_size, self.on_value, self.off_value)
|
||||
output_for_reshape = self.array_mul(
|
||||
one_hot_ids, self.embedding_table)
|
||||
else:
|
||||
output_for_reshape = self.gather(self.embedding_table, flat_ids, 0)
|
||||
|
||||
output = self.reshape(output_for_reshape, (_batch_size, _max_len, self.embedding_dim))
|
||||
return output, self.embedding_table
|
||||
|
|
@ -0,0 +1,179 @@
|
|||
# Copyright 2020 Huawei Technologies Co., Ltd
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
# ============================================================================
|
||||
"""Encoder of Transformer."""
|
||||
import mindspore.common.dtype as mstype
|
||||
from mindspore import nn
|
||||
|
||||
from .feed_forward_network import FeedForwardNet
|
||||
from .self_attention import SelfAttention
|
||||
from .components import LayerNorm
|
||||
|
||||
|
||||
class EncoderCell(nn.Cell):
|
||||
"""
|
||||
Single Encoder layer.
|
||||
|
||||
Layer structure is as below:
|
||||
-> pre_LayerNorm
|
||||
-> Multi-head Self-Attention
|
||||
-> Dropout & Add
|
||||
-> pre_LayerNorm
|
||||
-> Fc1
|
||||
-> Activation Function
|
||||
-> Dropout
|
||||
-> Fc2
|
||||
-> Dropout & Add
|
||||
|
||||
Args:
|
||||
attn_embed_dim (int): Dimensions of attention weights.
|
||||
num_attn_heads (int): Heads number.
|
||||
intermediate_size (int): Hidden size in FFN.
|
||||
attention_dropout_prob (float): Dropout rate in attention layer.
|
||||
initializer_range (float): Initial range.
|
||||
hidden_dropout_prob (float): Dropout rate in FFN.
|
||||
hidden_act (str): Activation function in FFN.
|
||||
compute_type (mstype): Mindspore data type.
|
||||
|
||||
Returns:
|
||||
Tensor, shape of (N, T, D).
|
||||
"""
|
||||
|
||||
def __init__(self,
|
||||
attn_embed_dim=768,
|
||||
num_attn_heads=12,
|
||||
intermediate_size=3072,
|
||||
attention_dropout_prob=0.02,
|
||||
initializer_range=0.02,
|
||||
hidden_dropout_prob=0.1,
|
||||
hidden_act="relu",
|
||||
compute_type=mstype.float32):
|
||||
super(EncoderCell, self).__init__()
|
||||
self.attention = SelfAttention(
|
||||
attn_embed_dim=attn_embed_dim,
|
||||
num_attn_heads=num_attn_heads,
|
||||
attn_dropout_prob=attention_dropout_prob,
|
||||
initializer_range=initializer_range,
|
||||
dropout_prob=hidden_dropout_prob,
|
||||
compute_type=compute_type)
|
||||
self.feed_forward_net = FeedForwardNet(
|
||||
in_channels=attn_embed_dim,
|
||||
hidden_size=intermediate_size,
|
||||
out_channels=attn_embed_dim,
|
||||
hidden_act=hidden_act,
|
||||
initializer_range=initializer_range,
|
||||
hidden_dropout_prob=hidden_dropout_prob,
|
||||
dropout=hidden_dropout_prob,
|
||||
compute_type=compute_type)
|
||||
|
||||
def construct(self, queries, attention_mask):
|
||||
"""
|
||||
Construct network.
|
||||
|
||||
Args:
|
||||
queries (Tensor): Shape (N, T, D).
|
||||
attention_mask (Tensor): Shape (N, T, T').
|
||||
|
||||
Returns:
|
||||
Tensor, shape (N, T, D).
|
||||
"""
|
||||
attention_output = self.attention(queries, queries, queries,
|
||||
attention_mask) # (N, T, D)
|
||||
output = self.feed_forward_net(attention_output) # (N, T, D)
|
||||
return output
|
||||
|
||||
|
||||
class TransformerEncoder(nn.Cell):
|
||||
"""
|
||||
Implements of Transformer encoder.
|
||||
|
||||
According to Google Tensor2Tensor lib experience, they found that
|
||||
put layer norm behind the multi-head self-attention and ffn would
|
||||
make model more robust.
|
||||
|
||||
Thus, we take the same action.
|
||||
|
||||
Encoder layer structure is as below:
|
||||
-> pre_LayerNorm
|
||||
-> Multi-head Self-Attention
|
||||
-> Dropout & Add
|
||||
-> pre_LayerNorm
|
||||
-> Fc1
|
||||
-> Activation Function
|
||||
-> Dropout
|
||||
-> Fc2
|
||||
-> Dropout & Add
|
||||
|
||||
Args:
|
||||
attn_embed_dim (int): Dimensions of attention weights.
|
||||
encoder_layers (int): Encoder layers.
|
||||
num_attn_heads (int): Heads number.
|
||||
intermediate_size (int): Hidden size in FFN.
|
||||
attention_dropout_prob (float): Dropout rate in attention.
|
||||
initializer_range (float): Initial range.
|
||||
hidden_dropout_prob (float): Dropout rate in FFN.
|
||||
hidden_act (str): Activation function.
|
||||
compute_type (mstype): Mindspore data type.
|
||||
|
||||
Returns:
|
||||
Tensor, shape of (N, T, D).
|
||||
"""
|
||||
|
||||
def __init__(self,
|
||||
attn_embed_dim,
|
||||
encoder_layers,
|
||||
num_attn_heads=12,
|
||||
intermediate_size=3072,
|
||||
attention_dropout_prob=0.1,
|
||||
initializer_range=0.02,
|
||||
hidden_dropout_prob=0.1,
|
||||
hidden_act="relu",
|
||||
compute_type=mstype.float32):
|
||||
super(TransformerEncoder, self).__init__()
|
||||
self.num_layers = encoder_layers
|
||||
|
||||
layers = []
|
||||
for _ in range(encoder_layers):
|
||||
layer = EncoderCell(
|
||||
attn_embed_dim=attn_embed_dim,
|
||||
num_attn_heads=num_attn_heads,
|
||||
intermediate_size=intermediate_size,
|
||||
attention_dropout_prob=attention_dropout_prob,
|
||||
initializer_range=initializer_range,
|
||||
hidden_dropout_prob=hidden_dropout_prob,
|
||||
hidden_act=hidden_act,
|
||||
compute_type=compute_type
|
||||
)
|
||||
layers.append(layer)
|
||||
|
||||
self.layers = nn.CellList(layers)
|
||||
self.layer_norm = LayerNorm(in_channels=attn_embed_dim)
|
||||
|
||||
def construct(self, input_tensor, attention_mask):
|
||||
"""
|
||||
Construct network.
|
||||
|
||||
Args:
|
||||
input_tensor (Tensor): Shape (N, T, D).
|
||||
attention_mask (Tensor): Shape (N, T, T).
|
||||
|
||||
Returns:
|
||||
Tensor, shape (N, T, D).
|
||||
"""
|
||||
prev_output = input_tensor
|
||||
for layer_module in self.layers:
|
||||
prev_output = layer_module(prev_output,
|
||||
attention_mask) # (N, T, D)
|
||||
prev_output = self.layer_norm(prev_output) # (N, T, D)
|
||||
return prev_output
|
||||
|
|
@ -0,0 +1,92 @@
|
|||
# Copyright 2020 Huawei Technologies Co., Ltd
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
# ============================================================================
|
||||
"""Forward network with two fc layers."""
|
||||
import mindspore.common.dtype as mstype
|
||||
from mindspore import nn
|
||||
from mindspore.common.initializer import TruncatedNormal
|
||||
from mindspore.ops import operations as P
|
||||
|
||||
from .residual_conn import ResidualConnection
|
||||
from .components import LayerNorm
|
||||
|
||||
|
||||
class FeedForwardNet(nn.Cell):
|
||||
"""
|
||||
Feed Forward Network (contain 2 fc layers).
|
||||
|
||||
Args:
|
||||
in_channels (int): Dimensions of input matrix.
|
||||
hidden_size (int): Hidden size.
|
||||
out_channels (int): Dimensions of output matrix.
|
||||
hidden_act (str): Activation function.
|
||||
initializer_range (float): Initialization value of TruncatedNormal. Default: 0.02.
|
||||
hidden_dropout_prob (float): The dropout probability for hidden outputs. Default: 0.1.
|
||||
dropout (float): Dropout in residual block. Default: 0.1.
|
||||
compute_type (mstype): Compute type in FeedForward. Default: mstype.float32.
|
||||
|
||||
Returns:
|
||||
Tensor, shape of (N, T, D).
|
||||
"""
|
||||
|
||||
def __init__(self,
|
||||
in_channels,
|
||||
hidden_size,
|
||||
out_channels,
|
||||
hidden_act="relu",
|
||||
initializer_range=0.02,
|
||||
hidden_dropout_prob=0.1,
|
||||
dropout=None,
|
||||
compute_type=mstype.float32):
|
||||
super(FeedForwardNet, self).__init__()
|
||||
|
||||
self.fc1 = nn.Dense(in_channels,
|
||||
hidden_size,
|
||||
activation=hidden_act,
|
||||
weight_init=TruncatedNormal(initializer_range)).to_float(compute_type)
|
||||
self.fc2 = nn.Dense(hidden_size,
|
||||
out_channels,
|
||||
weight_init=TruncatedNormal(initializer_range)).to_float(compute_type)
|
||||
|
||||
self.layer_norm = LayerNorm(in_channels=in_channels,
|
||||
return_2d=True)
|
||||
self.residual = ResidualConnection(
|
||||
dropout_prob=hidden_dropout_prob if dropout is None else dropout
|
||||
)
|
||||
self.get_shape = P.Shape()
|
||||
self.reshape = P.Reshape()
|
||||
self.dropout = nn.Dropout(keep_prob=1 - hidden_dropout_prob)
|
||||
|
||||
def construct(self, input_tensor):
|
||||
"""
|
||||
Construct network.
|
||||
|
||||
Args:
|
||||
input_tensor (Tensor): Shape (N, T, D).
|
||||
|
||||
Returns:
|
||||
Tensor, (N, T, D).
|
||||
"""
|
||||
shape = self.get_shape(input_tensor)
|
||||
batch_size = shape[0]
|
||||
max_len = shape[1]
|
||||
embed_dim = shape[2]
|
||||
|
||||
output = self.layer_norm(input_tensor)
|
||||
output = self.fc1(output)
|
||||
output = self.dropout(output)
|
||||
output = self.fc2(output) # (-1, D)
|
||||
output = self.residual(self.reshape(output, (batch_size, max_len, embed_dim)),
|
||||
input_tensor) # (N, T, D)
|
||||
return output
|
||||
|
|
@ -0,0 +1,67 @@
|
|||
# Copyright 2020 Huawei Technologies Co., Ltd
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
# ============================================================================
|
||||
"""Gradient clip."""
|
||||
import mindspore.nn as nn
|
||||
from mindspore.ops import operations as P
|
||||
from mindspore.ops import functional as F
|
||||
from mindspore.ops import composite as C
|
||||
|
||||
GRADIENT_CLIP_TYPE = 1
|
||||
GRADIENT_CLIP_VALUE = 8.0
|
||||
|
||||
|
||||
class ClipGradients(nn.Cell):
|
||||
"""
|
||||
Clip gradients.
|
||||
|
||||
Returns:
|
||||
List, a list of clipped_grad tuples.
|
||||
"""
|
||||
|
||||
def __init__(self):
|
||||
super(ClipGradients, self).__init__()
|
||||
self.clip_by_norm = nn.ClipByNorm()
|
||||
self.cast = P.Cast()
|
||||
self.dtype = P.DType()
|
||||
|
||||
def construct(self,
|
||||
grads,
|
||||
clip_type,
|
||||
clip_value):
|
||||
"""
|
||||
Construct gradient clip network.
|
||||
|
||||
Args:
|
||||
grads (list): List of gradient tuples.
|
||||
clip_type (Tensor): The way to clip, 'value' or 'norm'.
|
||||
clip_value (Tensor): Specifies how much to clip.
|
||||
|
||||
Returns:
|
||||
List, a list of clipped_grad tuples.
|
||||
"""
|
||||
if clip_type != 0 and clip_type != 1: # pylint: disable=R1714
|
||||
return grads
|
||||
|
||||
new_grads = ()
|
||||
for grad in grads:
|
||||
dt = self.dtype(grad)
|
||||
if clip_type == 0:
|
||||
t = C.clip_by_value(grad, self.cast(F.tuple_to_array((-clip_value,)), dt),
|
||||
self.cast(F.tuple_to_array((clip_value,)), dt))
|
||||
else:
|
||||
t = self.clip_by_norm(grad, self.cast(F.tuple_to_array((clip_value,)), dt))
|
||||
new_grads = new_grads + (t,)
|
||||
|
||||
return new_grads
|
||||
|
|
@ -0,0 +1,158 @@
|
|||
# Copyright 2020 Huawei Technologies Co., Ltd
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
# ============================================================================
|
||||
"""Infer api."""
|
||||
import time
|
||||
|
||||
import mindspore.nn as nn
|
||||
import mindspore.common.dtype as mstype
|
||||
from mindspore.common.tensor import Tensor
|
||||
from mindspore.train.model import Model
|
||||
|
||||
from mindspore import context
|
||||
|
||||
from src.dataset import load_dataset
|
||||
from .transformer_for_infer import TransformerInferModel
|
||||
from ..utils.load_weights import load_infer_weights
|
||||
|
||||
context.set_context(
|
||||
mode=context.GRAPH_MODE,
|
||||
save_graphs=False,
|
||||
device_target="Ascend",
|
||||
reserve_class_name_in_scope=False)
|
||||
|
||||
|
||||
class TransformerInferCell(nn.Cell):
|
||||
"""
|
||||
Encapsulation class of transformer network infer.
|
||||
|
||||
Args:
|
||||
network (nn.Cell): Transformer model.
|
||||
|
||||
Returns:
|
||||
Tuple[Tensor, Tensor], predicted_ids and predicted_probs.
|
||||
"""
|
||||
|
||||
def __init__(self, network):
|
||||
super(TransformerInferCell, self).__init__(auto_prefix=False)
|
||||
self.network = network
|
||||
|
||||
def construct(self,
|
||||
source_ids,
|
||||
source_mask):
|
||||
"""Defines the computation performed."""
|
||||
|
||||
predicted_ids, predicted_probs = self.network(source_ids,
|
||||
source_mask)
|
||||
|
||||
return predicted_ids, predicted_probs
|
||||
|
||||
|
||||
def transformer_infer(config, dataset):
|
||||
"""
|
||||
Run infer with Transformer.
|
||||
|
||||
Args:
|
||||
config (TransformerConfig): Config.
|
||||
dataset (Dataset): Dataset.
|
||||
|
||||
Returns:
|
||||
List[Dict], prediction, each example has 4 keys, "source",
|
||||
"target", "prediction" and "prediction_prob".
|
||||
"""
|
||||
tfm_model = TransformerInferModel(config=config, use_one_hot_embeddings=False)
|
||||
tfm_model.init_parameters_data()
|
||||
|
||||
params = tfm_model.trainable_params()
|
||||
weights = load_infer_weights(config)
|
||||
|
||||
for param in params:
|
||||
value = param.default_input
|
||||
name = param.name
|
||||
if name not in weights:
|
||||
raise ValueError(f"{name} is not found in weights.")
|
||||
|
||||
with open("weight_after_deal.txt", "a+") as f:
|
||||
weights_name = name
|
||||
f.write(weights_name + "\n")
|
||||
if isinstance(value, Tensor):
|
||||
print(name, value.asnumpy().shape)
|
||||
if weights_name in weights:
|
||||
assert weights_name in weights
|
||||
param.default_input = Tensor(weights[weights_name], mstype.float32)
|
||||
else:
|
||||
raise ValueError(f"{weights_name} is not found in checkpoint.")
|
||||
else:
|
||||
raise TypeError(f"Type of {weights_name} is not Tensor.")
|
||||
|
||||
print(" | Load weights successfully.")
|
||||
tfm_infer = TransformerInferCell(tfm_model)
|
||||
model = Model(tfm_infer)
|
||||
|
||||
predictions = []
|
||||
probs = []
|
||||
source_sentences = []
|
||||
target_sentences = []
|
||||
for batch in dataset.create_dict_iterator():
|
||||
source_sentences.append(batch["source_eos_ids"])
|
||||
target_sentences.append(batch["target_eos_ids"])
|
||||
|
||||
source_ids = Tensor(batch["source_eos_ids"], mstype.int32)
|
||||
source_mask = Tensor(batch["source_eos_mask"], mstype.int32)
|
||||
|
||||
start_time = time.time()
|
||||
predicted_ids, entire_probs = model.predict(source_ids, source_mask)
|
||||
print(f" | Batch size: {config.batch_size}, "
|
||||
f"Time cost: {time.time() - start_time}.")
|
||||
|
||||
predictions.append(predicted_ids.asnumpy())
|
||||
probs.append(entire_probs.asnumpy())
|
||||
|
||||
output = []
|
||||
for inputs, ref, batch_out, batch_probs in zip(source_sentences,
|
||||
target_sentences,
|
||||
predictions,
|
||||
probs):
|
||||
for i in range(config.batch_size):
|
||||
if batch_out.ndim == 3:
|
||||
batch_out = batch_out[:, 0]
|
||||
|
||||
example = {
|
||||
"source": inputs[i].tolist(),
|
||||
"target": ref[i].tolist(),
|
||||
"prediction": batch_out[i].tolist(),
|
||||
"prediction_prob": batch_probs[i].tolist()
|
||||
}
|
||||
output.append(example)
|
||||
|
||||
return output
|
||||
|
||||
|
||||
def infer(config):
|
||||
"""
|
||||
Transformer infer api.
|
||||
|
||||
Args:
|
||||
config (TransformerConfig): Config.
|
||||
|
||||
Returns:
|
||||
list, result with
|
||||
"""
|
||||
eval_dataset = load_dataset(data_files=config.test_dataset,
|
||||
batch_size=config.batch_size,
|
||||
epoch_count=1,
|
||||
sink_mode=config.dataset_sink_mode,
|
||||
shuffle=False) if config.test_dataset else None
|
||||
prediction = transformer_infer(config, eval_dataset)
|
||||
return prediction
|
||||
|
|
@ -0,0 +1,226 @@
|
|||
# Copyright 2020 Huawei Technologies Co., Ltd
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
# ============================================================================
|
||||
"""Multi-Head Self-Attention block."""
|
||||
import math
|
||||
|
||||
import mindspore.common.dtype as mstype
|
||||
import mindspore.nn as nn
|
||||
import mindspore.ops.functional as F
|
||||
from mindspore.common.initializer import TruncatedNormal
|
||||
from mindspore.common.tensor import Tensor
|
||||
from mindspore.ops import operations as P
|
||||
from .components import SaturateCast
|
||||
|
||||
|
||||
class MultiHeadAttention(nn.Cell):
|
||||
"""
|
||||
Implement of multi-head self-attention.
|
||||
|
||||
In the encoder, the calculation of single-head self-attention is as below.
|
||||
|
||||
Inputs: [x1, x2, x3, x4...] (xi is a word embedding, with shape T*D, Inputs's shape is N*T*D);
|
||||
Weights: Wq(D*embed_dim), Wk(D*embed_dim), Wv(D*embed_dim);
|
||||
|
||||
Query, key, value are calculated in below formula:
|
||||
Q = Input * Wq (N*T*embed_dim);
|
||||
K = Input * Wk (N*T*embed_dim);
|
||||
V = Input * Wv (N*T*embed_dim);
|
||||
|
||||
Then, attention score is calculated:
|
||||
A = K * Q.T (qi is doted with each ki, A's shape is N*T*T.
|
||||
e.g. q1 is doted with k1, k2, k3, k4,
|
||||
then vector of [a1.1, a1.2, a1.3, a1.4] will be available.
|
||||
ai,j represent the importance of j-th word embedding to i-th.)
|
||||
|
||||
A^ = Soft-max(A) (Normalize the score, N*T*T).
|
||||
|
||||
Finally, the output of self-attention cell is:
|
||||
O = A^ * V (N*T*embed_dim, each word embedding was represented with self-attention.)
|
||||
|
||||
Multi-head self-attention is the same with single-head self-attention except that
|
||||
Wq, Wk, Wv are repeat `head_num` times.
|
||||
|
||||
In our implements, Wq = Wk = Wv = attn_embed_dim // num_attn_heads.
|
||||
|
||||
Args:
|
||||
src_dim (int): Dimensions of queries.
|
||||
tgt_dim (int): Dimensions of keys and values.
|
||||
attn_embed_dim (int): Dimensions of attention weight, e.g. Q, K, V.
|
||||
num_attn_heads (int): Attention heads number. Default: 1.
|
||||
query_act (str): Activation function for Q. Default: None.
|
||||
key_act (str): Activation function for K. Default: None.
|
||||
value_act (str): Activation function for V. Default: None.
|
||||
has_attention_mask (bool): Whether has attention mask. Default: True.
|
||||
attention_dropout_prob (float): Dropout rate in attention. Default: 0.1.
|
||||
initializer_range (float): Initial range.
|
||||
do_return_2d_tensor (bool): Whether return 2d matrix. Default: True.
|
||||
compute_type (mstype): Mindspore data type. Default: mstype.float32.
|
||||
|
||||
Returns:
|
||||
Tensor, with shape (N, T, D).
|
||||
"""
|
||||
|
||||
def __init__(self,
|
||||
src_dim,
|
||||
tgt_dim,
|
||||
attn_embed_dim,
|
||||
num_attn_heads=1,
|
||||
query_act=None,
|
||||
key_act=None,
|
||||
value_act=None,
|
||||
out_act=None,
|
||||
has_attention_mask=True,
|
||||
attention_dropout_prob=0.0,
|
||||
initializer_range=0.02,
|
||||
do_return_2d_tensor=True,
|
||||
compute_type=mstype.float32):
|
||||
super(MultiHeadAttention, self).__init__()
|
||||
if attn_embed_dim % num_attn_heads != 0:
|
||||
raise ValueError(f"The hidden size {attn_embed_dim} is not a multiple of the "
|
||||
f"number of attention heads {num_attn_heads}")
|
||||
|
||||
self.attn_embed_dim = attn_embed_dim
|
||||
self.num_attn_heads = num_attn_heads
|
||||
self.size_per_head = attn_embed_dim // num_attn_heads
|
||||
self.src_dim = src_dim
|
||||
self.tgt_dim = tgt_dim
|
||||
self.has_attention_mask = has_attention_mask
|
||||
|
||||
if attn_embed_dim != self.num_attn_heads * self.size_per_head:
|
||||
raise ValueError("`attn_embed_dim` must be divided by num_attn_heads.")
|
||||
|
||||
self.scores_mul = Tensor([1.0 / math.sqrt(float(self.size_per_head))],
|
||||
dtype=compute_type)
|
||||
self.reshape = P.Reshape()
|
||||
|
||||
self.query_layer = nn.Dense(src_dim,
|
||||
attn_embed_dim,
|
||||
activation=query_act,
|
||||
has_bias=True,
|
||||
weight_init=TruncatedNormal(initializer_range)).to_float(compute_type)
|
||||
self.key_layer = nn.Dense(tgt_dim,
|
||||
attn_embed_dim,
|
||||
activation=key_act,
|
||||
has_bias=True,
|
||||
weight_init=TruncatedNormal(initializer_range)).to_float(compute_type)
|
||||
self.value_layer = nn.Dense(tgt_dim,
|
||||
attn_embed_dim,
|
||||
activation=value_act,
|
||||
has_bias=True,
|
||||
weight_init=TruncatedNormal(initializer_range)).to_float(compute_type)
|
||||
self.out_layer = nn.Dense(attn_embed_dim,
|
||||
attn_embed_dim,
|
||||
activation=out_act,
|
||||
has_bias=True,
|
||||
weight_init=TruncatedNormal(initializer_range)).to_float(compute_type)
|
||||
|
||||
self.matmul_trans_b = P.BatchMatMul(transpose_b=True)
|
||||
self.multiply = P.Mul()
|
||||
self.transpose = P.Transpose()
|
||||
self.multiply_data = Tensor([-10000.0], dtype=compute_type)
|
||||
self.matmul = P.BatchMatMul()
|
||||
|
||||
self.softmax = nn.Softmax()
|
||||
self.dropout = nn.Dropout(1 - attention_dropout_prob)
|
||||
|
||||
if self.has_attention_mask:
|
||||
self.expand_dims = P.ExpandDims()
|
||||
self.sub = P.Sub()
|
||||
self.add = P.TensorAdd()
|
||||
self.cast = P.Cast()
|
||||
self.get_dtype = P.DType()
|
||||
|
||||
self.do_return_2d_tensor = do_return_2d_tensor
|
||||
self.cast_compute_type = SaturateCast(dst_type=compute_type)
|
||||
self.softmax_cast = P.Cast()
|
||||
self.get_shape = P.Shape()
|
||||
self.transpose_orders = (0, 2, 1, 3)
|
||||
|
||||
def construct(self, queries, keys, values, attention_mask):
|
||||
"""
|
||||
Construct network.
|
||||
|
||||
For self attention operation, T==T'.
|
||||
For encoder-decoder-attention, T!=T'
|
||||
|
||||
Args:
|
||||
queries (Tensor): Input queries, with shape (N, T, D).
|
||||
keys (Tensor): Input keys, with shape (N, T', D).
|
||||
values (Tensor): Input values, with shape (N, T', D).
|
||||
attention_mask (Tensor): Mask matrix, with shape (N, T, T').
|
||||
|
||||
Returns:
|
||||
Tensor, with shape (N, T, D).
|
||||
"""
|
||||
q_shape = self.get_shape(queries) # (N, T, D)
|
||||
batch_size = q_shape[0]
|
||||
src_max_len = q_shape[1]
|
||||
|
||||
k_shape = self.get_shape(keys) # (N, T', D)
|
||||
tgt_max_len = k_shape[1]
|
||||
|
||||
_src_4d_shape = (batch_size, src_max_len, self.num_attn_heads, self.size_per_head)
|
||||
_tgt_4d_shape = (batch_size, tgt_max_len, self.num_attn_heads, self.size_per_head)
|
||||
|
||||
queries_2d = self.reshape(queries, (-1, self.src_dim))
|
||||
keys_2d = self.reshape(keys, (-1, self.tgt_dim))
|
||||
values_2d = self.reshape(values, (-1, self.tgt_dim))
|
||||
|
||||
query_out = self.query_layer(queries_2d) # (N*T, D)*(D, D) -> (N*T, D)
|
||||
key_out = self.key_layer(keys_2d) # (N*T, D)*(D, D) -> (N*T, D)
|
||||
value_out = self.value_layer(values_2d) # (N*T, D)*(D, D) -> (N*T, D)
|
||||
|
||||
query_out = self.multiply(query_out, self.scores_mul)
|
||||
|
||||
query_layer = self.reshape(query_out, _src_4d_shape)
|
||||
query_layer = self.transpose(query_layer, self.transpose_orders) # (N, h, T, D')
|
||||
key_layer = self.reshape(key_out, _tgt_4d_shape)
|
||||
key_layer = self.transpose(key_layer, self.transpose_orders) # (N, h, T', D')
|
||||
value_layer = self.reshape(value_out, _tgt_4d_shape)
|
||||
value_layer = self.transpose(value_layer, self.transpose_orders) # (N, h, T', D')
|
||||
|
||||
# (N, h, T, D')*(N, h, D', T') -> (N, h, T, T')
|
||||
attention_scores = self.matmul_trans_b(query_layer, key_layer)
|
||||
|
||||
if self.has_attention_mask:
|
||||
attention_mask = self.expand_dims(attention_mask, 1)
|
||||
multiply_out = self.sub(
|
||||
self.cast(F.tuple_to_array((1.0,)), self.get_dtype(attention_scores)),
|
||||
self.cast(attention_mask, self.get_dtype(attention_scores))
|
||||
) # make mask position into 1, unmask position into 0.
|
||||
adder = self.multiply(multiply_out, self.multiply_data)
|
||||
adder = self.softmax_cast(adder, mstype.float32)
|
||||
attention_scores = self.softmax_cast(attention_scores, mstype.float32)
|
||||
attention_scores = self.add(adder, attention_scores)
|
||||
|
||||
attention_scores = self.softmax_cast(attention_scores, mstype.float32)
|
||||
attention_prob = self.softmax(attention_scores)
|
||||
attention_prob = self.softmax_cast(attention_prob, self.get_dtype(key_layer))
|
||||
attention_prob = self.dropout(attention_prob)
|
||||
|
||||
# (N, h, T, T')*(N, h, T', D') -> (N, h, T, D')
|
||||
context_layer = self.matmul(attention_prob, value_layer)
|
||||
context_layer = self.transpose(context_layer, self.transpose_orders) # (N, T, h, D')
|
||||
context_layer = self.reshape(context_layer,
|
||||
(batch_size * src_max_len, self.attn_embed_dim)) # (N*T, D)
|
||||
|
||||
context_layer = self.out_layer(context_layer)
|
||||
|
||||
if not self.do_return_2d_tensor:
|
||||
context_layer = self.reshape(
|
||||
context_layer, (batch_size, src_max_len, self.attn_embed_dim)
|
||||
) # (N, T, D)
|
||||
|
||||
return context_layer
|
||||
|
|
@ -0,0 +1,82 @@
|
|||
# Copyright 2020 Huawei Technologies Co., Ltd
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
# ============================================================================
|
||||
"""Positional Embedding."""
|
||||
import numpy as np
|
||||
from mindspore import nn
|
||||
from mindspore import Tensor
|
||||
import mindspore.common.dtype as mstype
|
||||
from mindspore.ops import operations as P
|
||||
|
||||
|
||||
def position_encoding(length, depth,
|
||||
min_timescale=1,
|
||||
max_timescale=1e4):
|
||||
"""
|
||||
Create Tensor of sinusoids of different frequencies.
|
||||
|
||||
Args:
|
||||
length (int): Length of the Tensor to create, i.e. Number of steps.
|
||||
depth (int): Dimensions of embedding.
|
||||
min_timescale (float): Minimum time scale.
|
||||
max_timescale (float): Maximum time scale.
|
||||
|
||||
Returns:
|
||||
Tensor of shape (T, D)
|
||||
"""
|
||||
depth = depth // 2
|
||||
positions = np.arange(length, dtype=np.float32)
|
||||
log_timescale_increment = (np.log(max_timescale / min_timescale) / (depth - 1))
|
||||
inv_timescales = min_timescale * np.exp(
|
||||
np.arange(depth, dtype=np.float32) * -log_timescale_increment)
|
||||
scaled_time = np.expand_dims(positions, 1) * np.expand_dims(inv_timescales, 0)
|
||||
# instead of using SIN and COS interleaved
|
||||
# it's the same to first use SIN then COS
|
||||
# as they are applied to the same position
|
||||
x = np.concatenate([np.sin(scaled_time), np.cos(scaled_time)], axis=1)
|
||||
return x
|
||||
|
||||
|
||||
class PositionalEmbedding(nn.Cell):
|
||||
"""
|
||||
Add positional info to word embeddings.
|
||||
|
||||
Args:
|
||||
embedding_size (int): Size of word embedding.
|
||||
max_position_embeddings (int): Maximum step in this model.
|
||||
|
||||
Returns:
|
||||
Tensor, shape of (N, T, D).
|
||||
"""
|
||||
|
||||
def __init__(self,
|
||||
embedding_size,
|
||||
max_position_embeddings=512):
|
||||
super(PositionalEmbedding, self).__init__()
|
||||
self.add = P.TensorAdd()
|
||||
self.expand_dims = P.ExpandDims()
|
||||
self.position_embedding_table = Tensor(
|
||||
position_encoding(max_position_embeddings, embedding_size),
|
||||
mstype.float32
|
||||
)
|
||||
self.gather = P.GatherV2()
|
||||
self.get_shape = P.Shape()
|
||||
|
||||
def construct(self, word_embeddings):
|
||||
input_shape = self.get_shape(word_embeddings)
|
||||
input_len = input_shape[1]
|
||||
position_embeddings = self.position_embedding_table[0:input_len:1, ::]
|
||||
position_embeddings = self.expand_dims(position_embeddings, 0)
|
||||
output = self.add(word_embeddings, position_embeddings)
|
||||
return output
|
||||
|
|
@ -0,0 +1,49 @@
|
|||
# Copyright 2020 Huawei Technologies Co., Ltd
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
# ============================================================================
|
||||
"""Residual block."""
|
||||
import mindspore.nn as nn
|
||||
from mindspore.ops import operations as P
|
||||
|
||||
|
||||
class ResidualConnection(nn.Cell):
|
||||
"""
|
||||
Add residual to output.
|
||||
|
||||
Args:
|
||||
dropout_prob (float): Dropout rate.
|
||||
|
||||
Returns:
|
||||
Tensor, with same shape of hidden_tensor.
|
||||
"""
|
||||
|
||||
def __init__(self, dropout_prob=0.1):
|
||||
super(ResidualConnection, self).__init__()
|
||||
self.add = P.TensorAdd()
|
||||
self.dropout = nn.Dropout(1 - dropout_prob)
|
||||
|
||||
def construct(self, hidden_tensor, residual):
|
||||
"""
|
||||
Construct network.
|
||||
|
||||
Args:
|
||||
hidden_tensor (Tensor): Hidden tensor.
|
||||
residual (Tensor): Input tensor.
|
||||
|
||||
Returns:
|
||||
Tensor, which has the same shape with hidden_tensor and residual.
|
||||
"""
|
||||
output = self.dropout(hidden_tensor)
|
||||
output = self.add(output, residual)
|
||||
return output
|
||||
|
|
@ -0,0 +1,86 @@
|
|||
# Copyright 2020 Huawei Technologies Co., Ltd
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
# ============================================================================
|
||||
"""Self-Attention block."""
|
||||
import mindspore.common.dtype as mstype
|
||||
from mindspore import nn
|
||||
|
||||
from .multi_head_attention import MultiHeadAttention
|
||||
from .residual_conn import ResidualConnection
|
||||
from .components import LayerNorm
|
||||
|
||||
|
||||
class SelfAttention(nn.Cell):
|
||||
"""
|
||||
Self-Attention.
|
||||
|
||||
Layer norm -> Multi-Head Self-Attention -> Add & Dropout.
|
||||
|
||||
Args:
|
||||
attn_embed_dim (int): Dimensions of attention weight, e.g. Q, K, V.
|
||||
num_attn_heads (int): Attention heads number. Default: 1.
|
||||
attn_dropout_prob (float): Dropout rate in attention. Default: 0.1.
|
||||
initializer_range (float): Initial range.
|
||||
dropout_prob (float): Dropout rate.
|
||||
has_attention_mask (bool): Whether has attention mask.
|
||||
compute_type (mstype): Mindspore data type. Default: mstype.float32.
|
||||
|
||||
Returns:
|
||||
Tensor, shape (N, T, D).
|
||||
"""
|
||||
|
||||
def __init__(self,
|
||||
attn_embed_dim,
|
||||
num_attn_heads,
|
||||
attn_dropout_prob=0.1,
|
||||
initializer_range=0.02,
|
||||
dropout_prob=0.1,
|
||||
has_attention_mask=True,
|
||||
compute_type=mstype.float32):
|
||||
super(SelfAttention, self).__init__()
|
||||
self.multi_head_self_attention = MultiHeadAttention(
|
||||
src_dim=attn_embed_dim,
|
||||
tgt_dim=attn_embed_dim,
|
||||
attn_embed_dim=attn_embed_dim,
|
||||
num_attn_heads=num_attn_heads,
|
||||
attention_dropout_prob=attn_dropout_prob,
|
||||
initializer_range=initializer_range,
|
||||
has_attention_mask=has_attention_mask,
|
||||
do_return_2d_tensor=False,
|
||||
compute_type=compute_type)
|
||||
|
||||
self.layer_norm = LayerNorm(in_channels=attn_embed_dim)
|
||||
self.residual = ResidualConnection(dropout_prob=dropout_prob)
|
||||
|
||||
def construct(self, queries, keys, values, attention_mask):
|
||||
"""
|
||||
Construct self-attention block.
|
||||
|
||||
Layer norm -> Multi-Head Self-Attention -> Add & Dropout.
|
||||
|
||||
Args:
|
||||
queries (Tensor): Shape (N, T, D).
|
||||
keys (Tensor): Shape (N, T', D).
|
||||
values (Tensor): Shape (N, T', D).
|
||||
attention_mask (Tensor): Shape (N, T, T').
|
||||
|
||||
Returns:
|
||||
Tensor, shape (N, T, D).
|
||||
"""
|
||||
q = self.layer_norm(queries) # (N, T, D)
|
||||
attention_output = self.multi_head_self_attention(
|
||||
q, keys, values, attention_mask
|
||||
) # (N, T, D)
|
||||
q = self.residual(attention_output, queries)
|
||||
return q
|
||||
|
|
@ -0,0 +1,166 @@
|
|||
# Copyright 2020 Huawei Technologies Co., Ltd
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
# ============================================================================
|
||||
"""Transformer model addressed by Vaswani et al., 2017."""
|
||||
import copy
|
||||
import math
|
||||
|
||||
from mindspore import nn, Tensor
|
||||
from mindspore.ops import operations as P
|
||||
from mindspore.common import dtype as mstype
|
||||
|
||||
from config.config import TransformerConfig
|
||||
|
||||
from .encoder import TransformerEncoder
|
||||
from .decoder import TransformerDecoder
|
||||
from .create_attn_mask import CreateAttentionMaskFromInputMask
|
||||
from .embedding import EmbeddingLookup
|
||||
from .positional_embedding import PositionalEmbedding
|
||||
from .components import SaturateCast
|
||||
|
||||
|
||||
class Transformer(nn.Cell):
|
||||
"""
|
||||
Transformer with encoder and decoder.
|
||||
|
||||
In Transformer, we define T = src_max_len, T' = tgt_max_len.
|
||||
|
||||
Args:
|
||||
config (TransformerConfig): Model config.
|
||||
is_training (bool): Whether is training.
|
||||
use_one_hot_embeddings (bool): Whether use one-hot embedding.
|
||||
|
||||
Returns:
|
||||
Tuple[Tensor], network outputs.
|
||||
"""
|
||||
|
||||
def __init__(self,
|
||||
config: TransformerConfig,
|
||||
is_training: bool,
|
||||
use_one_hot_embeddings: bool = False,
|
||||
use_positional_embedding: bool = True):
|
||||
super(Transformer, self).__init__()
|
||||
|
||||
self.use_positional_embedding = use_positional_embedding
|
||||
config = copy.deepcopy(config)
|
||||
self.is_training = is_training
|
||||
if not is_training:
|
||||
config.hidden_dropout_prob = 0.0
|
||||
config.attention_dropout_prob = 0.0
|
||||
|
||||
self.input_mask_from_dataset = config.input_mask_from_dataset
|
||||
self.batch_size = config.batch_size
|
||||
self.max_positions = config.seq_length
|
||||
self.attn_embed_dim = config.hidden_size
|
||||
self.num_layers = config.num_hidden_layers
|
||||
self.word_embed_dim = config.hidden_size
|
||||
|
||||
self.last_idx = self.num_layers - 1
|
||||
|
||||
self.embedding_lookup = EmbeddingLookup(
|
||||
vocab_size=config.vocab_size,
|
||||
embed_dim=self.word_embed_dim,
|
||||
use_one_hot_embeddings=use_one_hot_embeddings)
|
||||
|
||||
if self.use_positional_embedding:
|
||||
self.positional_embedding = PositionalEmbedding(
|
||||
embedding_size=self.word_embed_dim,
|
||||
max_position_embeddings=config.max_position_embeddings)
|
||||
|
||||
self.encoder = TransformerEncoder(
|
||||
attn_embed_dim=self.attn_embed_dim,
|
||||
encoder_layers=self.num_layers,
|
||||
num_attn_heads=config.num_attention_heads,
|
||||
intermediate_size=config.intermediate_size,
|
||||
attention_dropout_prob=config.attention_dropout_prob,
|
||||
initializer_range=config.initializer_range,
|
||||
hidden_dropout_prob=config.hidden_dropout_prob,
|
||||
hidden_act=config.hidden_act,
|
||||
compute_type=config.compute_type)
|
||||
|
||||
self.decoder = TransformerDecoder(
|
||||
attn_embed_dim=self.attn_embed_dim,
|
||||
decoder_layers=self.num_layers,
|
||||
num_attn_heads=config.num_attention_heads,
|
||||
intermediate_size=config.intermediate_size,
|
||||
attn_dropout_prob=config.attention_dropout_prob,
|
||||
initializer_range=config.initializer_range,
|
||||
dropout_prob=config.hidden_dropout_prob,
|
||||
hidden_act=config.hidden_act,
|
||||
compute_type=config.compute_type)
|
||||
|
||||
self.cast = P.Cast()
|
||||
self.dtype = config.dtype
|
||||
self.cast_compute_type = SaturateCast(dst_type=config.compute_type)
|
||||
self.slice = P.StridedSlice()
|
||||
self.dropout = nn.Dropout(keep_prob=1 - config.hidden_dropout_prob)
|
||||
|
||||
self._create_attention_mask_from_input_mask = CreateAttentionMaskFromInputMask(config)
|
||||
|
||||
self.scale = Tensor([math.sqrt(float(self.word_embed_dim))],
|
||||
dtype=mstype.float32)
|
||||
self.multiply = P.Mul()
|
||||
|
||||
def construct(self, source_ids, source_mask, target_ids, target_mask):
|
||||
"""
|
||||
Construct network.
|
||||
|
||||
In this method, T = src_max_len, T' = tgt_max_len.
|
||||
|
||||
Args:
|
||||
source_ids (Tensor): Source sentences with shape (N, T).
|
||||
source_mask (Tensor): Source sentences padding mask with shape (N, T),
|
||||
where 0 indicates padding position.
|
||||
target_ids (Tensor): Target sentences with shape (N, T').
|
||||
target_mask (Tensor): Target sentences padding mask with shape (N, T'),
|
||||
where 0 indicates padding position.
|
||||
|
||||
Returns:
|
||||
Tuple[Tensor], network outputs.
|
||||
"""
|
||||
# Process source sentences.
|
||||
src_embeddings, embedding_tables = self.embedding_lookup(source_ids)
|
||||
src_embeddings = self.multiply(src_embeddings, self.scale)
|
||||
if self.use_positional_embedding:
|
||||
src_embeddings = self.positional_embedding(src_embeddings)
|
||||
src_embeddings = self.dropout(src_embeddings)
|
||||
|
||||
# Attention mask with shape (N, T, T).
|
||||
enc_attention_mask = self._create_attention_mask_from_input_mask(source_mask)
|
||||
# Transformer encoder.
|
||||
encoder_output = self.encoder(
|
||||
self.cast_compute_type(src_embeddings), # (N, T, D).
|
||||
self.cast_compute_type(enc_attention_mask) # (N, T, T).
|
||||
)
|
||||
|
||||
# Process target sentences.
|
||||
tgt_embeddings, _ = self.embedding_lookup(target_ids)
|
||||
tgt_embeddings = self.multiply(tgt_embeddings, self.scale)
|
||||
if self.use_positional_embedding:
|
||||
tgt_embeddings = self.positional_embedding(tgt_embeddings)
|
||||
tgt_embeddings = self.dropout(tgt_embeddings)
|
||||
|
||||
# Attention mask with shape (N, T', T').
|
||||
tgt_attention_mask = self._create_attention_mask_from_input_mask(
|
||||
target_mask, True
|
||||
)
|
||||
# Transformer decoder.
|
||||
decoder_output = self.decoder(
|
||||
self.cast_compute_type(tgt_embeddings), # (N, T', D)
|
||||
self.cast_compute_type(tgt_attention_mask), # (N, T', T')
|
||||
encoder_output, # (N, T, D)
|
||||
enc_attention_mask # (N, T, T)
|
||||
)
|
||||
|
||||
return encoder_output, decoder_output, embedding_tables
|
||||
|
|
@ -0,0 +1,331 @@
|
|||
# Copyright 2020 Huawei Technologies Co., Ltd
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
# ============================================================================
|
||||
"""Transformer for infer."""
|
||||
import math
|
||||
import copy
|
||||
import numpy as np
|
||||
import mindspore.common.dtype as mstype
|
||||
import mindspore.nn as nn
|
||||
from mindspore.ops import operations as P
|
||||
from mindspore.common.tensor import Tensor
|
||||
|
||||
from .beam_search import BeamSearchDecoder, TileBeam
|
||||
from .embedding import EmbeddingLookup
|
||||
from .positional_embedding import PositionalEmbedding
|
||||
from .components import SaturateCast
|
||||
from .create_attn_mask import CreateAttentionMaskFromInputMask
|
||||
from .decoder import TransformerDecoder
|
||||
from .encoder import TransformerEncoder
|
||||
|
||||
|
||||
class PredLogProbs(nn.Cell):
|
||||
"""
|
||||
Get log probs.
|
||||
|
||||
Args:
|
||||
batch_size (int): Batch size of input dataset.
|
||||
seq_length (int): The length of sequences.
|
||||
width (int): Number of parameters of a layer
|
||||
compute_type (int): Type of input type.
|
||||
dtype (int): Type of MindSpore output type.
|
||||
"""
|
||||
|
||||
def __init__(self,
|
||||
batch_size,
|
||||
seq_length,
|
||||
width,
|
||||
compute_type=mstype.float32,
|
||||
dtype=mstype.float32):
|
||||
super(PredLogProbs, self).__init__()
|
||||
self.batch_size = batch_size
|
||||
self.seq_length = seq_length
|
||||
self.width = width
|
||||
self.compute_type = compute_type
|
||||
self.dtype = dtype
|
||||
|
||||
self.reshape = P.Reshape()
|
||||
self.matmul = P.MatMul(transpose_b=True)
|
||||
self.log_softmax = nn.LogSoftmax(axis=-1)
|
||||
self.shape_flat_sequence_tensor = (self.batch_size * self.seq_length, self.width)
|
||||
self.cast = P.Cast()
|
||||
|
||||
def construct(self, input_tensor, output_weights):
|
||||
"""
|
||||
Calculate the log_softmax.
|
||||
|
||||
Inputs:
|
||||
input_tensor (Tensor): A batch of sentences with shape (N, T).
|
||||
output_weights (Tensor): A batch of masks with shape (N, T).
|
||||
|
||||
Returns:
|
||||
Tensor, the prediction probability with shape (N, T').
|
||||
"""
|
||||
input_tensor = self.reshape(input_tensor, self.shape_flat_sequence_tensor)
|
||||
input_tensor = self.cast(input_tensor, self.compute_type)
|
||||
output_weights = self.cast(output_weights, self.compute_type)
|
||||
|
||||
logits = self.matmul(input_tensor, output_weights)
|
||||
logits = self.cast(logits, self.dtype)
|
||||
|
||||
log_probs = self.log_softmax(logits)
|
||||
return log_probs
|
||||
|
||||
|
||||
class TransformerDecoderStep(nn.Cell):
|
||||
"""
|
||||
Multi-layer transformer decoder step.
|
||||
|
||||
Args:
|
||||
config (TransformerConfig): The config of Transformer.
|
||||
num_hidden_layers (int): The numbers of hidden layers.
|
||||
attn_embed_dim (int): Dimensions of attention weights.
|
||||
num_attn_heads=12 (int): Heads number.
|
||||
seq_length (int): The length of a sequence.
|
||||
intermediate_size: Hidden size in FFN.
|
||||
attn_dropout_prob (float): Dropout rate in attention. Default: 0.1.
|
||||
initializer_range (float): Initial range.
|
||||
hidden_dropout_prob (float): Dropout rate in FFN.
|
||||
hidden_act (str): Activation function in FFN.
|
||||
compute_type (mstype): Mindspore data type. Default: mstype.float32.
|
||||
embedding_lookup (function): Embeddings lookup operation. Default: None.
|
||||
positional_embedding (function): Position Embedding operation. Default: None.
|
||||
projection (function): Function to get log probs. Default: None.
|
||||
"""
|
||||
|
||||
def __init__(self,
|
||||
config,
|
||||
num_hidden_layers,
|
||||
attn_embed_dim,
|
||||
num_attn_heads=12,
|
||||
seq_length=64,
|
||||
intermediate_size=3072,
|
||||
attn_dropout_prob=0.1,
|
||||
initializer_range=0.02,
|
||||
hidden_dropout_prob=0.1,
|
||||
hidden_act="relu",
|
||||
compute_type=mstype.float32,
|
||||
embedding_lookup=None,
|
||||
positional_embedding=None,
|
||||
projection=None):
|
||||
super(TransformerDecoderStep, self).__init__(auto_prefix=False)
|
||||
self.embedding_lookup = embedding_lookup
|
||||
self.positional_embedding = positional_embedding
|
||||
self.projection = projection
|
||||
self.seq_length = seq_length
|
||||
self.decoder = TransformerDecoder(
|
||||
attn_embed_dim=attn_embed_dim,
|
||||
num_attn_heads=num_attn_heads,
|
||||
decoder_layers=num_hidden_layers,
|
||||
intermediate_size=intermediate_size,
|
||||
attn_dropout_prob=attn_dropout_prob,
|
||||
initializer_range=initializer_range,
|
||||
dropout_prob=hidden_dropout_prob,
|
||||
hidden_act=hidden_act,
|
||||
compute_type=compute_type)
|
||||
|
||||
self.ones_like = P.OnesLike()
|
||||
self.shape = P.Shape()
|
||||
|
||||
self._create_attention_mask_from_input_mask = CreateAttentionMaskFromInputMask(config)
|
||||
self.expand = P.ExpandDims()
|
||||
self.multiply = P.Mul()
|
||||
|
||||
ones = np.ones(shape=(seq_length, seq_length))
|
||||
self.future_mask = Tensor(np.tril(ones), dtype=mstype.float32)
|
||||
|
||||
self.cast_compute_type = SaturateCast(dst_type=compute_type)
|
||||
self.scale = Tensor([math.sqrt(float(attn_embed_dim))], dtype=mstype.float32)
|
||||
|
||||
def construct(self, input_ids, enc_states, enc_attention_mask):
|
||||
"""
|
||||
Get log probs.
|
||||
|
||||
Args:
|
||||
input_ids: [batch_size * beam_width, m]
|
||||
enc_states: [batch_size * beam_width, T, D]
|
||||
enc_attention_mask: [batch_size * beam_width, T, D]
|
||||
|
||||
Returns:
|
||||
Tensor, the log_probs. [batch_size * beam_width, 1, Vocabulary_Dimension]
|
||||
"""
|
||||
|
||||
# process embedding. input_embedding: [batch_size * beam_width, m, D], embedding_tables: [V, D]
|
||||
input_embedding, embedding_tables = self.embedding_lookup(input_ids)
|
||||
input_embedding = self.multiply(input_embedding, self.scale)
|
||||
input_embedding = self.positional_embedding(input_embedding)
|
||||
input_embedding = self.cast_compute_type(input_embedding)
|
||||
|
||||
input_shape = self.shape(input_ids)
|
||||
input_len = input_shape[1]
|
||||
# [m,m]
|
||||
future_mask = self.future_mask[0:input_len:1, 0:input_len:1]
|
||||
# [batch_size * beam_width, m]
|
||||
input_mask = self.ones_like(input_ids)
|
||||
# [batch_size * beam_width, m, m]
|
||||
input_mask = self._create_attention_mask_from_input_mask(input_mask)
|
||||
# [batch_size * beam_width, m, m]
|
||||
input_mask = self.multiply(input_mask, self.expand(future_mask, 0))
|
||||
input_mask = self.cast_compute_type(input_mask)
|
||||
|
||||
# [batch_size * beam_width, m, D]
|
||||
enc_attention_mask = enc_attention_mask[::, 0:input_len:1, ::]
|
||||
|
||||
# call TransformerDecoder: [batch_size * beam_width, m, D]
|
||||
decoder_output = self.decoder(input_embedding, input_mask, enc_states, enc_attention_mask)
|
||||
|
||||
# take the last step, [batch_size * beam_width, 1, D]
|
||||
decoder_output = decoder_output[::, input_len - 1:input_len:1, ::]
|
||||
|
||||
# projection and log_prob
|
||||
log_probs = self.projection(decoder_output, embedding_tables)
|
||||
|
||||
# [batch_size * beam_width, 1, vocabulary_size]
|
||||
return log_probs
|
||||
|
||||
|
||||
class TransformerInferModel(nn.Cell):
|
||||
"""
|
||||
Transformer Infer.
|
||||
|
||||
Args:
|
||||
config (TransformerConfig): The config of Transformer.
|
||||
use_one_hot_embeddings (bool): Specifies whether to use one hot encoding form. Default: False.
|
||||
"""
|
||||
|
||||
def __init__(self,
|
||||
config,
|
||||
use_one_hot_embeddings=False):
|
||||
super(TransformerInferModel, self).__init__()
|
||||
config = copy.deepcopy(config)
|
||||
config.hidden_dropout_prob = 0.0
|
||||
config.attention_dropout_prob = 0.0
|
||||
|
||||
self.input_mask_from_dataset = config.input_mask_from_dataset
|
||||
self.batch_size = config.batch_size
|
||||
self.seq_length = config.seq_length
|
||||
self.hidden_size = config.hidden_size
|
||||
self.num_hidden_layers = config.num_hidden_layers
|
||||
self.embedding_size = config.hidden_size
|
||||
self.attn_embed_dim = config.hidden_size
|
||||
self.num_layers = config.num_hidden_layers
|
||||
self.last_idx = self.num_hidden_layers - 1
|
||||
|
||||
self.embedding_lookup = EmbeddingLookup(
|
||||
vocab_size=config.vocab_size,
|
||||
embed_dim=self.embedding_size,
|
||||
use_one_hot_embeddings=use_one_hot_embeddings)
|
||||
|
||||
self.positional_embedding = PositionalEmbedding(
|
||||
embedding_size=self.embedding_size,
|
||||
max_position_embeddings=config.max_position_embeddings)
|
||||
# use for infer
|
||||
self.projection = PredLogProbs(
|
||||
batch_size=config.batch_size * config.beam_width,
|
||||
seq_length=1,
|
||||
width=self.hidden_size,
|
||||
compute_type=config.compute_type)
|
||||
|
||||
self.encoder = TransformerEncoder(
|
||||
attn_embed_dim=self.attn_embed_dim,
|
||||
encoder_layers=self.num_layers,
|
||||
num_attn_heads=config.num_attention_heads,
|
||||
intermediate_size=config.intermediate_size,
|
||||
attention_dropout_prob=config.attention_dropout_prob,
|
||||
initializer_range=config.initializer_range,
|
||||
hidden_dropout_prob=config.hidden_dropout_prob,
|
||||
hidden_act=config.hidden_act,
|
||||
compute_type=config.compute_type)
|
||||
|
||||
decoder_cell = TransformerDecoderStep(
|
||||
config=config,
|
||||
num_hidden_layers=config.num_hidden_layers,
|
||||
attn_embed_dim=self.attn_embed_dim,
|
||||
seq_length=config.seq_length,
|
||||
num_attn_heads=config.num_attention_heads,
|
||||
intermediate_size=config.intermediate_size,
|
||||
hidden_dropout_prob=config.hidden_dropout_prob,
|
||||
compute_type=config.compute_type,
|
||||
initializer_range=config.initializer_range,
|
||||
hidden_act="relu",
|
||||
embedding_lookup=self.embedding_lookup,
|
||||
positional_embedding=self.positional_embedding,
|
||||
attn_dropout_prob=config.attention_dropout_prob,
|
||||
projection=self.projection
|
||||
)
|
||||
|
||||
# link beam_search after decoder
|
||||
self.decoder = BeamSearchDecoder(
|
||||
batch_size=config.batch_size,
|
||||
seq_length=config.seq_length,
|
||||
vocab_size=config.vocab_size,
|
||||
decoder=decoder_cell,
|
||||
beam_width=config.beam_width,
|
||||
length_penalty_weight=config.length_penalty_weight,
|
||||
max_decode_length=config.max_decode_length)
|
||||
|
||||
self.decoder.add_flags(loop_can_unroll=True)
|
||||
|
||||
self.cast = P.Cast()
|
||||
self.dtype = config.dtype
|
||||
self.cast_compute_type = SaturateCast(dst_type=config.compute_type)
|
||||
self.expand = P.ExpandDims()
|
||||
self.multiply = P.Mul()
|
||||
|
||||
self._create_attention_mask_from_input_mask = CreateAttentionMaskFromInputMask(config)
|
||||
|
||||
# use for infer
|
||||
self.tile_beam = TileBeam(beam_width=config.beam_width)
|
||||
ones = np.ones(shape=(config.batch_size, config.max_decode_length))
|
||||
self.encode_mask = Tensor(ones, dtype=mstype.float32)
|
||||
|
||||
self.scale = Tensor([math.sqrt(float(self.embedding_size))],
|
||||
dtype=mstype.float32)
|
||||
self.reshape = P.Reshape()
|
||||
|
||||
def construct(self, source_ids, source_mask, target_ids=None, target_mask=None):
|
||||
"""
|
||||
Process source sentence
|
||||
|
||||
Inputs:
|
||||
source_ids (Tensor): Source sentences with shape (N, T).
|
||||
source_mask (Tensor): Source sentences padding mask with shape (N, T),
|
||||
where 0 indicates padding position.
|
||||
|
||||
Returns:
|
||||
Tensor, Predictions with shape (N, T').
|
||||
"""
|
||||
# word_embeddings
|
||||
src_embeddings, _ = self.embedding_lookup(source_ids)
|
||||
src_embeddings = self.multiply(src_embeddings, self.scale)
|
||||
# position_embeddings
|
||||
src_embeddings = self.positional_embedding(src_embeddings)
|
||||
# attention mask, [batch_size, seq_length, seq_length]
|
||||
enc_attention_mask = self._create_attention_mask_from_input_mask(source_mask)
|
||||
# encode
|
||||
encoder_output = self.encoder(self.cast_compute_type(src_embeddings),
|
||||
self.cast_compute_type(enc_attention_mask))
|
||||
|
||||
# bean search for encoder output
|
||||
beam_encoder_output = self.tile_beam(encoder_output)
|
||||
# [batch_size, T, D]
|
||||
enc_attention_mask = self.multiply(
|
||||
enc_attention_mask[::, 0:1:1, ::],
|
||||
self.expand(self.encode_mask, -1))
|
||||
# [N*batch_size, T, D]
|
||||
beam_enc_attention_mask = self.tile_beam(enc_attention_mask)
|
||||
beam_enc_attention_mask = self.cast_compute_type(beam_enc_attention_mask)
|
||||
predicted_ids, predicted_probs = self.decoder(beam_encoder_output, beam_enc_attention_mask)
|
||||
predicted_ids = self.reshape(predicted_ids, (self.batch_size, -1))
|
||||
return predicted_ids, predicted_probs
|
||||
|
|
@ -0,0 +1,348 @@
|
|||
# Copyright 2020 Huawei Technologies Co., Ltd
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
# ============================================================================
|
||||
"""Transformer for training."""
|
||||
from mindspore import nn
|
||||
from mindspore.ops import operations as P
|
||||
from mindspore.ops import functional as F
|
||||
from mindspore.ops import composite as C
|
||||
from mindspore.common.tensor import Tensor
|
||||
from mindspore.common.parameter import Parameter, ParameterTuple
|
||||
from mindspore.common import dtype as mstype
|
||||
from mindspore.nn.wrap.grad_reducer import DistributedGradReducer
|
||||
from mindspore.train.parallel_utils import ParallelMode
|
||||
from mindspore.parallel._utils import _get_device_num, _get_parallel_mode, _get_mirror_mean
|
||||
|
||||
from .transformer import Transformer
|
||||
from .grad_clip import GRADIENT_CLIP_TYPE, GRADIENT_CLIP_VALUE, ClipGradients
|
||||
|
||||
|
||||
class PredLogProbs(nn.Cell):
|
||||
"""
|
||||
Get log probs.
|
||||
|
||||
Args:
|
||||
config (TransformerConfig): The config of Transformer.
|
||||
|
||||
Returns:
|
||||
Tensor, masked lm output.
|
||||
"""
|
||||
|
||||
def __init__(self, config):
|
||||
super(PredLogProbs, self).__init__()
|
||||
self.width = config.hidden_size
|
||||
self.reshape = P.Reshape()
|
||||
|
||||
self.matmul = P.MatMul(transpose_b=True)
|
||||
self.log_softmax = nn.LogSoftmax(axis=-1)
|
||||
self.shape_flat_sequence_tensor = (config.batch_size * config.seq_length, self.width)
|
||||
self.cast = P.Cast()
|
||||
self.compute_type = config.compute_type
|
||||
self.dtype = config.dtype
|
||||
self.get_shape = P.Shape()
|
||||
|
||||
def construct(self, input_tensor, output_weights):
|
||||
"""
|
||||
Construct network.
|
||||
|
||||
Args:
|
||||
input_tensor (Tensor): Tensor.
|
||||
output_weights (Tensor): Tensor.
|
||||
|
||||
Returns:
|
||||
Tensor, masked lm output.
|
||||
"""
|
||||
shape = self.get_shape(input_tensor)
|
||||
|
||||
input_tensor = self.reshape(input_tensor, (shape[0] * shape[1], shape[2]))
|
||||
input_tensor = self.cast(input_tensor, self.compute_type)
|
||||
output_weights = self.cast(output_weights, self.compute_type)
|
||||
|
||||
logits = self.matmul(input_tensor, output_weights)
|
||||
logits = self.cast(logits, self.dtype)
|
||||
|
||||
log_probs = self.log_softmax(logits)
|
||||
return log_probs
|
||||
|
||||
|
||||
class TransformerTraining(nn.Cell):
|
||||
"""
|
||||
Transformer training network.
|
||||
|
||||
Args:
|
||||
config (TransformerConfig): The config of Transformer.
|
||||
is_training (bool): Specifies whether to use the training mode.
|
||||
use_one_hot_embeddings (bool): Specifies whether to use one-hot for embeddings.
|
||||
|
||||
Returns:
|
||||
Tensor, prediction_scores, seq_relationship_score.
|
||||
"""
|
||||
|
||||
def __init__(self, config, is_training, use_one_hot_embeddings):
|
||||
super(TransformerTraining, self).__init__()
|
||||
self.transformer = Transformer(config, is_training, use_one_hot_embeddings)
|
||||
self.projection = PredLogProbs(config)
|
||||
|
||||
def construct(self, source_ids, source_mask, target_ids, target_mask):
|
||||
"""
|
||||
Construct network.
|
||||
|
||||
Args:
|
||||
source_ids (Tensor): Source sentence.
|
||||
source_mask (Tensor): Source padding mask.
|
||||
target_ids (Tensor): Target sentence.
|
||||
target_mask (Tensor): Target padding mask.
|
||||
|
||||
Returns:
|
||||
Tensor, prediction_scores, seq_relationship_score.
|
||||
"""
|
||||
_, decoder_outputs, embedding_table = \
|
||||
self.transformer(source_ids, source_mask, target_ids, target_mask)
|
||||
prediction_scores = self.projection(decoder_outputs,
|
||||
embedding_table)
|
||||
return prediction_scores
|
||||
|
||||
|
||||
class LabelSmoothedCrossEntropyCriterion(nn.Cell):
|
||||
"""
|
||||
Label Smoothed Cross-Entropy Criterion.
|
||||
|
||||
Args:
|
||||
config (TransformerConfig): The config of Transformer.
|
||||
|
||||
Returns:
|
||||
Tensor, final loss.
|
||||
"""
|
||||
|
||||
def __init__(self, config):
|
||||
super(LabelSmoothedCrossEntropyCriterion, self).__init__()
|
||||
self.vocab_size = config.vocab_size
|
||||
self.onehot = P.OneHot()
|
||||
self.on_value = Tensor(float(1 - config.label_smoothing), mstype.float32)
|
||||
self.off_value = Tensor(config.label_smoothing / float(self.vocab_size - 1), mstype.float32)
|
||||
self.reduce_sum = P.ReduceSum()
|
||||
self.reduce_mean = P.ReduceMean()
|
||||
self.reshape = P.Reshape()
|
||||
self.last_idx = (-1,)
|
||||
self.flatten = P.Flatten()
|
||||
self.neg = P.Neg()
|
||||
self.cast = P.Cast()
|
||||
self.flat_shape = (config.batch_size * config.seq_length,)
|
||||
self.get_shape = P.Shape()
|
||||
|
||||
def construct(self, prediction_scores, label_ids, label_weights):
|
||||
"""
|
||||
Construct network to calculate loss.
|
||||
|
||||
Args:
|
||||
prediction_scores (Tensor): Prediction scores.
|
||||
label_ids (Tensor): Labels.
|
||||
label_weights (Tensor): Mask tensor.
|
||||
|
||||
Returns:
|
||||
Tensor, final loss.
|
||||
"""
|
||||
label_shape = self.get_shape(label_ids)
|
||||
|
||||
label_ids = self.reshape(label_ids, (label_shape[0] * label_shape[1],))
|
||||
label_weights = self.cast(
|
||||
self.reshape(label_weights, (label_shape[0] * label_shape[1],)),
|
||||
mstype.float32
|
||||
)
|
||||
one_hot_labels = self.onehot(label_ids, self.vocab_size, self.on_value, self.off_value)
|
||||
|
||||
per_example_loss = self.neg(self.reduce_sum(prediction_scores * one_hot_labels, self.last_idx))
|
||||
numerator = self.reduce_sum(label_weights * per_example_loss, ())
|
||||
denominator = self.reduce_sum(label_weights, ()) + self.cast(F.tuple_to_array((1e-5,)), mstype.float32)
|
||||
loss = numerator / denominator
|
||||
|
||||
return loss
|
||||
|
||||
|
||||
class TransformerNetworkWithLoss(nn.Cell):
|
||||
"""
|
||||
Provide transformer training loss through network.
|
||||
|
||||
Args:
|
||||
config (BertConfig): The config of Transformer.
|
||||
is_training (bool): Specifies whether to use the training mode.
|
||||
use_one_hot_embeddings (bool): Specifies whether to use one-hot for embeddings. Default: False.
|
||||
|
||||
Returns:
|
||||
Tensor, the loss of the network.
|
||||
"""
|
||||
|
||||
def __init__(self, config, is_training, use_one_hot_embeddings=False):
|
||||
super(TransformerNetworkWithLoss, self).__init__()
|
||||
self.transformer = TransformerTraining(config, is_training, use_one_hot_embeddings)
|
||||
self.loss = LabelSmoothedCrossEntropyCriterion(config)
|
||||
self.cast = P.Cast()
|
||||
|
||||
def construct(self,
|
||||
source_ids,
|
||||
source_mask,
|
||||
target_ids,
|
||||
target_mask,
|
||||
label_ids,
|
||||
label_weights):
|
||||
prediction_scores = self.transformer(source_ids, source_mask, target_ids, target_mask)
|
||||
total_loss = self.loss(prediction_scores, label_ids, label_weights)
|
||||
return self.cast(total_loss, mstype.float32)
|
||||
|
||||
|
||||
grad_scale = C.MultitypeFuncGraph("grad_scale")
|
||||
reciprocal = P.Reciprocal()
|
||||
|
||||
|
||||
@grad_scale.register("Tensor", "Tensor")
|
||||
def tensor_grad_scale(scale, grad):
|
||||
return grad * F.cast(reciprocal(scale), F.dtype(grad))
|
||||
|
||||
|
||||
class TransformerTrainOneStepWithLossScaleCell(nn.Cell):
|
||||
"""
|
||||
Encapsulation class of Transformer network training.
|
||||
|
||||
Append an optimizer to the training network after that the construct
|
||||
function can be called to create the backward graph.
|
||||
|
||||
Args:
|
||||
network: Cell. The training network. Note that loss function should have
|
||||
been added.
|
||||
optimizer: Optimizer. Optimizer for updating the weights.
|
||||
|
||||
Returns:
|
||||
Tuple[Tensor, Tensor, Tensor], loss, overflow, sen.
|
||||
"""
|
||||
|
||||
def __init__(self, network, optimizer, scale_update_cell=None):
|
||||
|
||||
super(TransformerTrainOneStepWithLossScaleCell, self).__init__(auto_prefix=False)
|
||||
self.network = network
|
||||
self.network.add_flags(defer_inline=True)
|
||||
self.weights = ParameterTuple(network.trainable_params())
|
||||
self.optimizer = optimizer
|
||||
self.grad = C.GradOperation('grad', get_by_list=True,
|
||||
sens_param=True)
|
||||
self.reducer_flag = False
|
||||
self.all_reduce = P.AllReduce()
|
||||
|
||||
self.parallel_mode = _get_parallel_mode()
|
||||
if self.parallel_mode not in ParallelMode.MODE_LIST:
|
||||
raise ValueError("Parallel mode does not support: ", self.parallel_mode)
|
||||
if self.parallel_mode in [ParallelMode.DATA_PARALLEL, ParallelMode.HYBRID_PARALLEL]:
|
||||
self.reducer_flag = True
|
||||
self.grad_reducer = None
|
||||
if self.reducer_flag:
|
||||
mean = _get_mirror_mean()
|
||||
degree = _get_device_num()
|
||||
self.grad_reducer = DistributedGradReducer(optimizer.parameters, mean, degree)
|
||||
self.is_distributed = (self.parallel_mode != ParallelMode.STAND_ALONE)
|
||||
self.clip_gradients = ClipGradients()
|
||||
self.cast = P.Cast()
|
||||
self.alloc_status = P.NPUAllocFloatStatus()
|
||||
self.get_status = P.NPUGetFloatStatus()
|
||||
self.clear_before_grad = P.NPUClearFloatStatus()
|
||||
self.reduce_sum = P.ReduceSum(keep_dims=False)
|
||||
self.depend_parameter_use = P.ControlDepend(depend_mode=1)
|
||||
self.base = Tensor(1, mstype.float32)
|
||||
self.less_equal = P.LessEqual()
|
||||
self.hyper_map = C.HyperMap()
|
||||
|
||||
self.loss_scale = None
|
||||
self.loss_scaling_manager = scale_update_cell
|
||||
if scale_update_cell:
|
||||
self.loss_scale = Parameter(Tensor(scale_update_cell.get_loss_scale(), dtype=mstype.float32),
|
||||
name="loss_scale")
|
||||
self.add_flags(has_effect=True)
|
||||
|
||||
def construct(self,
|
||||
source_eos_ids,
|
||||
source_eos_mask,
|
||||
target_sos_ids,
|
||||
target_sos_mask,
|
||||
target_eos_ids,
|
||||
target_eos_mask,
|
||||
sens=None):
|
||||
"""
|
||||
Construct network.
|
||||
|
||||
Args:
|
||||
source_eos_ids (Tensor): Source sentence.
|
||||
source_eos_mask (Tensor): Source padding mask.
|
||||
target_sos_ids (Tensor): Target sentence.
|
||||
target_sos_mask (Tensor): Target padding mask.
|
||||
target_eos_ids (Tensor): Prediction sentence.
|
||||
target_eos_mask (Tensor): Prediction padding mask.
|
||||
sens (Tensor): Loss sen.
|
||||
|
||||
Returns:
|
||||
Tuple[Tensor, Tensor, Tensor], loss, overflow, sen.
|
||||
"""
|
||||
source_ids = source_eos_ids
|
||||
source_mask = source_eos_mask
|
||||
target_ids = target_sos_ids
|
||||
target_mask = target_sos_mask
|
||||
label_ids = target_eos_ids
|
||||
label_weights = target_eos_mask
|
||||
|
||||
weights = self.weights
|
||||
loss = self.network(source_ids,
|
||||
source_mask,
|
||||
target_ids,
|
||||
target_mask,
|
||||
label_ids,
|
||||
label_weights)
|
||||
# Alloc status.
|
||||
init = self.alloc_status()
|
||||
# Clear overflow buffer.
|
||||
self.clear_before_grad(init)
|
||||
if sens is None:
|
||||
scaling_sens = self.loss_scale
|
||||
else:
|
||||
scaling_sens = sens
|
||||
grads = self.grad(self.network, weights)(source_ids,
|
||||
source_mask,
|
||||
target_ids,
|
||||
target_mask,
|
||||
label_ids,
|
||||
label_weights,
|
||||
self.cast(scaling_sens,
|
||||
mstype.float32))
|
||||
|
||||
grads = self.hyper_map(F.partial(grad_scale, scaling_sens), grads)
|
||||
grads = self.clip_gradients(grads, GRADIENT_CLIP_TYPE, GRADIENT_CLIP_VALUE)
|
||||
if self.reducer_flag:
|
||||
# Apply grad reducer on grads.
|
||||
grads = self.grad_reducer(grads)
|
||||
self.get_status(init)
|
||||
flag_sum = self.reduce_sum(init, (0,))
|
||||
|
||||
if self.is_distributed:
|
||||
# Sum overflow flag over devices.
|
||||
flag_reduce = self.all_reduce(flag_sum)
|
||||
cond = self.less_equal(self.base, flag_reduce)
|
||||
else:
|
||||
cond = self.less_equal(self.base, flag_sum)
|
||||
|
||||
overflow = cond
|
||||
if sens is None:
|
||||
overflow = self.loss_scaling_manager(self.loss_scale, cond)
|
||||
if overflow:
|
||||
succ = False
|
||||
else:
|
||||
succ = self.optimizer(grads)
|
||||
|
||||
ret = (loss, cond, scaling_sens)
|
||||
return F.depend(ret, succ)
|
||||
|
|
@ -0,0 +1,35 @@
|
|||
# Copyright 2020 Huawei Technologies Co., Ltd
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
# ============================================================================
|
||||
"""Utils for mass model."""
|
||||
from .dictionary import Dictionary
|
||||
from .ppl_score import ngram_ppl
|
||||
from .lr_scheduler import square_root_schedule
|
||||
from .loss_monitor import LossCallBack
|
||||
from .byte_pair_encoding import bpe_encode
|
||||
from .initializer import zero_weight, one_weight, normal_weight, weight_variable
|
||||
from .rouge_score import rouge
|
||||
|
||||
__all__ = [
|
||||
"Dictionary",
|
||||
"rouge",
|
||||
"bpe_encode",
|
||||
"ngram_ppl",
|
||||
"square_root_schedule",
|
||||
"LossCallBack",
|
||||
"one_weight",
|
||||
"zero_weight",
|
||||
"normal_weight",
|
||||
"weight_variable"
|
||||
]
|
||||
|
|
@ -0,0 +1,52 @@
|
|||
# Copyright 2020 Huawei Technologies Co., Ltd
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
# ============================================================================
|
||||
"""BPE."""
|
||||
import os
|
||||
import subprocess
|
||||
|
||||
ENCODER = "subword-nmt apply-bpe -c {codes} -i {input} -o {output}"
|
||||
LEARN_DICT = "subword-nmt get-vocab -i {input} -o {dict_path}"
|
||||
|
||||
|
||||
def bpe_encode(codes_path, src_path, output_path, dict_path):
|
||||
"""
|
||||
Do bpe.
|
||||
|
||||
Args:
|
||||
codes_path (str): BPE codes file.
|
||||
src_path (str): Source text file path.
|
||||
output_path (str): Output path.
|
||||
dict_path (str): Dict path.
|
||||
"""
|
||||
if not (os.path.isabs(codes_path)
|
||||
and os.path.isabs(src_path)
|
||||
and os.path.isabs(output_path)
|
||||
and os.path.isabs(dict_path)):
|
||||
raise ValueError("Absolute path is required.")
|
||||
|
||||
if not (os.path.exists(os.path.dirname(codes_path))
|
||||
and os.path.exists(os.path.dirname(src_path))
|
||||
and os.path.exists(os.path.dirname(output_path))
|
||||
and os.path.exists(os.path.dirname(dict_path))):
|
||||
raise FileNotFoundError("Dir not found.")
|
||||
|
||||
# Encoding.
|
||||
print(f" | Applying BPE encoding.")
|
||||
subprocess.call(ENCODER.format(codes=codes_path, input=src_path, output=output_path),
|
||||
shell=True)
|
||||
print(f" | Fetching vocabulary from single file.")
|
||||
# Learn vocab.
|
||||
subprocess.call(LEARN_DICT.format(input=output_path, dict_path=dict_path),
|
||||
shell=True)
|
||||
|
|
@ -0,0 +1,276 @@
|
|||
# Copyright 2020 Huawei Technologies Co., Ltd
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
# ============================================================================
|
||||
"""Vocabulary."""
|
||||
from typing import List
|
||||
import numpy as np
|
||||
|
||||
CUBE_SIZE = 16
|
||||
REPLACE_THRESHOLD = 200
|
||||
|
||||
|
||||
class Dictionary:
|
||||
"""Dictionary for mono lingual dataset."""
|
||||
|
||||
def __init__(self, max_size=46000, bos="<s>", eos="</s>", unk="<unk>",
|
||||
mask="<mask>", padding="<pad>"):
|
||||
self._bos = bos
|
||||
self._eos = eos
|
||||
self._unk = unk
|
||||
self._mask = mask
|
||||
self._padding = padding
|
||||
self._symbols = []
|
||||
self._frequency = []
|
||||
self._mapping = {}
|
||||
self._init_symbols()
|
||||
self.is_learning = False
|
||||
self.max_vocab_size = max_size
|
||||
|
||||
def shrink(self, threshold=50):
|
||||
"""
|
||||
Shrink dataset into a small one.
|
||||
|
||||
Args:
|
||||
threshold (int): Threshold that determinate whether to
|
||||
drop the word.
|
||||
|
||||
Returns:
|
||||
Dictionary, a new dict.
|
||||
"""
|
||||
_new_dict = Dictionary()
|
||||
|
||||
freq_idx = [(f, i) for i, f in enumerate(self._frequency)]
|
||||
freq_idx = sorted(freq_idx, key=lambda x: x[0], reverse=True)
|
||||
|
||||
freqs = np.array(self._frequency, dtype=np.int)
|
||||
filtered_count = np.where(freqs <= threshold)[0].shape[0]
|
||||
|
||||
left_count = self.size - filtered_count
|
||||
if left_count % CUBE_SIZE != 0:
|
||||
supplement = CUBE_SIZE - left_count % CUBE_SIZE
|
||||
if supplement <= filtered_count:
|
||||
filtered_count -= supplement
|
||||
|
||||
for f, i in freq_idx:
|
||||
if f <= threshold and filtered_count > 0:
|
||||
filtered_count -= 1
|
||||
continue
|
||||
_new_dict.add_symbol(self._symbols[i], f)
|
||||
|
||||
return _new_dict
|
||||
|
||||
def set_to_learn(self, learn: bool):
|
||||
self.is_learning = learn
|
||||
|
||||
def is_empty(self):
|
||||
if self.size <= 4:
|
||||
if sum(self._frequency) == 0:
|
||||
return True
|
||||
return False
|
||||
|
||||
@property
|
||||
def symbols(self):
|
||||
return self._symbols
|
||||
|
||||
@property
|
||||
def frequency(self):
|
||||
return self._frequency
|
||||
|
||||
@property
|
||||
def size(self):
|
||||
return len(self._symbols)
|
||||
|
||||
@property
|
||||
def mask(self):
|
||||
return self._mask
|
||||
|
||||
@property
|
||||
def eos(self):
|
||||
return self._eos
|
||||
|
||||
@property
|
||||
def bos(self):
|
||||
return self._bos
|
||||
|
||||
@property
|
||||
def unk(self):
|
||||
return self._unk
|
||||
|
||||
@property
|
||||
def padding(self):
|
||||
return self._padding
|
||||
|
||||
@property
|
||||
def padding_index(self):
|
||||
return self._padding_index
|
||||
|
||||
@property
|
||||
def mask_index(self):
|
||||
return self._mask_index
|
||||
|
||||
@property
|
||||
def eos_index(self):
|
||||
return self._eos_index
|
||||
|
||||
@property
|
||||
def bos_index(self):
|
||||
return self._bos_index
|
||||
|
||||
@property
|
||||
def unk_index(self):
|
||||
return self._unk_index
|
||||
|
||||
def _init_symbols(self):
|
||||
self._padding_index = self.add_symbol(self._padding, 0) # 0
|
||||
self._bos_index = self.add_symbol(self._bos, 0) # 1
|
||||
self._eos_index = self.add_symbol(self._eos, 0) # 2
|
||||
self._unk_index = self.add_symbol(self._unk, 0) # 3
|
||||
self._mask_index = self.add_symbol(self._mask, 0) # 4
|
||||
|
||||
def __contains__(self, symbol):
|
||||
return symbol in self._mapping
|
||||
|
||||
def __getitem__(self, idx):
|
||||
if 0 <= idx < self.size:
|
||||
return self._symbols[idx]
|
||||
return self._unk
|
||||
|
||||
def __len__(self):
|
||||
return self.size
|
||||
|
||||
def index(self, symbol: str):
|
||||
"""
|
||||
Return id according to symbol.
|
||||
|
||||
Args:
|
||||
symbol (str): Symbol.
|
||||
|
||||
Returns:
|
||||
int, id.
|
||||
"""
|
||||
idx = self._mapping.get(symbol)
|
||||
if idx is None:
|
||||
if self.is_learning and symbol.isalpha():
|
||||
if self.max_vocab_size <= self.size:
|
||||
return self.add_symbol(symbol)
|
||||
|
||||
if symbol.lower() in self._mapping:
|
||||
return self._mapping.get(symbol.lower())
|
||||
|
||||
idx = self._mapping.get(symbol.lower())
|
||||
if idx is not None:
|
||||
freq = self._frequency[idx]
|
||||
# If lower symbol in vocabulary and
|
||||
# its frequency larger than `REPLACE_THRESHOLD`,
|
||||
# then replace symbol by lower symbol.
|
||||
if freq >= REPLACE_THRESHOLD:
|
||||
return idx
|
||||
return self.unk_index
|
||||
return idx
|
||||
|
||||
def add_symbol(self, symbol, times=1):
|
||||
"""
|
||||
Add symbol to dict.
|
||||
|
||||
Args:
|
||||
symbol (str): Symbol.
|
||||
times (int): Frequency.
|
||||
|
||||
Returns:
|
||||
int, token id.
|
||||
"""
|
||||
if symbol in self._mapping:
|
||||
idx = self._mapping[symbol]
|
||||
self._frequency[idx] = self._frequency[idx] + times
|
||||
return idx
|
||||
|
||||
idx = len(self._symbols)
|
||||
self._mapping[symbol] = idx
|
||||
self._symbols.append(symbol)
|
||||
self._frequency.append(times)
|
||||
return idx
|
||||
|
||||
@classmethod
|
||||
def load_from_text(cls, filepaths: List[str]):
|
||||
"""
|
||||
Load dict from text which is in format of [word, freq].
|
||||
|
||||
Args:
|
||||
filepaths (str): Dict list.
|
||||
|
||||
Returns:
|
||||
Dictionary, dict instance.
|
||||
"""
|
||||
_dict = cls()
|
||||
for filepath in filepaths:
|
||||
with open(filepath, "r", encoding="utf-8") as f:
|
||||
for _, line in enumerate(f):
|
||||
line = line.strip()
|
||||
if line is None:
|
||||
continue
|
||||
try:
|
||||
word, freq = line.split(" ")
|
||||
_dict.add_symbol(word, times=int(freq))
|
||||
except ValueError:
|
||||
continue
|
||||
|
||||
return _dict
|
||||
|
||||
@classmethod
|
||||
def load_from_persisted_dict(cls, filepath):
|
||||
"""
|
||||
Load dict from binary file.
|
||||
|
||||
Args:
|
||||
filepath (str): File path.
|
||||
|
||||
Returns:
|
||||
Dictionary, dict instance.
|
||||
"""
|
||||
import pickle
|
||||
with open(filepath, "rb") as f:
|
||||
return pickle.load(f)
|
||||
|
||||
def persistence(self, path):
|
||||
"""Save dict to binary file."""
|
||||
import pickle
|
||||
with open(path, "wb") as _dict:
|
||||
pickle.dump(self, _dict, protocol=1)
|
||||
|
||||
def merge_dict(self, other, new_dict=False):
|
||||
"""Merge two dict."""
|
||||
if other.is_empty():
|
||||
return self
|
||||
|
||||
if new_dict:
|
||||
_dict = Dictionary()
|
||||
|
||||
for s, f in zip(self.symbols, self.frequency):
|
||||
_dict.add_symbol(s, times=f)
|
||||
for s, f in zip(other.symbols, other.frequency):
|
||||
_dict.add_symbol(s, times=f)
|
||||
return _dict
|
||||
|
||||
for s, f in zip(other.symbols, other.frequency):
|
||||
self.add_symbol(s, times=f)
|
||||
|
||||
return self
|
||||
|
||||
def export(self, path):
|
||||
"""Save text-like vocabulary."""
|
||||
_lines = []
|
||||
for token, freq in zip(self._symbols, self._frequency):
|
||||
_lines.append(f"{token} {freq}")
|
||||
with open(path, "w") as f:
|
||||
f.writelines(_lines)
|
||||
|
|
@ -0,0 +1,108 @@
|
|||
# Copyright 2020 Huawei Technologies Co., Ltd
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
# ============================================================================
|
||||
"""Initializer."""
|
||||
import math
|
||||
import numpy as np
|
||||
|
||||
from mindspore import Tensor
|
||||
|
||||
|
||||
def _compute_fans(shape):
|
||||
"""
|
||||
Computes the number of input and output units for a weight shape.
|
||||
|
||||
Args:
|
||||
shape (tuple): Integer shape tuple or TF tensor shape.
|
||||
|
||||
Returns:
|
||||
tuple, integer scalars (fan_in, fan_out).
|
||||
"""
|
||||
if not shape:
|
||||
fan_in = fan_out = 1
|
||||
elif len(shape) == 1:
|
||||
fan_in = fan_out = shape[0]
|
||||
elif len(shape) == 2:
|
||||
fan_in = shape[0]
|
||||
fan_out = shape[1]
|
||||
else:
|
||||
# Assuming convolution kernels (2D, 3D, or more).
|
||||
# kernel shape: (..., input_depth, depth)
|
||||
receptive_field_size = 1
|
||||
for dim in shape[:-2]:
|
||||
receptive_field_size *= dim
|
||||
fan_in = shape[-2] * receptive_field_size
|
||||
fan_out = shape[-1] * receptive_field_size
|
||||
return int(fan_in), int(fan_out)
|
||||
|
||||
|
||||
def weight_variable(shape):
|
||||
"""
|
||||
Generate weight var.
|
||||
|
||||
Args:
|
||||
shape (tuple): Shape.
|
||||
|
||||
Returns:
|
||||
Tensor, var.
|
||||
"""
|
||||
scale_shape = shape
|
||||
fan_in, fan_out = _compute_fans(scale_shape)
|
||||
scale = 1.0 / max(1., (fan_in + fan_out) / 2.)
|
||||
limit = math.sqrt(3.0 * scale)
|
||||
values = np.random.uniform(-limit, limit, shape).astype(np.float32)
|
||||
return Tensor(values)
|
||||
|
||||
|
||||
def one_weight(shape):
|
||||
"""
|
||||
Generate weight with ones.
|
||||
|
||||
Args:
|
||||
shape (tuple): Shape.
|
||||
|
||||
Returns:
|
||||
Tensor, var.
|
||||
"""
|
||||
ones = np.ones(shape).astype(np.float32)
|
||||
return Tensor(ones)
|
||||
|
||||
|
||||
def zero_weight(shape):
|
||||
"""
|
||||
Generate weight with zeros.
|
||||
|
||||
Args:
|
||||
shape (tuple): Shape.
|
||||
|
||||
Returns:
|
||||
Tensor, var.
|
||||
"""
|
||||
zeros = np.zeros(shape).astype(np.float32)
|
||||
return Tensor(zeros)
|
||||
|
||||
|
||||
def normal_weight(shape, num_units):
|
||||
"""
|
||||
Generate weight with normal dist.
|
||||
|
||||
Args:
|
||||
shape (tuple): Shape.
|
||||
num_units (int): Dimension.
|
||||
|
||||
Returns:
|
||||
Tensor, var.
|
||||
"""
|
||||
norm = np.random.normal(0.0, num_units ** -0.5, shape).astype(np.float32)
|
||||
return Tensor(norm)
|
||||
|
|
@ -0,0 +1,52 @@
|
|||
# Copyright 2020 Huawei Technologies Co., Ltd
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
# ============================================================================
|
||||
"""Weight loader."""
|
||||
import numpy as np
|
||||
from mindspore.train.serialization import load_checkpoint
|
||||
|
||||
|
||||
def load_infer_weights(config):
|
||||
"""
|
||||
Load weights from ckpt or npz.
|
||||
|
||||
Args:
|
||||
config (TransformerConfig): Config.
|
||||
|
||||
Returns:
|
||||
dict, weights.
|
||||
"""
|
||||
model_path = config.existed_ckpt
|
||||
if model_path.endswith(".npz"):
|
||||
ms_ckpt = np.load(model_path)
|
||||
is_npz = True
|
||||
else:
|
||||
ms_ckpt = load_checkpoint(model_path)
|
||||
is_npz = False
|
||||
weights = {}
|
||||
with open("variable_after_deal.txt", "a") as f:
|
||||
for param_name in ms_ckpt:
|
||||
infer_name = param_name.replace("transformer.transformer.", "")
|
||||
if not infer_name.startswith("encoder"):
|
||||
if infer_name.startswith("decoder.layers."):
|
||||
infer_name = infer_name.replace("decoder.layers.", "decoder.layer")
|
||||
infer_name = "decoder.decoder." + infer_name
|
||||
if is_npz:
|
||||
weights[infer_name] = ms_ckpt[param_name]
|
||||
else:
|
||||
weights[infer_name] = ms_ckpt[param_name].data.asnumpy()
|
||||
f.write(infer_name)
|
||||
f.write("\n")
|
||||
f.close()
|
||||
return weights
|
||||
|
|
@ -0,0 +1,62 @@
|
|||
# Copyright 2020 Huawei Technologies Co., Ltd
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
# ============================================================================
|
||||
"""Loss monitor."""
|
||||
import time
|
||||
from mindspore.train.callback import Callback
|
||||
from config import TransformerConfig
|
||||
|
||||
|
||||
class LossCallBack(Callback):
|
||||
"""
|
||||
Monitor the loss in training.
|
||||
|
||||
If the loss is NAN or INF terminating training.
|
||||
|
||||
Note:
|
||||
If per_print_times is 0 do not print loss.
|
||||
|
||||
Args:
|
||||
per_print_times (int): Print loss every times. Default: 1.
|
||||
"""
|
||||
time_stamp_init = False
|
||||
time_stamp_first = 0
|
||||
|
||||
def __init__(self, config: TransformerConfig, per_print_times: int = 1):
|
||||
super(LossCallBack, self).__init__()
|
||||
if not isinstance(per_print_times, int) or per_print_times < 0:
|
||||
raise ValueError("print_step must be int and >= 0.")
|
||||
self.config = config
|
||||
self._per_print_times = per_print_times
|
||||
|
||||
if not self.time_stamp_init:
|
||||
self.time_stamp_first = self._get_ms_timestamp()
|
||||
self.time_stamp_init = True
|
||||
|
||||
def step_end(self, run_context):
|
||||
cb_params = run_context.original_args()
|
||||
file_name = "./loss.log"
|
||||
with open(file_name, "a+") as f:
|
||||
time_stamp_current = self._get_ms_timestamp()
|
||||
f.write("time: {}, epoch: {}, step: {}, outputs are {}.\n".format(
|
||||
time_stamp_current - self.time_stamp_first,
|
||||
cb_params.cur_epoch_num,
|
||||
cb_params.cur_step_num,
|
||||
str(cb_params.net_outputs)
|
||||
))
|
||||
|
||||
@staticmethod
|
||||
def _get_ms_timestamp():
|
||||
t = time.time()
|
||||
return int(round(t * 1000))
|
||||
|
|
@ -0,0 +1,107 @@
|
|||
# Copyright 2020 Huawei Technologies Co., Ltd
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
# ============================================================================
|
||||
"""Learning scheduler."""
|
||||
from math import ceil
|
||||
|
||||
import numpy as np
|
||||
|
||||
|
||||
def square_root_schedule(lr, update_num, decay_start_step,
|
||||
warmup_steps=2000,
|
||||
min_lr=1e-5):
|
||||
"""
|
||||
Decay the LR based on the ISR(inverse square root).
|
||||
|
||||
During warm-up::
|
||||
lrs = np.linspace(0, lr, warmup_steps)
|
||||
|
||||
After warm-up:
|
||||
decay_factor = lr * sqrt(warmup_steps)
|
||||
lr = decay_factor / sqrt(step) if step >= decay_start_step else lr
|
||||
|
||||
Args:
|
||||
lr (float): Init learning rate.
|
||||
update_num (int): Total steps.
|
||||
decay_start_step (int): Decay begins after `decay_start_step` steps.
|
||||
warmup_steps (int): Warm up steps.
|
||||
min_lr (float): Min learning rate.
|
||||
|
||||
Returns:
|
||||
np.ndarray, learning rate array.
|
||||
"""
|
||||
warmup_end_lr = lr
|
||||
warmup_init_lr = 0 if warmup_steps > 0 else warmup_end_lr
|
||||
|
||||
# If warmup_init_lr > lr, then lr_step is negative.
|
||||
# Otherwise, it's positive.
|
||||
lr_step = (warmup_end_lr - warmup_init_lr) / warmup_steps
|
||||
decay_factor = lr * warmup_steps ** 0.5
|
||||
|
||||
lrs = np.empty(shape=update_num, dtype=np.float32)
|
||||
_start_step = 0
|
||||
if 0 < warmup_steps < update_num:
|
||||
lrs[:warmup_steps] = np.linspace(warmup_init_lr, warmup_end_lr, warmup_steps)
|
||||
_start_step = warmup_steps
|
||||
|
||||
for step in range(_start_step, update_num):
|
||||
if step < warmup_steps:
|
||||
_lr = warmup_init_lr + step * lr_step
|
||||
elif step < decay_start_step:
|
||||
_lr = lr
|
||||
else:
|
||||
_lr = decay_factor * step ** -0.5
|
||||
if _lr < min_lr:
|
||||
_lr = min_lr
|
||||
lrs[step] = _lr
|
||||
|
||||
return lrs
|
||||
|
||||
|
||||
def polynomial_decay_scheduler(lr, min_lr, decay_steps, total_update_num, warmup_steps=1000, power=1.0):
|
||||
"""
|
||||
Implements of polynomial decay learning rate scheduler which cycles by default.
|
||||
|
||||
Args:
|
||||
lr (float): Initial learning rate.
|
||||
warmup_steps (int): Warmup steps.
|
||||
decay_steps (int): Decay steps.
|
||||
total_update_num (int): Total update steps.
|
||||
min_lr (float): Min learning.
|
||||
power (float): Power factor.
|
||||
|
||||
Returns:
|
||||
np.ndarray, learning rate of each step.
|
||||
"""
|
||||
lrs = np.zeros(shape=total_update_num, dtype=np.float32)
|
||||
|
||||
if decay_steps <= 0:
|
||||
raise ValueError("`decay_steps` must larger than 1.")
|
||||
|
||||
_start_step = 0
|
||||
if 0 < warmup_steps < total_update_num:
|
||||
warmup_end_lr = lr
|
||||
warmup_init_lr = 0 if warmup_steps > 0 else warmup_end_lr
|
||||
lrs[:warmup_steps] = np.linspace(warmup_init_lr, warmup_end_lr, warmup_steps)
|
||||
_start_step = warmup_steps
|
||||
|
||||
decay_steps = decay_steps
|
||||
for step in range(_start_step, total_update_num):
|
||||
_step = step - _start_step # 2999
|
||||
ratio = ceil(_step / decay_steps) # 3
|
||||
ratio = 1 if ratio < 1 else ratio
|
||||
_decay_steps = decay_steps * ratio # 3000
|
||||
lrs[step] = (lr - min_lr) * pow(1 - _step / _decay_steps, power) + min_lr
|
||||
|
||||
return lrs
|
||||
|
|
@ -0,0 +1,64 @@
|
|||
# Copyright 2020 Huawei Technologies Co., Ltd
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
# ============================================================================
|
||||
"""Calculate Perplexity score under N-gram language model."""
|
||||
from typing import Union
|
||||
|
||||
import numpy as np
|
||||
|
||||
NINF = -1.0 * 1e9
|
||||
|
||||
|
||||
def ngram_ppl(prob: Union[np.ndarray, list], log_softmax=False, index: float = np.e):
|
||||
"""
|
||||
Calculate Perplexity(PPL) score under N-gram language model.
|
||||
|
||||
Please make sure the sum of `prob` is 1.
|
||||
Otherwise, assign `normalize=True`.
|
||||
|
||||
The number of N is depended by model.
|
||||
|
||||
Args:
|
||||
prob (Union[list, np.ndarray]): Prediction probability
|
||||
of the sentence.
|
||||
log_softmax (bool): If sum of `prob` is not 1, please
|
||||
set normalize=True.
|
||||
index (float): Base number of log softmax.
|
||||
|
||||
Returns:
|
||||
float, ppl score.
|
||||
"""
|
||||
eps = 1e-8
|
||||
if not isinstance(prob, (np.ndarray, list)):
|
||||
raise TypeError("`prob` must be type of list or np.ndarray.")
|
||||
if not isinstance(prob, np.ndarray):
|
||||
prob = np.array(prob)
|
||||
if prob.shape[0] == 0:
|
||||
raise ValueError("`prob` length must greater than 0.")
|
||||
|
||||
p = 1.0
|
||||
sen_len = 0
|
||||
for t in range(prob.shape[0]):
|
||||
s = prob[t]
|
||||
if s <= NINF:
|
||||
break
|
||||
if log_softmax:
|
||||
s = np.power(index, s)
|
||||
p *= (1 / (s + eps))
|
||||
sen_len += 1
|
||||
|
||||
if sen_len == 0:
|
||||
return np.inf
|
||||
|
||||
return pow(p, 1 / sen_len)
|
||||
|
|
@ -0,0 +1,127 @@
|
|||
# Copyright 2020 Huawei Technologies Co., Ltd
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
# ============================================================================
|
||||
"""Create pre-training dataset."""
|
||||
import os
|
||||
from multiprocessing import Pool, cpu_count
|
||||
|
||||
from src.dataset import MonoLingualDataLoader
|
||||
from src.language_model import LooseMaskedLanguageModel
|
||||
|
||||
|
||||
def _create_pre_train(text_file, vocabulary, output_folder_path,
|
||||
mask_ratio,
|
||||
mask_all_prob,
|
||||
min_sen_len,
|
||||
max_sen_len,
|
||||
suffix,
|
||||
dataset_type):
|
||||
"""
|
||||
Create pre-training dataset.
|
||||
|
||||
Args:
|
||||
text_file (str): Text file path.
|
||||
vocabulary (Dictionary): Vocab instance.
|
||||
output_folder_path (str): Output folder path.
|
||||
mask_ratio (float): Mask ratio.
|
||||
mask_all_prob (float): Mask all ratio.
|
||||
min_sen_len (int): Minimum sentence length.
|
||||
max_sen_len (int): Maximum sentence length.
|
||||
suffix (str): Suffix of output file.
|
||||
dataset_type (str): Tfrecord or mindrecord.
|
||||
"""
|
||||
suffix = suffix if not suffix else "_" + suffix
|
||||
loader = MonoLingualDataLoader(
|
||||
src_filepath=text_file,
|
||||
lang="en", dictionary=vocabulary,
|
||||
language_model=LooseMaskedLanguageModel(mask_ratio=mask_ratio, mask_all_prob=mask_all_prob),
|
||||
max_sen_len=max_sen_len, min_sen_len=min_sen_len
|
||||
)
|
||||
src_file_name = os.path.basename(text_file)
|
||||
if dataset_type.lower() == "tfrecord":
|
||||
file_name = os.path.join(
|
||||
output_folder_path,
|
||||
src_file_name.replace('.txt', f'_len_{max_sen_len}{suffix}.tfrecord')
|
||||
)
|
||||
loader.write_to_tfrecord(path=file_name)
|
||||
else:
|
||||
file_name = os.path.join(
|
||||
output_folder_path,
|
||||
src_file_name.replace('.txt', f'_len_{max_sen_len}{suffix}.mindrecord')
|
||||
)
|
||||
loader.write_to_mindrecord(path=file_name)
|
||||
|
||||
|
||||
def create_pre_training_dataset(folder_path,
|
||||
output_folder_path,
|
||||
vocabulary,
|
||||
prefix, suffix="",
|
||||
mask_ratio=0.3,
|
||||
mask_all_prob=None,
|
||||
min_sen_len=7,
|
||||
max_sen_len=82,
|
||||
dataset_type="tfrecord",
|
||||
cores=2):
|
||||
"""
|
||||
Create pre-training dataset.
|
||||
|
||||
Args:
|
||||
folder_path (str): Text file folder path.
|
||||
vocabulary (Dictionary): Vocab instance.
|
||||
output_folder_path (str): Output folder path.
|
||||
mask_ratio (float): Mask ratio.
|
||||
mask_all_prob (float): Mask all ratio.
|
||||
min_sen_len (int): Minimum sentence length.
|
||||
max_sen_len (int): Maximum sentence length.
|
||||
prefix (str): Prefix of text file.
|
||||
suffix (str): Suffix of output file.
|
||||
dataset_type (str): Tfrecord or mindrecord.
|
||||
cores (int): Cores to use.
|
||||
"""
|
||||
# Second step of data preparation.
|
||||
# Create mono zh-zh train MindRecord.
|
||||
if not os.path.exists(output_folder_path):
|
||||
raise NotADirectoryError(f"`output_folder_path` is not existed.")
|
||||
if not os.path.isdir(output_folder_path):
|
||||
raise NotADirectoryError(f"`output_folder_path` must be a dir.")
|
||||
|
||||
data_file = []
|
||||
dirs = os.listdir(folder_path)
|
||||
for file in dirs:
|
||||
if file.startswith(prefix) and file.endswith(".txt"):
|
||||
data_file.append(os.path.join(folder_path, file))
|
||||
|
||||
if not data_file:
|
||||
raise FileNotFoundError("No available text file found.")
|
||||
|
||||
args_groups = []
|
||||
for text_file in data_file:
|
||||
args_groups.append((text_file,
|
||||
vocabulary,
|
||||
output_folder_path,
|
||||
mask_ratio,
|
||||
mask_all_prob,
|
||||
min_sen_len,
|
||||
max_sen_len,
|
||||
suffix,
|
||||
dataset_type))
|
||||
|
||||
cores = min(cores, cpu_count())
|
||||
pool = Pool(cores)
|
||||
for arg in args_groups:
|
||||
pool.apply_async(_create_pre_train, args=arg)
|
||||
pool.close()
|
||||
pool.join()
|
||||
|
||||
print(f" | Generate Dataset for Pre-training is done.")
|
||||
|
|
@ -0,0 +1,60 @@
|
|||
# Copyright 2020 Huawei Technologies Co., Ltd
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
# ============================================================================
|
||||
"""Calculate ROUGE score."""
|
||||
from typing import List
|
||||
from rouge import Rouge
|
||||
|
||||
H_PATH = "summaries.txt"
|
||||
R_PATH = "references.txt"
|
||||
|
||||
|
||||
def rouge(hypothesis: List[str], target: List[str]):
|
||||
"""
|
||||
Calculate ROUGE score.
|
||||
|
||||
Args:
|
||||
hypothesis (List[str]): Inference result.
|
||||
target (List[str]): Reference.
|
||||
"""
|
||||
|
||||
def cut(s):
|
||||
idx = s.find("</s>")
|
||||
if idx != -1:
|
||||
s = s[:idx]
|
||||
return s
|
||||
|
||||
if not hypothesis or not target:
|
||||
raise ValueError(f"`hypothesis` and `target` can not be None.")
|
||||
|
||||
edited_hyp = []
|
||||
edited_ref = []
|
||||
for h, r in zip(hypothesis, target):
|
||||
h = cut(h).replace("<s>", "").strip()
|
||||
r = cut(r).replace("<s>", "").strip()
|
||||
edited_hyp.append(h + "\n")
|
||||
edited_ref.append(r + "\n")
|
||||
|
||||
_rouge = Rouge()
|
||||
scores = _rouge.get_scores(edited_hyp, target, avg=True)
|
||||
print(" | ROUGE Score:")
|
||||
print(f" | RG-1(F): {scores['rouge-1']['f'] * 100:8.2f}")
|
||||
print(f" | RG-2(F): {scores['rouge-2']['f'] * 100:8.2f}")
|
||||
print(f" | RG-L(F): {scores['rouge-l']['f'] * 100:8.2f}")
|
||||
|
||||
with open(H_PATH, "w") as f:
|
||||
f.writelines(edited_hyp)
|
||||
|
||||
with open(R_PATH, "w") as f:
|
||||
f.writelines(edited_ref)
|
||||
|
|
@ -0,0 +1,97 @@
|
|||
# Copyright 2020 Huawei Technologies Co., Ltd
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
# ============================================================================
|
||||
"""Tokenizer."""
|
||||
import os
|
||||
import argparse
|
||||
from typing import Callable
|
||||
from multiprocessing import Pool
|
||||
|
||||
parser = argparse.ArgumentParser(description='Corpus tokenizer which text file must end with `.txt`.')
|
||||
parser.add_argument("--corpus_folder", type=str, default="", required=True,
|
||||
help="Corpus folder path, if multi-folders are provided, use ',' split folders.")
|
||||
parser.add_argument("--output_folder", type=str, default="", required=True,
|
||||
help="Output folder path.")
|
||||
parser.add_argument("--tokenizer", type=str, default="nltk", required=False,
|
||||
help="Tokenizer to be used, nltk or jieba, if nltk is not installed fully, "
|
||||
"use jieba instead.")
|
||||
parser.add_argument("--pool_size", type=int, default=2, required=False,
|
||||
help="Processes pool size.")
|
||||
|
||||
TOKENIZER = Callable
|
||||
|
||||
|
||||
def create_tokenized_sentences(file_path, tokenized_file):
|
||||
"""
|
||||
Create tokenized sentences.
|
||||
|
||||
Args:
|
||||
file_path (str): Text file.
|
||||
tokenized_file (str): Output file.
|
||||
"""
|
||||
global TOKENIZER
|
||||
|
||||
print(f" | Processing {file_path}.")
|
||||
tokenized_sen = []
|
||||
with open(file_path, "r") as file:
|
||||
for sen in file:
|
||||
tokens = TOKENIZER(sen)
|
||||
tokens = [t for t in tokens if t != " "]
|
||||
if len(tokens) > 175:
|
||||
continue
|
||||
tokenized_sen.append(" ".join(tokens) + "\n")
|
||||
|
||||
with open(tokenized_file, "w") as file:
|
||||
file.writelines(tokenized_sen)
|
||||
print(f" | Wrote to {tokenized_file}.")
|
||||
|
||||
|
||||
def tokenize():
|
||||
"""Tokenizer."""
|
||||
global TOKENIZER
|
||||
|
||||
args, _ = parser.parse_known_args()
|
||||
src_folder = args.corpus_folder.split(",")
|
||||
|
||||
try:
|
||||
from nltk.tokenize import word_tokenize
|
||||
|
||||
TOKENIZER = word_tokenize
|
||||
except (ImportError, ModuleNotFoundError, LookupError):
|
||||
try:
|
||||
import jieba
|
||||
except Exception as e:
|
||||
raise e
|
||||
|
||||
print(" | NLTK is not found, use jieba instead.")
|
||||
TOKENIZER = jieba.cut
|
||||
|
||||
if args.tokenizer == "jieba":
|
||||
import jieba
|
||||
TOKENIZER = jieba.cut
|
||||
|
||||
pool = Pool(args.pool_size)
|
||||
for folder in src_folder:
|
||||
for file in os.listdir(folder):
|
||||
if not file.endswith(".txt"):
|
||||
continue
|
||||
file_path = os.path.join(folder, file)
|
||||
out_path = os.path.join(args.output_folder, file.replace(".txt", "_tokenized.txt"))
|
||||
pool.apply_async(create_tokenized_sentences, (file_path, out_path,))
|
||||
pool.close()
|
||||
pool.join()
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
tokenize()
|
||||
|
|
@ -0,0 +1,330 @@
|
|||
# Copyright 2020 Huawei Technologies Co., Ltd
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
# ============================================================================
|
||||
"""Train api."""
|
||||
import os
|
||||
import argparse
|
||||
import pickle
|
||||
|
||||
import numpy as np
|
||||
|
||||
import mindspore.common.dtype as mstype
|
||||
from mindspore.common.tensor import Tensor
|
||||
from mindspore.nn import Momentum
|
||||
from mindspore.nn.optim import Adam, Lamb
|
||||
from mindspore.train.model import Model
|
||||
from mindspore.train.loss_scale_manager import DynamicLossScaleManager
|
||||
from mindspore.train.callback import CheckpointConfig, ModelCheckpoint
|
||||
from mindspore import context, ParallelMode, Parameter
|
||||
from mindspore.communication import management as MultiAscend
|
||||
from mindspore.train.serialization import load_checkpoint
|
||||
|
||||
from config import TransformerConfig
|
||||
from src.dataset import load_dataset
|
||||
from src.transformer import TransformerNetworkWithLoss, TransformerTrainOneStepWithLossScaleCell
|
||||
from src.transformer.infer_mass import infer
|
||||
from src.utils import LossCallBack
|
||||
from src.utils import one_weight, zero_weight, weight_variable
|
||||
from src.utils import square_root_schedule
|
||||
from src.utils.lr_scheduler import polynomial_decay_scheduler
|
||||
|
||||
parser = argparse.ArgumentParser(description='MASS train entry point.')
|
||||
parser.add_argument("--config", type=str, required=True, help="model config json file path.")
|
||||
|
||||
device_id = os.getenv('DEVICE_ID', None)
|
||||
if device_id is None:
|
||||
raise RuntimeError("`DEVICE_ID` can not be None.")
|
||||
|
||||
device_id = int(device_id)
|
||||
context.set_context(
|
||||
mode=context.GRAPH_MODE,
|
||||
device_target="Ascend",
|
||||
reserve_class_name_in_scope=False,
|
||||
device_id=device_id)
|
||||
|
||||
|
||||
def get_config(config):
|
||||
config = TransformerConfig.from_json_file(config)
|
||||
config.compute_type = mstype.float16
|
||||
config.dtype = mstype.float32
|
||||
return config
|
||||
|
||||
|
||||
def _train(model, config: TransformerConfig,
|
||||
pre_training_dataset=None, fine_tune_dataset=None, test_dataset=None,
|
||||
callbacks: list = None):
|
||||
"""
|
||||
Train model.
|
||||
|
||||
Args:
|
||||
model (Model): MindSpore model instance.
|
||||
config (TransformerConfig): Config of mass model.
|
||||
pre_training_dataset (Dataset): Pre-training dataset.
|
||||
fine_tune_dataset (Dataset): Fine-tune dataset.
|
||||
test_dataset (Dataset): Test dataset.
|
||||
callbacks (list): A list of callbacks.
|
||||
"""
|
||||
callbacks = callbacks if callbacks else []
|
||||
|
||||
if pre_training_dataset is not None:
|
||||
print(" | Start pre-training job.")
|
||||
epoch_size = pre_training_dataset.get_repeat_count()
|
||||
if os.getenv("RANK_SIZE") is not None and int(os.getenv("RANK_SIZE")) > 1:
|
||||
print(f" | Rank {MultiAscend.get_rank()} Call model train.")
|
||||
model.train(epoch_size, pre_training_dataset,
|
||||
callbacks=callbacks, dataset_sink_mode=config.dataset_sink_mode)
|
||||
# Test the accuracy of the model.
|
||||
if test_dataset is not None:
|
||||
print(" | Start test job.")
|
||||
result = infer(_config)
|
||||
with open("validation_res_after_pre_training.bin", "wb") as f:
|
||||
pickle.dump(result, f, 1)
|
||||
|
||||
if fine_tune_dataset is not None:
|
||||
print(" | Start fine-tuning job.")
|
||||
epoch_size = fine_tune_dataset.get_repeat_count()
|
||||
|
||||
model.train(epoch_size, fine_tune_dataset,
|
||||
callbacks=callbacks, dataset_sink_mode=config.dataset_sink_mode)
|
||||
|
||||
# Test the accuracy of the model.
|
||||
if test_dataset is not None:
|
||||
print(" | Start test job.")
|
||||
result = infer(_config)
|
||||
with open("validation_res_after_pre_training.bin", "wb") as f:
|
||||
pickle.dump(result, f, 1)
|
||||
|
||||
|
||||
def _build_training_pipeline(config: TransformerConfig,
|
||||
pre_training_dataset=None,
|
||||
fine_tune_dataset=None,
|
||||
test_dataset=None):
|
||||
"""
|
||||
Build training pipeline.
|
||||
|
||||
Args:
|
||||
config (TransformerConfig): Config of mass model.
|
||||
pre_training_dataset (Dataset): Pre-training dataset.
|
||||
fine_tune_dataset (Dataset): Fine-tune dataset.
|
||||
test_dataset (Dataset): Test dataset.
|
||||
"""
|
||||
net_with_loss = TransformerNetworkWithLoss(config, is_training=True)
|
||||
|
||||
if config.existed_ckpt:
|
||||
if config.existed_ckpt.endswith(".npz"):
|
||||
weights = np.load(config.existed_ckpt)
|
||||
else:
|
||||
weights = load_checkpoint(config.existed_ckpt)
|
||||
for param in net_with_loss.trainable_params():
|
||||
weights_name = param.name
|
||||
if weights_name not in weights:
|
||||
raise ValueError(f"Param {weights_name} is not found in ckpt file.")
|
||||
|
||||
if isinstance(weights[weights_name], Parameter):
|
||||
param.default_input = weights[weights_name].default_input
|
||||
elif isinstance(weights[weights_name], Tensor):
|
||||
param.default_input = Tensor(weights[weights_name].asnumpy(), config.dtype)
|
||||
elif isinstance(weights[weights_name], np.ndarray):
|
||||
param.default_input = Tensor(weights[weights_name], config.dtype)
|
||||
else:
|
||||
param.default_input = weights[weights_name]
|
||||
else:
|
||||
for param in net_with_loss.trainable_params():
|
||||
name = param.name
|
||||
value = param.default_input
|
||||
if isinstance(value, Tensor):
|
||||
if name.endswith(".gamma"):
|
||||
param.default_input = one_weight(value.asnumpy().shape)
|
||||
elif name.endswith(".beta") or name.endswith(".bias"):
|
||||
param.default_input = zero_weight(value.asnumpy().shape)
|
||||
else:
|
||||
param.default_input = weight_variable(value.asnumpy().shape)
|
||||
|
||||
dataset = pre_training_dataset if pre_training_dataset is not None \
|
||||
else fine_tune_dataset
|
||||
|
||||
if dataset is None:
|
||||
raise ValueError("pre-training dataset or fine-tuning dataset must be provided one.")
|
||||
|
||||
update_steps = dataset.get_repeat_count() * dataset.get_dataset_size()
|
||||
if config.lr_scheduler == "isr":
|
||||
lr = Tensor(square_root_schedule(lr=config.lr,
|
||||
update_num=update_steps,
|
||||
decay_start_step=config.decay_start_step,
|
||||
warmup_steps=config.warmup_steps,
|
||||
min_lr=config.min_lr), dtype=mstype.float32)
|
||||
elif config.lr_scheduler == "poly":
|
||||
lr = Tensor(polynomial_decay_scheduler(lr=config.lr,
|
||||
min_lr=config.min_lr,
|
||||
decay_steps=config.decay_steps,
|
||||
total_update_num=update_steps,
|
||||
warmup_steps=config.warmup_steps,
|
||||
power=config.poly_lr_scheduler_power), dtype=mstype.float32)
|
||||
else:
|
||||
lr = config.lr
|
||||
|
||||
if config.optimizer.lower() == "adam":
|
||||
optimizer = Adam(net_with_loss.trainable_params(), lr, beta1=0.9, beta2=0.98)
|
||||
elif config.optimizer.lower() == "lamb":
|
||||
optimizer = Lamb(net_with_loss.trainable_params(), decay_steps=12000,
|
||||
start_learning_rate=config.lr, end_learning_rate=config.min_lr,
|
||||
power=10.0, warmup_steps=config.warmup_steps, weight_decay=0.01,
|
||||
eps=1e-6)
|
||||
elif config.optimizer.lower() == "momentum":
|
||||
optimizer = Momentum(net_with_loss.trainable_params(), lr, momentum=0.9)
|
||||
else:
|
||||
raise ValueError(f"optimizer only support `adam` and `momentum` now.")
|
||||
|
||||
# Dynamic loss scale.
|
||||
scale_manager = DynamicLossScaleManager(init_loss_scale=config.init_loss_scale,
|
||||
scale_factor=config.loss_scale_factor,
|
||||
scale_window=config.scale_window)
|
||||
net_with_grads = TransformerTrainOneStepWithLossScaleCell(
|
||||
network=net_with_loss, optimizer=optimizer,
|
||||
scale_update_cell=scale_manager.get_update_cell()
|
||||
)
|
||||
net_with_grads.set_train(True)
|
||||
model = Model(net_with_grads)
|
||||
loss_monitor = LossCallBack(config)
|
||||
ckpt_config = CheckpointConfig(save_checkpoint_steps=config.save_ckpt_steps,
|
||||
keep_checkpoint_max=config.keep_ckpt_max)
|
||||
|
||||
rank_size = os.getenv('RANK_SIZE')
|
||||
callbacks = [loss_monitor]
|
||||
if rank_size is not None and int(rank_size) > 1 and MultiAscend.get_rank() % 8 == 0:
|
||||
ckpt_callback = ModelCheckpoint(
|
||||
prefix=config.ckpt_prefix,
|
||||
directory=os.path.join(config.ckpt_path, 'ckpt_{}'.format(os.getenv('DEVICE_ID'))),
|
||||
config=ckpt_config)
|
||||
callbacks.append(ckpt_callback)
|
||||
|
||||
if rank_size is None or int(rank_size) == 1:
|
||||
ckpt_callback = ModelCheckpoint(
|
||||
prefix=config.ckpt_prefix,
|
||||
directory=os.path.join(config.ckpt_path, 'ckpt_{}'.format(os.getenv('DEVICE_ID'))),
|
||||
config=ckpt_config)
|
||||
callbacks.append(ckpt_callback)
|
||||
|
||||
print(f" | ALL SET, PREPARE TO TRAIN.")
|
||||
_train(model=model, config=config,
|
||||
pre_training_dataset=pre_training_dataset,
|
||||
fine_tune_dataset=fine_tune_dataset,
|
||||
test_dataset=test_dataset,
|
||||
callbacks=callbacks)
|
||||
|
||||
|
||||
def _setup_parallel_env():
|
||||
context.reset_auto_parallel_context()
|
||||
MultiAscend.init()
|
||||
context.set_auto_parallel_context(
|
||||
parallel_mode=ParallelMode.DATA_PARALLEL,
|
||||
device_num=MultiAscend.get_group_size(),
|
||||
parameter_broadcast=True,
|
||||
mirror_mean=True
|
||||
)
|
||||
|
||||
|
||||
def train_parallel(config: TransformerConfig):
|
||||
"""
|
||||
Train model with multi ascend chips.
|
||||
|
||||
Args:
|
||||
config (TransformerConfig): Config for MASS model.
|
||||
"""
|
||||
_setup_parallel_env()
|
||||
|
||||
print(f" | Starting training on {os.getenv('RANK_SIZE', None)} devices.")
|
||||
|
||||
pre_train_dataset = load_dataset(
|
||||
data_files=config.pre_train_dataset,
|
||||
batch_size=config.batch_size, epoch_count=config.epochs,
|
||||
sink_mode=config.dataset_sink_mode,
|
||||
sink_step=config.dataset_sink_step,
|
||||
rank_size=MultiAscend.get_group_size(),
|
||||
rank_id=MultiAscend.get_rank()
|
||||
) if config.pre_train_dataset else None
|
||||
fine_tune_dataset = load_dataset(
|
||||
data_files=config.fine_tune_dataset,
|
||||
batch_size=config.batch_size, epoch_count=config.epochs,
|
||||
sink_mode=config.dataset_sink_mode,
|
||||
sink_step=config.dataset_sink_step,
|
||||
rank_size=MultiAscend.get_group_size(),
|
||||
rank_id=MultiAscend.get_rank()
|
||||
) if config.fine_tune_dataset else None
|
||||
test_dataset = load_dataset(
|
||||
data_files=config.test_dataset,
|
||||
batch_size=config.batch_size, epoch_count=config.epochs,
|
||||
sink_mode=config.dataset_sink_mode,
|
||||
sink_step=config.dataset_sink_step,
|
||||
rank_size=MultiAscend.get_group_size(),
|
||||
rank_id=MultiAscend.get_rank()
|
||||
) if config.test_dataset else None
|
||||
|
||||
_build_training_pipeline(config=config,
|
||||
pre_training_dataset=pre_train_dataset,
|
||||
fine_tune_dataset=fine_tune_dataset,
|
||||
test_dataset=test_dataset)
|
||||
|
||||
|
||||
def train_single(config: TransformerConfig):
|
||||
"""
|
||||
Train model on single device.
|
||||
|
||||
Args:
|
||||
config (TransformerConfig): Config for model.
|
||||
"""
|
||||
print(" | Starting training on single device.")
|
||||
pre_train_dataset = load_dataset(data_files=config.pre_train_dataset,
|
||||
batch_size=config.batch_size,
|
||||
epoch_count=config.epochs,
|
||||
sink_mode=config.dataset_sink_mode,
|
||||
sink_step=config.dataset_sink_step) if config.pre_train_dataset else None
|
||||
fine_tune_dataset = load_dataset(data_files=config.fine_tune_dataset,
|
||||
batch_size=config.batch_size,
|
||||
epoch_count=config.epochs,
|
||||
sink_mode=config.dataset_sink_mode,
|
||||
sink_step=config.dataset_sink_step) if config.fine_tune_dataset else None
|
||||
test_dataset = load_dataset(data_files=config.test_dataset,
|
||||
batch_size=config.batch_size,
|
||||
epoch_count=config.epochs,
|
||||
sink_mode=config.dataset_sink_mode,
|
||||
sink_step=config.dataset_sink_step) if config.test_dataset else None
|
||||
|
||||
_build_training_pipeline(config=config,
|
||||
pre_training_dataset=pre_train_dataset,
|
||||
fine_tune_dataset=fine_tune_dataset,
|
||||
test_dataset=test_dataset)
|
||||
|
||||
|
||||
def _check_args(config):
|
||||
if not os.path.exists(config):
|
||||
raise FileNotFoundError("`config` is not existed.")
|
||||
if not isinstance(config, str):
|
||||
raise ValueError("`config` must be type of str.")
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
_rank_size = os.getenv('RANK_SIZE')
|
||||
|
||||
args, _ = parser.parse_known_args()
|
||||
_check_args(args.config)
|
||||
_config = get_config(args.config)
|
||||
|
||||
np.random.seed(_config.random_seed)
|
||||
context.set_context(save_graphs=_config.save_graphs)
|
||||
|
||||
if _rank_size is not None and int(_rank_size) > 1:
|
||||
train_parallel(_config)
|
||||
else:
|
||||
train_single(_config)
|
||||
|
|
@ -0,0 +1,81 @@
|
|||
# Copyright 2020 Huawei Technologies Co., Ltd
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
# ============================================================================
|
||||
"""Weight average."""
|
||||
import os
|
||||
import argparse
|
||||
import numpy as np
|
||||
from mindspore.train.serialization import load_checkpoint
|
||||
|
||||
parser = argparse.ArgumentParser(description='transformer')
|
||||
parser.add_argument("--input_files", type=str, default=None, required=False,
|
||||
help="Multi ckpt files path.")
|
||||
parser.add_argument("--input_folder", type=str, default=None, required=False,
|
||||
help="Ckpt files folder.")
|
||||
parser.add_argument("--output_file", type=str, default=None, required=True,
|
||||
help="Output model file path.")
|
||||
|
||||
|
||||
def average_me_models(ckpt_list):
|
||||
"""
|
||||
Average multi ckpt params.
|
||||
|
||||
Args:
|
||||
ckpt_list (list): Ckpt paths.
|
||||
|
||||
Returns:
|
||||
dict, params dict.
|
||||
"""
|
||||
avg_model = {}
|
||||
# load all checkpoint
|
||||
for ckpt in ckpt_list:
|
||||
if not ckpt.endswith(".ckpt"):
|
||||
continue
|
||||
if not os.path.exists(ckpt):
|
||||
raise FileNotFoundError(f"Checkpoint file is not existed.")
|
||||
|
||||
print(f" | Loading ckpt from {ckpt}.")
|
||||
ms_ckpt = load_checkpoint(ckpt)
|
||||
for param_name in ms_ckpt:
|
||||
if param_name not in avg_model:
|
||||
avg_model[param_name] = []
|
||||
avg_model[param_name].append(ms_ckpt[param_name].data.asnumpy())
|
||||
|
||||
for name in avg_model:
|
||||
avg_model[name] = sum(avg_model[name]) / float(len(ckpt_list))
|
||||
|
||||
return avg_model
|
||||
|
||||
|
||||
def main():
|
||||
"""Entry point."""
|
||||
args, _ = parser.parse_known_args()
|
||||
|
||||
if not args.input_files and not args.input_folder:
|
||||
raise ValueError("`--input_files` or `--input_folder` must be provided one as least.")
|
||||
|
||||
ckpt_list = []
|
||||
if args.input_files:
|
||||
ckpt_list.extend(args.input_files.split(","))
|
||||
|
||||
if args.input_folder and os.path.exists(args.input_folder) and os.path.isdir(args.input_folder):
|
||||
for file in os.listdir(args.input_folder):
|
||||
ckpt_list.append(os.path.join(args.input_folder, file))
|
||||
|
||||
avg_weights = average_me_models(ckpt_list)
|
||||
np.savez(args.output_file, **avg_weights)
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
main()
|
||||
Loading…
Reference in New Issue