[MLIR] Replace std ops with arith dialect ops
Precursor: https://reviews.llvm.org/D110200 Removed redundant ops from the standard dialect that were moved to the `arith` or `math` dialects. Renamed all instances of operations in the codebase and in tests. Reviewed By: rriddle, jpienaar Differential Revision: https://reviews.llvm.org/D110797
|
|
@ -18,7 +18,7 @@ class AbstractConverter;
|
|||
/// Generate call to a character comparison for two ssa-values of type
|
||||
/// `boxchar`.
|
||||
mlir::Value genBoxCharCompare(AbstractConverter &converter, mlir::Location loc,
|
||||
mlir::CmpIPredicate cmp, mlir::Value lhs,
|
||||
mlir::arith::CmpIPredicate cmp, mlir::Value lhs,
|
||||
mlir::Value rhs);
|
||||
|
||||
/// Generate call to a character comparison op for two unboxed variables. There
|
||||
|
|
@ -26,9 +26,9 @@ mlir::Value genBoxCharCompare(AbstractConverter &converter, mlir::Location loc,
|
|||
/// reference to its buffer (`ref<char<K>>`) and its LEN type parameter (some
|
||||
/// integral type).
|
||||
mlir::Value genRawCharCompare(AbstractConverter &converter, mlir::Location loc,
|
||||
mlir::CmpIPredicate cmp, mlir::Value lhsBuff,
|
||||
mlir::Value lhsLen, mlir::Value rhsBuff,
|
||||
mlir::Value rhsLen);
|
||||
mlir::arith::CmpIPredicate cmp,
|
||||
mlir::Value lhsBuff, mlir::Value lhsLen,
|
||||
mlir::Value rhsBuff, mlir::Value rhsLen);
|
||||
|
||||
} // namespace lower
|
||||
} // namespace Fortran
|
||||
|
|
|
|||
|
|
@ -30,9 +30,9 @@ inline llvm::StringRef toStringRef(const Fortran::parser::CharBlock &cb) {
|
|||
}
|
||||
|
||||
namespace fir {
|
||||
/// Return the integer value of a ConstantOp.
|
||||
inline std::int64_t toInt(mlir::ConstantOp cop) {
|
||||
return cop.getValue().cast<mlir::IntegerAttr>().getValue().getSExtValue();
|
||||
/// Return the integer value of a arith::ConstantOp.
|
||||
inline std::int64_t toInt(mlir::arith::ConstantOp cop) {
|
||||
return cop.value().cast<mlir::IntegerAttr>().getValue().getSExtValue();
|
||||
}
|
||||
} // namespace fir
|
||||
|
||||
|
|
|
|||
|
|
@ -10,6 +10,7 @@
|
|||
#define FORTRAN_OPTIMIZER_DIALECT_FIROPS_H
|
||||
|
||||
#include "flang/Optimizer/Dialect/FIRType.h"
|
||||
#include "mlir/Dialect/Arithmetic/IR/Arithmetic.h"
|
||||
#include "mlir/Dialect/StandardOps/IR/Ops.h"
|
||||
#include "mlir/Interfaces/LoopLikeInterface.h"
|
||||
#include "mlir/Interfaces/SideEffectInterfaces.h"
|
||||
|
|
@ -23,7 +24,7 @@ class DoLoopOp;
|
|||
class RealAttr;
|
||||
|
||||
void buildCmpCOp(mlir::OpBuilder &builder, mlir::OperationState &result,
|
||||
mlir::CmpFPredicate predicate, mlir::Value lhs,
|
||||
mlir::arith::CmpFPredicate predicate, mlir::Value lhs,
|
||||
mlir::Value rhs);
|
||||
unsigned getCaseArgumentOffset(llvm::ArrayRef<mlir::Attribute> cases,
|
||||
unsigned dest);
|
||||
|
|
|
|||
|
|
@ -310,7 +310,7 @@ def fir_CharConvertOp : fir_Op<"char_convert", []> {
|
|||
argument. The length of the !fir.char type is ignored.
|
||||
|
||||
```mlir
|
||||
fir.char_convert %1 for %2 to %3 : !fir.ref<!fir.char<1,?>>, i32,
|
||||
fir.char_convert %1 for %2 to %3 : !fir.ref<!fir.char<1,?>>, i32,
|
||||
!fir.ref<!fir.char<2,20>>
|
||||
```
|
||||
|
||||
|
|
@ -2544,7 +2544,7 @@ def fir_CmpcOp : fir_Op<"cmpc",
|
|||
|
||||
let printer = "printCmpcOp(p, *this);";
|
||||
|
||||
let builders = [OpBuilder<(ins "mlir::CmpFPredicate":$predicate,
|
||||
let builders = [OpBuilder<(ins "mlir::arith::CmpFPredicate":$predicate,
|
||||
"mlir::Value":$lhs, "mlir::Value":$rhs), [{
|
||||
buildCmpCOp($_builder, $_state, predicate, lhs, rhs);
|
||||
}]>];
|
||||
|
|
@ -2554,12 +2554,12 @@ def fir_CmpcOp : fir_Op<"cmpc",
|
|||
return "predicate";
|
||||
}
|
||||
|
||||
CmpFPredicate getPredicate() {
|
||||
return (CmpFPredicate)(*this)->getAttrOfType<mlir::IntegerAttr>(
|
||||
arith::CmpFPredicate getPredicate() {
|
||||
return (arith::CmpFPredicate)(*this)->getAttrOfType<mlir::IntegerAttr>(
|
||||
getPredicateAttrName()).getInt();
|
||||
}
|
||||
|
||||
static CmpFPredicate getPredicateByName(llvm::StringRef name);
|
||||
static arith::CmpFPredicate getPredicateByName(llvm::StringRef name);
|
||||
}];
|
||||
}
|
||||
|
||||
|
|
@ -2676,9 +2676,9 @@ def fir_NoReassocOp : fir_OneResultOp<"no_reassoc",
|
|||
operations with a single FMA operation.
|
||||
|
||||
```mlir
|
||||
%98 = mulf %96, %97 : f32
|
||||
%98 = arith.mulf %96, %97 : f32
|
||||
%99 = fir.no_reassoc %98 : f32
|
||||
%a0 = addf %99, %95 : f32
|
||||
%a0 = arith.addf %99, %95 : f32
|
||||
```
|
||||
}];
|
||||
|
||||
|
|
|
|||
|
|
@ -13,6 +13,7 @@
|
|||
#ifndef FORTRAN_OPTIMIZER_SUPPORT_INITFIR_H
|
||||
#define FORTRAN_OPTIMIZER_SUPPORT_INITFIR_H
|
||||
|
||||
#include "flang/Optimizer/CodeGen/CodeGen.h"
|
||||
#include "flang/Optimizer/Dialect/FIRDialect.h"
|
||||
#include "mlir/Conversion/Passes.h"
|
||||
#include "mlir/Dialect/Affine/Passes.h"
|
||||
|
|
@ -27,7 +28,8 @@ namespace fir::support {
|
|||
#define FLANG_NONCODEGEN_DIALECT_LIST \
|
||||
mlir::AffineDialect, FIROpsDialect, mlir::acc::OpenACCDialect, \
|
||||
mlir::omp::OpenMPDialect, mlir::scf::SCFDialect, \
|
||||
mlir::StandardOpsDialect, mlir::vector::VectorDialect
|
||||
mlir::arith::ArithmeticDialect, mlir::StandardOpsDialect, \
|
||||
mlir::vector::VectorDialect
|
||||
|
||||
// The definitive list of dialects used by flang.
|
||||
#define FLANG_DIALECT_LIST \
|
||||
|
|
|
|||
|
|
@ -17,9 +17,9 @@
|
|||
#include "mlir/IR/BuiltinAttributes.h"
|
||||
|
||||
namespace fir {
|
||||
/// Return the integer value of a ConstantOp.
|
||||
inline std::int64_t toInt(mlir::ConstantOp cop) {
|
||||
return cop.getValue().cast<mlir::IntegerAttr>().getValue().getSExtValue();
|
||||
/// Return the integer value of a arith::ConstantOp.
|
||||
inline std::int64_t toInt(mlir::arith::ConstantOp cop) {
|
||||
return cop.value().cast<mlir::IntegerAttr>().getValue().getSExtValue();
|
||||
}
|
||||
} // namespace fir
|
||||
|
||||
|
|
|
|||
|
|
@ -15,6 +15,7 @@
|
|||
#define FORTRAN_FIR_REWRITE_PATTERNS
|
||||
|
||||
include "mlir/IR/OpBase.td"
|
||||
include "mlir/Dialect/Arithmetic/IR/ArithmeticOps.td"
|
||||
include "mlir/Dialect/StandardOps/IR/Ops.td"
|
||||
include "flang/Optimizer/Dialect/FIROps.td"
|
||||
|
||||
|
|
@ -46,12 +47,12 @@ def CombineConvertOptPattern
|
|||
,(SmallerWidthPred $arg, $irm)]>;
|
||||
|
||||
def createConstantOp
|
||||
: NativeCodeCall<"$_builder.create<mlir::ConstantOp>"
|
||||
: NativeCodeCall<"$_builder.create<mlir::arith::ConstantOp>"
|
||||
"($_loc, $_builder.getIndexType(), "
|
||||
"rewriter.getIndexAttr($1.dyn_cast<IntegerAttr>().getInt()))">;
|
||||
|
||||
def ForwardConstantConvertPattern
|
||||
: Pat<(fir_ConvertOp:$res (ConstantOp:$cnt $attr)),
|
||||
: Pat<(fir_ConvertOp:$res (Arith_ConstantOp:$cnt $attr)),
|
||||
(createConstantOp $res, $attr),
|
||||
[(IndexTypePred $res)
|
||||
,(IntegerTypePred $cnt)]>;
|
||||
|
|
|
|||
|
|
@ -268,7 +268,8 @@ void Fortran::lower::CharacterExprHelper::createAssign(
|
|||
// Pad if needed.
|
||||
if (!compileTimeSameLength) {
|
||||
auto one = builder.createIntegerConstant(loc, lhs.getLen().getType(), 1);
|
||||
auto maxPadding = builder.create<mlir::SubIOp>(loc, lhs.getLen(), one);
|
||||
auto maxPadding =
|
||||
builder.create<mlir::arith::SubIOp>(loc, lhs.getLen(), one);
|
||||
createPadding(lhs, copyCount, maxPadding);
|
||||
}
|
||||
}
|
||||
|
|
@ -276,17 +277,17 @@ void Fortran::lower::CharacterExprHelper::createAssign(
|
|||
fir::CharBoxValue Fortran::lower::CharacterExprHelper::createConcatenate(
|
||||
const fir::CharBoxValue &lhs, const fir::CharBoxValue &rhs) {
|
||||
mlir::Value len =
|
||||
builder.create<mlir::AddIOp>(loc, lhs.getLen(), rhs.getLen());
|
||||
builder.create<mlir::arith::AddIOp>(loc, lhs.getLen(), rhs.getLen());
|
||||
auto temp = createTemp(getCharacterType(rhs), len);
|
||||
createCopy(temp, lhs, lhs.getLen());
|
||||
auto one = builder.createIntegerConstant(loc, len.getType(), 1);
|
||||
auto upperBound = builder.create<mlir::SubIOp>(loc, len, one);
|
||||
auto upperBound = builder.create<mlir::arith::SubIOp>(loc, len, one);
|
||||
auto lhsLen =
|
||||
builder.createConvert(loc, builder.getIndexType(), lhs.getLen());
|
||||
Fortran::lower::DoLoopHelper{builder, loc}.createLoop(
|
||||
lhs.getLen(), upperBound, one,
|
||||
[&](Fortran::lower::FirOpBuilder &bldr, mlir::Value index) {
|
||||
auto rhsIndex = bldr.create<mlir::SubIOp>(loc, index, lhsLen);
|
||||
auto rhsIndex = bldr.create<mlir::arith::SubIOp>(loc, index, lhsLen);
|
||||
auto charVal = createLoadCharAt(rhs, rhsIndex);
|
||||
createStoreCharAt(temp, index, charVal);
|
||||
});
|
||||
|
|
@ -312,7 +313,8 @@ fir::CharBoxValue Fortran::lower::CharacterExprHelper::createSubstring(
|
|||
auto lowerBound = castBounds[0];
|
||||
// FIR CoordinateOp is zero based but Fortran substring are one based.
|
||||
auto one = builder.createIntegerConstant(loc, lowerBound.getType(), 1);
|
||||
auto offset = builder.create<mlir::SubIOp>(loc, lowerBound, one).getResult();
|
||||
auto offset =
|
||||
builder.create<mlir::arith::SubIOp>(loc, lowerBound, one).getResult();
|
||||
auto idxType = builder.getIndexType();
|
||||
if (offset.getType() != idxType)
|
||||
offset = builder.createConvert(loc, idxType, offset);
|
||||
|
|
@ -323,17 +325,17 @@ fir::CharBoxValue Fortran::lower::CharacterExprHelper::createSubstring(
|
|||
mlir::Value substringLen{};
|
||||
if (nbounds < 2) {
|
||||
substringLen =
|
||||
builder.create<mlir::SubIOp>(loc, str.getLen(), castBounds[0]);
|
||||
builder.create<mlir::arith::SubIOp>(loc, str.getLen(), castBounds[0]);
|
||||
} else {
|
||||
substringLen =
|
||||
builder.create<mlir::SubIOp>(loc, castBounds[1], castBounds[0]);
|
||||
builder.create<mlir::arith::SubIOp>(loc, castBounds[1], castBounds[0]);
|
||||
}
|
||||
substringLen = builder.create<mlir::AddIOp>(loc, substringLen, one);
|
||||
substringLen = builder.create<mlir::arith::AddIOp>(loc, substringLen, one);
|
||||
|
||||
// Set length to zero if bounds were reversed (Fortran 2018 9.4.1)
|
||||
auto zero = builder.createIntegerConstant(loc, substringLen.getType(), 0);
|
||||
auto cdt = builder.create<mlir::CmpIOp>(loc, mlir::CmpIPredicate::slt,
|
||||
substringLen, zero);
|
||||
auto cdt = builder.create<mlir::arith::CmpIOp>(
|
||||
loc, mlir::arith::CmpIPredicate::slt, substringLen, zero);
|
||||
substringLen = builder.create<mlir::SelectOp>(loc, cdt, zero, substringLen);
|
||||
|
||||
return {substringRef, substringLen};
|
||||
|
|
|
|||
|
|
@ -85,11 +85,10 @@ static int discoverKind(mlir::Type ty) {
|
|||
// Lower character operations
|
||||
//===----------------------------------------------------------------------===//
|
||||
|
||||
mlir::Value
|
||||
Fortran::lower::genRawCharCompare(Fortran::lower::AbstractConverter &converter,
|
||||
mlir::Location loc, mlir::CmpIPredicate cmp,
|
||||
mlir::Value lhsBuff, mlir::Value lhsLen,
|
||||
mlir::Value rhsBuff, mlir::Value rhsLen) {
|
||||
mlir::Value Fortran::lower::genRawCharCompare(
|
||||
Fortran::lower::AbstractConverter &converter, mlir::Location loc,
|
||||
mlir::arith::CmpIPredicate cmp, mlir::Value lhsBuff, mlir::Value lhsLen,
|
||||
mlir::Value rhsBuff, mlir::Value rhsLen) {
|
||||
auto &builder = converter.getFirOpBuilder();
|
||||
mlir::FuncOp beginFunc;
|
||||
switch (discoverKind(lhsBuff.getType())) {
|
||||
|
|
@ -113,13 +112,12 @@ Fortran::lower::genRawCharCompare(Fortran::lower::AbstractConverter &converter,
|
|||
llvm::SmallVector<mlir::Value, 4> args = {lptr, rptr, llen, rlen};
|
||||
auto tri = builder.create<mlir::CallOp>(loc, beginFunc, args).getResult(0);
|
||||
auto zero = builder.createIntegerConstant(loc, tri.getType(), 0);
|
||||
return builder.create<mlir::CmpIOp>(loc, cmp, tri, zero);
|
||||
return builder.create<mlir::arith::CmpIOp>(loc, cmp, tri, zero);
|
||||
}
|
||||
|
||||
mlir::Value
|
||||
Fortran::lower::genBoxCharCompare(Fortran::lower::AbstractConverter &converter,
|
||||
mlir::Location loc, mlir::CmpIPredicate cmp,
|
||||
mlir::Value lhs, mlir::Value rhs) {
|
||||
mlir::Value Fortran::lower::genBoxCharCompare(
|
||||
Fortran::lower::AbstractConverter &converter, mlir::Location loc,
|
||||
mlir::arith::CmpIPredicate cmp, mlir::Value lhs, mlir::Value rhs) {
|
||||
auto &builder = converter.getFirOpBuilder();
|
||||
Fortran::lower::CharacterExprHelper helper{builder, loc};
|
||||
auto lhsPair = helper.materializeCharacter(lhs);
|
||||
|
|
|
|||
|
|
@ -46,13 +46,15 @@ mlir::Value Fortran::lower::ComplexExprHelper::createComplexCompare(
|
|||
auto imag1 = extract<Part::Imag>(cplx1);
|
||||
auto imag2 = extract<Part::Imag>(cplx2);
|
||||
|
||||
mlir::CmpFPredicate predicate =
|
||||
eq ? mlir::CmpFPredicate::UEQ : mlir::CmpFPredicate::UNE;
|
||||
mlir::arith::CmpFPredicate predicate =
|
||||
eq ? mlir::arith::CmpFPredicate::UEQ : mlir::arith::CmpFPredicate::UNE;
|
||||
mlir::Value realCmp =
|
||||
builder.create<mlir::CmpFOp>(loc, predicate, real1, real2);
|
||||
builder.create<mlir::arith::CmpFOp>(loc, predicate, real1, real2);
|
||||
mlir::Value imagCmp =
|
||||
builder.create<mlir::CmpFOp>(loc, predicate, imag1, imag2);
|
||||
builder.create<mlir::arith::CmpFOp>(loc, predicate, imag1, imag2);
|
||||
|
||||
return eq ? builder.create<mlir::AndOp>(loc, realCmp, imagCmp).getResult()
|
||||
: builder.create<mlir::OrOp>(loc, realCmp, imagCmp).getResult();
|
||||
return eq ? builder.create<mlir::arith::AndIOp>(loc, realCmp, imagCmp)
|
||||
.getResult()
|
||||
: builder.create<mlir::arith::OrIOp>(loc, realCmp, imagCmp)
|
||||
.getResult();
|
||||
}
|
||||
|
|
|
|||
|
|
@ -39,6 +39,6 @@ void Fortran::lower::DoLoopHelper::createLoop(
|
|||
auto indexType = builder.getIndexType();
|
||||
auto zero = builder.createIntegerConstant(loc, indexType, 0);
|
||||
auto one = builder.createIntegerConstant(loc, count.getType(), 1);
|
||||
auto up = builder.create<mlir::SubIOp>(loc, count, one);
|
||||
auto up = builder.create<mlir::arith::SubIOp>(loc, count, one);
|
||||
createLoop(zero, up, one, bodyGenerator);
|
||||
}
|
||||
|
|
|
|||
|
|
@ -48,12 +48,13 @@ Fortran::lower::FirOpBuilder::createNullConstant(mlir::Location loc) {
|
|||
|
||||
mlir::Value Fortran::lower::FirOpBuilder::createIntegerConstant(
|
||||
mlir::Location loc, mlir::Type ty, std::int64_t cst) {
|
||||
return create<mlir::ConstantOp>(loc, ty, getIntegerAttr(ty, cst));
|
||||
return create<mlir::arith::ConstantOp>(loc, ty, getIntegerAttr(ty, cst));
|
||||
}
|
||||
|
||||
mlir::Value Fortran::lower::FirOpBuilder::createRealConstant(
|
||||
mlir::Location loc, mlir::Type realType, const llvm::APFloat &val) {
|
||||
return create<mlir::ConstantOp>(loc, realType, getFloatAttr(realType, val));
|
||||
return create<mlir::arith::ConstantOp>(loc, realType,
|
||||
getFloatAttr(realType, val));
|
||||
}
|
||||
|
||||
mlir::Value
|
||||
|
|
@ -67,7 +68,7 @@ Fortran::lower::FirOpBuilder::createRealZeroConstant(mlir::Location loc,
|
|||
} else { // mlir::FloatType.
|
||||
attr = getZeroAttr(realType);
|
||||
}
|
||||
return create<mlir::ConstantOp>(loc, realType, attr);
|
||||
return create<mlir::arith::ConstantOp>(loc, realType, attr);
|
||||
}
|
||||
|
||||
mlir::Value Fortran::lower::FirOpBuilder::allocateLocal(
|
||||
|
|
|
|||
|
|
@ -319,8 +319,9 @@ static void genInputItemList(Fortran::lower::AbstractConverter &converter,
|
|||
auto complexPartAddr = [&](int index) {
|
||||
return builder.create<fir::CoordinateOp>(
|
||||
loc, complexPartType, originalItemAddr,
|
||||
llvm::SmallVector<mlir::Value, 1>{builder.create<mlir::ConstantOp>(
|
||||
loc, builder.getI32IntegerAttr(index))});
|
||||
llvm::SmallVector<mlir::Value, 1>{
|
||||
builder.create<mlir::arith::ConstantOp>(
|
||||
loc, builder.getI32IntegerAttr(index))});
|
||||
};
|
||||
if (complexPartType)
|
||||
itemAddr = complexPartAddr(0); // real part
|
||||
|
|
@ -332,7 +333,7 @@ static void genInputItemList(Fortran::lower::AbstractConverter &converter,
|
|||
inputFuncArgs.push_back(
|
||||
builder.createConvert(loc, inputFunc.getType().getInput(2), len));
|
||||
} else if (itemType.isa<mlir::IntegerType>()) {
|
||||
inputFuncArgs.push_back(builder.create<mlir::ConstantOp>(
|
||||
inputFuncArgs.push_back(builder.create<mlir::arith::ConstantOp>(
|
||||
loc, builder.getI32IntegerAttr(
|
||||
itemType.cast<mlir::IntegerType>().getWidth() / 8)));
|
||||
}
|
||||
|
|
@ -373,7 +374,7 @@ static void genIoLoop(Fortran::lower::AbstractConverter &converter,
|
|||
auto upperValue = genFIRLoopIndex(control.upper);
|
||||
auto stepValue = control.step.has_value()
|
||||
? genFIRLoopIndex(*control.step)
|
||||
: builder.create<mlir::ConstantIndexOp>(loc, 1);
|
||||
: builder.create<mlir::arith::ConstantIndexOp>(loc, 1);
|
||||
auto genItemList = [&](const D &ioImpliedDo, bool inIterWhileLoop) {
|
||||
if constexpr (std::is_same_v<D, Fortran::parser::InputImpliedDo>)
|
||||
genInputItemList(converter, cookie, itemList, insertPt, checkResult, ok,
|
||||
|
|
@ -430,28 +431,28 @@ static void genIoLoop(Fortran::lower::AbstractConverter &converter,
|
|||
|
||||
static mlir::Value getDefaultFilename(Fortran::lower::FirOpBuilder &builder,
|
||||
mlir::Location loc, mlir::Type toType) {
|
||||
mlir::Value null =
|
||||
builder.create<mlir::ConstantOp>(loc, builder.getI64IntegerAttr(0));
|
||||
mlir::Value null = builder.create<mlir::arith::ConstantOp>(
|
||||
loc, builder.getI64IntegerAttr(0));
|
||||
return builder.createConvert(loc, toType, null);
|
||||
}
|
||||
|
||||
static mlir::Value getDefaultLineNo(Fortran::lower::FirOpBuilder &builder,
|
||||
mlir::Location loc, mlir::Type toType) {
|
||||
return builder.create<mlir::ConstantOp>(loc,
|
||||
builder.getIntegerAttr(toType, 0));
|
||||
return builder.create<mlir::arith::ConstantOp>(
|
||||
loc, builder.getIntegerAttr(toType, 0));
|
||||
}
|
||||
|
||||
static mlir::Value getDefaultScratch(Fortran::lower::FirOpBuilder &builder,
|
||||
mlir::Location loc, mlir::Type toType) {
|
||||
mlir::Value null =
|
||||
builder.create<mlir::ConstantOp>(loc, builder.getI64IntegerAttr(0));
|
||||
mlir::Value null = builder.create<mlir::arith::ConstantOp>(
|
||||
loc, builder.getI64IntegerAttr(0));
|
||||
return builder.createConvert(loc, toType, null);
|
||||
}
|
||||
|
||||
static mlir::Value getDefaultScratchLen(Fortran::lower::FirOpBuilder &builder,
|
||||
mlir::Location loc, mlir::Type toType) {
|
||||
return builder.create<mlir::ConstantOp>(loc,
|
||||
builder.getIntegerAttr(toType, 0));
|
||||
return builder.create<mlir::arith::ConstantOp>(
|
||||
loc, builder.getIntegerAttr(toType, 0));
|
||||
}
|
||||
|
||||
/// Lower a string literal. Many arguments to the runtime are conveyed as
|
||||
|
|
@ -470,7 +471,7 @@ lowerStringLit(Fortran::lower::AbstractConverter &converter, mlir::Location loc,
|
|||
auto len = builder.createConvert(loc, lenTy, dataLen.second);
|
||||
if (ty2) {
|
||||
auto kindVal = helper.getCharacterKind(str.getType());
|
||||
auto kind = builder.create<mlir::ConstantOp>(
|
||||
auto kind = builder.create<mlir::arith::ConstantOp>(
|
||||
loc, builder.getIntegerAttr(ty2, kindVal));
|
||||
return {buff, len, kind};
|
||||
}
|
||||
|
|
@ -777,7 +778,7 @@ genConditionHandlerCall(Fortran::lower::AbstractConverter &converter,
|
|||
getIORuntimeFunc<mkIOKey(EnableHandlers)>(loc, builder);
|
||||
mlir::Type boolType = enableHandlers.getType().getInput(1);
|
||||
auto boolValue = [&](bool specifierIsPresent) {
|
||||
return builder.create<mlir::ConstantOp>(
|
||||
return builder.create<mlir::arith::ConstantOp>(
|
||||
loc, builder.getIntegerAttr(boolType, specifierIsPresent));
|
||||
};
|
||||
llvm::SmallVector<mlir::Value, 6> ioArgs = {
|
||||
|
|
@ -998,7 +999,7 @@ static mlir::Value genIOUnit(Fortran::lower::AbstractConverter &converter,
|
|||
auto ex = converter.genExprValue(Fortran::semantics::GetExpr(*e), loc);
|
||||
return builder.createConvert(loc, ty, ex);
|
||||
}
|
||||
return builder.create<mlir::ConstantOp>(
|
||||
return builder.create<mlir::arith::ConstantOp>(
|
||||
loc, builder.getIntegerAttr(ty, Fortran::runtime::io::DefaultUnit));
|
||||
}
|
||||
|
||||
|
|
@ -1291,7 +1292,7 @@ void genBeginCallArguments(llvm::SmallVector<mlir::Value, 8> &ioArgs,
|
|||
ioArgs.push_back(std::get<1>(pair));
|
||||
}
|
||||
// unit (always last)
|
||||
ioArgs.push_back(builder.create<mlir::ConstantOp>(
|
||||
ioArgs.push_back(builder.create<mlir::arith::ConstantOp>(
|
||||
loc, builder.getIntegerAttr(ioFuncTy.getInput(ioArgs.size()),
|
||||
Fortran::runtime::io::DefaultUnit)));
|
||||
}
|
||||
|
|
|
|||
|
|
@ -948,7 +948,7 @@ mlir::Value IntrinsicLibrary::genAbs(mlir::Type resultType,
|
|||
auto arg = args[0];
|
||||
auto type = arg.getType();
|
||||
if (fir::isa_real(type)) {
|
||||
// Runtime call to fp abs. An alternative would be to use mlir AbsFOp
|
||||
// Runtime call to fp abs. An alternative would be to use mlir math::AbsOp
|
||||
// but it does not support all fir floating point types.
|
||||
return genRuntimeCall("abs", resultType, args);
|
||||
}
|
||||
|
|
@ -957,9 +957,9 @@ mlir::Value IntrinsicLibrary::genAbs(mlir::Type resultType,
|
|||
// So, implement abs here without branching.
|
||||
auto shift =
|
||||
builder.createIntegerConstant(loc, intType, intType.getWidth() - 1);
|
||||
auto mask = builder.create<mlir::SignedShiftRightOp>(loc, arg, shift);
|
||||
auto xored = builder.create<mlir::XOrOp>(loc, arg, mask);
|
||||
return builder.create<mlir::SubIOp>(loc, xored, mask);
|
||||
auto mask = builder.create<mlir::arith::ShRSIOp>(loc, arg, shift);
|
||||
auto xored = builder.create<mlir::arith::XOrIOp>(loc, arg, mask);
|
||||
return builder.create<mlir::arith::SubIOp>(loc, xored, mask);
|
||||
}
|
||||
if (fir::isa_complex(type)) {
|
||||
// Use HYPOT to fulfill the no underflow/overflow requirement.
|
||||
|
|
@ -1021,7 +1021,7 @@ mlir::Value IntrinsicLibrary::genConjg(mlir::Type resultType,
|
|||
auto imag =
|
||||
Fortran::lower::ComplexExprHelper{builder, loc}.extractComplexPart(
|
||||
cplx, /*isImagPart=*/true);
|
||||
auto negImag = builder.create<mlir::NegFOp>(loc, imag);
|
||||
auto negImag = builder.create<mlir::arith::NegFOp>(loc, imag);
|
||||
return Fortran::lower::ComplexExprHelper{builder, loc}.insertComplexPart(
|
||||
cplx, negImag, /*isImagPart=*/true);
|
||||
}
|
||||
|
|
@ -1032,16 +1032,16 @@ mlir::Value IntrinsicLibrary::genDim(mlir::Type resultType,
|
|||
assert(args.size() == 2);
|
||||
if (resultType.isa<mlir::IntegerType>()) {
|
||||
auto zero = builder.createIntegerConstant(loc, resultType, 0);
|
||||
auto diff = builder.create<mlir::SubIOp>(loc, args[0], args[1]);
|
||||
auto cmp =
|
||||
builder.create<mlir::CmpIOp>(loc, mlir::CmpIPredicate::sgt, diff, zero);
|
||||
auto diff = builder.create<mlir::arith::SubIOp>(loc, args[0], args[1]);
|
||||
auto cmp = builder.create<mlir::arith::CmpIOp>(
|
||||
loc, mlir::arith::CmpIPredicate::sgt, diff, zero);
|
||||
return builder.create<mlir::SelectOp>(loc, cmp, diff, zero);
|
||||
}
|
||||
assert(fir::isa_real(resultType) && "Only expects real and integer in DIM");
|
||||
auto zero = builder.createRealZeroConstant(loc, resultType);
|
||||
auto diff = builder.create<mlir::SubFOp>(loc, args[0], args[1]);
|
||||
auto cmp =
|
||||
builder.create<mlir::CmpFOp>(loc, mlir::CmpFPredicate::OGT, diff, zero);
|
||||
auto diff = builder.create<mlir::arith::SubFOp>(loc, args[0], args[1]);
|
||||
auto cmp = builder.create<mlir::arith::CmpFOp>(
|
||||
loc, mlir::arith::CmpFPredicate::OGT, diff, zero);
|
||||
return builder.create<mlir::SelectOp>(loc, cmp, diff, zero);
|
||||
}
|
||||
|
||||
|
|
@ -1053,7 +1053,7 @@ mlir::Value IntrinsicLibrary::genDprod(mlir::Type resultType,
|
|||
"Result must be double precision in DPROD");
|
||||
auto a = builder.createConvert(loc, resultType, args[0]);
|
||||
auto b = builder.createConvert(loc, resultType, args[1]);
|
||||
return builder.create<mlir::MulFOp>(loc, a, b);
|
||||
return builder.create<mlir::arith::MulFOp>(loc, a, b);
|
||||
}
|
||||
|
||||
// FLOOR
|
||||
|
|
@ -1072,7 +1072,7 @@ mlir::Value IntrinsicLibrary::genIAnd(mlir::Type resultType,
|
|||
llvm::ArrayRef<mlir::Value> args) {
|
||||
assert(args.size() == 2);
|
||||
|
||||
return builder.create<mlir::AndOp>(loc, args[0], args[1]);
|
||||
return builder.create<mlir::arith::AndIOp>(loc, args[0], args[1]);
|
||||
}
|
||||
|
||||
// ICHAR
|
||||
|
|
@ -1096,14 +1096,14 @@ mlir::Value IntrinsicLibrary::genIchar(mlir::Type resultType,
|
|||
mlir::Value IntrinsicLibrary::genIEOr(mlir::Type resultType,
|
||||
llvm::ArrayRef<mlir::Value> args) {
|
||||
assert(args.size() == 2);
|
||||
return builder.create<mlir::XOrOp>(loc, args[0], args[1]);
|
||||
return builder.create<mlir::arith::XOrIOp>(loc, args[0], args[1]);
|
||||
}
|
||||
|
||||
// IOR
|
||||
mlir::Value IntrinsicLibrary::genIOr(mlir::Type resultType,
|
||||
llvm::ArrayRef<mlir::Value> args) {
|
||||
assert(args.size() == 2);
|
||||
return builder.create<mlir::OrOp>(loc, args[0], args[1]);
|
||||
return builder.create<mlir::arith::OrIOp>(loc, args[0], args[1]);
|
||||
}
|
||||
|
||||
// LEN
|
||||
|
|
@ -1154,12 +1154,12 @@ mlir::Value IntrinsicLibrary::genMod(mlir::Type resultType,
|
|||
llvm::ArrayRef<mlir::Value> args) {
|
||||
assert(args.size() == 2);
|
||||
if (resultType.isa<mlir::IntegerType>())
|
||||
return builder.create<mlir::SignedRemIOp>(loc, args[0], args[1]);
|
||||
return builder.create<mlir::arith::RemSIOp>(loc, args[0], args[1]);
|
||||
|
||||
// Use runtime. Note that mlir::RemFOp implements floating point
|
||||
// Use runtime. Note that mlir::arith::RemFOp implements floating point
|
||||
// remainder, but it does not work with fir::Real type.
|
||||
// TODO: consider using mlir::RemFOp when possible, that may help folding
|
||||
// and optimizations.
|
||||
// TODO: consider using mlir::arith::RemFOp when possible, that may help
|
||||
// folding and optimizations.
|
||||
return genRuntimeCall("mod", resultType, args);
|
||||
}
|
||||
|
||||
|
|
@ -1179,17 +1179,18 @@ mlir::Value IntrinsicLibrary::genSign(mlir::Type resultType,
|
|||
auto abs = genAbs(resultType, {args[0]});
|
||||
if (resultType.isa<mlir::IntegerType>()) {
|
||||
auto zero = builder.createIntegerConstant(loc, resultType, 0);
|
||||
auto neg = builder.create<mlir::SubIOp>(loc, zero, abs);
|
||||
auto cmp = builder.create<mlir::CmpIOp>(loc, mlir::CmpIPredicate::slt,
|
||||
args[1], zero);
|
||||
auto neg = builder.create<mlir::arith::SubIOp>(loc, zero, abs);
|
||||
auto cmp = builder.create<mlir::arith::CmpIOp>(
|
||||
loc, mlir::arith::CmpIPredicate::slt, args[1], zero);
|
||||
return builder.create<mlir::SelectOp>(loc, cmp, neg, abs);
|
||||
}
|
||||
// TODO: Requirements when second argument is +0./0.
|
||||
auto zeroAttr = builder.getZeroAttr(resultType);
|
||||
auto zero = builder.create<mlir::ConstantOp>(loc, resultType, zeroAttr);
|
||||
auto neg = builder.create<mlir::NegFOp>(loc, abs);
|
||||
auto cmp = builder.create<mlir::CmpFOp>(loc, mlir::CmpFPredicate::OLT,
|
||||
args[1], zero);
|
||||
auto zero =
|
||||
builder.create<mlir::arith::ConstantOp>(loc, resultType, zeroAttr);
|
||||
auto neg = builder.create<mlir::arith::NegFOp>(loc, abs);
|
||||
auto cmp = builder.create<mlir::arith::CmpFOp>(
|
||||
loc, mlir::arith::CmpFPredicate::OLT, args[1], zero);
|
||||
return builder.create<mlir::SelectOp>(loc, cmp, neg, abs);
|
||||
}
|
||||
|
||||
|
|
@ -1198,12 +1199,12 @@ template <Extremum extremum, ExtremumBehavior behavior>
|
|||
static mlir::Value createExtremumCompare(mlir::Location loc,
|
||||
Fortran::lower::FirOpBuilder &builder,
|
||||
mlir::Value left, mlir::Value right) {
|
||||
static constexpr auto integerPredicate = extremum == Extremum::Max
|
||||
? mlir::CmpIPredicate::sgt
|
||||
: mlir::CmpIPredicate::slt;
|
||||
static constexpr auto integerPredicate =
|
||||
extremum == Extremum::Max ? mlir::arith::CmpIPredicate::sgt
|
||||
: mlir::arith::CmpIPredicate::slt;
|
||||
static constexpr auto orderedCmp = extremum == Extremum::Max
|
||||
? mlir::CmpFPredicate::OGT
|
||||
: mlir::CmpFPredicate::OLT;
|
||||
? mlir::arith::CmpFPredicate::OGT
|
||||
: mlir::arith::CmpFPredicate::OLT;
|
||||
auto type = left.getType();
|
||||
mlir::Value result;
|
||||
if (fir::isa_real(type)) {
|
||||
|
|
@ -1213,33 +1214,37 @@ static mlir::Value createExtremumCompare(mlir::Location loc,
|
|||
// Return the number if one of the inputs is NaN and the other is
|
||||
// a number.
|
||||
auto leftIsResult =
|
||||
builder.create<mlir::CmpFOp>(loc, orderedCmp, left, right);
|
||||
auto rightIsNan = builder.create<mlir::CmpFOp>(
|
||||
loc, mlir::CmpFPredicate::UNE, right, right);
|
||||
result = builder.create<mlir::OrOp>(loc, leftIsResult, rightIsNan);
|
||||
builder.create<mlir::arith::CmpFOp>(loc, orderedCmp, left, right);
|
||||
auto rightIsNan = builder.create<mlir::arith::CmpFOp>(
|
||||
loc, mlir::arith::CmpFPredicate::UNE, right, right);
|
||||
result =
|
||||
builder.create<mlir::arith::OrIOp>(loc, leftIsResult, rightIsNan);
|
||||
} else if constexpr (behavior == ExtremumBehavior::IeeeMinMaximum) {
|
||||
// Always return NaNs if one the input is NaNs
|
||||
auto leftIsResult =
|
||||
builder.create<mlir::CmpFOp>(loc, orderedCmp, left, right);
|
||||
auto leftIsNan = builder.create<mlir::CmpFOp>(
|
||||
loc, mlir::CmpFPredicate::UNE, left, left);
|
||||
result = builder.create<mlir::OrOp>(loc, leftIsResult, leftIsNan);
|
||||
builder.create<mlir::arith::CmpFOp>(loc, orderedCmp, left, right);
|
||||
auto leftIsNan = builder.create<mlir::arith::CmpFOp>(
|
||||
loc, mlir::arith::CmpFPredicate::UNE, left, left);
|
||||
result = builder.create<mlir::arith::OrIOp>(loc, leftIsResult, leftIsNan);
|
||||
} else if constexpr (behavior == ExtremumBehavior::MinMaxss) {
|
||||
// If the left is a NaN, return the right whatever it is.
|
||||
result = builder.create<mlir::CmpFOp>(loc, orderedCmp, left, right);
|
||||
result =
|
||||
builder.create<mlir::arith::CmpFOp>(loc, orderedCmp, left, right);
|
||||
} else if constexpr (behavior == ExtremumBehavior::PgfortranLlvm) {
|
||||
// If one of the operand is a NaN, return left whatever it is.
|
||||
static constexpr auto unorderedCmp = extremum == Extremum::Max
|
||||
? mlir::CmpFPredicate::UGT
|
||||
: mlir::CmpFPredicate::ULT;
|
||||
result = builder.create<mlir::CmpFOp>(loc, unorderedCmp, left, right);
|
||||
static constexpr auto unorderedCmp =
|
||||
extremum == Extremum::Max ? mlir::arith::CmpFPredicate::UGT
|
||||
: mlir::arith::CmpFPredicate::ULT;
|
||||
result =
|
||||
builder.create<mlir::arith::CmpFOp>(loc, unorderedCmp, left, right);
|
||||
} else {
|
||||
// TODO: ieeeMinNum/ieeeMaxNum
|
||||
static_assert(behavior == ExtremumBehavior::IeeeMinMaxNum,
|
||||
"ieeeMinNum/ieeeMaxNum behavior not implemented");
|
||||
}
|
||||
} else if (fir::isa_integer(type)) {
|
||||
result = builder.create<mlir::CmpIOp>(loc, integerPredicate, left, right);
|
||||
result =
|
||||
builder.create<mlir::arith::CmpIOp>(loc, integerPredicate, left, right);
|
||||
} else if (type.isa<fir::CharacterType>()) {
|
||||
// TODO: ! character min and max is tricky because the result
|
||||
// length is the length of the longest argument!
|
||||
|
|
|
|||
|
|
@ -62,11 +62,14 @@ namespace {
|
|||
/// ```
|
||||
/// %1 = fir.shape_shift %4, %5 : (index, index) -> !fir.shapeshift<1>
|
||||
/// %2 = fir.slice %6, %7, %8 : (index, index, index) -> !fir.slice<1>
|
||||
/// %3 = fir.embox %0 (%1) [%2] : (!fir.ref<!fir.array<?xi32>>, !fir.shapeshift<1>, !fir.slice<1>) -> !fir.box<!fir.array<?xi32>>
|
||||
/// %3 = fir.embox %0 (%1) [%2] : (!fir.ref<!fir.array<?xi32>>,
|
||||
/// !fir.shapeshift<1>, !fir.slice<1>) -> !fir.box<!fir.array<?xi32>>
|
||||
/// ```
|
||||
/// can be rewritten as
|
||||
/// ```
|
||||
/// %1 = fircg.ext_embox %0(%5) origin %4[%6, %7, %8] : (!fir.ref<!fir.array<?xi32>>, index, index, index, index, index) -> !fir.box<!fir.array<?xi32>>
|
||||
/// %1 = fircg.ext_embox %0(%5) origin %4[%6, %7, %8] :
|
||||
/// (!fir.ref<!fir.array<?xi32>>, index, index, index, index, index) ->
|
||||
/// !fir.box<!fir.array<?xi32>>
|
||||
/// ```
|
||||
class EmboxConversion : public mlir::OpRewritePattern<EmboxOp> {
|
||||
public:
|
||||
|
|
@ -94,7 +97,7 @@ public:
|
|||
auto idxTy = rewriter.getIndexType();
|
||||
for (auto ext : seqTy.getShape()) {
|
||||
auto iAttr = rewriter.getIndexAttr(ext);
|
||||
auto extVal = rewriter.create<mlir::ConstantOp>(loc, idxTy, iAttr);
|
||||
auto extVal = rewriter.create<mlir::arith::ConstantOp>(loc, idxTy, iAttr);
|
||||
shapeOpers.push_back(extVal);
|
||||
}
|
||||
auto xbox = rewriter.create<cg::XEmboxOp>(
|
||||
|
|
@ -139,11 +142,13 @@ public:
|
|||
///
|
||||
/// For example,
|
||||
/// ```
|
||||
/// %5 = fir.rebox %3(%1) : (!fir.box<!fir.array<?xi32>>, !fir.shapeshift<1>) -> !fir.box<!fir.array<?xi32>>
|
||||
/// %5 = fir.rebox %3(%1) : (!fir.box<!fir.array<?xi32>>, !fir.shapeshift<1>) ->
|
||||
/// !fir.box<!fir.array<?xi32>>
|
||||
/// ```
|
||||
/// converted to
|
||||
/// ```
|
||||
/// %5 = fircg.ext_rebox %3(%13) origin %12 : (!fir.box<!fir.array<?xi32>>, index, index) -> !fir.box<!fir.array<?xi32>>
|
||||
/// %5 = fircg.ext_rebox %3(%13) origin %12 : (!fir.box<!fir.array<?xi32>>,
|
||||
/// index, index) -> !fir.box<!fir.array<?xi32>>
|
||||
/// ```
|
||||
class ReboxConversion : public mlir::OpRewritePattern<ReboxOp> {
|
||||
public:
|
||||
|
|
@ -187,11 +192,14 @@ public:
|
|||
///
|
||||
/// For example,
|
||||
/// ```
|
||||
/// %4 = fir.array_coor %addr (%1) [%2] %0 : (!fir.ref<!fir.array<?xi32>>, !fir.shapeshift<1>, !fir.slice<1>, index) -> !fir.ref<i32>
|
||||
/// %4 = fir.array_coor %addr (%1) [%2] %0 : (!fir.ref<!fir.array<?xi32>>,
|
||||
/// !fir.shapeshift<1>, !fir.slice<1>, index) -> !fir.ref<i32>
|
||||
/// ```
|
||||
/// converted to
|
||||
/// ```
|
||||
/// %40 = fircg.ext_array_coor %addr(%9) origin %8[%4, %5, %6<%39> : (!fir.ref<!fir.array<?xi32>>, index, index, index, index, index, index) -> !fir.ref<i32>
|
||||
/// %40 = fircg.ext_array_coor %addr(%9) origin %8[%4, %5, %6<%39> :
|
||||
/// (!fir.ref<!fir.array<?xi32>>, index, index, index, index, index, index) ->
|
||||
/// !fir.ref<i32>
|
||||
/// ```
|
||||
class ArrayCoorConversion : public mlir::OpRewritePattern<ArrayCoorOp> {
|
||||
public:
|
||||
|
|
@ -237,8 +245,8 @@ public:
|
|||
auto &context = getContext();
|
||||
mlir::OpBuilder rewriter(&context);
|
||||
mlir::ConversionTarget target(context);
|
||||
target.addLegalDialect<FIROpsDialect, FIRCodeGenDialect,
|
||||
mlir::StandardOpsDialect>();
|
||||
target.addLegalDialect<mlir::arith::ArithmeticDialect, FIROpsDialect,
|
||||
FIRCodeGenDialect, mlir::StandardOpsDialect>();
|
||||
target.addIllegalOp<ArrayCoorOp>();
|
||||
target.addIllegalOp<ReboxOp>();
|
||||
target.addDynamicallyLegalOp<EmboxOp>([](EmboxOp embox) {
|
||||
|
|
|
|||
|
|
@ -10,6 +10,7 @@ add_flang_library(FIRDialect
|
|||
|
||||
LINK_LIBS
|
||||
FIRSupport
|
||||
MLIRArithmetic
|
||||
MLIROpenMPToLLVM
|
||||
MLIRLLVMToLLVMIRTranslation
|
||||
MLIRTargetLLVMIRExport
|
||||
|
|
|
|||
|
|
@ -638,12 +638,13 @@ void fir::CallOp::build(mlir::OpBuilder &builder, mlir::OperationState &result,
|
|||
template <typename OPTY>
|
||||
static void printCmpOp(OpAsmPrinter &p, OPTY op) {
|
||||
p << ' ';
|
||||
auto predSym = mlir::symbolizeCmpFPredicate(
|
||||
auto predSym = mlir::arith::symbolizeCmpFPredicate(
|
||||
op->template getAttrOfType<mlir::IntegerAttr>(
|
||||
OPTY::getPredicateAttrName())
|
||||
.getInt());
|
||||
assert(predSym.hasValue() && "invalid symbol value for predicate");
|
||||
p << '"' << mlir::stringifyCmpFPredicate(predSym.getValue()) << '"' << ", ";
|
||||
p << '"' << mlir::arith::stringifyCmpFPredicate(predSym.getValue()) << '"'
|
||||
<< ", ";
|
||||
p.printOperand(op.lhs());
|
||||
p << ", ";
|
||||
p.printOperand(op.rhs());
|
||||
|
|
@ -706,7 +707,7 @@ static mlir::LogicalResult verify(fir::CharConvertOp op) {
|
|||
//===----------------------------------------------------------------------===//
|
||||
|
||||
void fir::buildCmpCOp(OpBuilder &builder, OperationState &result,
|
||||
CmpFPredicate predicate, Value lhs, Value rhs) {
|
||||
arith::CmpFPredicate predicate, Value lhs, Value rhs) {
|
||||
result.addOperands({lhs, rhs});
|
||||
result.types.push_back(builder.getI1Type());
|
||||
result.addAttribute(
|
||||
|
|
@ -714,8 +715,9 @@ void fir::buildCmpCOp(OpBuilder &builder, OperationState &result,
|
|||
builder.getI64IntegerAttr(static_cast<int64_t>(predicate)));
|
||||
}
|
||||
|
||||
mlir::CmpFPredicate fir::CmpcOp::getPredicateByName(llvm::StringRef name) {
|
||||
auto pred = mlir::symbolizeCmpFPredicate(name);
|
||||
mlir::arith::CmpFPredicate
|
||||
fir::CmpcOp::getPredicateByName(llvm::StringRef name) {
|
||||
auto pred = mlir::arith::symbolizeCmpFPredicate(name);
|
||||
assert(pred.hasValue() && "invalid predicate name");
|
||||
return pred.getValue();
|
||||
}
|
||||
|
|
@ -1276,9 +1278,9 @@ template <bool AllowFields>
|
|||
static void appendAsAttribute(llvm::SmallVectorImpl<mlir::Attribute> &attrs,
|
||||
mlir::Value val) {
|
||||
if (auto *op = val.getDefiningOp()) {
|
||||
if (auto cop = mlir::dyn_cast<mlir::ConstantOp>(op)) {
|
||||
if (auto cop = mlir::dyn_cast<mlir::arith::ConstantOp>(op)) {
|
||||
// append the integer constant value
|
||||
if (auto iattr = cop.getValue().dyn_cast<mlir::IntegerAttr>()) {
|
||||
if (auto iattr = cop.value().dyn_cast<mlir::IntegerAttr>()) {
|
||||
attrs.push_back(iattr);
|
||||
return;
|
||||
}
|
||||
|
|
@ -1505,8 +1507,8 @@ struct UndoComplexPattern : public mlir::RewritePattern {
|
|||
|
||||
void fir::InsertValueOp::getCanonicalizationPatterns(
|
||||
mlir::OwningRewritePatternList &results, mlir::MLIRContext *context) {
|
||||
results.insert<UndoComplexPattern<mlir::AddFOp, fir::AddcOp>,
|
||||
UndoComplexPattern<mlir::SubFOp, fir::SubcOp>>(context);
|
||||
results.insert<UndoComplexPattern<mlir::arith::AddFOp, fir::AddcOp>,
|
||||
UndoComplexPattern<mlir::arith::SubFOp, fir::SubcOp>>(context);
|
||||
}
|
||||
|
||||
//===----------------------------------------------------------------------===//
|
||||
|
|
@ -3239,7 +3241,7 @@ mlir::Type fir::applyPathToType(mlir::Type eleTy, mlir::ValueRange path) {
|
|||
if (auto *op = (*i++).getDefiningOp()) {
|
||||
if (auto off = mlir::dyn_cast<fir::FieldIndexOp>(op))
|
||||
return ty.getType(off.getFieldName());
|
||||
if (auto off = mlir::dyn_cast<mlir::ConstantOp>(op))
|
||||
if (auto off = mlir::dyn_cast<mlir::arith::ConstantOp>(op))
|
||||
return ty.getType(fir::toInt(off));
|
||||
}
|
||||
return mlir::Type{};
|
||||
|
|
@ -3254,7 +3256,7 @@ mlir::Type fir::applyPathToType(mlir::Type eleTy, mlir::ValueRange path) {
|
|||
})
|
||||
.Case<mlir::TupleType>([&](mlir::TupleType ty) {
|
||||
if (auto *op = (*i++).getDefiningOp())
|
||||
if (auto off = mlir::dyn_cast<mlir::ConstantOp>(op))
|
||||
if (auto off = mlir::dyn_cast<mlir::arith::ConstantOp>(op))
|
||||
return ty.getType(fir::toInt(off));
|
||||
return mlir::Type{};
|
||||
})
|
||||
|
|
|
|||
|
|
@ -248,7 +248,8 @@ public:
|
|||
return;
|
||||
|
||||
// Convert the calls and, if needed, the ReturnOp in the function body.
|
||||
target.addLegalDialect<fir::FIROpsDialect, mlir::StandardOpsDialect>();
|
||||
target.addLegalDialect<fir::FIROpsDialect, mlir::arith::ArithmeticDialect,
|
||||
mlir::StandardOpsDialect>();
|
||||
target.addIllegalOp<fir::SaveResultOp>();
|
||||
target.addDynamicallyLegalOp<fir::CallOp>([](fir::CallOp call) {
|
||||
return !mustConvertCallOrFunc(call.getFunctionType());
|
||||
|
|
|
|||
|
|
@ -144,6 +144,7 @@ public:
|
|||
return true;
|
||||
});
|
||||
target.addLegalDialect<FIROpsDialect, mlir::scf::SCFDialect,
|
||||
mlir::arith::ArithmeticDialect,
|
||||
mlir::StandardOpsDialect>();
|
||||
|
||||
if (mlir::failed(mlir::applyPartialConversion(function, target,
|
||||
|
|
|
|||
|
|
@ -157,7 +157,7 @@ struct AffineIfCondition {
|
|||
using MaybeAffineExpr = llvm::Optional<mlir::AffineExpr>;
|
||||
|
||||
explicit AffineIfCondition(mlir::Value fc) : firCondition(fc) {
|
||||
if (auto condDef = firCondition.getDefiningOp<mlir::CmpIOp>())
|
||||
if (auto condDef = firCondition.getDefiningOp<mlir::arith::CmpIOp>())
|
||||
fromCmpIOp(condDef);
|
||||
}
|
||||
|
||||
|
|
@ -193,19 +193,19 @@ private:
|
|||
/// in an affine expression, this includes -, +, *, rem, constant.
|
||||
/// block arguments of a loopOp or forOp are used as dimensions
|
||||
MaybeAffineExpr toAffineExpr(mlir::Value value) {
|
||||
if (auto op = value.getDefiningOp<mlir::SubIOp>())
|
||||
if (auto op = value.getDefiningOp<mlir::arith::SubIOp>())
|
||||
return affineBinaryOp(mlir::AffineExprKind::Add, toAffineExpr(op.lhs()),
|
||||
affineBinaryOp(mlir::AffineExprKind::Mul,
|
||||
toAffineExpr(op.rhs()),
|
||||
toAffineExpr(-1)));
|
||||
if (auto op = value.getDefiningOp<mlir::AddIOp>())
|
||||
if (auto op = value.getDefiningOp<mlir::arith::AddIOp>())
|
||||
return affineBinaryOp(mlir::AffineExprKind::Add, op.lhs(), op.rhs());
|
||||
if (auto op = value.getDefiningOp<mlir::MulIOp>())
|
||||
if (auto op = value.getDefiningOp<mlir::arith::MulIOp>())
|
||||
return affineBinaryOp(mlir::AffineExprKind::Mul, op.lhs(), op.rhs());
|
||||
if (auto op = value.getDefiningOp<mlir::UnsignedRemIOp>())
|
||||
if (auto op = value.getDefiningOp<mlir::arith::RemUIOp>())
|
||||
return affineBinaryOp(mlir::AffineExprKind::Mod, op.lhs(), op.rhs());
|
||||
if (auto op = value.getDefiningOp<mlir::ConstantOp>())
|
||||
if (auto intConstant = op.getValue().dyn_cast<IntegerAttr>())
|
||||
if (auto op = value.getDefiningOp<mlir::arith::ConstantOp>())
|
||||
if (auto intConstant = op.value().dyn_cast<IntegerAttr>())
|
||||
return toAffineExpr(intConstant.getInt());
|
||||
if (auto blockArg = value.dyn_cast<mlir::BlockArgument>()) {
|
||||
affineArgs.push_back(value);
|
||||
|
|
@ -217,7 +217,7 @@ private:
|
|||
return {};
|
||||
}
|
||||
|
||||
void fromCmpIOp(mlir::CmpIOp cmpOp) {
|
||||
void fromCmpIOp(mlir::arith::CmpIOp cmpOp) {
|
||||
auto lhsAffine = toAffineExpr(cmpOp.lhs());
|
||||
auto rhsAffine = toAffineExpr(cmpOp.rhs());
|
||||
if (!lhsAffine.hasValue() || !rhsAffine.hasValue())
|
||||
|
|
@ -233,17 +233,17 @@ private:
|
|||
}
|
||||
|
||||
llvm::Optional<std::pair<AffineExpr, bool>>
|
||||
constraint(mlir::CmpIPredicate predicate, mlir::AffineExpr basic) {
|
||||
constraint(mlir::arith::CmpIPredicate predicate, mlir::AffineExpr basic) {
|
||||
switch (predicate) {
|
||||
case mlir::CmpIPredicate::slt:
|
||||
case mlir::arith::CmpIPredicate::slt:
|
||||
return {std::make_pair(basic - 1, false)};
|
||||
case mlir::CmpIPredicate::sle:
|
||||
case mlir::arith::CmpIPredicate::sle:
|
||||
return {std::make_pair(basic, false)};
|
||||
case mlir::CmpIPredicate::sgt:
|
||||
case mlir::arith::CmpIPredicate::sgt:
|
||||
return {std::make_pair(1 - basic, false)};
|
||||
case mlir::CmpIPredicate::sge:
|
||||
case mlir::arith::CmpIPredicate::sge:
|
||||
return {std::make_pair(0 - basic, false)};
|
||||
case mlir::CmpIPredicate::eq:
|
||||
case mlir::arith::CmpIPredicate::eq:
|
||||
return {std::make_pair(basic, true)};
|
||||
default:
|
||||
return {};
|
||||
|
|
@ -315,8 +315,8 @@ static mlir::AffineMap createArrayIndexAffineMap(unsigned dimensions,
|
|||
}
|
||||
|
||||
static Optional<int64_t> constantIntegerLike(const mlir::Value value) {
|
||||
if (auto definition = value.getDefiningOp<ConstantOp>())
|
||||
if (auto stepAttr = definition.getValue().dyn_cast<IntegerAttr>())
|
||||
if (auto definition = value.getDefiningOp<mlir::arith::ConstantOp>())
|
||||
if (auto stepAttr = definition.value().dyn_cast<IntegerAttr>())
|
||||
return stepAttr.getInt();
|
||||
return {};
|
||||
}
|
||||
|
|
@ -335,7 +335,7 @@ static mlir::Type coordinateArrayElement(fir::ArrayCoorOp op) {
|
|||
static void populateIndexArgs(fir::ArrayCoorOp acoOp, fir::ShapeOp shape,
|
||||
SmallVectorImpl<mlir::Value> &indexArgs,
|
||||
mlir::PatternRewriter &rewriter) {
|
||||
auto one = rewriter.create<mlir::ConstantOp>(
|
||||
auto one = rewriter.create<mlir::arith::ConstantOp>(
|
||||
acoOp.getLoc(), rewriter.getIndexType(), rewriter.getIndexAttr(1));
|
||||
auto extents = shape.extents();
|
||||
for (auto i = extents.begin(); i < extents.end(); i++) {
|
||||
|
|
@ -348,7 +348,7 @@ static void populateIndexArgs(fir::ArrayCoorOp acoOp, fir::ShapeOp shape,
|
|||
static void populateIndexArgs(fir::ArrayCoorOp acoOp, fir::ShapeShiftOp shape,
|
||||
SmallVectorImpl<mlir::Value> &indexArgs,
|
||||
mlir::PatternRewriter &rewriter) {
|
||||
auto one = rewriter.create<mlir::ConstantOp>(
|
||||
auto one = rewriter.create<mlir::arith::ConstantOp>(
|
||||
acoOp.getLoc(), rewriter.getIndexType(), rewriter.getIndexAttr(1));
|
||||
auto extents = shape.pairs();
|
||||
for (auto i = extents.begin(); i < extents.end();) {
|
||||
|
|
@ -579,8 +579,9 @@ public:
|
|||
patterns.insert<AffineIfConversion>(context, functionAnalysis);
|
||||
patterns.insert<AffineLoopConversion>(context, functionAnalysis);
|
||||
mlir::ConversionTarget target = *context;
|
||||
target.addLegalDialect<mlir::AffineDialect, FIROpsDialect,
|
||||
mlir::scf::SCFDialect, mlir::StandardOpsDialect>();
|
||||
target.addLegalDialect<
|
||||
mlir::AffineDialect, FIROpsDialect, mlir::scf::SCFDialect,
|
||||
mlir::arith::ArithmeticDialect, mlir::StandardOpsDialect>();
|
||||
target.addDynamicallyLegalOp<IfOp>([&functionAnalysis](fir::IfOp op) {
|
||||
return !(functionAnalysis.getChildIfAnalysis(op).canPromoteToAffine());
|
||||
});
|
||||
|
|
|
|||
|
|
@ -43,11 +43,11 @@ public:
|
|||
<< "running character conversion on " << conv << '\n');
|
||||
|
||||
// Establish a loop that executes count iterations.
|
||||
auto zero = rewriter.create<mlir::ConstantIndexOp>(loc, 0);
|
||||
auto one = rewriter.create<mlir::ConstantIndexOp>(loc, 1);
|
||||
auto zero = rewriter.create<mlir::arith::ConstantIndexOp>(loc, 0);
|
||||
auto one = rewriter.create<mlir::arith::ConstantIndexOp>(loc, 1);
|
||||
auto idxTy = rewriter.getIndexType();
|
||||
auto castCnt = rewriter.create<fir::ConvertOp>(loc, idxTy, conv.count());
|
||||
auto countm1 = rewriter.create<mlir::SubIOp>(loc, castCnt, one);
|
||||
auto countm1 = rewriter.create<mlir::arith::SubIOp>(loc, castCnt, one);
|
||||
auto loop = rewriter.create<fir::DoLoopOp>(loc, zero, countm1, one);
|
||||
auto insPt = rewriter.saveInsertionPoint();
|
||||
rewriter.setInsertionPointToStart(loop.getBody());
|
||||
|
|
@ -83,7 +83,8 @@ public:
|
|||
mlir::Value icast =
|
||||
(fromBits >= toBits)
|
||||
? rewriter.create<fir::ConvertOp>(loc, toTy, load).getResult()
|
||||
: rewriter.create<mlir::ZeroExtendIOp>(loc, toTy, load).getResult();
|
||||
: rewriter.create<mlir::arith::ExtUIOp>(loc, toTy, load)
|
||||
.getResult();
|
||||
rewriter.replaceOpWithNewOp<fir::StoreOp>(conv, icast, toi);
|
||||
rewriter.restoreInsertionPoint(insPt);
|
||||
return mlir::success();
|
||||
|
|
@ -104,6 +105,7 @@ public:
|
|||
patterns.insert<CharacterConvertConversion>(context);
|
||||
mlir::ConversionTarget target(*context);
|
||||
target.addLegalDialect<mlir::AffineDialect, fir::FIROpsDialect,
|
||||
mlir::arith::ArithmeticDialect,
|
||||
mlir::StandardOpsDialect>();
|
||||
|
||||
// apply the patterns
|
||||
|
|
|
|||
|
|
@ -65,16 +65,16 @@ public:
|
|||
|
||||
// Initalization block
|
||||
rewriter.setInsertionPointToEnd(initBlock);
|
||||
auto diff = rewriter.create<mlir::SubIOp>(loc, high, low);
|
||||
auto distance = rewriter.create<mlir::AddIOp>(loc, diff, step);
|
||||
auto diff = rewriter.create<mlir::arith::SubIOp>(loc, high, low);
|
||||
auto distance = rewriter.create<mlir::arith::AddIOp>(loc, diff, step);
|
||||
mlir::Value iters =
|
||||
rewriter.create<mlir::SignedDivIOp>(loc, distance, step);
|
||||
rewriter.create<mlir::arith::DivSIOp>(loc, distance, step);
|
||||
|
||||
if (forceLoopToExecuteOnce) {
|
||||
auto zero = rewriter.create<mlir::ConstantIndexOp>(loc, 0);
|
||||
auto cond =
|
||||
rewriter.create<mlir::CmpIOp>(loc, CmpIPredicate::sle, iters, zero);
|
||||
auto one = rewriter.create<mlir::ConstantIndexOp>(loc, 1);
|
||||
auto zero = rewriter.create<mlir::arith::ConstantIndexOp>(loc, 0);
|
||||
auto cond = rewriter.create<mlir::arith::CmpIOp>(
|
||||
loc, arith::CmpIPredicate::sle, iters, zero);
|
||||
auto one = rewriter.create<mlir::arith::ConstantIndexOp>(loc, 1);
|
||||
iters = rewriter.create<mlir::SelectOp>(loc, cond, one, iters);
|
||||
}
|
||||
|
||||
|
|
@ -90,13 +90,14 @@ public:
|
|||
auto *terminator = lastBlock->getTerminator();
|
||||
rewriter.setInsertionPointToEnd(lastBlock);
|
||||
auto iv = conditionalBlock->getArgument(0);
|
||||
mlir::Value steppedIndex = rewriter.create<mlir::AddIOp>(loc, iv, step);
|
||||
mlir::Value steppedIndex =
|
||||
rewriter.create<mlir::arith::AddIOp>(loc, iv, step);
|
||||
assert(steppedIndex && "must be a Value");
|
||||
auto lastArg = conditionalBlock->getNumArguments() - 1;
|
||||
auto itersLeft = conditionalBlock->getArgument(lastArg);
|
||||
auto one = rewriter.create<mlir::ConstantIndexOp>(loc, 1);
|
||||
auto one = rewriter.create<mlir::arith::ConstantIndexOp>(loc, 1);
|
||||
mlir::Value itersMinusOne =
|
||||
rewriter.create<mlir::SubIOp>(loc, itersLeft, one);
|
||||
rewriter.create<mlir::arith::SubIOp>(loc, itersLeft, one);
|
||||
|
||||
llvm::SmallVector<mlir::Value> loopCarried;
|
||||
loopCarried.push_back(steppedIndex);
|
||||
|
|
@ -109,9 +110,9 @@ public:
|
|||
|
||||
// Conditional block
|
||||
rewriter.setInsertionPointToEnd(conditionalBlock);
|
||||
auto zero = rewriter.create<mlir::ConstantIndexOp>(loc, 0);
|
||||
auto comparison =
|
||||
rewriter.create<mlir::CmpIOp>(loc, CmpIPredicate::sgt, itersLeft, zero);
|
||||
auto zero = rewriter.create<mlir::arith::ConstantIndexOp>(loc, 0);
|
||||
auto comparison = rewriter.create<mlir::arith::CmpIOp>(
|
||||
loc, arith::CmpIPredicate::sgt, itersLeft, zero);
|
||||
|
||||
rewriter.create<mlir::CondBranchOp>(loc, comparison, firstBlock,
|
||||
llvm::ArrayRef<mlir::Value>(), endBlock,
|
||||
|
|
@ -237,7 +238,7 @@ public:
|
|||
auto *terminator = lastBodyBlock->getTerminator();
|
||||
rewriter.setInsertionPointToEnd(lastBodyBlock);
|
||||
auto step = whileOp.step();
|
||||
mlir::Value stepped = rewriter.create<mlir::AddIOp>(loc, iv, step);
|
||||
mlir::Value stepped = rewriter.create<mlir::arith::AddIOp>(loc, iv, step);
|
||||
assert(stepped && "must be a Value");
|
||||
|
||||
llvm::SmallVector<mlir::Value> loopCarried;
|
||||
|
|
@ -267,20 +268,21 @@ public:
|
|||
// The comparison depends on the sign of the step value. We fully expect
|
||||
// this expression to be folded by the optimizer or LLVM. This expression
|
||||
// is written this way so that `step == 0` always returns `false`.
|
||||
auto zero = rewriter.create<mlir::ConstantIndexOp>(loc, 0);
|
||||
auto compl0 =
|
||||
rewriter.create<mlir::CmpIOp>(loc, CmpIPredicate::slt, zero, step);
|
||||
auto compl1 =
|
||||
rewriter.create<mlir::CmpIOp>(loc, CmpIPredicate::sle, iv, upperBound);
|
||||
auto compl2 =
|
||||
rewriter.create<mlir::CmpIOp>(loc, CmpIPredicate::slt, step, zero);
|
||||
auto compl3 =
|
||||
rewriter.create<mlir::CmpIOp>(loc, CmpIPredicate::sle, upperBound, iv);
|
||||
auto cmp0 = rewriter.create<mlir::AndOp>(loc, compl0, compl1);
|
||||
auto cmp1 = rewriter.create<mlir::AndOp>(loc, compl2, compl3);
|
||||
auto cmp2 = rewriter.create<mlir::OrOp>(loc, cmp0, cmp1);
|
||||
auto zero = rewriter.create<mlir::arith::ConstantIndexOp>(loc, 0);
|
||||
auto compl0 = rewriter.create<mlir::arith::CmpIOp>(
|
||||
loc, arith::CmpIPredicate::slt, zero, step);
|
||||
auto compl1 = rewriter.create<mlir::arith::CmpIOp>(
|
||||
loc, arith::CmpIPredicate::sle, iv, upperBound);
|
||||
auto compl2 = rewriter.create<mlir::arith::CmpIOp>(
|
||||
loc, arith::CmpIPredicate::slt, step, zero);
|
||||
auto compl3 = rewriter.create<mlir::arith::CmpIOp>(
|
||||
loc, arith::CmpIPredicate::sle, upperBound, iv);
|
||||
auto cmp0 = rewriter.create<mlir::arith::AndIOp>(loc, compl0, compl1);
|
||||
auto cmp1 = rewriter.create<mlir::arith::AndIOp>(loc, compl2, compl3);
|
||||
auto cmp2 = rewriter.create<mlir::arith::OrIOp>(loc, cmp0, cmp1);
|
||||
// Remember to AND in the early-exit bool.
|
||||
auto comparison = rewriter.create<mlir::AndOp>(loc, iterateVar, cmp2);
|
||||
auto comparison =
|
||||
rewriter.create<mlir::arith::AndIOp>(loc, iterateVar, cmp2);
|
||||
rewriter.create<mlir::CondBranchOp>(loc, comparison, firstBodyBlock,
|
||||
llvm::ArrayRef<mlir::Value>(), endBlock,
|
||||
llvm::ArrayRef<mlir::Value>());
|
||||
|
|
|
|||
|
|
@ -28,9 +28,9 @@ func private @boxfunc(i64) -> !fir.box<!fir.heap<f64>>
|
|||
func private @arrayfunc_callee(%n : index) -> !fir.array<?xf32> {
|
||||
%buffer = fir.alloca !fir.array<?xf32>, %n
|
||||
// Do something with result (res(4) = 42.)
|
||||
%c4 = constant 4 : i64
|
||||
%c4 = arith.constant 4 : i64
|
||||
%coor = fir.coordinate_of %buffer, %c4 : (!fir.ref<!fir.array<?xf32>>, i64) -> !fir.ref<f32>
|
||||
%cst = constant 4.200000e+01 : f32
|
||||
%cst = arith.constant 4.200000e+01 : f32
|
||||
fir.store %cst to %coor : !fir.ref<f32>
|
||||
%res = fir.load %buffer : !fir.ref<!fir.array<?xf32>>
|
||||
return %res : !fir.array<?xf32>
|
||||
|
|
@ -90,19 +90,19 @@ func @boxfunc_callee() -> !fir.box<!fir.heap<f64>> {
|
|||
// CHECK-LABEL: func @call_arrayfunc() {
|
||||
// CHECK-BOX-LABEL: func @call_arrayfunc() {
|
||||
func @call_arrayfunc() {
|
||||
%c100 = constant 100 : index
|
||||
%c100 = arith.constant 100 : index
|
||||
%buffer = fir.alloca !fir.array<?xf32>, %c100
|
||||
%shape = fir.shape %c100 : (index) -> !fir.shape<1>
|
||||
%res = fir.call @arrayfunc_callee(%c100) : (index) -> !fir.array<?xf32>
|
||||
fir.save_result %res to %buffer(%shape) : !fir.array<?xf32>, !fir.ref<!fir.array<?xf32>>, !fir.shape<1>
|
||||
return
|
||||
|
||||
// CHECK: %[[c100:.*]] = constant 100 : index
|
||||
// CHECK: %[[c100:.*]] = arith.constant 100 : index
|
||||
// CHECK: %[[buffer:.*]] = fir.alloca !fir.array<?xf32>, %[[c100]]
|
||||
// CHECK: fir.call @arrayfunc_callee(%[[buffer]], %[[c100]]) : (!fir.ref<!fir.array<?xf32>>, index) -> ()
|
||||
// CHECK-NOT: fir.save_result
|
||||
|
||||
// CHECK-BOX: %[[c100:.*]] = constant 100 : index
|
||||
// CHECK-BOX: %[[c100:.*]] = arith.constant 100 : index
|
||||
// CHECK-BOX: %[[buffer:.*]] = fir.alloca !fir.array<?xf32>, %[[c100]]
|
||||
// CHECK-BOX: %[[shape:.*]] = fir.shape %[[c100]] : (index) -> !fir.shape<1>
|
||||
// CHECK-BOX: %[[box:.*]] = fir.embox %[[buffer]](%[[shape]]) : (!fir.ref<!fir.array<?xf32>>, !fir.shape<1>) -> !fir.box<!fir.array<?xf32>>
|
||||
|
|
@ -114,17 +114,17 @@ func @call_arrayfunc() {
|
|||
// CHECK-BOX-LABEL: func @call_derivedfunc() {
|
||||
func @call_derivedfunc() {
|
||||
%buffer = fir.alloca !fir.type<t{x:f32}>
|
||||
%cst = constant 4.200000e+01 : f32
|
||||
%cst = arith.constant 4.200000e+01 : f32
|
||||
%res = fir.call @derivedfunc_callee(%cst) : (f32) -> !fir.type<t{x:f32}>
|
||||
fir.save_result %res to %buffer : !fir.type<t{x:f32}>, !fir.ref<!fir.type<t{x:f32}>>
|
||||
return
|
||||
// CHECK: %[[buffer:.*]] = fir.alloca !fir.type<t{x:f32}>
|
||||
// CHECK: %[[cst:.*]] = constant {{.*}} : f32
|
||||
// CHECK: %[[cst:.*]] = arith.constant {{.*}} : f32
|
||||
// CHECK: fir.call @derivedfunc_callee(%[[buffer]], %[[cst]]) : (!fir.ref<!fir.type<t{x:f32}>>, f32) -> ()
|
||||
// CHECK-NOT: fir.save_result
|
||||
|
||||
// CHECK-BOX: %[[buffer:.*]] = fir.alloca !fir.type<t{x:f32}>
|
||||
// CHECK-BOX: %[[cst:.*]] = constant {{.*}} : f32
|
||||
// CHECK-BOX: %[[cst:.*]] = arith.constant {{.*}} : f32
|
||||
// CHECK-BOX: %[[box:.*]] = fir.embox %[[buffer]] : (!fir.ref<!fir.type<t{x:f32}>>) -> !fir.box<!fir.type<t{x:f32}>>
|
||||
// CHECK-BOX: fir.call @derivedfunc_callee(%[[box]], %[[cst]]) : (!fir.box<!fir.type<t{x:f32}>>, f32) -> ()
|
||||
// CHECK-BOX-NOT: fir.save_result
|
||||
|
|
@ -137,19 +137,19 @@ func private @derived_lparams_func() -> !fir.type<t2(l1:i32,l2:i32){x:f32}>
|
|||
// CHECK-BOX-LABEL: func @call_derived_lparams_func(
|
||||
// CHECK-BOX-SAME: %[[buffer:.*]]: !fir.ref<!fir.type<t2(l1:i32,l2:i32){x:f32}>>
|
||||
func @call_derived_lparams_func(%buffer: !fir.ref<!fir.type<t2(l1:i32,l2:i32){x:f32}>>) {
|
||||
%l1 = constant 3 : i32
|
||||
%l2 = constant 5 : i32
|
||||
%l1 = arith.constant 3 : i32
|
||||
%l2 = arith.constant 5 : i32
|
||||
%res = fir.call @derived_lparams_func() : () -> !fir.type<t2(l1:i32,l2:i32){x:f32}>
|
||||
fir.save_result %res to %buffer typeparams %l1, %l2 : !fir.type<t2(l1:i32,l2:i32){x:f32}>, !fir.ref<!fir.type<t2(l1:i32,l2:i32){x:f32}>>, i32, i32
|
||||
return
|
||||
|
||||
// CHECK: %[[l1:.*]] = constant 3 : i32
|
||||
// CHECK: %[[l2:.*]] = constant 5 : i32
|
||||
// CHECK: %[[l1:.*]] = arith.constant 3 : i32
|
||||
// CHECK: %[[l2:.*]] = arith.constant 5 : i32
|
||||
// CHECK: fir.call @derived_lparams_func(%[[buffer]]) : (!fir.ref<!fir.type<t2(l1:i32,l2:i32){x:f32}>>) -> ()
|
||||
// CHECK-NOT: fir.save_result
|
||||
|
||||
// CHECK-BOX: %[[l1:.*]] = constant 3 : i32
|
||||
// CHECK-BOX: %[[l2:.*]] = constant 5 : i32
|
||||
// CHECK-BOX: %[[l1:.*]] = arith.constant 3 : i32
|
||||
// CHECK-BOX: %[[l2:.*]] = arith.constant 5 : i32
|
||||
// CHECK-BOX: %[[box:.*]] = fir.embox %[[buffer]] typeparams %[[l1]], %[[l2]] : (!fir.ref<!fir.type<t2(l1:i32,l2:i32){x:f32}>>, i32, i32) -> !fir.box<!fir.type<t2(l1:i32,l2:i32){x:f32}>>
|
||||
// CHECK-BOX: fir.call @derived_lparams_func(%[[box]]) : (!fir.box<!fir.type<t2(l1:i32,l2:i32){x:f32}>>) -> ()
|
||||
// CHECK-BOX-NOT: fir.save_result
|
||||
|
|
@ -177,22 +177,22 @@ func private @chararrayfunc(index, index) -> !fir.array<?x!fir.char<1,?>>
|
|||
// CHECK-LABEL: func @call_chararrayfunc() {
|
||||
// CHECK-BOX-LABEL: func @call_chararrayfunc() {
|
||||
func @call_chararrayfunc() {
|
||||
%c100 = constant 100 : index
|
||||
%c50 = constant 50 : index
|
||||
%c100 = arith.constant 100 : index
|
||||
%c50 = arith.constant 50 : index
|
||||
%buffer = fir.alloca !fir.array<?x!fir.char<1,?>>(%c100 : index), %c50
|
||||
%shape = fir.shape %c100 : (index) -> !fir.shape<1>
|
||||
%res = fir.call @chararrayfunc(%c100, %c50) : (index, index) -> !fir.array<?x!fir.char<1,?>>
|
||||
fir.save_result %res to %buffer(%shape) typeparams %c50 : !fir.array<?x!fir.char<1,?>>, !fir.ref<!fir.array<?x!fir.char<1,?>>>, !fir.shape<1>, index
|
||||
return
|
||||
|
||||
// CHECK: %[[c100:.*]] = constant 100 : index
|
||||
// CHECK: %[[c50:.*]] = constant 50 : index
|
||||
// CHECK: %[[c100:.*]] = arith.constant 100 : index
|
||||
// CHECK: %[[c50:.*]] = arith.constant 50 : index
|
||||
// CHECK: %[[buffer:.*]] = fir.alloca !fir.array<?x!fir.char<1,?>>(%[[c100]] : index), %[[c50]]
|
||||
// CHECK: fir.call @chararrayfunc(%[[buffer]], %[[c100]], %[[c50]]) : (!fir.ref<!fir.array<?x!fir.char<1,?>>>, index, index) -> ()
|
||||
// CHECK-NOT: fir.save_result
|
||||
|
||||
// CHECK-BOX: %[[c100:.*]] = constant 100 : index
|
||||
// CHECK-BOX: %[[c50:.*]] = constant 50 : index
|
||||
// CHECK-BOX: %[[c100:.*]] = arith.constant 100 : index
|
||||
// CHECK-BOX: %[[c50:.*]] = arith.constant 50 : index
|
||||
// CHECK-BOX: %[[buffer:.*]] = fir.alloca !fir.array<?x!fir.char<1,?>>(%[[c100]] : index), %[[c50]]
|
||||
// CHECK-BOX: %[[shape:.*]] = fir.shape %[[c100]] : (index) -> !fir.shape<1>
|
||||
// CHECK-BOX: %[[box:.*]] = fir.embox %[[buffer]](%[[shape]]) typeparams %[[c50]] : (!fir.ref<!fir.array<?x!fir.char<1,?>>>, !fir.shape<1>, index) -> !fir.box<!fir.array<?x!fir.char<1,?>>>
|
||||
|
|
@ -228,7 +228,7 @@ func @test_address_of() {
|
|||
// CHECK-BOX-LABEL: func @test_indirect_calls(
|
||||
// CHECK-BOX-SAME: %[[arg0:.*]]: () -> ()) {
|
||||
func @test_indirect_calls(%arg0: () -> ()) {
|
||||
%c100 = constant 100 : index
|
||||
%c100 = arith.constant 100 : index
|
||||
%buffer = fir.alloca !fir.array<?xf32>, %c100
|
||||
%shape = fir.shape %c100 : (index) -> !fir.shape<1>
|
||||
%0 = fir.convert %arg0 : (() -> ()) -> ((index) -> !fir.array<?xf32>)
|
||||
|
|
@ -236,7 +236,7 @@ func @test_indirect_calls(%arg0: () -> ()) {
|
|||
fir.save_result %res to %buffer(%shape) : !fir.array<?xf32>, !fir.ref<!fir.array<?xf32>>, !fir.shape<1>
|
||||
return
|
||||
|
||||
// CHECK: %[[c100:.*]] = constant 100 : index
|
||||
// CHECK: %[[c100:.*]] = arith.constant 100 : index
|
||||
// CHECK: %[[buffer:.*]] = fir.alloca !fir.array<?xf32>, %[[c100]]
|
||||
// CHECK: %[[shape:.*]] = fir.shape %[[c100]] : (index) -> !fir.shape<1>
|
||||
// CHECK: %[[original_conv:.*]] = fir.convert %[[arg0]] : (() -> ()) -> ((index) -> !fir.array<?xf32>)
|
||||
|
|
@ -244,7 +244,7 @@ func @test_indirect_calls(%arg0: () -> ()) {
|
|||
// CHECK: fir.call %[[conv]](%[[buffer]], %c100) : (!fir.ref<!fir.array<?xf32>>, index) -> ()
|
||||
// CHECK-NOT: fir.save_result
|
||||
|
||||
// CHECK-BOX: %[[c100:.*]] = constant 100 : index
|
||||
// CHECK-BOX: %[[c100:.*]] = arith.constant 100 : index
|
||||
// CHECK-BOX: %[[buffer:.*]] = fir.alloca !fir.array<?xf32>, %[[c100]]
|
||||
// CHECK-BOX: %[[shape:.*]] = fir.shape %[[c100]] : (index) -> !fir.shape<1>
|
||||
// CHECK-BOX: %[[original_conv:.*]] = fir.convert %[[arg0]] : (() -> ()) -> ((index) -> !fir.array<?xf32>)
|
||||
|
|
|
|||
|
|
@ -7,8 +7,8 @@
|
|||
#map2 = affine_map<(d0)[s0, s1, s2] -> (d0 * s2 - s0)>
|
||||
module {
|
||||
func @calc(%arg0: !fir.ref<!fir.array<?xf32>>, %arg1: !fir.ref<!fir.array<?xf32>>, %arg2: !fir.ref<!fir.array<?xf32>>) {
|
||||
%c1 = constant 1 : index
|
||||
%c100 = constant 100 : index
|
||||
%c1 = arith.constant 1 : index
|
||||
%c100 = arith.constant 100 : index
|
||||
%0 = fir.shape %c100 : (index) -> !fir.shape<1>
|
||||
%1 = affine.apply #map0()[%c1, %c100]
|
||||
%2 = fir.alloca !fir.array<?xf32>, %1
|
||||
|
|
@ -19,7 +19,7 @@ module {
|
|||
%7 = affine.apply #map2(%arg3)[%c1, %c100, %c1]
|
||||
%8 = affine.load %3[%7] : memref<?xf32>
|
||||
%9 = affine.load %4[%7] : memref<?xf32>
|
||||
%10 = addf %8, %9 : f32
|
||||
%10 = arith.addf %8, %9 : f32
|
||||
affine.store %10, %5[%7] : memref<?xf32>
|
||||
}
|
||||
%6 = fir.convert %arg2 : (!fir.ref<!fir.array<?xf32>>) -> memref<?xf32>
|
||||
|
|
@ -27,7 +27,7 @@ module {
|
|||
%7 = affine.apply #map2(%arg3)[%c1, %c100, %c1]
|
||||
%8 = affine.load %5[%7] : memref<?xf32>
|
||||
%9 = affine.load %4[%7] : memref<?xf32>
|
||||
%10 = mulf %8, %9 : f32
|
||||
%10 = arith.mulf %8, %9 : f32
|
||||
affine.store %10, %6[%7] : memref<?xf32>
|
||||
}
|
||||
return
|
||||
|
|
@ -35,10 +35,10 @@ module {
|
|||
}
|
||||
|
||||
// CHECK: func @calc(%[[VAL_0:.*]]: !fir.ref<!fir.array<?xf32>>, %[[VAL_1:.*]]: !fir.ref<!fir.array<?xf32>>, %[[VAL_2:.*]]: !fir.ref<!fir.array<?xf32>>) {
|
||||
// CHECK: %[[VAL_3:.*]] = constant 1 : index
|
||||
// CHECK: %[[VAL_4:.*]] = constant 100 : index
|
||||
// CHECK: %[[VAL_3:.*]] = arith.constant 1 : index
|
||||
// CHECK: %[[VAL_4:.*]] = arith.constant 100 : index
|
||||
// CHECK: %[[VAL_5:.*]] = fir.shape %[[VAL_4]] : (index) -> !fir.shape<1>
|
||||
// CHECK: %[[VAL_6:.*]] = constant 100 : index
|
||||
// CHECK: %[[VAL_6:.*]] = arith.constant 100 : index
|
||||
// CHECK: %[[VAL_7:.*]] = fir.alloca !fir.array<?xf32>, %[[VAL_6]]
|
||||
// CHECK: %[[VAL_8:.*]] = fir.convert %[[VAL_0]] : (!fir.ref<!fir.array<?xf32>>) -> !fir.ref<!fir.array<?xf32>>
|
||||
// CHECK: %[[VAL_9:.*]] = fir.convert %[[VAL_1]] : (!fir.ref<!fir.array<?xf32>>) -> !fir.ref<!fir.array<?xf32>>
|
||||
|
|
@ -49,7 +49,7 @@ module {
|
|||
// CHECK: %[[VAL_14:.*]] = fir.load %[[VAL_13]] : !fir.ref<f32>
|
||||
// CHECK: %[[VAL_15:.*]] = fir.coordinate_of %[[VAL_9]], %[[VAL_12]] : (!fir.ref<!fir.array<?xf32>>, index) -> !fir.ref<f32>
|
||||
// CHECK: %[[VAL_16:.*]] = fir.load %[[VAL_15]] : !fir.ref<f32>
|
||||
// CHECK: %[[VAL_17:.*]] = addf %[[VAL_14]], %[[VAL_16]] : f32
|
||||
// CHECK: %[[VAL_17:.*]] = arith.addf %[[VAL_14]], %[[VAL_16]] : f32
|
||||
// CHECK: %[[VAL_18:.*]] = fir.coordinate_of %[[VAL_10]], %[[VAL_12]] : (!fir.ref<!fir.array<?xf32>>, index) -> !fir.ref<f32>
|
||||
// CHECK: fir.store %[[VAL_17]] to %[[VAL_18]] : !fir.ref<f32>
|
||||
// CHECK: }
|
||||
|
|
@ -60,7 +60,7 @@ module {
|
|||
// CHECK: %[[VAL_23:.*]] = fir.load %[[VAL_22]] : !fir.ref<f32>
|
||||
// CHECK: %[[VAL_24:.*]] = fir.coordinate_of %[[VAL_9]], %[[VAL_21]] : (!fir.ref<!fir.array<?xf32>>, index) -> !fir.ref<f32>
|
||||
// CHECK: %[[VAL_25:.*]] = fir.load %[[VAL_24]] : !fir.ref<f32>
|
||||
// CHECK: %[[VAL_26:.*]] = mulf %[[VAL_23]], %[[VAL_25]] : f32
|
||||
// CHECK: %[[VAL_26:.*]] = arith.mulf %[[VAL_23]], %[[VAL_25]] : f32
|
||||
// CHECK: %[[VAL_27:.*]] = fir.coordinate_of %[[VAL_19]], %[[VAL_21]] : (!fir.ref<!fir.array<?xf32>>, index) -> !fir.ref<f32>
|
||||
// CHECK: fir.store %[[VAL_26]] to %[[VAL_27]] : !fir.ref<f32>
|
||||
// CHECK: }
|
||||
|
|
|
|||
|
|
@ -6,9 +6,9 @@
|
|||
#arr_len = affine_map<()[j1,k1] -> (k1 - j1 + 1)>
|
||||
|
||||
func @loop_with_load_and_store(%a1: !arr_d1, %a2: !arr_d1, %a3: !arr_d1) {
|
||||
%c1 = constant 1 : index
|
||||
%c0 = constant 0 : index
|
||||
%len = constant 100 : index
|
||||
%c1 = arith.constant 1 : index
|
||||
%c0 = arith.constant 0 : index
|
||||
%len = arith.constant 100 : index
|
||||
%dims = fir.shape %len : (index) -> !fir.shape<1>
|
||||
%siz = affine.apply #arr_len()[%c1,%len]
|
||||
%t1 = fir.alloca !fir.array<?xf32>, %siz
|
||||
|
|
@ -22,7 +22,7 @@ func @loop_with_load_and_store(%a1: !arr_d1, %a2: !arr_d1, %a3: !arr_d1) {
|
|||
: (!arr_d1, !fir.shape<1>, index) -> !fir.ref<f32>
|
||||
%a2_v = fir.load %a2_idx : !fir.ref<f32>
|
||||
|
||||
%v = addf %a1_v, %a2_v : f32
|
||||
%v = arith.addf %a1_v, %a2_v : f32
|
||||
%t1_idx = fir.array_coor %t1(%dims) %i
|
||||
: (!arr_d1, !fir.shape<1>, index) -> !fir.ref<f32>
|
||||
|
||||
|
|
@ -37,7 +37,7 @@ func @loop_with_load_and_store(%a1: !arr_d1, %a2: !arr_d1, %a3: !arr_d1) {
|
|||
: (!arr_d1, !fir.shape<1>, index) -> !fir.ref<f32>
|
||||
%a2_v = fir.load %a2_idx : !fir.ref<f32>
|
||||
|
||||
%v = mulf %t1_v, %a2_v : f32
|
||||
%v = arith.mulf %t1_v, %a2_v : f32
|
||||
%a3_idx = fir.array_coor %a3(%dims) %i
|
||||
: (!arr_d1, !fir.shape<1>, index) -> !fir.ref<f32>
|
||||
|
||||
|
|
@ -47,8 +47,8 @@ func @loop_with_load_and_store(%a1: !arr_d1, %a2: !arr_d1, %a3: !arr_d1) {
|
|||
}
|
||||
|
||||
// CHECK: func @loop_with_load_and_store(%[[VAL_0:.*]]: !fir.ref<!fir.array<?xf32>>, %[[VAL_1:.*]]: !fir.ref<!fir.array<?xf32>>, %[[VAL_2:.*]]: !fir.ref<!fir.array<?xf32>>) {
|
||||
// CHECK: %[[VAL_3:.*]] = constant 1 : index
|
||||
// CHECK: %[[VAL_4:.*]] = constant 100 : index
|
||||
// CHECK: %[[VAL_3:.*]] = arith.constant 1 : index
|
||||
// CHECK: %[[VAL_4:.*]] = arith.constant 100 : index
|
||||
// CHECK: %[[VAL_5:.*]] = fir.shape %[[VAL_4]] : (index) -> !fir.shape<1>
|
||||
// CHECK: %[[VAL_6:.*]] = affine.apply #map0(){{\[}}%[[VAL_3]], %[[VAL_4]]]
|
||||
// CHECK: %[[VAL_7:.*]] = fir.alloca !fir.array<?xf32>, %[[VAL_6]]
|
||||
|
|
@ -59,7 +59,7 @@ func @loop_with_load_and_store(%a1: !arr_d1, %a2: !arr_d1, %a3: !arr_d1) {
|
|||
// CHECK: %[[VAL_12:.*]] = affine.apply #map2(%[[VAL_11]]){{\[}}%[[VAL_3]], %[[VAL_4]], %[[VAL_3]]]
|
||||
// CHECK: %[[VAL_13:.*]] = affine.load %[[VAL_8]]{{\[}}%[[VAL_12]]] : memref<?xf32>
|
||||
// CHECK: %[[VAL_14:.*]] = affine.load %[[VAL_9]]{{\[}}%[[VAL_12]]] : memref<?xf32>
|
||||
// CHECK: %[[VAL_15:.*]] = addf %[[VAL_13]], %[[VAL_14]] : f32
|
||||
// CHECK: %[[VAL_15:.*]] = arith.addf %[[VAL_13]], %[[VAL_14]] : f32
|
||||
// CHECK: affine.store %[[VAL_15]], %[[VAL_10]]{{\[}}%[[VAL_12]]] : memref<?xf32>
|
||||
// CHECK: }
|
||||
// CHECK: %[[VAL_16:.*]] = fir.convert %[[VAL_2]] : (!fir.ref<!fir.array<?xf32>>) -> memref<?xf32>
|
||||
|
|
@ -67,7 +67,7 @@ func @loop_with_load_and_store(%a1: !arr_d1, %a2: !arr_d1, %a3: !arr_d1) {
|
|||
// CHECK: %[[VAL_18:.*]] = affine.apply #map2(%[[VAL_17]]){{\[}}%[[VAL_3]], %[[VAL_4]], %[[VAL_3]]]
|
||||
// CHECK: %[[VAL_19:.*]] = affine.load %[[VAL_10]]{{\[}}%[[VAL_18]]] : memref<?xf32>
|
||||
// CHECK: %[[VAL_20:.*]] = affine.load %[[VAL_9]]{{\[}}%[[VAL_18]]] : memref<?xf32>
|
||||
// CHECK: %[[VAL_21:.*]] = mulf %[[VAL_19]], %[[VAL_20]] : f32
|
||||
// CHECK: %[[VAL_21:.*]] = arith.mulf %[[VAL_19]], %[[VAL_20]] : f32
|
||||
// CHECK: affine.store %[[VAL_21]], %[[VAL_16]]{{\[}}%[[VAL_18]]] : memref<?xf32>
|
||||
// CHECK: }
|
||||
// CHECK: return
|
||||
|
|
@ -79,17 +79,17 @@ func @loop_with_load_and_store(%a1: !arr_d1, %a2: !arr_d1, %a3: !arr_d1) {
|
|||
#arr_len = affine_map<()[j1,k1] -> (k1 - j1 + 1)>
|
||||
|
||||
func @loop_with_if(%a: !arr_d1, %v: f32) {
|
||||
%c0 = constant 0 : index
|
||||
%c1 = constant 1 : index
|
||||
%c2 = constant 2 : index
|
||||
%len = constant 100 : index
|
||||
%c0 = arith.constant 0 : index
|
||||
%c1 = arith.constant 1 : index
|
||||
%c2 = arith.constant 2 : index
|
||||
%len = arith.constant 100 : index
|
||||
%dims = fir.shape %len : (index) -> !fir.shape<1>
|
||||
|
||||
fir.do_loop %i = %c1 to %len step %c1 {
|
||||
fir.do_loop %j = %c1 to %len step %c1 {
|
||||
fir.do_loop %k = %c1 to %len step %c1 {
|
||||
%im2 = subi %i, %c2 : index
|
||||
%cond = cmpi "sgt", %im2, %c0 : index
|
||||
%im2 = arith.subi %i, %c2 : index
|
||||
%cond = arith.cmpi "sgt", %im2, %c0 : index
|
||||
fir.if %cond {
|
||||
%a_idx = fir.array_coor %a(%dims) %i
|
||||
: (!arr_d1, !fir.shape<1>, index) -> !fir.ref<f32>
|
||||
|
|
@ -108,10 +108,10 @@ func @loop_with_if(%a: !arr_d1, %v: f32) {
|
|||
}
|
||||
|
||||
// CHECK: func @loop_with_if(%[[VAL_0:.*]]: !fir.ref<!fir.array<?xf32>>, %[[VAL_1:.*]]: f32) {
|
||||
// CHECK: %[[VAL_2:.*]] = constant 0 : index
|
||||
// CHECK: %[[VAL_3:.*]] = constant 1 : index
|
||||
// CHECK: %[[VAL_4:.*]] = constant 2 : index
|
||||
// CHECK: %[[VAL_5:.*]] = constant 100 : index
|
||||
// CHECK: %[[VAL_2:.*]] = arith.constant 0 : index
|
||||
// CHECK: %[[VAL_3:.*]] = arith.constant 1 : index
|
||||
// CHECK: %[[VAL_4:.*]] = arith.constant 2 : index
|
||||
// CHECK: %[[VAL_5:.*]] = arith.constant 100 : index
|
||||
// CHECK: %[[VAL_6:.*]] = fir.shape %[[VAL_5]] : (index) -> !fir.shape<1>
|
||||
// CHECK: %[[VAL_7:.*]] = fir.convert %[[VAL_0]] : (!fir.ref<!fir.array<?xf32>>) -> memref<?xf32>
|
||||
// CHECK: affine.for %[[VAL_8:.*]] = %[[VAL_3]] to #map0(){{\[}}%[[VAL_5]]] {
|
||||
|
|
@ -123,7 +123,7 @@ func @loop_with_if(%a: !arr_d1, %v: f32) {
|
|||
// CHECK: affine.store %[[VAL_1]], %[[VAL_7]]{{\[}}%[[VAL_11]]] : memref<?xf32>
|
||||
// CHECK: }
|
||||
// CHECK: affine.for %[[VAL_12:.*]] = %[[VAL_3]] to #map0(){{\[}}%[[VAL_5]]] {
|
||||
// CHECK: %[[VAL_13:.*]] = subi %[[VAL_12]], %[[VAL_4]] : index
|
||||
// CHECK: %[[VAL_13:.*]] = arith.subi %[[VAL_12]], %[[VAL_4]] : index
|
||||
// CHECK: affine.if #set(%[[VAL_12]]) {
|
||||
// CHECK: %[[VAL_14:.*]] = affine.apply #map1(%[[VAL_12]]){{\[}}%[[VAL_3]], %[[VAL_5]], %[[VAL_3]]]
|
||||
// CHECK: affine.store %[[VAL_1]], %[[VAL_7]]{{\[}}%[[VAL_14]]] : memref<?xf32>
|
||||
|
|
|
|||
|
|
@ -3,8 +3,8 @@
|
|||
// CHECK-LABEL: func @codegen(
|
||||
// CHECK-SAME: %[[arg:.*]]: !fir
|
||||
func @codegen(%addr : !fir.ref<!fir.array<?xi32>>) {
|
||||
// CHECK: %[[zero:.*]] = constant 0 : index
|
||||
%0 = constant 0 : index
|
||||
// CHECK: %[[zero:.*]] = arith.constant 0 : index
|
||||
%0 = arith.constant 0 : index
|
||||
%1 = fir.shape_shift %0, %0 : (index, index) -> !fir.shapeshift<1>
|
||||
%2 = fir.slice %0, %0, %0 : (index, index, index) -> !fir.slice<1>
|
||||
// CHECK: %[[box:.*]] = fircg.ext_embox %[[arg]](%[[zero]]) origin %[[zero]][%[[zero]], %[[zero]], %[[zero]]] : (!fir.ref<!fir.array<?xi32>>, index, index, index, index, index) -> !fir.box<!fir.array<?xi32>>
|
||||
|
|
@ -20,8 +20,8 @@ func @codegen(%addr : !fir.ref<!fir.array<?xi32>>) {
|
|||
fir.global @box_global : !fir.box<!fir.array<?xi32>> {
|
||||
// CHECK: %[[arr:.*]] = fir.zero_bits !fir.ref
|
||||
%arr = fir.zero_bits !fir.ref<!fir.array<?xi32>>
|
||||
// CHECK: %[[zero:.*]] = constant 0 : index
|
||||
%0 = constant 0 : index
|
||||
// CHECK: %[[zero:.*]] = arith.constant 0 : index
|
||||
%0 = arith.constant 0 : index
|
||||
%1 = fir.shape_shift %0, %0 : (index, index) -> !fir.shapeshift<1>
|
||||
%2 = fir.slice %0, %0, %0 : (index, index, index) -> !fir.slice<1>
|
||||
// CHECK: fircg.ext_embox %[[arr]](%[[zero]]) origin %[[zero]][%[[zero]], %[[zero]], %[[zero]]] : (!fir.ref<!fir.array<?xi32>>, index, index, index, index, index) -> !fir.box<!fir.array<?xi32>>
|
||||
|
|
|
|||
|
|
@ -12,17 +12,17 @@ func @char_convert() {
|
|||
// CHECK: %[[VAL_0:.*]] = fir.undefined i32
|
||||
// CHECK: %[[VAL_1:.*]] = fir.undefined !fir.ref<!fir.char<1>>
|
||||
// CHECK: %[[VAL_2:.*]] = fir.undefined !fir.ref<!fir.array<?x!fir.char<2,?>>>
|
||||
// CHECK: %[[VAL_3:.*]] = constant 0 : index
|
||||
// CHECK: %[[VAL_4:.*]] = constant 1 : index
|
||||
// CHECK: %[[VAL_3:.*]] = arith.constant 0 : index
|
||||
// CHECK: %[[VAL_4:.*]] = arith.constant 1 : index
|
||||
// CHECK: %[[VAL_5:.*]] = fir.convert %[[VAL_0]] : (i32) -> index
|
||||
// CHECK: %[[VAL_6:.*]] = subi %[[VAL_5]], %[[VAL_4]] : index
|
||||
// CHECK: %[[VAL_6:.*]] = arith.subi %[[VAL_5]], %[[VAL_4]] : index
|
||||
// CHECK: fir.do_loop %[[VAL_7:.*]] = %[[VAL_3]] to %[[VAL_6]] step %[[VAL_4]] {
|
||||
// CHECK: %[[VAL_8:.*]] = fir.convert %[[VAL_1]] : (!fir.ref<!fir.char<1>>) -> !fir.ref<!fir.array<?xi8>>
|
||||
// CHECK: %[[VAL_9:.*]] = fir.convert %[[VAL_2]] : (!fir.ref<!fir.array<?x!fir.char<2,?>>>) -> !fir.ref<!fir.array<?xi16>>
|
||||
// CHECK: %[[VAL_10:.*]] = fir.coordinate_of %[[VAL_8]], %[[VAL_7]] : (!fir.ref<!fir.array<?xi8>>, index) -> !fir.ref<i8>
|
||||
// CHECK: %[[VAL_11:.*]] = fir.coordinate_of %[[VAL_9]], %[[VAL_7]] : (!fir.ref<!fir.array<?xi16>>, index) -> !fir.ref<i16>
|
||||
// CHECK: %[[VAL_12:.*]] = fir.load %[[VAL_10]] : !fir.ref<i8>
|
||||
// CHECK: %[[VAL_13:.*]] = zexti %[[VAL_12]] : i8 to i16
|
||||
// CHECK: %[[VAL_13:.*]] = arith.extui %[[VAL_12]] : i8 to i16
|
||||
// CHECK: fir.store %[[VAL_13]] to %[[VAL_11]] : !fir.ref<i16>
|
||||
// CHECK: }
|
||||
// CHECK: return
|
||||
|
|
|
|||
|
|
@ -29,9 +29,9 @@ func @htest(%x : !fir.int<4>) -> !fir.int<4> {
|
|||
|
||||
// CHECK-LABEL: @ctest
|
||||
func @ctest() -> index {
|
||||
%1 = constant 10 : i32
|
||||
%1 = arith.constant 10 : i32
|
||||
%2 = fir.convert %1 : (i32) -> index
|
||||
// CHECK-NEXT: %{{.*}} = constant 10 : index
|
||||
// CHECK-NEXT: %{{.*}} = arith.constant 10 : index
|
||||
// CHECK-NEXT: return %{{.*}} : index
|
||||
return %2 : index
|
||||
}
|
||||
|
|
|
|||
|
|
@ -1,7 +1,7 @@
|
|||
// RUN: fir-opt --external-name-interop %s | FileCheck %s
|
||||
|
||||
func @_QPfoo() {
|
||||
%c0 = constant 0 : index
|
||||
%c0 = arith.constant 0 : index
|
||||
%0 = fir.address_of(@_QBa) : !fir.ref<!fir.array<4xi8>>
|
||||
%1 = fir.convert %0 : (!fir.ref<!fir.array<4xi8>>) -> !fir.ref<!fir.array<?xi8>>
|
||||
%2 = fir.coordinate_of %1, %c0 : (!fir.ref<!fir.array<?xi8>>, index) -> !fir.ref<i8>
|
||||
|
|
|
|||
|
|
@ -37,11 +37,11 @@ func @instructions() {
|
|||
// CHECK: [[VAL_0:%.*]] = fir.alloca !fir.array<10xi32>
|
||||
// CHECK: [[VAL_1:%.*]] = fir.load [[VAL_0]] : !fir.ref<!fir.array<10xi32>>
|
||||
// CHECK: [[VAL_2:%.*]] = fir.alloca i32
|
||||
// CHECK: [[VAL_3:%.*]] = constant 22 : i32
|
||||
// CHECK: [[VAL_3:%.*]] = arith.constant 22 : i32
|
||||
%0 = fir.alloca !fir.array<10xi32>
|
||||
%1 = fir.load %0 : !fir.ref<!fir.array<10xi32>>
|
||||
%2 = fir.alloca i32
|
||||
%3 = constant 22 : i32
|
||||
%3 = arith.constant 22 : i32
|
||||
|
||||
// CHECK: fir.store [[VAL_3]] to [[VAL_2]] : !fir.ref<i32>
|
||||
// CHECK: [[VAL_4:%.*]] = fir.undefined i32
|
||||
|
|
@ -53,12 +53,12 @@ func @instructions() {
|
|||
%6 = fir.embox %5 : (!fir.heap<!fir.array<100xf32>>) -> !fir.box<!fir.array<100xf32>>
|
||||
|
||||
// CHECK: [[VAL_7:%.*]] = fir.box_addr [[VAL_6]] : (!fir.box<!fir.array<100xf32>>) -> !fir.ref<!fir.array<100xf32>>
|
||||
// CHECK: [[VAL_8:%.*]] = constant 0 : index
|
||||
// CHECK: [[VAL_8:%.*]] = arith.constant 0 : index
|
||||
// CHECK: [[VAL_9:%.*]]:3 = fir.box_dims [[VAL_6]], [[VAL_8]] : (!fir.box<!fir.array<100xf32>>, index) -> (index, index, index)
|
||||
// CHECK: fir.call @print_index3([[VAL_9]]#0, [[VAL_9]]#1, [[VAL_9]]#2) : (index, index, index) -> ()
|
||||
// CHECK: [[VAL_10:%.*]] = fir.call @it1() : () -> !fir.int<4>
|
||||
%7 = fir.box_addr %6 : (!fir.box<!fir.array<100xf32>>) -> !fir.ref<!fir.array<100xf32>>
|
||||
%c0 = constant 0 : index
|
||||
%c0 = arith.constant 0 : index
|
||||
%d1:3 = fir.box_dims %6, %c0 : (!fir.box<!fir.array<100xf32>>, index) -> (index, index, index)
|
||||
fir.call @print_index3(%d1#0, %d1#1, %d1#2) : (index, index, index) -> ()
|
||||
%8 = fir.call @it1() : () -> !fir.int<4>
|
||||
|
|
@ -85,25 +85,25 @@ func @instructions() {
|
|||
%17 = fir.call @box2() : () -> !fir.boxproc<(i32, i32) -> i64>
|
||||
%18 = fir.boxproc_host %17 : (!fir.boxproc<(i32, i32) -> i64>) -> !fir.ref<i32>
|
||||
|
||||
// CHECK: [[VAL_21:%.*]] = constant 10 : i32
|
||||
// CHECK: [[VAL_21:%.*]] = arith.constant 10 : i32
|
||||
// CHECK: [[VAL_22:%.*]] = fir.coordinate_of [[VAL_5]], [[VAL_21]] : (!fir.heap<!fir.array<100xf32>>, i32) -> !fir.ref<f32>
|
||||
// CHECK: [[VAL_23:%.*]] = fir.field_index f, !fir.type<derived{f:f32}>
|
||||
// CHECK: [[VAL_24:%.*]] = fir.undefined !fir.type<derived{f:f32}>
|
||||
// CHECK: [[VAL_25:%.*]] = fir.extract_value [[VAL_24]], ["f", !fir.type<derived{f:f32}>] : (!fir.type<derived{f:f32}>) -> f32
|
||||
%19 = constant 10 : i32
|
||||
%19 = arith.constant 10 : i32
|
||||
%20 = fir.coordinate_of %5, %19 : (!fir.heap<!fir.array<100xf32>>, i32) -> !fir.ref<f32>
|
||||
%21 = fir.field_index f, !fir.type<derived{f:f32}>
|
||||
%22 = fir.undefined !fir.type<derived{f:f32}>
|
||||
%23 = fir.extract_value %22, ["f", !fir.type<derived{f:f32}>] : (!fir.type<derived{f:f32}>) -> f32
|
||||
|
||||
// CHECK: [[VAL_26:%.*]] = constant 1 : i32
|
||||
// CHECK: [[VAL_26:%.*]] = arith.constant 1 : i32
|
||||
// CHECK: [[VAL_27:%.*]] = fir.shape [[VAL_21]] : (i32) -> !fir.shape<1>
|
||||
// CHECK: [[VAL_28:%.*]] = constant 1.0
|
||||
// CHECK: [[VAL_28:%.*]] = arith.constant 1.0
|
||||
// CHECK: [[VAL_29:%.*]] = fir.insert_value [[VAL_24]], [[VAL_28]], ["f", !fir.type<derived{f:f32}>] : (!fir.type<derived{f:f32}>, f32) -> !fir.type<derived{f:f32}>
|
||||
// CHECK: [[VAL_30:%.*]] = fir.len_param_index f, !fir.type<derived3{f:f32}>
|
||||
%c1 = constant 1 : i32
|
||||
%c1 = arith.constant 1 : i32
|
||||
%24 = fir.shape %19 : (i32) -> !fir.shape<1>
|
||||
%cf1 = constant 1.0 : f32
|
||||
%cf1 = arith.constant 1.0 : f32
|
||||
%25 = fir.insert_value %22, %cf1, ["f", !fir.type<derived{f:f32}>] : (!fir.type<derived{f:f32}>, f32) -> !fir.type<derived{f:f32}>
|
||||
%26 = fir.len_param_index f, !fir.type<derived3{f:f32}>
|
||||
|
||||
|
|
@ -143,16 +143,16 @@ func @boxing_match() {
|
|||
// CHECK: [[VAL_41:%.*]] = fir.alloca tuple<i32, f64>
|
||||
// CHECK: [[VAL_42:%.*]] = fir.embox [[VAL_38]] : (!fir.ref<i32>) -> !fir.box<i32>
|
||||
// CHECK: [[VAL_43:%.*]]:6 = fir.unbox [[VAL_42]] : (!fir.box<i32>) -> (!fir.ref<i32>, i32, i32, !fir.tdesc<i32>, i32, !fir.array<3x?xindex>)
|
||||
// CHECK: [[VAL_44:%.*]] = constant 8 : i32
|
||||
// CHECK: [[VAL_44:%.*]] = arith.constant 8 : i32
|
||||
// CHECK: [[VAL_45:%.*]] = fir.undefined !fir.char<1>
|
||||
// CHECK: [[VAL_46:%.*]] = fir.emboxchar [[VAL_40]], [[VAL_44]] : (!fir.ref<!fir.char<1>>, i32) -> !fir.boxchar<1>
|
||||
// CHECK: [[VAL_47:%.*]]:2 = fir.unboxchar [[VAL_46]] : (!fir.boxchar<1>) -> (!fir.ref<!fir.char<1>>, i32)
|
||||
// CHECK: [[VAL_48:%.*]] = fir.undefined !fir.type<qq2{f1:i32,f2:f64}>
|
||||
// CHECK: [[VAL_49:%.*]] = constant 0 : i32
|
||||
// CHECK: [[VAL_50:%.*]] = constant 12 : i32
|
||||
// CHECK: [[VAL_49:%.*]] = arith.constant 0 : i32
|
||||
// CHECK: [[VAL_50:%.*]] = arith.constant 12 : i32
|
||||
// CHECK: [[VAL_51:%.*]] = fir.insert_value [[VAL_48]], [[VAL_50]], [0 : i32] : (!fir.type<qq2{f1:i32,f2:f64}>, i32) -> !fir.type<qq2{f1:i32,f2:f64}>
|
||||
// CHECK: [[VAL_52:%.*]] = constant 1 : i32
|
||||
// CHECK: [[VAL_53:%.*]] = constant 4.213000e+01 : f64
|
||||
// CHECK: [[VAL_52:%.*]] = arith.constant 1 : i32
|
||||
// CHECK: [[VAL_53:%.*]] = arith.constant 4.213000e+01 : f64
|
||||
// CHECK: [[VAL_54:%.*]] = fir.insert_value [[VAL_48]], [[VAL_53]], [1 : i32] : (!fir.type<qq2{f1:i32,f2:f64}>, f64) -> !fir.type<qq2{f1:i32,f2:f64}>
|
||||
// CHECK: fir.store [[VAL_54]] to [[VAL_39]] : !fir.ref<!fir.type<qq2{f1:i32,f2:f64}>>
|
||||
// CHECK: [[VAL_55:%.*]] = fir.emboxproc @method_impl, [[VAL_41]] : ((!fir.box<!fir.type<derived3{f:f32}>>) -> (), !fir.ref<tuple<i32, f64>>) -> !fir.boxproc<(!fir.box<!fir.type<derived3{f:f32}>>) -> ()>
|
||||
|
|
@ -169,16 +169,16 @@ func @boxing_match() {
|
|||
%e6 = fir.alloca tuple<i32,f64>
|
||||
%1 = fir.embox %0 : (!fir.ref<i32>) -> !fir.box<i32>
|
||||
%2:6 = fir.unbox %1 : (!fir.box<i32>) -> (!fir.ref<i32>,i32,i32,!fir.tdesc<i32>,i32,!fir.array<3x?xindex>)
|
||||
%c8 = constant 8 : i32
|
||||
%c8 = arith.constant 8 : i32
|
||||
%3 = fir.undefined !fir.char<1>
|
||||
%4 = fir.emboxchar %d3, %c8 : (!fir.ref<!fir.char<1>>, i32) -> !fir.boxchar<1>
|
||||
%5:2 = fir.unboxchar %4 : (!fir.boxchar<1>) -> (!fir.ref<!fir.char<1>>, i32)
|
||||
%6 = fir.undefined !fir.type<qq2{f1:i32,f2:f64}>
|
||||
%z = constant 0 : i32
|
||||
%c12 = constant 12 : i32
|
||||
%z = arith.constant 0 : i32
|
||||
%c12 = arith.constant 12 : i32
|
||||
%a2 = fir.insert_value %6, %c12, [0 : i32] : (!fir.type<qq2{f1:i32,f2:f64}>, i32) -> !fir.type<qq2{f1:i32,f2:f64}>
|
||||
%z1 = constant 1 : i32
|
||||
%c42 = constant 42.13 : f64
|
||||
%z1 = arith.constant 1 : i32
|
||||
%c42 = arith.constant 42.13 : f64
|
||||
%a3 = fir.insert_value %6, %c42, [1 : i32] : (!fir.type<qq2{f1:i32,f2:f64}>, f64) -> !fir.type<qq2{f1:i32,f2:f64}>
|
||||
fir.store %a3 to %d6 : !fir.ref<!fir.type<qq2{f1:i32,f2:f64}>>
|
||||
%7 = fir.emboxproc @method_impl, %e6 : ((!fir.box<!fir.type<derived3{f:f32}>>) -> (), !fir.ref<tuple<i32,f64>>) -> !fir.boxproc<(!fir.box<!fir.type<derived3{f:f32}>>) -> ()>
|
||||
|
|
@ -192,12 +192,12 @@ func @boxing_match() {
|
|||
|
||||
// CHECK-LABEL: func @loop() {
|
||||
func @loop() {
|
||||
// CHECK: [[VAL_62:%.*]] = constant 1 : index
|
||||
// CHECK: [[VAL_63:%.*]] = constant 10 : index
|
||||
// CHECK: [[VAL_64:%.*]] = constant true
|
||||
%c1 = constant 1 : index
|
||||
%c10 = constant 10 : index
|
||||
%ct = constant true
|
||||
// CHECK: [[VAL_62:%.*]] = arith.constant 1 : index
|
||||
// CHECK: [[VAL_63:%.*]] = arith.constant 10 : index
|
||||
// CHECK: [[VAL_64:%.*]] = arith.constant true
|
||||
%c1 = arith.constant 1 : index
|
||||
%c10 = arith.constant 10 : index
|
||||
%ct = arith.constant true
|
||||
|
||||
// CHECK: fir.do_loop [[VAL_65:%.*]] = [[VAL_62]] to [[VAL_63]] step [[VAL_62]] {
|
||||
// CHECK: fir.if [[VAL_64]] {
|
||||
|
|
@ -220,92 +220,92 @@ func @loop() {
|
|||
|
||||
// CHECK: func @bar_select([[VAL_66:%.*]]: i32, [[VAL_67:%.*]]: i32) -> i32 {
|
||||
func @bar_select(%arg : i32, %arg2 : i32) -> i32 {
|
||||
// CHECK: [[VAL_68:%.*]] = constant 1 : i32
|
||||
// CHECK: [[VAL_69:%.*]] = constant 2 : i32
|
||||
// CHECK: [[VAL_70:%.*]] = constant 3 : i32
|
||||
// CHECK: [[VAL_71:%.*]] = constant 4 : i32
|
||||
%0 = constant 1 : i32
|
||||
%1 = constant 2 : i32
|
||||
%2 = constant 3 : i32
|
||||
%3 = constant 4 : i32
|
||||
// CHECK: [[VAL_68:%.*]] = arith.constant 1 : i32
|
||||
// CHECK: [[VAL_69:%.*]] = arith.constant 2 : i32
|
||||
// CHECK: [[VAL_70:%.*]] = arith.constant 3 : i32
|
||||
// CHECK: [[VAL_71:%.*]] = arith.constant 4 : i32
|
||||
%0 = arith.constant 1 : i32
|
||||
%1 = arith.constant 2 : i32
|
||||
%2 = arith.constant 3 : i32
|
||||
%3 = arith.constant 4 : i32
|
||||
|
||||
// CHECK: fir.select [[VAL_66]] : i32 [1, ^bb1([[VAL_68]] : i32), 2, ^bb2([[VAL_70]], [[VAL_66]], [[VAL_67]] : i32, i32, i32), -3, ^bb3([[VAL_67]], [[VAL_70]] : i32, i32), 4, ^bb4([[VAL_69]] : i32), unit, ^bb5]
|
||||
// CHECK: ^bb1([[VAL_72:%.*]]: i32):
|
||||
// CHECK: return [[VAL_72]] : i32
|
||||
// CHECK: ^bb2([[VAL_73:%.*]]: i32, [[VAL_74:%.*]]: i32, [[VAL_75:%.*]]: i32):
|
||||
// CHECK: [[VAL_76:%.*]] = addi [[VAL_73]], [[VAL_74]] : i32
|
||||
// CHECK: [[VAL_77:%.*]] = addi [[VAL_76]], [[VAL_75]] : i32
|
||||
// CHECK: [[VAL_76:%.*]] = arith.addi [[VAL_73]], [[VAL_74]] : i32
|
||||
// CHECK: [[VAL_77:%.*]] = arith.addi [[VAL_76]], [[VAL_75]] : i32
|
||||
// CHECK: return [[VAL_77]] : i32
|
||||
// CHECK: ^bb3([[VAL_78:%.*]]: i32, [[VAL_79:%.*]]: i32):
|
||||
// CHECK: [[VAL_80:%.*]] = addi [[VAL_78]], [[VAL_79]] : i32
|
||||
// CHECK: [[VAL_80:%.*]] = arith.addi [[VAL_78]], [[VAL_79]] : i32
|
||||
// CHECK: return [[VAL_80]] : i32
|
||||
// CHECK: ^bb4([[VAL_81:%.*]]: i32):
|
||||
// CHECK: return [[VAL_81]] : i32
|
||||
// CHECK: ^bb5:
|
||||
// CHECK: [[VAL_82:%.*]] = constant 0 : i32
|
||||
// CHECK: [[VAL_82:%.*]] = arith.constant 0 : i32
|
||||
// CHECK: return [[VAL_82]] : i32
|
||||
// CHECK: }
|
||||
fir.select %arg:i32 [ 1,^bb1(%0:i32), 2,^bb2(%2,%arg,%arg2:i32,i32,i32), -3,^bb3(%arg2,%2:i32,i32), 4,^bb4(%1:i32), unit,^bb5 ]
|
||||
^bb1(%a : i32) :
|
||||
return %a : i32
|
||||
^bb2(%b : i32, %b2 : i32, %b3:i32) :
|
||||
%4 = addi %b, %b2 : i32
|
||||
%5 = addi %4, %b3 : i32
|
||||
%4 = arith.addi %b, %b2 : i32
|
||||
%5 = arith.addi %4, %b3 : i32
|
||||
return %5 : i32
|
||||
^bb3(%c:i32, %c2:i32) :
|
||||
%6 = addi %c, %c2 : i32
|
||||
%6 = arith.addi %c, %c2 : i32
|
||||
return %6 : i32
|
||||
^bb4(%d : i32) :
|
||||
return %d : i32
|
||||
^bb5 :
|
||||
%zero = constant 0 : i32
|
||||
%zero = arith.constant 0 : i32
|
||||
return %zero : i32
|
||||
}
|
||||
|
||||
// CHECK-LABEL: func @bar_select_rank(
|
||||
// CHECK-SAME: [[VAL_83:%.*]]: i32, [[VAL_84:%.*]]: i32) -> i32 {
|
||||
func @bar_select_rank(%arg : i32, %arg2 : i32) -> i32 {
|
||||
// CHECK: [[VAL_85:%.*]] = constant 1 : i32
|
||||
// CHECK: [[VAL_86:%.*]] = constant 2 : i32
|
||||
// CHECK: [[VAL_87:%.*]] = constant 3 : i32
|
||||
// CHECK: [[VAL_88:%.*]] = constant 4 : i32
|
||||
%0 = constant 1 : i32
|
||||
%1 = constant 2 : i32
|
||||
%2 = constant 3 : i32
|
||||
%3 = constant 4 : i32
|
||||
// CHECK: [[VAL_85:%.*]] = arith.constant 1 : i32
|
||||
// CHECK: [[VAL_86:%.*]] = arith.constant 2 : i32
|
||||
// CHECK: [[VAL_87:%.*]] = arith.constant 3 : i32
|
||||
// CHECK: [[VAL_88:%.*]] = arith.constant 4 : i32
|
||||
%0 = arith.constant 1 : i32
|
||||
%1 = arith.constant 2 : i32
|
||||
%2 = arith.constant 3 : i32
|
||||
%3 = arith.constant 4 : i32
|
||||
|
||||
// CHECK: fir.select_rank [[VAL_83]] : i32 [1, ^bb1([[VAL_85]] : i32), 2, ^bb2([[VAL_87]], [[VAL_83]], [[VAL_84]] : i32, i32, i32), 3, ^bb3([[VAL_84]], [[VAL_87]] : i32, i32), -1, ^bb4([[VAL_86]] : i32), unit, ^bb5]
|
||||
// CHECK: ^bb1([[VAL_89:%.*]]: i32):
|
||||
// CHECK: return [[VAL_89]] : i32
|
||||
// CHECK: ^bb2([[VAL_90:%.*]]: i32, [[VAL_91:%.*]]: i32, [[VAL_92:%.*]]: i32):
|
||||
// CHECK: [[VAL_93:%.*]] = addi [[VAL_90]], [[VAL_91]] : i32
|
||||
// CHECK: [[VAL_94:%.*]] = addi [[VAL_93]], [[VAL_92]] : i32
|
||||
// CHECK: [[VAL_93:%.*]] = arith.addi [[VAL_90]], [[VAL_91]] : i32
|
||||
// CHECK: [[VAL_94:%.*]] = arith.addi [[VAL_93]], [[VAL_92]] : i32
|
||||
// CHECK: return [[VAL_94]] : i32
|
||||
fir.select_rank %arg:i32 [ 1,^bb1(%0:i32), 2,^bb2(%2,%arg,%arg2:i32,i32,i32), 3,^bb3(%arg2,%2:i32,i32), -1,^bb4(%1:i32), unit,^bb5 ]
|
||||
^bb1(%a : i32) :
|
||||
return %a : i32
|
||||
^bb2(%b : i32, %b2 : i32, %b3:i32) :
|
||||
%4 = addi %b, %b2 : i32
|
||||
%5 = addi %4, %b3 : i32
|
||||
%4 = arith.addi %b, %b2 : i32
|
||||
%5 = arith.addi %4, %b3 : i32
|
||||
return %5 : i32
|
||||
|
||||
// CHECK: ^bb3([[VAL_95:%.*]]: i32, [[VAL_96:%.*]]: i32):
|
||||
// CHECK: [[VAL_97:%.*]] = addi [[VAL_95]], [[VAL_96]] : i32
|
||||
// CHECK: [[VAL_97:%.*]] = arith.addi [[VAL_95]], [[VAL_96]] : i32
|
||||
// CHECK: return [[VAL_97]] : i32
|
||||
// CHECK: ^bb4([[VAL_98:%.*]]: i32):
|
||||
// CHECK: return [[VAL_98]] : i32
|
||||
^bb3(%c:i32, %c2:i32) :
|
||||
%6 = addi %c, %c2 : i32
|
||||
%6 = arith.addi %c, %c2 : i32
|
||||
return %6 : i32
|
||||
^bb4(%d : i32) :
|
||||
return %d : i32
|
||||
|
||||
// CHECK: ^bb5:
|
||||
// CHECK: [[VAL_99:%.*]] = constant 0 : i32
|
||||
// CHECK: [[VAL_99:%.*]] = arith.constant 0 : i32
|
||||
// CHECK: [[VAL_100:%.*]] = fir.call @get_method_box() : () -> !fir.box<!fir.type<derived3{f:f32}>>
|
||||
// CHECK: fir.dispatch "method"([[VAL_100]]) : (!fir.box<!fir.type<derived3{f:f32}>>) -> ()
|
||||
^bb5 :
|
||||
%zero = constant 0 : i32
|
||||
%zero = arith.constant 0 : i32
|
||||
%7 = fir.call @get_method_box() : () -> !fir.box<!fir.type<derived3{f:f32}>>
|
||||
fir.dispatch method(%7) : (!fir.box<!fir.type<derived3{f:f32}>>) -> ()
|
||||
|
||||
|
|
@ -318,14 +318,14 @@ func @bar_select_rank(%arg : i32, %arg2 : i32) -> i32 {
|
|||
// CHECK-SAME: [[VAL_101:%.*]]: !fir.box<!fir.type<name(param1:i32){fld:!fir.char<1>}>>) -> i32 {
|
||||
func @bar_select_type(%arg : !fir.box<!fir.type<name(param1:i32){fld:!fir.char<1>}>>) -> i32 {
|
||||
|
||||
// CHECK: [[VAL_102:%.*]] = constant 1 : i32
|
||||
// CHECK: [[VAL_103:%.*]] = constant 2 : i32
|
||||
// CHECK: [[VAL_104:%.*]] = constant 3 : i32
|
||||
// CHECK: [[VAL_105:%.*]] = constant 4 : i32
|
||||
%0 = constant 1 : i32
|
||||
%1 = constant 2 : i32
|
||||
%2 = constant 3 : i32
|
||||
%3 = constant 4 : i32
|
||||
// CHECK: [[VAL_102:%.*]] = arith.constant 1 : i32
|
||||
// CHECK: [[VAL_103:%.*]] = arith.constant 2 : i32
|
||||
// CHECK: [[VAL_104:%.*]] = arith.constant 3 : i32
|
||||
// CHECK: [[VAL_105:%.*]] = arith.constant 4 : i32
|
||||
%0 = arith.constant 1 : i32
|
||||
%1 = arith.constant 2 : i32
|
||||
%2 = arith.constant 3 : i32
|
||||
%3 = arith.constant 4 : i32
|
||||
|
||||
// CHECK: fir.select_type [[VAL_101]] : !fir.box<!fir.type<name(param1:i32){fld:!fir.char<1>}>> [#fir.instance<!fir.int<4>>, ^bb1([[VAL_102]] : i32), #fir.instance<!fir.int<8>>, ^bb2([[VAL_104]] : i32), #fir.subsumed<!fir.int<2>>, ^bb3([[VAL_104]] : i32), #fir.instance<!fir.int<1>>, ^bb4([[VAL_103]] : i32), unit, ^bb5]
|
||||
fir.select_type %arg : !fir.box<!fir.type<name(param1:i32){fld:!fir.char<1>}>> [ #fir.instance<!fir.int<4>>,^bb1(%0:i32), #fir.instance<!fir.int<8>>,^bb2(%2:i32), #fir.subsumed<!fir.int<2>>,^bb3(%2:i32), #fir.instance<!fir.int<1>>,^bb4(%1:i32), unit,^bb5 ]
|
||||
|
|
@ -348,25 +348,25 @@ func @bar_select_type(%arg : !fir.box<!fir.type<name(param1:i32){fld:!fir.char<1
|
|||
return %d : i32
|
||||
|
||||
// CHECK: ^bb5:
|
||||
// CHECK: [[VAL_110:%.*]] = constant 0 : i32
|
||||
// CHECK: [[VAL_110:%.*]] = arith.constant 0 : i32
|
||||
// CHECK: return [[VAL_110]] : i32
|
||||
// CHECK: }
|
||||
^bb5 :
|
||||
%zero = constant 0 : i32
|
||||
%zero = arith.constant 0 : i32
|
||||
return %zero : i32
|
||||
}
|
||||
|
||||
// CHECK-LABEL: func @bar_select_case(
|
||||
// CHECK-SAME: [[VAL_111:%.*]]: i32, [[VAL_112:%.*]]: i32) -> i32 {
|
||||
// CHECK: [[VAL_113:%.*]] = constant 1 : i32
|
||||
// CHECK: [[VAL_114:%.*]] = constant 2 : i32
|
||||
// CHECK: [[VAL_115:%.*]] = constant 3 : i32
|
||||
// CHECK: [[VAL_116:%.*]] = constant 4 : i32
|
||||
// CHECK: [[VAL_113:%.*]] = arith.constant 1 : i32
|
||||
// CHECK: [[VAL_114:%.*]] = arith.constant 2 : i32
|
||||
// CHECK: [[VAL_115:%.*]] = arith.constant 3 : i32
|
||||
// CHECK: [[VAL_116:%.*]] = arith.constant 4 : i32
|
||||
func @bar_select_case(%arg : i32, %arg2 : i32) -> i32 {
|
||||
%0 = constant 1 : i32
|
||||
%1 = constant 2 : i32
|
||||
%2 = constant 3 : i32
|
||||
%3 = constant 4 : i32
|
||||
%0 = arith.constant 1 : i32
|
||||
%1 = arith.constant 2 : i32
|
||||
%2 = arith.constant 3 : i32
|
||||
%3 = arith.constant 4 : i32
|
||||
|
||||
// CHECK: fir.select_case [[VAL_111]] : i32 [#fir.point, [[VAL_113]], ^bb1([[VAL_113]] : i32), #fir.lower, [[VAL_114]], ^bb2([[VAL_115]], [[VAL_111]], [[VAL_112]], [[VAL_114]] : i32, i32, i32, i32), #fir.interval, [[VAL_115]], [[VAL_116]], ^bb3([[VAL_115]], [[VAL_112]] : i32, i32), #fir.upper, [[VAL_111]], ^bb4([[VAL_114]] : i32), unit, ^bb5]
|
||||
fir.select_case %arg : i32 [#fir.point, %0, ^bb1(%0:i32), #fir.lower, %1, ^bb2(%2,%arg,%arg2,%1:i32,i32,i32,i32), #fir.interval, %2, %3, ^bb3(%2,%arg2:i32,i32), #fir.upper, %arg, ^bb4(%1:i32), unit, ^bb5]
|
||||
|
|
@ -374,52 +374,52 @@ func @bar_select_case(%arg : i32, %arg2 : i32) -> i32 {
|
|||
// CHECK: ^bb1([[VAL_117:%.*]]: i32):
|
||||
// CHECK: return [[VAL_117]] : i32
|
||||
// CHECK: ^bb2([[VAL_118:%.*]]: i32, [[VAL_119:%.*]]: i32, [[VAL_120:%.*]]: i32, [[VAL_121:%.*]]: i32):
|
||||
// CHECK: [[VAL_122:%.*]] = addi [[VAL_118]], [[VAL_119]] : i32
|
||||
// CHECK: [[VAL_123:%.*]] = muli [[VAL_122]], [[VAL_120]] : i32
|
||||
// CHECK: [[VAL_124:%.*]] = addi [[VAL_123]], [[VAL_121]] : i32
|
||||
// CHECK: [[VAL_122:%.*]] = arith.addi [[VAL_118]], [[VAL_119]] : i32
|
||||
// CHECK: [[VAL_123:%.*]] = arith.muli [[VAL_122]], [[VAL_120]] : i32
|
||||
// CHECK: [[VAL_124:%.*]] = arith.addi [[VAL_123]], [[VAL_121]] : i32
|
||||
// CHECK: return [[VAL_124]] : i32
|
||||
// CHECK: ^bb3([[VAL_125:%.*]]: i32, [[VAL_126:%.*]]: i32):
|
||||
// CHECK: [[VAL_127:%.*]] = addi [[VAL_125]], [[VAL_126]] : i32
|
||||
// CHECK: [[VAL_127:%.*]] = arith.addi [[VAL_125]], [[VAL_126]] : i32
|
||||
// CHECK: return [[VAL_127]] : i32
|
||||
// CHECK: ^bb4([[VAL_128:%.*]]: i32):
|
||||
// CHECK: return [[VAL_128]] : i32
|
||||
^bb1(%a : i32) :
|
||||
return %a : i32
|
||||
^bb2(%b : i32, %b2:i32, %b3:i32, %b4:i32) :
|
||||
%4 = addi %b, %b2 : i32
|
||||
%5 = muli %4, %b3 : i32
|
||||
%6 = addi %5, %b4 : i32
|
||||
%4 = arith.addi %b, %b2 : i32
|
||||
%5 = arith.muli %4, %b3 : i32
|
||||
%6 = arith.addi %5, %b4 : i32
|
||||
return %6 : i32
|
||||
^bb3(%c : i32, %c2 : i32) :
|
||||
%7 = addi %c, %c2 : i32
|
||||
%7 = arith.addi %c, %c2 : i32
|
||||
return %7 : i32
|
||||
^bb4(%d : i32) :
|
||||
return %d : i32
|
||||
|
||||
// CHECK: ^bb5:
|
||||
// CHECK: [[VAL_129:%.*]] = constant 0 : i32
|
||||
// CHECK: [[VAL_129:%.*]] = arith.constant 0 : i32
|
||||
// CHECK: return [[VAL_129]] : i32
|
||||
// CHECK: }
|
||||
^bb5 :
|
||||
%zero = constant 0 : i32
|
||||
%zero = arith.constant 0 : i32
|
||||
return %zero : i32
|
||||
}
|
||||
|
||||
// CHECK-LABEL: fir.global @global_var : i32 {
|
||||
// CHECK: [[VAL_130:%.*]] = constant 1 : i32
|
||||
// CHECK: [[VAL_130:%.*]] = arith.constant 1 : i32
|
||||
// CHECK: fir.has_value [[VAL_130]] : i32
|
||||
// CHECK: }
|
||||
fir.global @global_var : i32 {
|
||||
%0 = constant 1 : i32
|
||||
%0 = arith.constant 1 : i32
|
||||
fir.has_value %0 : i32
|
||||
}
|
||||
|
||||
// CHECK-LABEL: fir.global @global_constant constant : i32 {
|
||||
// CHECK: [[VAL_131:%.*]] = constant 934 : i32
|
||||
// CHECK: [[VAL_131:%.*]] = arith.constant 934 : i32
|
||||
// CHECK: fir.has_value [[VAL_131]] : i32
|
||||
// CHECK: }
|
||||
fir.global @global_constant constant : i32 {
|
||||
%0 = constant 934 : i32
|
||||
%0 = arith.constant 934 : i32
|
||||
fir.has_value %0 : i32
|
||||
}
|
||||
|
||||
|
|
@ -489,20 +489,20 @@ func @compare_complex(%a : !fir.complex<16>, %b : !fir.complex<16>) {
|
|||
// CHECK-SAME: [[VAL_169:%.*]]: f128, [[VAL_170:%.*]]: f128) -> f128 {
|
||||
func @arith_real(%a : f128, %b : f128) -> f128 {
|
||||
|
||||
// CHECK: [[VAL_171:%.*]] = constant 1.0
|
||||
// CHECK: [[VAL_171:%.*]] = arith.constant 1.0
|
||||
// CHECK: [[VAL_172:%.*]] = fir.convert [[VAL_171]] : (f32) -> f128
|
||||
// CHECK: [[VAL_173:%.*]] = negf [[VAL_169]] : f128
|
||||
// CHECK: [[VAL_174:%.*]] = addf [[VAL_172]], [[VAL_173]] : f128
|
||||
// CHECK: [[VAL_175:%.*]] = subf [[VAL_174]], [[VAL_170]] : f128
|
||||
// CHECK: [[VAL_176:%.*]] = mulf [[VAL_173]], [[VAL_175]] : f128
|
||||
// CHECK: [[VAL_177:%.*]] = divf [[VAL_176]], [[VAL_169]] : f128
|
||||
%c1 = constant 1.0 : f32
|
||||
// CHECK: [[VAL_173:%.*]] = arith.negf [[VAL_169]] : f128
|
||||
// CHECK: [[VAL_174:%.*]] = arith.addf [[VAL_172]], [[VAL_173]] : f128
|
||||
// CHECK: [[VAL_175:%.*]] = arith.subf [[VAL_174]], [[VAL_170]] : f128
|
||||
// CHECK: [[VAL_176:%.*]] = arith.mulf [[VAL_173]], [[VAL_175]] : f128
|
||||
// CHECK: [[VAL_177:%.*]] = arith.divf [[VAL_176]], [[VAL_169]] : f128
|
||||
%c1 = arith.constant 1.0 : f32
|
||||
%0 = fir.convert %c1 : (f32) -> f128
|
||||
%1 = negf %a : f128
|
||||
%2 = addf %0, %1 : f128
|
||||
%3 = subf %2, %b : f128
|
||||
%4 = mulf %1, %3 : f128
|
||||
%5 = divf %4, %a : f128
|
||||
%1 = arith.negf %a : f128
|
||||
%2 = arith.addf %0, %1 : f128
|
||||
%3 = arith.subf %2, %b : f128
|
||||
%4 = arith.mulf %1, %3 : f128
|
||||
%5 = arith.divf %4, %a : f128
|
||||
// CHECK: return [[VAL_177]] : f128
|
||||
// CHECK: }
|
||||
return %5 : f128
|
||||
|
|
@ -541,10 +541,10 @@ func private @earlyexit2(%a : i32) -> i1
|
|||
// CHECK-LABEL: func @early_exit(
|
||||
// CHECK-SAME: [[VAL_187:%.*]]: i1, [[VAL_188:%.*]]: i32) -> i1 {
|
||||
func @early_exit(%ok : i1, %k : i32) -> i1 {
|
||||
// CHECK: [[VAL_189:%.*]] = constant 1 : index
|
||||
// CHECK: [[VAL_190:%.*]] = constant 100 : index
|
||||
%c1 = constant 1 : index
|
||||
%c100 = constant 100 : index
|
||||
// CHECK: [[VAL_189:%.*]] = arith.constant 1 : index
|
||||
// CHECK: [[VAL_190:%.*]] = arith.constant 100 : index
|
||||
%c1 = arith.constant 1 : index
|
||||
%c100 = arith.constant 100 : index
|
||||
|
||||
// CHECK: %[[VAL_191:.*]]:2 = fir.iterate_while ([[VAL_192:%.*]] = [[VAL_189]] to [[VAL_190]] step [[VAL_189]]) and ([[VAL_193:%.*]] = [[VAL_187]]) iter_args([[VAL_194:%.*]] = [[VAL_188]]) -> (i32) {
|
||||
// CHECK: [[VAL_195:%.*]] = call @earlyexit2([[VAL_194]]) : (i32) -> i1
|
||||
|
|
@ -561,29 +561,29 @@ func @early_exit(%ok : i1, %k : i32) -> i1 {
|
|||
|
||||
// CHECK-LABEL: @array_access
|
||||
func @array_access(%arr : !fir.ref<!fir.array<?x?xf32>>) {
|
||||
// CHECK-DAG: %[[c1:.*]] = constant 100
|
||||
// CHECK-DAG: %[[c2:.*]] = constant 50
|
||||
%c100 = constant 100 : index
|
||||
%c50 = constant 50 : index
|
||||
// CHECK-DAG: %[[c1:.*]] = arith.constant 100
|
||||
// CHECK-DAG: %[[c2:.*]] = arith.constant 50
|
||||
%c100 = arith.constant 100 : index
|
||||
%c50 = arith.constant 50 : index
|
||||
// CHECK: %[[sh:.*]] = fir.shape %[[c1]], %[[c2]] : {{.*}} -> !fir.shape<2>
|
||||
%shape = fir.shape %c100, %c50 : (index, index) -> !fir.shape<2>
|
||||
%c47 = constant 47 : index
|
||||
%c78 = constant 78 : index
|
||||
%c3 = constant 3 : index
|
||||
%c18 = constant 18 : index
|
||||
%c36 = constant 36 : index
|
||||
%c4 = constant 4 : index
|
||||
%c47 = arith.constant 47 : index
|
||||
%c78 = arith.constant 78 : index
|
||||
%c3 = arith.constant 3 : index
|
||||
%c18 = arith.constant 18 : index
|
||||
%c36 = arith.constant 36 : index
|
||||
%c4 = arith.constant 4 : index
|
||||
// CHECK: %[[sl:.*]] = fir.slice {{.*}} -> !fir.slice<2>
|
||||
%slice = fir.slice %c47, %c78, %c3, %c18, %c36, %c4 : (index,index,index,index,index,index) -> !fir.slice<2>
|
||||
%c0 = constant 0 : index
|
||||
%c99 = constant 99 : index
|
||||
%c1 = constant 1 : index
|
||||
%c0 = arith.constant 0 : index
|
||||
%c99 = arith.constant 99 : index
|
||||
%c1 = arith.constant 1 : index
|
||||
fir.do_loop %i = %c0 to %c99 step %c1 {
|
||||
%c49 = constant 49 : index
|
||||
%c49 = arith.constant 49 : index
|
||||
fir.do_loop %j = %c0 to %c49 step %c1 {
|
||||
// CHECK: fir.array_coor %{{.*}}(%[[sh]]) [%[[sl]]] %{{.*}}, %{{.*}} :
|
||||
%p = fir.array_coor %arr(%shape)[%slice] %i, %j : (!fir.ref<!fir.array<?x?xf32>>, !fir.shape<2>, !fir.slice<2>, index, index) -> !fir.ref<f32>
|
||||
%x = constant 42.0 : f32
|
||||
%x = arith.constant 42.0 : f32
|
||||
fir.store %x to %p : !fir.ref<f32>
|
||||
}
|
||||
}
|
||||
|
|
@ -607,16 +607,16 @@ func @test_absent() -> i1 {
|
|||
// CHECK-LABEL: @test_misc_ops(
|
||||
// CHECK-SAME: [[ARR1:%.*]]: !fir.ref<!fir.array<?x?xf32>>, [[INDXM:%.*]]: index, [[INDXN:%.*]]: index, [[INDXO:%.*]]: index, [[INDXP:%.*]]: index)
|
||||
func @test_misc_ops(%arr1 : !fir.ref<!fir.array<?x?xf32>>, %m : index, %n : index, %o : index, %p : index) {
|
||||
// CHECK: [[I10:%.*]] = constant 10 : index
|
||||
// CHECK: [[J20:%.*]] = constant 20 : index
|
||||
// CHECK: [[C2:%.*]] = constant 2 : index
|
||||
// CHECK: [[C9:%.*]] = constant 9 : index
|
||||
// CHECK: [[C1_I32:%.*]] = constant 9 : i32
|
||||
%i10 = constant 10 : index
|
||||
%j20 = constant 20 : index
|
||||
%c2 = constant 2 : index
|
||||
%c9 = constant 9 : index
|
||||
%c1_i32 = constant 9 : i32
|
||||
// CHECK: [[I10:%.*]] = arith.constant 10 : index
|
||||
// CHECK: [[J20:%.*]] = arith.constant 20 : index
|
||||
// CHECK: [[C2:%.*]] = arith.constant 2 : index
|
||||
// CHECK: [[C9:%.*]] = arith.constant 9 : index
|
||||
// CHECK: [[C1_I32:%.*]] = arith.constant 9 : i32
|
||||
%i10 = arith.constant 10 : index
|
||||
%j20 = arith.constant 20 : index
|
||||
%c2 = arith.constant 2 : index
|
||||
%c9 = arith.constant 9 : index
|
||||
%c1_i32 = arith.constant 9 : i32
|
||||
|
||||
// CHECK: [[ARR2:%.*]] = fir.zero_bits !fir.array<10xi32>
|
||||
// CHECK: [[ARR3:%.*]] = fir.insert_on_range [[ARR2]], [[C1_I32]], [2 : index, 9 : index] : (!fir.array<10xi32>, i32) -> !fir.array<10xi32>
|
||||
|
|
@ -651,8 +651,8 @@ func @test_misc_ops(%arr1 : !fir.ref<!fir.array<?x?xf32>>, %m : index, %n : inde
|
|||
|
||||
// CHECK-LABEL: @test_shift
|
||||
func @test_shift(%arg0: !fir.box<!fir.array<?xf32>>) -> !fir.ref<f32> {
|
||||
%c4 = constant 4 : index
|
||||
%c100 = constant 100 : index
|
||||
%c4 = arith.constant 4 : index
|
||||
%c100 = arith.constant 100 : index
|
||||
// CHECK: fir.shift %{{.*}} : (index) -> !fir.shift<1>
|
||||
%0 = fir.shift %c4 : (index) -> !fir.shift<1>
|
||||
%1 = fir.array_coor %arg0(%0) %c100 : (!fir.box<!fir.array<?xf32>>, !fir.shift<1>, index) -> !fir.ref<f32>
|
||||
|
|
@ -662,13 +662,13 @@ func @test_shift(%arg0: !fir.box<!fir.array<?xf32>>) -> !fir.ref<f32> {
|
|||
func private @bar_rebox_test(!fir.box<!fir.array<?x?xf32>>)
|
||||
// CHECK-LABEL: @test_rebox(
|
||||
func @test_rebox(%arg0: !fir.box<!fir.array<?xf32>>) {
|
||||
%c0 = constant 0 : index
|
||||
%c1 = constant 1 : index
|
||||
%c2 = constant 2 : index
|
||||
%c3 = constant 3 : index
|
||||
%c4 = constant 4 : index
|
||||
%c10 = constant 10 : index
|
||||
%c33 = constant 33 : index
|
||||
%c0 = arith.constant 0 : index
|
||||
%c1 = arith.constant 1 : index
|
||||
%c2 = arith.constant 2 : index
|
||||
%c3 = arith.constant 3 : index
|
||||
%c4 = arith.constant 4 : index
|
||||
%c10 = arith.constant 10 : index
|
||||
%c33 = arith.constant 33 : index
|
||||
%0 = fir.slice %c10, %c33, %c2 : (index, index, index) -> !fir.slice<1>
|
||||
%1 = fir.shift %c0 : (index) -> !fir.shift<1>
|
||||
// CHECK: fir.rebox %{{.*}}(%{{.*}}) [%{{.*}}] : (!fir.box<!fir.array<?xf32>>, !fir.shift<1>, !fir.slice<1>) -> !fir.box<!fir.array<?xf32>>
|
||||
|
|
@ -682,8 +682,8 @@ func @test_rebox(%arg0: !fir.box<!fir.array<?xf32>>) {
|
|||
|
||||
// CHECK-LABEL: @test_save_result(
|
||||
func @test_save_result(%buffer: !fir.ref<!fir.array<?x!fir.char<1,?>>>) {
|
||||
%c100 = constant 100 : index
|
||||
%c50 = constant 50 : index
|
||||
%c100 = arith.constant 100 : index
|
||||
%c50 = arith.constant 50 : index
|
||||
%shape = fir.shape %c100 : (index) -> !fir.shape<1>
|
||||
%res = fir.call @array_func() : () -> !fir.array<?x!fir.char<1,?>>
|
||||
// CHECK: fir.save_result %{{.*}} to %{{.*}}(%{{.*}}) typeparams %{{.*}} : !fir.array<?x!fir.char<1,?>>, !fir.ref<!fir.array<?x!fir.char<1,?>>>, !fir.shape<1>, index
|
||||
|
|
|
|||
|
|
@ -18,7 +18,7 @@
|
|||
// -----
|
||||
|
||||
func @bad_rebox_1(%arg0: !fir.ref<!fir.array<?x?xf32>>) {
|
||||
%c10 = constant 10 : index
|
||||
%c10 = arith.constant 10 : index
|
||||
%0 = fir.shape %c10 : (index) -> !fir.shape<1>
|
||||
// expected-error@+1{{op operand #0 must be The type of a Fortran descriptor, but got '!fir.ref<!fir.array<?x?xf32>>'}}
|
||||
%1 = fir.rebox %arg0(%0) : (!fir.ref<!fir.array<?x?xf32>>, !fir.shape<1>) -> !fir.box<!fir.array<?xf32>>
|
||||
|
|
@ -28,7 +28,7 @@ func @bad_rebox_1(%arg0: !fir.ref<!fir.array<?x?xf32>>) {
|
|||
// -----
|
||||
|
||||
func @bad_rebox_2(%arg0: !fir.box<!fir.array<?x?xf32>>) {
|
||||
%c10 = constant 10 : index
|
||||
%c10 = arith.constant 10 : index
|
||||
%0 = fir.shape %c10 : (index) -> !fir.shape<1>
|
||||
// expected-error@+1{{op result #0 must be The type of a Fortran descriptor, but got '!fir.ref<!fir.array<?xf32>>'}}
|
||||
%1 = fir.rebox %arg0(%0) : (!fir.box<!fir.array<?x?xf32>>, !fir.shape<1>) -> !fir.ref<!fir.array<?xf32>>
|
||||
|
|
@ -38,7 +38,7 @@ func @bad_rebox_2(%arg0: !fir.box<!fir.array<?x?xf32>>) {
|
|||
// -----
|
||||
|
||||
func @bad_rebox_3(%arg0: !fir.box<!fir.array<*:f32>>) {
|
||||
%c10 = constant 10 : index
|
||||
%c10 = arith.constant 10 : index
|
||||
%0 = fir.shape %c10 : (index) -> !fir.shape<1>
|
||||
// expected-error@+1{{op box operand must not have unknown rank or type}}
|
||||
%1 = fir.rebox %arg0(%0) : (!fir.box<!fir.array<*:f32>>, !fir.shape<1>) -> !fir.box<!fir.array<?xf32>>
|
||||
|
|
@ -56,8 +56,8 @@ func @bad_rebox_4(%arg0: !fir.box<!fir.array<?xf32>>) {
|
|||
// -----
|
||||
|
||||
func @bad_rebox_5(%arg0: !fir.box<!fir.array<?x?xf32>>) {
|
||||
%c1 = constant 1 : index
|
||||
%c10 = constant 10 : index
|
||||
%c1 = arith.constant 1 : index
|
||||
%c10 = arith.constant 10 : index
|
||||
%0 = fir.slice %c1, %c10, %c1 : (index, index, index) -> !fir.slice<1>
|
||||
// expected-error@+1{{op slice operand rank must match box operand rank}}
|
||||
%1 = fir.rebox %arg0 [%0] : (!fir.box<!fir.array<?x?xf32>>, !fir.slice<1>) -> !fir.box<!fir.array<?xf32>>
|
||||
|
|
@ -67,8 +67,8 @@ func @bad_rebox_5(%arg0: !fir.box<!fir.array<?x?xf32>>) {
|
|||
// -----
|
||||
|
||||
func @bad_rebox_6(%arg0: !fir.box<!fir.array<?xf32>>) {
|
||||
%c1 = constant 1 : index
|
||||
%c10 = constant 10 : index
|
||||
%c1 = arith.constant 1 : index
|
||||
%c10 = arith.constant 10 : index
|
||||
%0 = fir.slice %c1, %c10, %c1 : (index, index, index) -> !fir.slice<1>
|
||||
%1 = fir.shift %c1, %c1 : (index, index) -> !fir.shift<2>
|
||||
// expected-error@+1{{shape operand and input box ranks must match when there is a slice}}
|
||||
|
|
@ -79,8 +79,8 @@ func @bad_rebox_6(%arg0: !fir.box<!fir.array<?xf32>>) {
|
|||
// -----
|
||||
|
||||
func @bad_rebox_7(%arg0: !fir.box<!fir.array<?xf32>>) {
|
||||
%c1 = constant 1 : index
|
||||
%c10 = constant 10 : index
|
||||
%c1 = arith.constant 1 : index
|
||||
%c10 = arith.constant 10 : index
|
||||
%0 = fir.slice %c1, %c10, %c1 : (index, index, index) -> !fir.slice<1>
|
||||
%1 = fir.shape %c10 : (index) -> !fir.shape<1>
|
||||
// expected-error@+1{{shape operand must absent or be a fir.shift when there is a slice}}
|
||||
|
|
@ -91,8 +91,8 @@ func @bad_rebox_7(%arg0: !fir.box<!fir.array<?xf32>>) {
|
|||
// -----
|
||||
|
||||
func @bad_rebox_8(%arg0: !fir.box<!fir.array<?x?xf32>>) {
|
||||
%c1 = constant 1 : index
|
||||
%c10 = constant 10 : index
|
||||
%c1 = arith.constant 1 : index
|
||||
%c10 = arith.constant 10 : index
|
||||
%undef = fir.undefined index
|
||||
%0 = fir.slice %c1, %undef, %undef, %c1, %c10, %c1 : (index, index, index, index, index, index) -> !fir.slice<2>
|
||||
// expected-error@+1{{result type rank and rank after applying slice operand must match}}
|
||||
|
|
@ -103,7 +103,7 @@ func @bad_rebox_8(%arg0: !fir.box<!fir.array<?x?xf32>>) {
|
|||
// -----
|
||||
|
||||
func @bad_rebox_9(%arg0: !fir.box<!fir.array<?xf32>>) {
|
||||
%c10 = constant 10 : index
|
||||
%c10 = arith.constant 10 : index
|
||||
%0 = fir.shift %c10, %c10 : (index, index) -> !fir.shift<2>
|
||||
// expected-error@+1{{shape operand and input box ranks must match when the shape is a fir.shift}}
|
||||
%1 = fir.rebox %arg0(%0) : (!fir.box<!fir.array<?xf32>>, !fir.shift<2>) -> !fir.box<!fir.array<?x?xf32>>
|
||||
|
|
@ -113,7 +113,7 @@ func @bad_rebox_9(%arg0: !fir.box<!fir.array<?xf32>>) {
|
|||
// -----
|
||||
|
||||
func @bad_rebox_10(%arg0: !fir.box<!fir.array<?xf32>>) {
|
||||
%c10 = constant 10 : index
|
||||
%c10 = arith.constant 10 : index
|
||||
%0 = fir.shape %c10, %c10 : (index, index) -> !fir.shape<2>
|
||||
// expected-error@+1{{result type and shape operand ranks must match}}
|
||||
%1 = fir.rebox %arg0(%0) : (!fir.box<!fir.array<?xf32>>, !fir.shape<2>) -> !fir.box<!fir.array<?xf32>>
|
||||
|
|
@ -123,7 +123,7 @@ func @bad_rebox_10(%arg0: !fir.box<!fir.array<?xf32>>) {
|
|||
// -----
|
||||
|
||||
func @bad_rebox_11(%arg0: !fir.box<!fir.array<?x?xf32>>) {
|
||||
%c42 = constant 42 : index
|
||||
%c42 = arith.constant 42 : index
|
||||
%0 = fir.shape %c42 : (index) -> !fir.shape<1>
|
||||
// expected-error@+1{{op input and output element types must match for intrinsic types}}
|
||||
%1 = fir.rebox %arg0(%0) : (!fir.box<!fir.array<?x?xf32>>, !fir.shape<1>) -> !fir.box<!fir.array<?xf64>>
|
||||
|
|
@ -133,9 +133,9 @@ func @bad_rebox_11(%arg0: !fir.box<!fir.array<?x?xf32>>) {
|
|||
// -----
|
||||
|
||||
func @array_access(%arr : !fir.ref<!fir.array<?x?xf32>>) {
|
||||
%c1 = constant 1 : index
|
||||
%c100 = constant 100 : index
|
||||
%c50 = constant 50 : index
|
||||
%c1 = arith.constant 1 : index
|
||||
%c100 = arith.constant 100 : index
|
||||
%c50 = arith.constant 50 : index
|
||||
%shape = fir.shape %c100, %c50 : (index, index) -> !fir.shape<2>
|
||||
// expected-error@+1 {{'fir.array_coor' op operand #0 must be any reference or box, but got 'index'}}
|
||||
%p = fir.array_coor %c100(%shape) %c1, %c1 : (index, !fir.shape<2>, index, index) -> !fir.ref<f32>
|
||||
|
|
@ -145,9 +145,9 @@ func @array_access(%arr : !fir.ref<!fir.array<?x?xf32>>) {
|
|||
// -----
|
||||
|
||||
func @array_access(%arr : !fir.ref<f32>) {
|
||||
%c1 = constant 1 : index
|
||||
%c100 = constant 100 : index
|
||||
%c50 = constant 50 : index
|
||||
%c1 = arith.constant 1 : index
|
||||
%c100 = arith.constant 100 : index
|
||||
%c50 = arith.constant 50 : index
|
||||
%shape = fir.shape %c100, %c50 : (index, index) -> !fir.shape<2>
|
||||
// expected-error@+1 {{'fir.array_coor' op must be a reference to an array}}
|
||||
%p = fir.array_coor %arr(%shape) %c1, %c1 : (!fir.ref<f32>, !fir.shape<2>, index, index) -> !fir.ref<f32>
|
||||
|
|
@ -157,13 +157,13 @@ func @array_access(%arr : !fir.ref<f32>) {
|
|||
// -----
|
||||
|
||||
func @array_access(%arr : !fir.ref<!fir.array<?x?xf32>>) {
|
||||
%c1 = constant 1 : index
|
||||
%c100 = constant 100 : index
|
||||
%c50 = constant 50 : index
|
||||
%c1 = arith.constant 1 : index
|
||||
%c100 = arith.constant 100 : index
|
||||
%c50 = arith.constant 50 : index
|
||||
%shape = fir.shape %c100, %c50 : (index, index) -> !fir.shape<2>
|
||||
%c47 = constant 47 : index
|
||||
%c78 = constant 78 : index
|
||||
%c3 = constant 3 : index
|
||||
%c47 = arith.constant 47 : index
|
||||
%c78 = arith.constant 78 : index
|
||||
%c3 = arith.constant 3 : index
|
||||
%slice = fir.slice %c47, %c78, %c3 : (index,index,index) -> !fir.slice<1>
|
||||
// expected-error@+1 {{'fir.array_coor' op rank of dimension in slice mismatched}}
|
||||
%p = fir.array_coor %arr(%shape)[%slice] %c1, %c1 : (!fir.ref<!fir.array<?x?xf32>>, !fir.shape<2>, !fir.slice<1>, index, index) -> !fir.ref<f32>
|
||||
|
|
@ -173,8 +173,8 @@ func @array_access(%arr : !fir.ref<!fir.array<?x?xf32>>) {
|
|||
// -----
|
||||
|
||||
func @array_access(%arr : !fir.ref<!fir.array<?x?xf32>>) {
|
||||
%c1 = constant 1 : index
|
||||
%c100 = constant 100 : index
|
||||
%c1 = arith.constant 1 : index
|
||||
%c100 = arith.constant 100 : index
|
||||
%shape = fir.shape %c100 : (index) -> !fir.shape<1>
|
||||
// expected-error@+1 {{'fir.array_coor' op rank of dimension mismatched}}
|
||||
%p = fir.array_coor %arr(%shape) %c1, %c1 : (!fir.ref<!fir.array<?x?xf32>>, !fir.shape<1>, index, index) -> !fir.ref<f32>
|
||||
|
|
@ -184,8 +184,8 @@ func @array_access(%arr : !fir.ref<!fir.array<?x?xf32>>) {
|
|||
// -----
|
||||
|
||||
func @array_access(%arr : !fir.ref<!fir.array<?x?xf32>>) {
|
||||
%c1 = constant 1 : index
|
||||
%c100 = constant 100 : index
|
||||
%c1 = arith.constant 1 : index
|
||||
%c100 = arith.constant 100 : index
|
||||
%shift = fir.shift %c1 : (index) -> !fir.shift<1>
|
||||
// expected-error@+1 {{'fir.array_coor' op shift can only be provided with fir.box memref}}
|
||||
%p = fir.array_coor %arr(%shift) %c1, %c1 : (!fir.ref<!fir.array<?x?xf32>>, !fir.shift<1>, index, index) -> !fir.ref<f32>
|
||||
|
|
@ -195,9 +195,9 @@ func @array_access(%arr : !fir.ref<!fir.array<?x?xf32>>) {
|
|||
// -----
|
||||
|
||||
func @array_access(%arr : !fir.ref<!fir.array<?x?xf32>>) {
|
||||
%c1 = constant 1 : index
|
||||
%c100 = constant 100 : index
|
||||
%c50 = constant 50 : index
|
||||
%c1 = arith.constant 1 : index
|
||||
%c100 = arith.constant 100 : index
|
||||
%c50 = arith.constant 50 : index
|
||||
%shape = fir.shape %c100, %c50 : (index, index) -> !fir.shape<2>
|
||||
// expected-error@+1 {{'fir.array_coor' op number of indices do not match dim rank}}
|
||||
%p = fir.array_coor %arr(%shape) %c1 : (!fir.ref<!fir.array<?x?xf32>>, !fir.shape<2>, index) -> !fir.ref<f32>
|
||||
|
|
@ -207,7 +207,7 @@ func @array_access(%arr : !fir.ref<!fir.array<?x?xf32>>) {
|
|||
// -----
|
||||
|
||||
func @test_misc_ops(%arr1 : !fir.ref<!fir.array<?x?xf32>>, %m : index, %n : index, %o : index, %p : index) {
|
||||
%c2 = constant 2 : index
|
||||
%c2 = arith.constant 2 : index
|
||||
%s = fir.shape_shift %m, %n, %o, %p : (index, index, index, index) -> !fir.shapeshift<2>
|
||||
// expected-error@+1 {{'fir.array_load' op operand #0 must be any reference or box, but got 'index'}}
|
||||
%av1 = fir.array_load %c2(%s) : (index, !fir.shapeshift<2>) -> !fir.array<?x?xf32>
|
||||
|
|
@ -235,7 +235,7 @@ func @test_misc_ops(%arr1 : !fir.ref<!fir.array<?x?xf32>>, %m : index, %n : inde
|
|||
// -----
|
||||
|
||||
func @test_misc_ops(%arr1 : !fir.ref<!fir.array<?x?xf32>>, %m : index, %n : index, %o : index, %p : index) {
|
||||
%c2 = constant 2 : index
|
||||
%c2 = arith.constant 2 : index
|
||||
%shift = fir.shift %c2 : (index) -> !fir.shift<1>
|
||||
// expected-error@+1 {{'fir.array_load' op shift can only be provided with fir.box memref}}
|
||||
%av1 = fir.array_load %arr1(%shift) : (!fir.ref<!fir.array<?x?xf32>>, !fir.shift<1>) -> !fir.array<?x?xf32>
|
||||
|
|
@ -245,9 +245,9 @@ func @test_misc_ops(%arr1 : !fir.ref<!fir.array<?x?xf32>>, %m : index, %n : inde
|
|||
// -----
|
||||
|
||||
func @test_misc_ops(%arr1 : !fir.ref<!fir.array<?x?xf32>>, %m : index, %n : index, %o : index, %p : index) {
|
||||
%c47 = constant 47 : index
|
||||
%c78 = constant 78 : index
|
||||
%c3 = constant 3 : index
|
||||
%c47 = arith.constant 47 : index
|
||||
%c78 = arith.constant 78 : index
|
||||
%c3 = arith.constant 3 : index
|
||||
%slice = fir.slice %c47, %c78, %c3 : (index,index,index) -> !fir.slice<1>
|
||||
%s = fir.shape_shift %m, %n, %o, %p: (index, index, index, index) -> !fir.shapeshift<2>
|
||||
// expected-error@+1 {{'fir.array_load' op rank of dimension in slice mismatched}}
|
||||
|
|
@ -258,7 +258,7 @@ func @test_misc_ops(%arr1 : !fir.ref<!fir.array<?x?xf32>>, %m : index, %n : inde
|
|||
// -----
|
||||
|
||||
func @test_coordinate_of(%arr : !fir.ref<!fir.array<?x?xf32>>) {
|
||||
%1 = constant 10 : i32
|
||||
%1 = arith.constant 10 : i32
|
||||
// expected-error@+1 {{'fir.coordinate_of' op cannot find coordinate with unknown extents}}
|
||||
%2 = fir.coordinate_of %arr, %1 : (!fir.ref<!fir.array<?x?xf32>>, i32) -> !fir.ref<f32>
|
||||
return
|
||||
|
|
@ -267,7 +267,7 @@ func @test_coordinate_of(%arr : !fir.ref<!fir.array<?x?xf32>>) {
|
|||
// -----
|
||||
|
||||
func @test_coordinate_of(%arr : !fir.ref<!fir.array<*:f32>>) {
|
||||
%1 = constant 10 : i32
|
||||
%1 = arith.constant 10 : i32
|
||||
// expected-error@+1 {{'fir.coordinate_of' op cannot find coordinate in unknown shape}}
|
||||
%2 = fir.coordinate_of %arr, %1 : (!fir.ref<!fir.array<*:f32>>, i32) -> !fir.ref<f32>
|
||||
return
|
||||
|
|
@ -276,7 +276,7 @@ func @test_coordinate_of(%arr : !fir.ref<!fir.array<*:f32>>) {
|
|||
// -----
|
||||
|
||||
func @test_coordinate_of(%arr : !fir.ref<!fir.char<10>>) {
|
||||
%1 = constant 10 : i32
|
||||
%1 = arith.constant 10 : i32
|
||||
// expected-error@+1 {{'fir.coordinate_of' op cannot apply coordinate_of to this type}}
|
||||
%2 = fir.coordinate_of %arr, %1 : (!fir.ref<!fir.char<10>>, i32) -> !fir.ref<f32>
|
||||
return
|
||||
|
|
@ -284,14 +284,14 @@ func @test_coordinate_of(%arr : !fir.ref<!fir.char<10>>) {
|
|||
|
||||
// -----
|
||||
|
||||
%0 = constant 22 : i32
|
||||
%0 = arith.constant 22 : i32
|
||||
// expected-error@+1 {{'fir.embox' op operand #0 must be any reference, but got 'i32'}}
|
||||
%1 = fir.embox %0 : (i32) -> !fir.box<i32>
|
||||
|
||||
// -----
|
||||
|
||||
func @fun(%0 : !fir.ref<i32>) {
|
||||
%c_100 = constant 100 : index
|
||||
%c_100 = arith.constant 100 : index
|
||||
%1 = fir.shape %c_100 : (index) -> !fir.shape<1>
|
||||
// expected-error@+1 {{'fir.embox' op shape must not be provided for a scalar}}
|
||||
%2 = fir.embox %0(%1) : (!fir.ref<i32>, !fir.shape<1>) -> !fir.box<i32>
|
||||
|
|
@ -300,7 +300,7 @@ func @fun(%0 : !fir.ref<i32>) {
|
|||
// -----
|
||||
|
||||
func @fun(%0 : !fir.ref<i32>) {
|
||||
%c_100 = constant 100 : index
|
||||
%c_100 = arith.constant 100 : index
|
||||
%1 = fir.slice %c_100, %c_100, %c_100 : (index, index, index) -> !fir.slice<1>
|
||||
// expected-error@+1 {{'fir.embox' op operand #1 must be any legal shape type, but got '!fir.slice<1>'}}
|
||||
%2 = fir.embox %0(%1) : (!fir.ref<i32>, !fir.slice<1>) -> !fir.box<i32>
|
||||
|
|
@ -309,7 +309,7 @@ func @fun(%0 : !fir.ref<i32>) {
|
|||
// -----
|
||||
|
||||
func @fun(%0 : !fir.ref<i32>) {
|
||||
%c_100 = constant 100 : index
|
||||
%c_100 = arith.constant 100 : index
|
||||
%1 = fir.shape %c_100 : (index) -> !fir.shape<1>
|
||||
// expected-error@+1 {{'fir.embox' op operand #1 must be FIR slice, but got '!fir.shape<1>'}}
|
||||
%2 = fir.embox %0[%1] : (!fir.ref<i32>, !fir.shape<1>) -> !fir.box<i32>
|
||||
|
|
@ -318,7 +318,7 @@ func @fun(%0 : !fir.ref<i32>) {
|
|||
// -----
|
||||
|
||||
func @fun(%0 : !fir.ref<i32>) {
|
||||
%c_100 = constant 100 : index
|
||||
%c_100 = arith.constant 100 : index
|
||||
%1 = fir.slice %c_100, %c_100, %c_100 : (index, index, index) -> !fir.slice<1>
|
||||
// expected-error@+1 {{'fir.embox' op slice must not be provided for a scalar}}
|
||||
%2 = fir.embox %0[%1] : (!fir.ref<i32>, !fir.slice<1>) -> !fir.box<i32>
|
||||
|
|
@ -326,11 +326,11 @@ func @fun(%0 : !fir.ref<i32>) {
|
|||
|
||||
// -----
|
||||
|
||||
%lo = constant 1 : index
|
||||
%c1 = constant 1 : index
|
||||
%up = constant 10 : index
|
||||
%okIn = constant 1 : i1
|
||||
%shIn = constant 1 : i16
|
||||
%lo = arith.constant 1 : index
|
||||
%c1 = arith.constant 1 : index
|
||||
%up = arith.constant 10 : index
|
||||
%okIn = arith.constant 1 : i1
|
||||
%shIn = arith.constant 1 : i16
|
||||
// expected-error@+1 {{'fir.iterate_while' op expected body first argument to be an index argument for the induction variable}}
|
||||
%v:3 = fir.iterate_while (%i = %lo to %up step %c1) and (%ok = %okIn) iter_args(%sh = %shIn) -> (i16, i1, i16) {
|
||||
%shNew = fir.call @bar(%sh) : (i16) -> i16
|
||||
|
|
@ -340,11 +340,11 @@ func @fun(%0 : !fir.ref<i32>) {
|
|||
|
||||
// -----
|
||||
|
||||
%lo = constant 1 : index
|
||||
%c1 = constant 1 : index
|
||||
%up = constant 10 : index
|
||||
%okIn = constant 1 : i1
|
||||
%shIn = constant 1 : i16
|
||||
%lo = arith.constant 1 : index
|
||||
%c1 = arith.constant 1 : index
|
||||
%up = arith.constant 10 : index
|
||||
%okIn = arith.constant 1 : i1
|
||||
%shIn = arith.constant 1 : i16
|
||||
// expected-error@+1 {{'fir.iterate_while' op expected body second argument to be an index argument for the induction variable}}
|
||||
%v:3 = fir.iterate_while (%i = %lo to %up step %c1) and (%ok = %okIn) iter_args(%sh = %shIn) -> (index, f32, i16) {
|
||||
%shNew = fir.call @bar(%sh) : (i16) -> i16
|
||||
|
|
@ -354,26 +354,26 @@ func @fun(%0 : !fir.ref<i32>) {
|
|||
|
||||
// -----
|
||||
|
||||
%c1 = constant 1 : index
|
||||
%c10 = constant 10 : index
|
||||
%c1 = arith.constant 1 : index
|
||||
%c10 = arith.constant 10 : index
|
||||
// expected-error@+1 {{'fir.do_loop' op unordered loop has no final value}}
|
||||
fir.do_loop %i = %c1 to %c10 step %c1 unordered -> index {
|
||||
}
|
||||
|
||||
// -----
|
||||
|
||||
%c1 = constant 1 : index
|
||||
%c10 = constant 10 : index
|
||||
%c1 = arith.constant 1 : index
|
||||
%c10 = arith.constant 10 : index
|
||||
fir.do_loop %i = %c1 to %c10 step %c1 -> index {
|
||||
%f1 = constant 1.0 : f32
|
||||
%f1 = arith.constant 1.0 : f32
|
||||
// expected-error@+1 {{'fir.result' op types mismatch between result op and its parent}}
|
||||
fir.result %f1 : f32
|
||||
}
|
||||
|
||||
// -----
|
||||
|
||||
%c1 = constant 1 : index
|
||||
%c10 = constant 10 : index
|
||||
%c1 = arith.constant 1 : index
|
||||
%c10 = arith.constant 10 : index
|
||||
// expected-error@+1 {{'fir.result' op parent of result must have same arity}}
|
||||
fir.do_loop %i = %c1 to %c10 step %c1 -> index {
|
||||
}
|
||||
|
|
@ -425,7 +425,7 @@ func @ugly_char_convert() {
|
|||
// -----
|
||||
|
||||
fir.global internal @_QEmultiarray : !fir.array<32x32xi32> {
|
||||
%c0_i32 = constant 1 : i32
|
||||
%c0_i32 = arith.constant 1 : i32
|
||||
%0 = fir.undefined !fir.array<32x32xi32>
|
||||
// expected-error@+1 {{'fir.insert_on_range' op has uneven number of values in ranges}}
|
||||
%2 = fir.insert_on_range %0, %c0_i32, [0 : index, 31 : index, 0 : index] : (!fir.array<32x32xi32>, i32) -> !fir.array<32x32xi32>
|
||||
|
|
@ -435,7 +435,7 @@ fir.global internal @_QEmultiarray : !fir.array<32x32xi32> {
|
|||
// -----
|
||||
|
||||
fir.global internal @_QEmultiarray : !fir.array<32x32xi32> {
|
||||
%c0_i32 = constant 1 : i32
|
||||
%c0_i32 = arith.constant 1 : i32
|
||||
%0 = fir.undefined !fir.array<32x32xi32>
|
||||
// expected-error@+1 {{'fir.insert_on_range' op has uneven number of values in ranges}}
|
||||
%2 = fir.insert_on_range %0, %c0_i32, [0 : index] : (!fir.array<32x32xi32>, i32) -> !fir.array<32x32xi32>
|
||||
|
|
@ -445,7 +445,7 @@ fir.global internal @_QEmultiarray : !fir.array<32x32xi32> {
|
|||
// -----
|
||||
|
||||
fir.global internal @_QEmultiarray : !fir.array<32x32xi32> {
|
||||
%c0_i32 = constant 1 : i32
|
||||
%c0_i32 = arith.constant 1 : i32
|
||||
%0 = fir.undefined !fir.array<32x32xi32>
|
||||
// expected-error@+1 {{'fir.insert_on_range' op negative range bound}}
|
||||
%2 = fir.insert_on_range %0, %c0_i32, [-1 : index, 0 : index] : (!fir.array<32x32xi32>, i32) -> !fir.array<32x32xi32>
|
||||
|
|
@ -455,7 +455,7 @@ fir.global internal @_QEmultiarray : !fir.array<32x32xi32> {
|
|||
// -----
|
||||
|
||||
fir.global internal @_QEmultiarray : !fir.array<32x32xi32> {
|
||||
%c0_i32 = constant 1 : i32
|
||||
%c0_i32 = arith.constant 1 : i32
|
||||
%0 = fir.undefined !fir.array<32x32xi32>
|
||||
// expected-error@+1 {{'fir.insert_on_range' op empty range}}
|
||||
%2 = fir.insert_on_range %0, %c0_i32, [10 : index, 9 : index] : (!fir.array<32x32xi32>, i32) -> !fir.array<32x32xi32>
|
||||
|
|
@ -575,7 +575,7 @@ func @test_misc_ops(%arr1 : !fir.ref<!fir.array<?x?xf32>>, %m : index, %n : inde
|
|||
func @test_misc_ops(%arr1 : !fir.ref<!fir.array<?x?xf32>>, %m : index, %n : index, %o : index, %p : index) {
|
||||
%s = fir.shape_shift %m, %n, %o, %p : (index, index, index, index) -> !fir.shapeshift<2>
|
||||
%av1 = fir.array_load %arr1(%s) : (!fir.ref<!fir.array<?x?xf32>>, !fir.shapeshift<2>) -> !fir.array<?x?xf32>
|
||||
%c0 = constant 0 : i32
|
||||
%c0 = arith.constant 0 : i32
|
||||
// expected-error@+1 {{'fir.array_update' op merged value does not have element type}}
|
||||
%av2 = fir.array_update %av1, %c0, %m, %n : (!fir.array<?x?xf32>, i32, index, index) -> !fir.array<?x?xf32>
|
||||
return
|
||||
|
|
@ -596,8 +596,8 @@ func @test_misc_ops(%arr1 : !fir.ref<!fir.array<?x?xf32>>, %m : index, %n : inde
|
|||
// -----
|
||||
|
||||
func @bad_array_modify(%arr1 : !fir.ref<!fir.array<?x?xf32>>, %m : index, %n : index, %o : index, %p : index, %f : f32) {
|
||||
%i10 = constant 10 : index
|
||||
%j20 = constant 20 : index
|
||||
%i10 = arith.constant 10 : index
|
||||
%j20 = arith.constant 20 : index
|
||||
%s = fir.shape_shift %m, %n, %o, %p : (index, index, index, index) -> !fir.shapeshift<2>
|
||||
%av1 = fir.array_load %arr1(%s) : (!fir.ref<!fir.array<?x?xf32>>, !fir.shapeshift<2>) -> !fir.array<?x?xf32>
|
||||
// expected-error@+1 {{'fir.array_modify' op number of indices must match array dimension}}
|
||||
|
|
|
|||
|
|
@ -6,7 +6,7 @@ func @x(%lb : index, %ub : index, %step : index, %b : i1, %addr : !fir.ref<index
|
|||
fir.if %b {
|
||||
fir.store %iv to %addr : !fir.ref<index>
|
||||
} else {
|
||||
%zero = constant 0 : index
|
||||
%zero = arith.constant 0 : index
|
||||
fir.store %zero to %addr : !fir.ref<index>
|
||||
}
|
||||
}
|
||||
|
|
@ -16,13 +16,13 @@ func @x(%lb : index, %ub : index, %step : index, %b : i1, %addr : !fir.ref<index
|
|||
func private @f2() -> i1
|
||||
|
||||
// CHECK: func @x(%[[VAL_0:.*]]: index, %[[VAL_1:.*]]: index, %[[VAL_2:.*]]: index, %[[VAL_3:.*]]: i1, %[[VAL_4:.*]]: !fir.ref<index>) {
|
||||
// CHECK: %[[VAL_5:.*]] = subi %[[VAL_1]], %[[VAL_0]] : index
|
||||
// CHECK: %[[VAL_6:.*]] = addi %[[VAL_5]], %[[VAL_2]] : index
|
||||
// CHECK: %[[VAL_7:.*]] = divi_signed %[[VAL_6]], %[[VAL_2]] : index
|
||||
// CHECK: %[[VAL_5:.*]] = arith.subi %[[VAL_1]], %[[VAL_0]] : index
|
||||
// CHECK: %[[VAL_6:.*]] = arith.addi %[[VAL_5]], %[[VAL_2]] : index
|
||||
// CHECK: %[[VAL_7:.*]] = arith.divsi %[[VAL_6]], %[[VAL_2]] : index
|
||||
// CHECK: br ^bb1(%[[VAL_0]], %[[VAL_7]] : index, index)
|
||||
// CHECK: ^bb1(%[[VAL_8:.*]]: index, %[[VAL_9:.*]]: index):
|
||||
// CHECK: %[[VAL_10:.*]] = constant 0 : index
|
||||
// CHECK: %[[VAL_11:.*]] = cmpi sgt, %[[VAL_9]], %[[VAL_10]] : index
|
||||
// CHECK: %[[VAL_10:.*]] = arith.constant 0 : index
|
||||
// CHECK: %[[VAL_11:.*]] = arith.cmpi sgt, %[[VAL_9]], %[[VAL_10]] : index
|
||||
// CHECK: cond_br %[[VAL_11]], ^bb2, ^bb6
|
||||
// CHECK: ^bb2:
|
||||
// CHECK: cond_br %[[VAL_3]], ^bb3, ^bb4
|
||||
|
|
@ -30,13 +30,13 @@ func private @f2() -> i1
|
|||
// CHECK: fir.store %[[VAL_8]] to %[[VAL_4]] : !fir.ref<index>
|
||||
// CHECK: br ^bb5
|
||||
// CHECK: ^bb4:
|
||||
// CHECK: %[[VAL_12:.*]] = constant 0 : index
|
||||
// CHECK: %[[VAL_12:.*]] = arith.constant 0 : index
|
||||
// CHECK: fir.store %[[VAL_12]] to %[[VAL_4]] : !fir.ref<index>
|
||||
// CHECK: br ^bb5
|
||||
// CHECK: ^bb5:
|
||||
// CHECK: %[[VAL_13:.*]] = addi %[[VAL_8]], %[[VAL_2]] : index
|
||||
// CHECK: %[[VAL_14:.*]] = constant 1 : index
|
||||
// CHECK: %[[VAL_15:.*]] = subi %[[VAL_9]], %[[VAL_14]] : index
|
||||
// CHECK: %[[VAL_13:.*]] = arith.addi %[[VAL_8]], %[[VAL_2]] : index
|
||||
// CHECK: %[[VAL_14:.*]] = arith.constant 1 : index
|
||||
// CHECK: %[[VAL_15:.*]] = arith.subi %[[VAL_9]], %[[VAL_14]] : index
|
||||
// CHECK: br ^bb1(%[[VAL_13]], %[[VAL_15]] : index, index)
|
||||
// CHECK: ^bb6:
|
||||
// CHECK: return
|
||||
|
|
@ -46,7 +46,7 @@ func private @f2() -> i1
|
|||
// -----
|
||||
|
||||
func @x2(%lo : index, %up : index, %ok : i1) {
|
||||
%c1 = constant 1 : index
|
||||
%c1 = arith.constant 1 : index
|
||||
%unused = fir.iterate_while (%i = %lo to %up step %c1) and (%ok1 = %ok) {
|
||||
%ok2 = fir.call @f2() : () -> i1
|
||||
fir.result %ok2 : i1
|
||||
|
|
@ -57,22 +57,22 @@ func @x2(%lo : index, %up : index, %ok : i1) {
|
|||
func private @f3(i16)
|
||||
|
||||
// CHECK: func @x2(%[[VAL_0:.*]]: index, %[[VAL_1:.*]]: index, %[[VAL_2:.*]]: i1) {
|
||||
// CHECK: %[[VAL_3:.*]] = constant 1 : index
|
||||
// CHECK: %[[VAL_3:.*]] = arith.constant 1 : index
|
||||
// CHECK: br ^bb1(%[[VAL_0]], %[[VAL_2]] : index, i1)
|
||||
// CHECK: ^bb1(%[[VAL_4:.*]]: index, %[[VAL_5:.*]]: i1):
|
||||
// CHECK: %[[VAL_6:.*]] = constant 0 : index
|
||||
// CHECK: %[[VAL_7:.*]] = cmpi slt, %[[VAL_6]], %[[VAL_3]] : index
|
||||
// CHECK: %[[VAL_8:.*]] = cmpi sle, %[[VAL_4]], %[[VAL_1]] : index
|
||||
// CHECK: %[[VAL_9:.*]] = cmpi slt, %[[VAL_3]], %[[VAL_6]] : index
|
||||
// CHECK: %[[VAL_10:.*]] = cmpi sle, %[[VAL_1]], %[[VAL_4]] : index
|
||||
// CHECK: %[[VAL_11:.*]] = and %[[VAL_7]], %[[VAL_8]] : i1
|
||||
// CHECK: %[[VAL_12:.*]] = and %[[VAL_9]], %[[VAL_10]] : i1
|
||||
// CHECK: %[[VAL_13:.*]] = or %[[VAL_11]], %[[VAL_12]] : i1
|
||||
// CHECK: %[[VAL_14:.*]] = and %[[VAL_5]], %[[VAL_13]] : i1
|
||||
// CHECK: %[[VAL_6:.*]] = arith.constant 0 : index
|
||||
// CHECK: %[[VAL_7:.*]] = arith.cmpi slt, %[[VAL_6]], %[[VAL_3]] : index
|
||||
// CHECK: %[[VAL_8:.*]] = arith.cmpi sle, %[[VAL_4]], %[[VAL_1]] : index
|
||||
// CHECK: %[[VAL_9:.*]] = arith.cmpi slt, %[[VAL_3]], %[[VAL_6]] : index
|
||||
// CHECK: %[[VAL_10:.*]] = arith.cmpi sle, %[[VAL_1]], %[[VAL_4]] : index
|
||||
// CHECK: %[[VAL_11:.*]] = arith.andi %[[VAL_7]], %[[VAL_8]] : i1
|
||||
// CHECK: %[[VAL_12:.*]] = arith.andi %[[VAL_9]], %[[VAL_10]] : i1
|
||||
// CHECK: %[[VAL_13:.*]] = arith.ori %[[VAL_11]], %[[VAL_12]] : i1
|
||||
// CHECK: %[[VAL_14:.*]] = arith.andi %[[VAL_5]], %[[VAL_13]] : i1
|
||||
// CHECK: cond_br %[[VAL_14]], ^bb2, ^bb3
|
||||
// CHECK: ^bb2:
|
||||
// CHECK: %[[VAL_15:.*]] = fir.call @f2() : () -> i1
|
||||
// CHECK: %[[VAL_16:.*]] = addi %[[VAL_4]], %[[VAL_3]] : index
|
||||
// CHECK: %[[VAL_16:.*]] = arith.addi %[[VAL_4]], %[[VAL_3]] : index
|
||||
// CHECK: br ^bb1(%[[VAL_16]], %[[VAL_15]] : index, i1)
|
||||
// CHECK: ^bb3:
|
||||
// CHECK: return
|
||||
|
|
@ -83,8 +83,8 @@ func private @f3(i16)
|
|||
|
||||
// do_loop with an extra loop-carried value
|
||||
func @x3(%lo : index, %up : index) -> i1 {
|
||||
%c1 = constant 1 : index
|
||||
%ok1 = constant true
|
||||
%c1 = arith.constant 1 : index
|
||||
%ok1 = arith.constant true
|
||||
%ok2 = fir.do_loop %i = %lo to %up step %c1 iter_args(%j = %ok1) -> i1 {
|
||||
%ok = fir.call @f2() : () -> i1
|
||||
fir.result %ok : i1
|
||||
|
|
@ -95,21 +95,21 @@ func @x3(%lo : index, %up : index) -> i1 {
|
|||
// CHECK-LABEL: func @x3(
|
||||
// CHECK-SAME: %[[VAL_0:.*]]: index,
|
||||
// CHECK-SAME: %[[VAL_1:.*]]: index) -> i1 {
|
||||
// CHECK: %[[VAL_2:.*]] = constant 1 : index
|
||||
// CHECK: %[[VAL_3:.*]] = constant true
|
||||
// CHECK: %[[VAL_4:.*]] = subi %[[VAL_1]], %[[VAL_0]] : index
|
||||
// CHECK: %[[VAL_5:.*]] = addi %[[VAL_4]], %[[VAL_2]] : index
|
||||
// CHECK: %[[VAL_6:.*]] = divi_signed %[[VAL_5]], %[[VAL_2]] : index
|
||||
// CHECK: %[[VAL_2:.*]] = arith.constant 1 : index
|
||||
// CHECK: %[[VAL_3:.*]] = arith.constant true
|
||||
// CHECK: %[[VAL_4:.*]] = arith.subi %[[VAL_1]], %[[VAL_0]] : index
|
||||
// CHECK: %[[VAL_5:.*]] = arith.addi %[[VAL_4]], %[[VAL_2]] : index
|
||||
// CHECK: %[[VAL_6:.*]] = arith.divsi %[[VAL_5]], %[[VAL_2]] : index
|
||||
// CHECK: br ^bb1(%[[VAL_0]], %[[VAL_3]], %[[VAL_6]] : index, i1, index)
|
||||
// CHECK: ^bb1(%[[VAL_7:.*]]: index, %[[VAL_8:.*]]: i1, %[[VAL_9:.*]]: index):
|
||||
// CHECK: %[[VAL_10:.*]] = constant 0 : index
|
||||
// CHECK: %[[VAL_11:.*]] = cmpi sgt, %[[VAL_9]], %[[VAL_10]] : index
|
||||
// CHECK: %[[VAL_10:.*]] = arith.constant 0 : index
|
||||
// CHECK: %[[VAL_11:.*]] = arith.cmpi sgt, %[[VAL_9]], %[[VAL_10]] : index
|
||||
// CHECK: cond_br %[[VAL_11]], ^bb2, ^bb3
|
||||
// CHECK: ^bb2:
|
||||
// CHECK: %[[VAL_12:.*]] = fir.call @f2() : () -> i1
|
||||
// CHECK: %[[VAL_13:.*]] = addi %[[VAL_7]], %[[VAL_2]] : index
|
||||
// CHECK: %[[VAL_14:.*]] = constant 1 : index
|
||||
// CHECK: %[[VAL_15:.*]] = subi %[[VAL_9]], %[[VAL_14]] : index
|
||||
// CHECK: %[[VAL_13:.*]] = arith.addi %[[VAL_7]], %[[VAL_2]] : index
|
||||
// CHECK: %[[VAL_14:.*]] = arith.constant 1 : index
|
||||
// CHECK: %[[VAL_15:.*]] = arith.subi %[[VAL_9]], %[[VAL_14]] : index
|
||||
// CHECK: br ^bb1(%[[VAL_13]], %[[VAL_12]], %[[VAL_15]] : index, i1, index)
|
||||
// CHECK: ^bb3:
|
||||
// CHECK: return %[[VAL_8]] : i1
|
||||
|
|
@ -119,14 +119,14 @@ func @x3(%lo : index, %up : index) -> i1 {
|
|||
|
||||
// iterate_while with an extra loop-carried value
|
||||
func @y3(%lo : index, %up : index) -> i1 {
|
||||
%c1 = constant 1 : index
|
||||
%ok1 = constant true
|
||||
%c1 = arith.constant 1 : index
|
||||
%ok1 = arith.constant true
|
||||
%ok4 = fir.call @f2() : () -> i1
|
||||
%ok2:2 = fir.iterate_while (%i = %lo to %up step %c1) and (%ok3 = %ok1) iter_args(%j = %ok4) -> i1 {
|
||||
%ok = fir.call @f2() : () -> i1
|
||||
fir.result %ok3, %ok : i1, i1
|
||||
}
|
||||
%andok = and %ok2#0, %ok2#1 : i1
|
||||
%andok = arith.andi %ok2#0, %ok2#1 : i1
|
||||
return %andok : i1
|
||||
}
|
||||
|
||||
|
|
@ -135,27 +135,27 @@ func private @f4(i32) -> i1
|
|||
// CHECK-LABEL: func @y3(
|
||||
// CHECK-SAME: %[[VAL_0:.*]]: index,
|
||||
// CHECK-SAME: %[[VAL_1:.*]]: index) -> i1 {
|
||||
// CHECK: %[[VAL_2:.*]] = constant 1 : index
|
||||
// CHECK: %[[VAL_3:.*]] = constant true
|
||||
// CHECK: %[[VAL_2:.*]] = arith.constant 1 : index
|
||||
// CHECK: %[[VAL_3:.*]] = arith.constant true
|
||||
// CHECK: %[[VAL_4:.*]] = fir.call @f2() : () -> i1
|
||||
// CHECK: br ^bb1(%[[VAL_0]], %[[VAL_3]], %[[VAL_4]] : index, i1, i1)
|
||||
// CHECK: ^bb1(%[[VAL_5:.*]]: index, %[[VAL_6:.*]]: i1, %[[VAL_7:.*]]: i1):
|
||||
// CHECK: %[[VAL_8:.*]] = constant 0 : index
|
||||
// CHECK: %[[VAL_9:.*]] = cmpi slt, %[[VAL_8]], %[[VAL_2]] : index
|
||||
// CHECK: %[[VAL_10:.*]] = cmpi sle, %[[VAL_5]], %[[VAL_1]] : index
|
||||
// CHECK: %[[VAL_11:.*]] = cmpi slt, %[[VAL_2]], %[[VAL_8]] : index
|
||||
// CHECK: %[[VAL_12:.*]] = cmpi sle, %[[VAL_1]], %[[VAL_5]] : index
|
||||
// CHECK: %[[VAL_13:.*]] = and %[[VAL_9]], %[[VAL_10]] : i1
|
||||
// CHECK: %[[VAL_14:.*]] = and %[[VAL_11]], %[[VAL_12]] : i1
|
||||
// CHECK: %[[VAL_15:.*]] = or %[[VAL_13]], %[[VAL_14]] : i1
|
||||
// CHECK: %[[VAL_16:.*]] = and %[[VAL_6]], %[[VAL_15]] : i1
|
||||
// CHECK: %[[VAL_8:.*]] = arith.constant 0 : index
|
||||
// CHECK: %[[VAL_9:.*]] = arith.cmpi slt, %[[VAL_8]], %[[VAL_2]] : index
|
||||
// CHECK: %[[VAL_10:.*]] = arith.cmpi sle, %[[VAL_5]], %[[VAL_1]] : index
|
||||
// CHECK: %[[VAL_11:.*]] = arith.cmpi slt, %[[VAL_2]], %[[VAL_8]] : index
|
||||
// CHECK: %[[VAL_12:.*]] = arith.cmpi sle, %[[VAL_1]], %[[VAL_5]] : index
|
||||
// CHECK: %[[VAL_13:.*]] = arith.andi %[[VAL_9]], %[[VAL_10]] : i1
|
||||
// CHECK: %[[VAL_14:.*]] = arith.andi %[[VAL_11]], %[[VAL_12]] : i1
|
||||
// CHECK: %[[VAL_15:.*]] = arith.ori %[[VAL_13]], %[[VAL_14]] : i1
|
||||
// CHECK: %[[VAL_16:.*]] = arith.andi %[[VAL_6]], %[[VAL_15]] : i1
|
||||
// CHECK: cond_br %[[VAL_16]], ^bb2, ^bb3
|
||||
// CHECK: ^bb2:
|
||||
// CHECK: %[[VAL_17:.*]] = fir.call @f2() : () -> i1
|
||||
// CHECK: %[[VAL_18:.*]] = addi %[[VAL_5]], %[[VAL_2]] : index
|
||||
// CHECK: %[[VAL_18:.*]] = arith.addi %[[VAL_5]], %[[VAL_2]] : index
|
||||
// CHECK: br ^bb1(%[[VAL_18]], %[[VAL_6]], %[[VAL_17]] : index, i1, i1)
|
||||
// CHECK: ^bb3:
|
||||
// CHECK: %[[VAL_19:.*]] = and %[[VAL_6]], %[[VAL_7]] : i1
|
||||
// CHECK: %[[VAL_19:.*]] = arith.andi %[[VAL_6]], %[[VAL_7]] : i1
|
||||
// CHECK: return %[[VAL_19]] : i1
|
||||
// CHECK: }
|
||||
// CHECK: func private @f4(i32) -> i1
|
||||
|
|
@ -164,7 +164,7 @@ func private @f4(i32) -> i1
|
|||
|
||||
// do_loop that returns the final value of the induction
|
||||
func @x4(%lo : index, %up : index) -> index {
|
||||
%c1 = constant 1 : index
|
||||
%c1 = arith.constant 1 : index
|
||||
%v = fir.do_loop %i = %lo to %up step %c1 -> index {
|
||||
%i1 = fir.convert %i : (index) -> i32
|
||||
%ok = fir.call @f4(%i1) : (i32) -> i1
|
||||
|
|
@ -176,21 +176,21 @@ func @x4(%lo : index, %up : index) -> index {
|
|||
// CHECK-LABEL: func @x4(
|
||||
// CHECK-SAME: %[[VAL_0:.*]]: index,
|
||||
// CHECK-SAME: %[[VAL_1:.*]]: index) -> index {
|
||||
// CHECK: %[[VAL_2:.*]] = constant 1 : index
|
||||
// CHECK: %[[VAL_3:.*]] = subi %[[VAL_1]], %[[VAL_0]] : index
|
||||
// CHECK: %[[VAL_4:.*]] = addi %[[VAL_3]], %[[VAL_2]] : index
|
||||
// CHECK: %[[VAL_5:.*]] = divi_signed %[[VAL_4]], %[[VAL_2]] : index
|
||||
// CHECK: %[[VAL_2:.*]] = arith.constant 1 : index
|
||||
// CHECK: %[[VAL_3:.*]] = arith.subi %[[VAL_1]], %[[VAL_0]] : index
|
||||
// CHECK: %[[VAL_4:.*]] = arith.addi %[[VAL_3]], %[[VAL_2]] : index
|
||||
// CHECK: %[[VAL_5:.*]] = arith.divsi %[[VAL_4]], %[[VAL_2]] : index
|
||||
// CHECK: br ^bb1(%[[VAL_0]], %[[VAL_5]] : index, index)
|
||||
// CHECK: ^bb1(%[[VAL_6:.*]]: index, %[[VAL_7:.*]]: index):
|
||||
// CHECK: %[[VAL_8:.*]] = constant 0 : index
|
||||
// CHECK: %[[VAL_9:.*]] = cmpi sgt, %[[VAL_7]], %[[VAL_8]] : index
|
||||
// CHECK: %[[VAL_8:.*]] = arith.constant 0 : index
|
||||
// CHECK: %[[VAL_9:.*]] = arith.cmpi sgt, %[[VAL_7]], %[[VAL_8]] : index
|
||||
// CHECK: cond_br %[[VAL_9]], ^bb2, ^bb3
|
||||
// CHECK: ^bb2:
|
||||
// CHECK: %[[VAL_10:.*]] = fir.convert %[[VAL_6]] : (index) -> i32
|
||||
// CHECK: %[[VAL_11:.*]] = fir.call @f4(%[[VAL_10]]) : (i32) -> i1
|
||||
// CHECK: %[[VAL_12:.*]] = addi %[[VAL_6]], %[[VAL_2]] : index
|
||||
// CHECK: %[[VAL_13:.*]] = constant 1 : index
|
||||
// CHECK: %[[VAL_14:.*]] = subi %[[VAL_7]], %[[VAL_13]] : index
|
||||
// CHECK: %[[VAL_12:.*]] = arith.addi %[[VAL_6]], %[[VAL_2]] : index
|
||||
// CHECK: %[[VAL_13:.*]] = arith.constant 1 : index
|
||||
// CHECK: %[[VAL_14:.*]] = arith.subi %[[VAL_7]], %[[VAL_13]] : index
|
||||
// CHECK: br ^bb1(%[[VAL_12]], %[[VAL_14]] : index, index)
|
||||
// CHECK: ^bb3:
|
||||
// CHECK: return %[[VAL_6]] : index
|
||||
|
|
@ -200,8 +200,8 @@ func @x4(%lo : index, %up : index) -> index {
|
|||
|
||||
// iterate_while that returns the final value of both inductions
|
||||
func @y4(%lo : index, %up : index) -> index {
|
||||
%c1 = constant 1 : index
|
||||
%ok1 = constant true
|
||||
%c1 = arith.constant 1 : index
|
||||
%ok1 = arith.constant true
|
||||
%v:2 = fir.iterate_while (%i = %lo to %up step %c1) and (%ok2 = %ok1) -> (index, i1) {
|
||||
%i1 = fir.convert %i : (index) -> i32
|
||||
%ok = fir.call @f4(%i1) : (i32) -> i1
|
||||
|
|
@ -213,24 +213,24 @@ func @y4(%lo : index, %up : index) -> index {
|
|||
// CHECK-LABEL: func @y4(
|
||||
// CHECK-SAME: %[[VAL_0:.*]]: index,
|
||||
// CHECK-SAME: %[[VAL_1:.*]]: index) -> index {
|
||||
// CHECK: %[[VAL_2:.*]] = constant 1 : index
|
||||
// CHECK: %[[VAL_3:.*]] = constant true
|
||||
// CHECK: %[[VAL_2:.*]] = arith.constant 1 : index
|
||||
// CHECK: %[[VAL_3:.*]] = arith.constant true
|
||||
// CHECK: br ^bb1(%[[VAL_0]], %[[VAL_3]] : index, i1)
|
||||
// CHECK: ^bb1(%[[VAL_4:.*]]: index, %[[VAL_5:.*]]: i1):
|
||||
// CHECK: %[[VAL_6:.*]] = constant 0 : index
|
||||
// CHECK: %[[VAL_7:.*]] = cmpi slt, %[[VAL_6]], %[[VAL_2]] : index
|
||||
// CHECK: %[[VAL_8:.*]] = cmpi sle, %[[VAL_4]], %[[VAL_1]] : index
|
||||
// CHECK: %[[VAL_9:.*]] = cmpi slt, %[[VAL_2]], %[[VAL_6]] : index
|
||||
// CHECK: %[[VAL_10:.*]] = cmpi sle, %[[VAL_1]], %[[VAL_4]] : index
|
||||
// CHECK: %[[VAL_11:.*]] = and %[[VAL_7]], %[[VAL_8]] : i1
|
||||
// CHECK: %[[VAL_12:.*]] = and %[[VAL_9]], %[[VAL_10]] : i1
|
||||
// CHECK: %[[VAL_13:.*]] = or %[[VAL_11]], %[[VAL_12]] : i1
|
||||
// CHECK: %[[VAL_14:.*]] = and %[[VAL_5]], %[[VAL_13]] : i1
|
||||
// CHECK: %[[VAL_6:.*]] = arith.constant 0 : index
|
||||
// CHECK: %[[VAL_7:.*]] = arith.cmpi slt, %[[VAL_6]], %[[VAL_2]] : index
|
||||
// CHECK: %[[VAL_8:.*]] = arith.cmpi sle, %[[VAL_4]], %[[VAL_1]] : index
|
||||
// CHECK: %[[VAL_9:.*]] = arith.cmpi slt, %[[VAL_2]], %[[VAL_6]] : index
|
||||
// CHECK: %[[VAL_10:.*]] = arith.cmpi sle, %[[VAL_1]], %[[VAL_4]] : index
|
||||
// CHECK: %[[VAL_11:.*]] = arith.andi %[[VAL_7]], %[[VAL_8]] : i1
|
||||
// CHECK: %[[VAL_12:.*]] = arith.andi %[[VAL_9]], %[[VAL_10]] : i1
|
||||
// CHECK: %[[VAL_13:.*]] = arith.ori %[[VAL_11]], %[[VAL_12]] : i1
|
||||
// CHECK: %[[VAL_14:.*]] = arith.andi %[[VAL_5]], %[[VAL_13]] : i1
|
||||
// CHECK: cond_br %[[VAL_14]], ^bb2, ^bb3
|
||||
// CHECK: ^bb2:
|
||||
// CHECK: %[[VAL_15:.*]] = fir.convert %[[VAL_4]] : (index) -> i32
|
||||
// CHECK: %[[VAL_16:.*]] = fir.call @f4(%[[VAL_15]]) : (i32) -> i1
|
||||
// CHECK: %[[VAL_17:.*]] = addi %[[VAL_4]], %[[VAL_2]] : index
|
||||
// CHECK: %[[VAL_17:.*]] = arith.addi %[[VAL_4]], %[[VAL_2]] : index
|
||||
// CHECK: br ^bb1(%[[VAL_17]], %[[VAL_16]] : index, i1)
|
||||
// CHECK: ^bb3:
|
||||
// CHECK: return %[[VAL_4]] : index
|
||||
|
|
@ -241,8 +241,8 @@ func @y4(%lo : index, %up : index) -> index {
|
|||
// do_loop that returns the final induction value
|
||||
// and an extra loop-carried value
|
||||
func @x5(%lo : index, %up : index) -> index {
|
||||
%c1 = constant 1 : index
|
||||
%s1 = constant 42 : i16
|
||||
%c1 = arith.constant 1 : index
|
||||
%s1 = arith.constant 42 : i16
|
||||
%v:2 = fir.do_loop %i = %lo to %up step %c1 iter_args(%s = %s1) -> (index, i16) {
|
||||
%ok = fir.call @f2() : () -> i1
|
||||
%s2 = fir.convert %ok : (i1) -> i16
|
||||
|
|
@ -255,22 +255,22 @@ func @x5(%lo : index, %up : index) -> index {
|
|||
// CHECK-LABEL: func @x5(
|
||||
// CHECK-SAME: %[[VAL_0:.*]]: index,
|
||||
// CHECK-SAME: %[[VAL_1:.*]]: index) -> index {
|
||||
// CHECK: %[[VAL_2:.*]] = constant 1 : index
|
||||
// CHECK: %[[VAL_3:.*]] = constant 42 : i16
|
||||
// CHECK: %[[VAL_4:.*]] = subi %[[VAL_1]], %[[VAL_0]] : index
|
||||
// CHECK: %[[VAL_5:.*]] = addi %[[VAL_4]], %[[VAL_2]] : index
|
||||
// CHECK: %[[VAL_6:.*]] = divi_signed %[[VAL_5]], %[[VAL_2]] : index
|
||||
// CHECK: %[[VAL_2:.*]] = arith.constant 1 : index
|
||||
// CHECK: %[[VAL_3:.*]] = arith.constant 42 : i16
|
||||
// CHECK: %[[VAL_4:.*]] = arith.subi %[[VAL_1]], %[[VAL_0]] : index
|
||||
// CHECK: %[[VAL_5:.*]] = arith.addi %[[VAL_4]], %[[VAL_2]] : index
|
||||
// CHECK: %[[VAL_6:.*]] = arith.divsi %[[VAL_5]], %[[VAL_2]] : index
|
||||
// CHECK: br ^bb1(%[[VAL_0]], %[[VAL_3]], %[[VAL_6]] : index, i16, index)
|
||||
// CHECK: ^bb1(%[[VAL_7:.*]]: index, %[[VAL_8:.*]]: i16, %[[VAL_9:.*]]: index):
|
||||
// CHECK: %[[VAL_10:.*]] = constant 0 : index
|
||||
// CHECK: %[[VAL_11:.*]] = cmpi sgt, %[[VAL_9]], %[[VAL_10]] : index
|
||||
// CHECK: %[[VAL_10:.*]] = arith.constant 0 : index
|
||||
// CHECK: %[[VAL_11:.*]] = arith.cmpi sgt, %[[VAL_9]], %[[VAL_10]] : index
|
||||
// CHECK: cond_br %[[VAL_11]], ^bb2, ^bb3
|
||||
// CHECK: ^bb2:
|
||||
// CHECK: %[[VAL_12:.*]] = fir.call @f2() : () -> i1
|
||||
// CHECK: %[[VAL_13:.*]] = fir.convert %[[VAL_12]] : (i1) -> i16
|
||||
// CHECK: %[[VAL_14:.*]] = addi %[[VAL_7]], %[[VAL_2]] : index
|
||||
// CHECK: %[[VAL_15:.*]] = constant 1 : index
|
||||
// CHECK: %[[VAL_16:.*]] = subi %[[VAL_9]], %[[VAL_15]] : index
|
||||
// CHECK: %[[VAL_14:.*]] = arith.addi %[[VAL_7]], %[[VAL_2]] : index
|
||||
// CHECK: %[[VAL_15:.*]] = arith.constant 1 : index
|
||||
// CHECK: %[[VAL_16:.*]] = arith.subi %[[VAL_9]], %[[VAL_15]] : index
|
||||
// CHECK: br ^bb1(%[[VAL_14]], %[[VAL_13]], %[[VAL_16]] : index, i16, index)
|
||||
// CHECK: ^bb3:
|
||||
// CHECK: fir.call @f3(%[[VAL_8]]) : (i16) -> ()
|
||||
|
|
@ -282,16 +282,16 @@ func @x5(%lo : index, %up : index) -> index {
|
|||
// iterate_while that returns the both induction values
|
||||
// and an extra loop-carried value
|
||||
func @y5(%lo : index, %up : index) -> index {
|
||||
%c1 = constant 1 : index
|
||||
%s1 = constant 42 : i16
|
||||
%ok1 = constant true
|
||||
%c1 = arith.constant 1 : index
|
||||
%s1 = arith.constant 42 : i16
|
||||
%ok1 = arith.constant true
|
||||
%v:3 = fir.iterate_while (%i = %lo to %up step %c1) and (%ok2 = %ok1) iter_args(%s = %s1) -> (index, i1, i16) {
|
||||
%ok = fir.call @f2() : () -> i1
|
||||
%s2 = fir.convert %ok : (i1) -> i16
|
||||
fir.result %i, %ok, %s2 : index, i1, i16
|
||||
}
|
||||
fir.if %v#1 {
|
||||
%arg = constant 0 : i32
|
||||
%arg = arith.constant 0 : i32
|
||||
%ok4 = fir.call @f4(%arg) : (i32) -> i1
|
||||
}
|
||||
fir.call @f3(%v#2) : (i16) -> ()
|
||||
|
|
@ -301,30 +301,30 @@ func @y5(%lo : index, %up : index) -> index {
|
|||
// CHECK-LABEL: func @y5(
|
||||
// CHECK-SAME: %[[VAL_0:.*]]: index,
|
||||
// CHECK-SAME: %[[VAL_1:.*]]: index) -> index {
|
||||
// CHECK: %[[VAL_2:.*]] = constant 1 : index
|
||||
// CHECK: %[[VAL_3:.*]] = constant 42 : i16
|
||||
// CHECK: %[[VAL_4:.*]] = constant true
|
||||
// CHECK: %[[VAL_2:.*]] = arith.constant 1 : index
|
||||
// CHECK: %[[VAL_3:.*]] = arith.constant 42 : i16
|
||||
// CHECK: %[[VAL_4:.*]] = arith.constant true
|
||||
// CHECK: br ^bb1(%[[VAL_0]], %[[VAL_4]], %[[VAL_3]] : index, i1, i16)
|
||||
// CHECK: ^bb1(%[[VAL_5:.*]]: index, %[[VAL_6:.*]]: i1, %[[VAL_7:.*]]: i16):
|
||||
// CHECK: %[[VAL_8:.*]] = constant 0 : index
|
||||
// CHECK: %[[VAL_9:.*]] = cmpi slt, %[[VAL_8]], %[[VAL_2]] : index
|
||||
// CHECK: %[[VAL_10:.*]] = cmpi sle, %[[VAL_5]], %[[VAL_1]] : index
|
||||
// CHECK: %[[VAL_11:.*]] = cmpi slt, %[[VAL_2]], %[[VAL_8]] : index
|
||||
// CHECK: %[[VAL_12:.*]] = cmpi sle, %[[VAL_1]], %[[VAL_5]] : index
|
||||
// CHECK: %[[VAL_13:.*]] = and %[[VAL_9]], %[[VAL_10]] : i1
|
||||
// CHECK: %[[VAL_14:.*]] = and %[[VAL_11]], %[[VAL_12]] : i1
|
||||
// CHECK: %[[VAL_15:.*]] = or %[[VAL_13]], %[[VAL_14]] : i1
|
||||
// CHECK: %[[VAL_16:.*]] = and %[[VAL_6]], %[[VAL_15]] : i1
|
||||
// CHECK: %[[VAL_8:.*]] = arith.constant 0 : index
|
||||
// CHECK: %[[VAL_9:.*]] = arith.cmpi slt, %[[VAL_8]], %[[VAL_2]] : index
|
||||
// CHECK: %[[VAL_10:.*]] = arith.cmpi sle, %[[VAL_5]], %[[VAL_1]] : index
|
||||
// CHECK: %[[VAL_11:.*]] = arith.cmpi slt, %[[VAL_2]], %[[VAL_8]] : index
|
||||
// CHECK: %[[VAL_12:.*]] = arith.cmpi sle, %[[VAL_1]], %[[VAL_5]] : index
|
||||
// CHECK: %[[VAL_13:.*]] = arith.andi %[[VAL_9]], %[[VAL_10]] : i1
|
||||
// CHECK: %[[VAL_14:.*]] = arith.andi %[[VAL_11]], %[[VAL_12]] : i1
|
||||
// CHECK: %[[VAL_15:.*]] = arith.ori %[[VAL_13]], %[[VAL_14]] : i1
|
||||
// CHECK: %[[VAL_16:.*]] = arith.andi %[[VAL_6]], %[[VAL_15]] : i1
|
||||
// CHECK: cond_br %[[VAL_16]], ^bb2, ^bb3
|
||||
// CHECK: ^bb2:
|
||||
// CHECK: %[[VAL_17:.*]] = fir.call @f2() : () -> i1
|
||||
// CHECK: %[[VAL_18:.*]] = fir.convert %[[VAL_17]] : (i1) -> i16
|
||||
// CHECK: %[[VAL_19:.*]] = addi %[[VAL_5]], %[[VAL_2]] : index
|
||||
// CHECK: %[[VAL_19:.*]] = arith.addi %[[VAL_5]], %[[VAL_2]] : index
|
||||
// CHECK: br ^bb1(%[[VAL_19]], %[[VAL_17]], %[[VAL_18]] : index, i1, i16)
|
||||
// CHECK: ^bb3:
|
||||
// CHECK: cond_br %[[VAL_6]], ^bb4, ^bb5
|
||||
// CHECK: ^bb4:
|
||||
// CHECK: %[[VAL_20:.*]] = constant 0 : i32
|
||||
// CHECK: %[[VAL_20:.*]] = arith.constant 0 : i32
|
||||
// CHECK: %[[VAL_21:.*]] = fir.call @f4(%[[VAL_20]]) : (i32) -> i1
|
||||
// CHECK: br ^bb5
|
||||
// CHECK: ^bb5:
|
||||
|
|
|
|||
|
|
@ -2,8 +2,8 @@
|
|||
// RUN: fir-opt --cfg-conversion %s | FileCheck %s --check-prefix=NOOPT
|
||||
|
||||
func @x(%addr : !fir.ref<index>) {
|
||||
%bound = constant 452 : index
|
||||
%step = constant 1 : index
|
||||
%bound = arith.constant 452 : index
|
||||
%step = arith.constant 1 : index
|
||||
fir.do_loop %iv = %bound to %bound step %step {
|
||||
fir.call @y(%addr) : (!fir.ref<index>) -> ()
|
||||
}
|
||||
|
|
@ -15,25 +15,25 @@ func private @y(%addr : !fir.ref<index>)
|
|||
|
||||
// CHECK-LABEL: func @x(
|
||||
// CHECK-SAME: %[[VAL_0:.*]]: !fir.ref<index>) {
|
||||
// CHECK: %[[VAL_1:.*]] = constant 452 : index
|
||||
// CHECK: %[[VAL_2:.*]] = constant 1 : index
|
||||
// CHECK: %[[VAL_3:.*]] = subi %[[VAL_1]], %[[VAL_1]] : index
|
||||
// CHECK: %[[VAL_4:.*]] = addi %[[VAL_3]], %[[VAL_2]] : index
|
||||
// CHECK: %[[VAL_5:.*]] = divi_signed %[[VAL_4]], %[[VAL_2]] : index
|
||||
// CHECK: %[[VAL_6:.*]] = constant 0 : index
|
||||
// CHECK: %[[VAL_7:.*]] = cmpi sle, %[[VAL_5]], %[[VAL_6]] : index
|
||||
// CHECK: %[[VAL_8:.*]] = constant 1 : index
|
||||
// CHECK: %[[VAL_1:.*]] = arith.constant 452 : index
|
||||
// CHECK: %[[VAL_2:.*]] = arith.constant 1 : index
|
||||
// CHECK: %[[VAL_3:.*]] = arith.subi %[[VAL_1]], %[[VAL_1]] : index
|
||||
// CHECK: %[[VAL_4:.*]] = arith.addi %[[VAL_3]], %[[VAL_2]] : index
|
||||
// CHECK: %[[VAL_5:.*]] = arith.divsi %[[VAL_4]], %[[VAL_2]] : index
|
||||
// CHECK: %[[VAL_6:.*]] = arith.constant 0 : index
|
||||
// CHECK: %[[VAL_7:.*]] = arith.cmpi sle, %[[VAL_5]], %[[VAL_6]] : index
|
||||
// CHECK: %[[VAL_8:.*]] = arith.constant 1 : index
|
||||
// CHECK: %[[VAL_9:.*]] = select %[[VAL_7]], %[[VAL_8]], %[[VAL_5]] : index
|
||||
// CHECK: br ^bb1(%[[VAL_1]], %[[VAL_9]] : index, index)
|
||||
// CHECK: ^bb1(%[[VAL_10:.*]]: index, %[[VAL_11:.*]]: index):
|
||||
// CHECK: %[[VAL_12:.*]] = constant 0 : index
|
||||
// CHECK: %[[VAL_13:.*]] = cmpi sgt, %[[VAL_11]], %[[VAL_12]] : index
|
||||
// CHECK: %[[VAL_12:.*]] = arith.constant 0 : index
|
||||
// CHECK: %[[VAL_13:.*]] = arith.cmpi sgt, %[[VAL_11]], %[[VAL_12]] : index
|
||||
// CHECK: cond_br %[[VAL_13]], ^bb2, ^bb3
|
||||
// CHECK: ^bb2:
|
||||
// CHECK: fir.call @y(%[[VAL_0]]) : (!fir.ref<index>) -> ()
|
||||
// CHECK: %[[VAL_14:.*]] = addi %[[VAL_10]], %[[VAL_2]] : index
|
||||
// CHECK: %[[VAL_15:.*]] = constant 1 : index
|
||||
// CHECK: %[[VAL_16:.*]] = subi %[[VAL_11]], %[[VAL_15]] : index
|
||||
// CHECK: %[[VAL_14:.*]] = arith.addi %[[VAL_10]], %[[VAL_2]] : index
|
||||
// CHECK: %[[VAL_15:.*]] = arith.constant 1 : index
|
||||
// CHECK: %[[VAL_16:.*]] = arith.subi %[[VAL_11]], %[[VAL_15]] : index
|
||||
// CHECK: br ^bb1(%[[VAL_14]], %[[VAL_16]] : index, index)
|
||||
// CHECK: ^bb3:
|
||||
// CHECK: return
|
||||
|
|
@ -42,21 +42,21 @@ func private @y(%addr : !fir.ref<index>)
|
|||
|
||||
// NOOPT-LABEL: func @x(
|
||||
// NOOPT-SAME: %[[VAL_0:.*]]: !fir.ref<index>) {
|
||||
// NOOPT: %[[VAL_1:.*]] = constant 452 : index
|
||||
// NOOPT: %[[VAL_2:.*]] = constant 1 : index
|
||||
// NOOPT: %[[VAL_3:.*]] = subi %[[VAL_1]], %[[VAL_1]] : index
|
||||
// NOOPT: %[[VAL_4:.*]] = addi %[[VAL_3]], %[[VAL_2]] : index
|
||||
// NOOPT: %[[VAL_5:.*]] = divi_signed %[[VAL_4]], %[[VAL_2]] : index
|
||||
// NOOPT: %[[VAL_1:.*]] = arith.constant 452 : index
|
||||
// NOOPT: %[[VAL_2:.*]] = arith.constant 1 : index
|
||||
// NOOPT: %[[VAL_3:.*]] = arith.subi %[[VAL_1]], %[[VAL_1]] : index
|
||||
// NOOPT: %[[VAL_4:.*]] = arith.addi %[[VAL_3]], %[[VAL_2]] : index
|
||||
// NOOPT: %[[VAL_5:.*]] = arith.divsi %[[VAL_4]], %[[VAL_2]] : index
|
||||
// NOOPT: br ^bb1(%[[VAL_1]], %[[VAL_5]] : index, index)
|
||||
// NOOPT: ^bb1(%[[VAL_6:.*]]: index, %[[VAL_7:.*]]: index):
|
||||
// NOOPT: %[[VAL_8:.*]] = constant 0 : index
|
||||
// NOOPT: %[[VAL_9:.*]] = cmpi sgt, %[[VAL_7]], %[[VAL_8]] : index
|
||||
// NOOPT: %[[VAL_8:.*]] = arith.constant 0 : index
|
||||
// NOOPT: %[[VAL_9:.*]] = arith.cmpi sgt, %[[VAL_7]], %[[VAL_8]] : index
|
||||
// NOOPT: cond_br %[[VAL_9]], ^bb2, ^bb3
|
||||
// NOOPT: ^bb2:
|
||||
// NOOPT: fir.call @y(%[[VAL_0]]) : (!fir.ref<index>) -> ()
|
||||
// NOOPT: %[[VAL_10:.*]] = addi %[[VAL_6]], %[[VAL_2]] : index
|
||||
// NOOPT: %[[VAL_11:.*]] = constant 1 : index
|
||||
// NOOPT: %[[VAL_12:.*]] = subi %[[VAL_7]], %[[VAL_11]] : index
|
||||
// NOOPT: %[[VAL_10:.*]] = arith.addi %[[VAL_6]], %[[VAL_2]] : index
|
||||
// NOOPT: %[[VAL_11:.*]] = arith.constant 1 : index
|
||||
// NOOPT: %[[VAL_12:.*]] = arith.subi %[[VAL_7]], %[[VAL_11]] : index
|
||||
// NOOPT: br ^bb1(%[[VAL_10]], %[[VAL_12]] : index, index)
|
||||
// NOOPT: ^bb3:
|
||||
// NOOPT: return
|
||||
|
|
|
|||
|
|
@ -8,22 +8,22 @@
|
|||
|
||||
### Pre-requisites
|
||||
|
||||
* A relatively recent Python3 installation
|
||||
* Installation of python dependencies as specified in
|
||||
`mlir/python/requirements.txt`
|
||||
* A relatively recent Python3 installation
|
||||
* Installation of python dependencies as specified in
|
||||
`mlir/python/requirements.txt`
|
||||
|
||||
### CMake variables
|
||||
|
||||
* **`MLIR_ENABLE_BINDINGS_PYTHON`**`:BOOL`
|
||||
* **`MLIR_ENABLE_BINDINGS_PYTHON`**`:BOOL`
|
||||
|
||||
Enables building the Python bindings. Defaults to `OFF`.
|
||||
Enables building the Python bindings. Defaults to `OFF`.
|
||||
|
||||
* **`Python3_EXECUTABLE`**:`STRING`
|
||||
* **`Python3_EXECUTABLE`**:`STRING`
|
||||
|
||||
Specifies the `python` executable used for the LLVM build, including for
|
||||
determining header/link flags for the Python bindings. On systems with
|
||||
multiple Python implementations, setting this explicitly to the preferred
|
||||
`python3` executable is strongly recommended.
|
||||
Specifies the `python` executable used for the LLVM build, including for
|
||||
determining header/link flags for the Python bindings. On systems with
|
||||
multiple Python implementations, setting this explicitly to the preferred
|
||||
`python3` executable is strongly recommended.
|
||||
|
||||
### Recommended development practices
|
||||
|
||||
|
|
@ -62,8 +62,8 @@ the `PYTHONPATH`. Typically:
|
|||
export PYTHONPATH=$(cd build && pwd)/tools/mlir/python_packages/mlir_core
|
||||
```
|
||||
|
||||
Note that if you have installed (i.e. via `ninja install`, et al), then
|
||||
python packages for all enabled projects will be in your install tree under
|
||||
Note that if you have installed (i.e. via `ninja install`, et al), then python
|
||||
packages for all enabled projects will be in your install tree under
|
||||
`python_packages/` (i.e. `python_packages/mlir_core`). Official distributions
|
||||
are built with a more specialized setup.
|
||||
|
||||
|
|
@ -73,12 +73,12 @@ are built with a more specialized setup.
|
|||
|
||||
There are likely two primary use cases for the MLIR python bindings:
|
||||
|
||||
1. Support users who expect that an installed version of LLVM/MLIR will yield
|
||||
the ability to `import mlir` and use the API in a pure way out of the box.
|
||||
1. Support users who expect that an installed version of LLVM/MLIR will yield
|
||||
the ability to `import mlir` and use the API in a pure way out of the box.
|
||||
|
||||
1. Downstream integrations will likely want to include parts of the API in their
|
||||
private namespace or specially built libraries, probably mixing it with other
|
||||
python native bits.
|
||||
1. Downstream integrations will likely want to include parts of the API in
|
||||
their private namespace or specially built libraries, probably mixing it
|
||||
with other python native bits.
|
||||
|
||||
### Composable modules
|
||||
|
||||
|
|
@ -86,15 +86,15 @@ In order to support use case \#2, the Python bindings are organized into
|
|||
composable modules that downstream integrators can include and re-export into
|
||||
their own namespace if desired. This forces several design points:
|
||||
|
||||
* Separate the construction/populating of a `py::module` from `PYBIND11_MODULE`
|
||||
global constructor.
|
||||
* Separate the construction/populating of a `py::module` from
|
||||
`PYBIND11_MODULE` global constructor.
|
||||
|
||||
* Introduce headers for C++-only wrapper classes as other related C++ modules
|
||||
will need to interop with it.
|
||||
* Introduce headers for C++-only wrapper classes as other related C++ modules
|
||||
will need to interop with it.
|
||||
|
||||
* Separate any initialization routines that depend on optional components into
|
||||
its own module/dependency (currently, things like `registerAllDialects` fall
|
||||
into this category).
|
||||
* Separate any initialization routines that depend on optional components into
|
||||
its own module/dependency (currently, things like `registerAllDialects` fall
|
||||
into this category).
|
||||
|
||||
There are a lot of co-related issues of shared library linkage, distribution
|
||||
concerns, etc that affect such things. Organizing the code into composable
|
||||
|
|
@ -113,17 +113,17 @@ of functional units in MLIR.
|
|||
|
||||
Examples:
|
||||
|
||||
* `mlir.ir`
|
||||
* `mlir.passes` (`pass` is a reserved word :( )
|
||||
* `mlir.dialect`
|
||||
* `mlir.execution_engine` (aside from namespacing, it is important that
|
||||
"bulky"/optional parts like this are isolated)
|
||||
* `mlir.ir`
|
||||
* `mlir.passes` (`pass` is a reserved word :( )
|
||||
* `mlir.dialect`
|
||||
* `mlir.execution_engine` (aside from namespacing, it is important that
|
||||
"bulky"/optional parts like this are isolated)
|
||||
|
||||
In addition, initialization functions that imply optional dependencies should
|
||||
be in underscored (notionally private) modules such as `_init` and linked
|
||||
In addition, initialization functions that imply optional dependencies should be
|
||||
in underscored (notionally private) modules such as `_init` and linked
|
||||
separately. This allows downstream integrators to completely customize what is
|
||||
included "in the box" and covers things like dialect registration,
|
||||
pass registration, etc.
|
||||
included "in the box" and covers things like dialect registration, pass
|
||||
registration, etc.
|
||||
|
||||
### Loader
|
||||
|
||||
|
|
@ -131,17 +131,16 @@ LLVM/MLIR is a non-trivial python-native project that is likely to co-exist with
|
|||
other non-trivial native extensions. As such, the native extension (i.e. the
|
||||
`.so`/`.pyd`/`.dylib`) is exported as a notionally private top-level symbol
|
||||
(`_mlir`), while a small set of Python code is provided in
|
||||
`mlir/_cext_loader.py` and siblings which loads and re-exports it. This
|
||||
split provides a place to stage code that needs to prepare the environment
|
||||
*before* the shared library is loaded into the Python runtime, and also
|
||||
provides a place that one-time initialization code can be invoked apart from
|
||||
module constructors.
|
||||
`mlir/_cext_loader.py` and siblings which loads and re-exports it. This split
|
||||
provides a place to stage code that needs to prepare the environment *before*
|
||||
the shared library is loaded into the Python runtime, and also provides a place
|
||||
that one-time initialization code can be invoked apart from module constructors.
|
||||
|
||||
It is recommended to avoid using `__init__.py` files to the extent possible,
|
||||
until reaching a leaf package that represents a discrete component. The rule
|
||||
to keep in mind is that the presence of an `__init__.py` file prevents the
|
||||
ability to split anything at that level or below in the namespace into
|
||||
different directories, deployment packages, wheels, etc.
|
||||
until reaching a leaf package that represents a discrete component. The rule to
|
||||
keep in mind is that the presence of an `__init__.py` file prevents the ability
|
||||
to split anything at that level or below in the namespace into different
|
||||
directories, deployment packages, wheels, etc.
|
||||
|
||||
See the documentation for more information and advice:
|
||||
https://packaging.python.org/guides/packaging-namespace-packages/
|
||||
|
|
@ -157,11 +156,12 @@ are) with non-RTTI polymorphic C++ code (the default compilation mode of LLVM).
|
|||
|
||||
### Ownership in the Core IR
|
||||
|
||||
There are several top-level types in the core IR that are strongly owned by their python-side reference:
|
||||
There are several top-level types in the core IR that are strongly owned by
|
||||
their python-side reference:
|
||||
|
||||
* `PyContext` (`mlir.ir.Context`)
|
||||
* `PyModule` (`mlir.ir.Module`)
|
||||
* `PyOperation` (`mlir.ir.Operation`) - but with caveats
|
||||
* `PyContext` (`mlir.ir.Context`)
|
||||
* `PyModule` (`mlir.ir.Module`)
|
||||
* `PyOperation` (`mlir.ir.Operation`) - but with caveats
|
||||
|
||||
All other objects are dependent. All objects maintain a back-reference
|
||||
(keep-alive) to their closest containing top-level object. Further, dependent
|
||||
|
|
@ -173,11 +173,12 @@ bulk operation).
|
|||
|
||||
### Optionality and argument ordering in the Core IR
|
||||
|
||||
The following types support being bound to the current thread as a context manager:
|
||||
The following types support being bound to the current thread as a context
|
||||
manager:
|
||||
|
||||
* `PyLocation` (`loc: mlir.ir.Location = None`)
|
||||
* `PyInsertionPoint` (`ip: mlir.ir.InsertionPoint = None`)
|
||||
* `PyMlirContext` (`context: mlir.ir.Context = None`)
|
||||
* `PyLocation` (`loc: mlir.ir.Location = None`)
|
||||
* `PyInsertionPoint` (`ip: mlir.ir.InsertionPoint = None`)
|
||||
* `PyMlirContext` (`context: mlir.ir.Context = None`)
|
||||
|
||||
In order to support composability of function arguments, when these types appear
|
||||
as arguments, they should always be the last and appear in the above order and
|
||||
|
|
@ -692,9 +693,9 @@ Over:
|
|||
m.def("getContext", ...)
|
||||
```
|
||||
|
||||
### __repr__ methods
|
||||
### **repr** methods
|
||||
|
||||
Things that have nice printed representations are really great :) If there is a
|
||||
Things that have nice printed representations are really great :) If there is a
|
||||
reasonable printed form, it can be a significant productivity boost to wire that
|
||||
to the `__repr__` method (and verify it with a [doctest](#sample-doctest)).
|
||||
|
||||
|
|
@ -759,14 +760,14 @@ typically be `.py` files that have a lit run line.
|
|||
|
||||
We use `lit` and `FileCheck` based tests:
|
||||
|
||||
* For generative tests (those that produce IR), define a Python module that
|
||||
constructs/prints the IR and pipe it through `FileCheck`.
|
||||
* Parsing should be kept self-contained within the module under test by use of
|
||||
raw constants and an appropriate `parse_asm` call.
|
||||
* Any file I/O code should be staged through a tempfile vs relying on file
|
||||
artifacts/paths outside of the test module.
|
||||
* For convenience, we also test non-generative API interactions with the same
|
||||
mechanisms, printing and `CHECK`ing as needed.
|
||||
* For generative tests (those that produce IR), define a Python module that
|
||||
constructs/prints the IR and pipe it through `FileCheck`.
|
||||
* Parsing should be kept self-contained within the module under test by use of
|
||||
raw constants and an appropriate `parse_asm` call.
|
||||
* Any file I/O code should be staged through a tempfile vs relying on file
|
||||
artifacts/paths outside of the test module.
|
||||
* For convenience, we also test non-generative API interactions with the same
|
||||
mechanisms, printing and `CHECK`ing as needed.
|
||||
|
||||
### Sample FileCheck test
|
||||
|
||||
|
|
@ -794,13 +795,13 @@ def create_my_op():
|
|||
## Integration with ODS
|
||||
|
||||
The MLIR Python bindings integrate with the tablegen-based ODS system for
|
||||
providing user-friendly wrappers around MLIR dialects and operations. There
|
||||
are multiple parts to this integration, outlined below. Most details have
|
||||
been elided: refer to the build rules and python sources under `mlir.dialects`
|
||||
for the canonical way to use this facility.
|
||||
providing user-friendly wrappers around MLIR dialects and operations. There are
|
||||
multiple parts to this integration, outlined below. Most details have been
|
||||
elided: refer to the build rules and python sources under `mlir.dialects` for
|
||||
the canonical way to use this facility.
|
||||
|
||||
Users are responsible for providing a `{DIALECT_NAMESPACE}.py` (or an
|
||||
equivalent directory with `__init__.py` file) as the entrypoint.
|
||||
Users are responsible for providing a `{DIALECT_NAMESPACE}.py` (or an equivalent
|
||||
directory with `__init__.py` file) as the entrypoint.
|
||||
|
||||
### Generating `_{DIALECT_NAMESPACE}_ops_gen.py` wrapper modules
|
||||
|
||||
|
|
@ -838,10 +839,10 @@ from ._my_dialect_ops_gen import *
|
|||
### Extending the search path for wrapper modules
|
||||
|
||||
When the python bindings need to locate a wrapper module, they consult the
|
||||
`dialect_search_path` and use it to find an appropriately named module. For
|
||||
the main repository, this search path is hard-coded to include the
|
||||
`mlir.dialects` module, which is where wrappers are emitted by the abobe build
|
||||
rule. Out of tree dialects and add their modules to the search path by calling:
|
||||
`dialect_search_path` and use it to find an appropriately named module. For the
|
||||
main repository, this search path is hard-coded to include the `mlir.dialects`
|
||||
module, which is where wrappers are emitted by the abobe build rule. Out of tree
|
||||
dialects and add their modules to the search path by calling:
|
||||
|
||||
```python
|
||||
mlir._cext.append_dialect_search_prefix("myproject.mlir.dialects")
|
||||
|
|
@ -851,10 +852,10 @@ mlir._cext.append_dialect_search_prefix("myproject.mlir.dialects")
|
|||
|
||||
The wrapper module tablegen emitter outputs:
|
||||
|
||||
* A `_Dialect` class (extending `mlir.ir.Dialect`) with a `DIALECT_NAMESPACE`
|
||||
attribute.
|
||||
* An `{OpName}` class for each operation (extending `mlir.ir.OpView`).
|
||||
* Decorators for each of the above to register with the system.
|
||||
* A `_Dialect` class (extending `mlir.ir.Dialect`) with a `DIALECT_NAMESPACE`
|
||||
attribute.
|
||||
* An `{OpName}` class for each operation (extending `mlir.ir.OpView`).
|
||||
* Decorators for each of the above to register with the system.
|
||||
|
||||
Note: In order to avoid naming conflicts, all internal names used by the wrapper
|
||||
module are prefixed by `_ods_`.
|
||||
|
|
@ -862,54 +863,54 @@ module are prefixed by `_ods_`.
|
|||
Each concrete `OpView` subclass further defines several public-intended
|
||||
attributes:
|
||||
|
||||
* `OPERATION_NAME` attribute with the `str` fully qualified operation name
|
||||
(i.e. `std.absf`).
|
||||
* An `__init__` method for the *default builder* if one is defined or inferred
|
||||
for the operation.
|
||||
* `@property` getter for each operand or result (using an auto-generated name
|
||||
for unnamed of each).
|
||||
* `@property` getter, setter and deleter for each declared attribute.
|
||||
* `OPERATION_NAME` attribute with the `str` fully qualified operation name
|
||||
(i.e. `math.abs`).
|
||||
* An `__init__` method for the *default builder* if one is defined or inferred
|
||||
for the operation.
|
||||
* `@property` getter for each operand or result (using an auto-generated name
|
||||
for unnamed of each).
|
||||
* `@property` getter, setter and deleter for each declared attribute.
|
||||
|
||||
It further emits additional private-intended attributes meant for subclassing
|
||||
and customization (default cases omit these attributes in favor of the
|
||||
defaults on `OpView`):
|
||||
and customization (default cases omit these attributes in favor of the defaults
|
||||
on `OpView`):
|
||||
|
||||
* `_ODS_REGIONS`: A specification on the number and types of regions.
|
||||
Currently a tuple of (min_region_count, has_no_variadic_regions). Note that
|
||||
the API does some light validation on this but the primary purpose is to
|
||||
capture sufficient information to perform other default building and region
|
||||
accessor generation.
|
||||
* `_ODS_OPERAND_SEGMENTS` and `_ODS_RESULT_SEGMENTS`: Black-box value which
|
||||
indicates the structure of either the operand or results with respect to
|
||||
variadics. Used by `OpView._ods_build_default` to decode operand and result
|
||||
lists that contain lists.
|
||||
* `_ODS_REGIONS`: A specification on the number and types of regions.
|
||||
Currently a tuple of (min_region_count, has_no_variadic_regions). Note that
|
||||
the API does some light validation on this but the primary purpose is to
|
||||
capture sufficient information to perform other default building and region
|
||||
accessor generation.
|
||||
* `_ODS_OPERAND_SEGMENTS` and `_ODS_RESULT_SEGMENTS`: Black-box value which
|
||||
indicates the structure of either the operand or results with respect to
|
||||
variadics. Used by `OpView._ods_build_default` to decode operand and result
|
||||
lists that contain lists.
|
||||
|
||||
#### Default Builder
|
||||
|
||||
Presently, only a single, default builder is mapped to the `__init__` method.
|
||||
The intent is that this `__init__` method represents the *most specific* of
|
||||
the builders typically generated for C++; however currently it is just the
|
||||
generic form below.
|
||||
The intent is that this `__init__` method represents the *most specific* of the
|
||||
builders typically generated for C++; however currently it is just the generic
|
||||
form below.
|
||||
|
||||
* One argument for each declared result:
|
||||
* For single-valued results: Each will accept an `mlir.ir.Type`.
|
||||
* For variadic results: Each will accept a `List[mlir.ir.Type]`.
|
||||
* One argument for each declared operand or attribute:
|
||||
* For single-valued operands: Each will accept an `mlir.ir.Value`.
|
||||
* For variadic operands: Each will accept a `List[mlir.ir.Value]`.
|
||||
* For attributes, it will accept an `mlir.ir.Attribute`.
|
||||
* Trailing usage-specific, optional keyword arguments:
|
||||
* `loc`: An explicit `mlir.ir.Location` to use. Defaults to the location
|
||||
bound to the thread (i.e. `with Location.unknown():`) or an error if none
|
||||
is bound nor specified.
|
||||
* `ip`: An explicit `mlir.ir.InsertionPoint` to use. Default to the insertion
|
||||
point bound to the thread (i.e. `with InsertionPoint(...):`).
|
||||
* One argument for each declared result:
|
||||
* For single-valued results: Each will accept an `mlir.ir.Type`.
|
||||
* For variadic results: Each will accept a `List[mlir.ir.Type]`.
|
||||
* One argument for each declared operand or attribute:
|
||||
* For single-valued operands: Each will accept an `mlir.ir.Value`.
|
||||
* For variadic operands: Each will accept a `List[mlir.ir.Value]`.
|
||||
* For attributes, it will accept an `mlir.ir.Attribute`.
|
||||
* Trailing usage-specific, optional keyword arguments:
|
||||
* `loc`: An explicit `mlir.ir.Location` to use. Defaults to the location
|
||||
bound to the thread (i.e. `with Location.unknown():`) or an error if
|
||||
none is bound nor specified.
|
||||
* `ip`: An explicit `mlir.ir.InsertionPoint` to use. Default to the
|
||||
insertion point bound to the thread (i.e. `with InsertionPoint(...):`).
|
||||
|
||||
In addition, each `OpView` inherits a `build_generic` method which allows
|
||||
construction via a (nested in the case of variadic) sequence of `results` and
|
||||
`operands`. This can be used to get some default construction semantics for
|
||||
operations that are otherwise unsupported in Python, at the expense of having
|
||||
a very generic signature.
|
||||
operations that are otherwise unsupported in Python, at the expense of having a
|
||||
very generic signature.
|
||||
|
||||
#### Extending Generated Op Classes
|
||||
|
||||
|
|
@ -919,15 +920,15 @@ they don't feel the need to understand the subtlety. The `builtin` dialect
|
|||
provides some relatively simple examples.
|
||||
|
||||
As mentioned above, the build system generates Python sources like
|
||||
`_{DIALECT_NAMESPACE}_ops_gen.py` for each dialect with Python bindings. It
|
||||
is often desirable to to use these generated classes as a starting point for
|
||||
further customization, so an extension mechanism is provided to make this
|
||||
easy (you are always free to do ad-hoc patching in your `{DIALECT_NAMESPACE}.py`
|
||||
file but we prefer a more standard mechanism that is applied uniformly).
|
||||
`_{DIALECT_NAMESPACE}_ops_gen.py` for each dialect with Python bindings. It is
|
||||
often desirable to to use these generated classes as a starting point for
|
||||
further customization, so an extension mechanism is provided to make this easy
|
||||
(you are always free to do ad-hoc patching in your `{DIALECT_NAMESPACE}.py` file
|
||||
but we prefer a more standard mechanism that is applied uniformly).
|
||||
|
||||
To provide extensions, add a `_{DIALECT_NAMESPACE}_ops_ext.py` file to the
|
||||
`dialects` module (i.e. adjacent to your `{DIALECT_NAMESPACE}.py` top-level
|
||||
and the `*_ops_gen.py` file). Using the `builtin` dialect and `FuncOp` as an
|
||||
`dialects` module (i.e. adjacent to your `{DIALECT_NAMESPACE}.py` top-level and
|
||||
the `*_ops_gen.py` file). Using the `builtin` dialect and `FuncOp` as an
|
||||
example, the generated code will include an import like this:
|
||||
|
||||
```python
|
||||
|
|
@ -949,41 +950,41 @@ class FuncOp(_ods_ir.OpView):
|
|||
See the `_ods_common.py` `extend_opview_class` function for details of the
|
||||
mechanism. At a high level:
|
||||
|
||||
* If the extension module exists, locate an extension class for the op (in
|
||||
this example, `FuncOp`):
|
||||
* First by looking for an attribute with the exact name in the extension
|
||||
module.
|
||||
* Falling back to calling a `select_opview_mixin(parent_opview_cls)`
|
||||
function defined in the extension module.
|
||||
* If a mixin class is found, a new subclass is dynamically created that multiply
|
||||
inherits from `({_builtin_ops_ext.FuncOp}, _builtin_ops_gen.FuncOp)`.
|
||||
* If the extension module exists, locate an extension class for the op (in
|
||||
this example, `FuncOp`):
|
||||
* First by looking for an attribute with the exact name in the extension
|
||||
module.
|
||||
* Falling back to calling a `select_opview_mixin(parent_opview_cls)`
|
||||
function defined in the extension module.
|
||||
* If a mixin class is found, a new subclass is dynamically created that
|
||||
multiply inherits from `({_builtin_ops_ext.FuncOp},
|
||||
_builtin_ops_gen.FuncOp)`.
|
||||
|
||||
The mixin class should not inherit from anything (i.e. directly extends
|
||||
`object` only). The facility is typically used to define custom `__init__`
|
||||
methods, properties, instance methods and static methods. Due to the
|
||||
inheritance ordering, the mixin class can act as though it extends the
|
||||
generated `OpView` subclass in most contexts (i.e.
|
||||
`issubclass(_builtin_ops_ext.FuncOp, OpView)` will return `False` but usage
|
||||
generally allows you treat it as duck typed as an `OpView`).
|
||||
The mixin class should not inherit from anything (i.e. directly extends `object`
|
||||
only). The facility is typically used to define custom `__init__` methods,
|
||||
properties, instance methods and static methods. Due to the inheritance
|
||||
ordering, the mixin class can act as though it extends the generated `OpView`
|
||||
subclass in most contexts (i.e. `issubclass(_builtin_ops_ext.FuncOp, OpView)`
|
||||
will return `False` but usage generally allows you treat it as duck typed as an
|
||||
`OpView`).
|
||||
|
||||
There are a couple of recommendations, given how the class hierarchy is
|
||||
defined:
|
||||
There are a couple of recommendations, given how the class hierarchy is defined:
|
||||
|
||||
* For static methods that need to instantiate the actual "leaf" op (which
|
||||
is dynamically generated and would result in circular dependencies to try
|
||||
to reference by name), prefer to use `@classmethod` and the concrete
|
||||
subclass will be provided as your first `cls` argument. See
|
||||
`_builtin_ops_ext.FuncOp.from_py_func` as an example.
|
||||
* If seeking to replace the generated `__init__` method entirely, you may
|
||||
actually want to invoke the super-super-class `mlir.ir.OpView` constructor
|
||||
directly, as it takes an `mlir.ir.Operation`, which is likely what you
|
||||
are constructing (i.e. the generated `__init__` method likely adds more
|
||||
API constraints than you want to expose in a custom builder).
|
||||
* For static methods that need to instantiate the actual "leaf" op (which is
|
||||
dynamically generated and would result in circular dependencies to try to
|
||||
reference by name), prefer to use `@classmethod` and the concrete subclass
|
||||
will be provided as your first `cls` argument. See
|
||||
`_builtin_ops_ext.FuncOp.from_py_func` as an example.
|
||||
* If seeking to replace the generated `__init__` method entirely, you may
|
||||
actually want to invoke the super-super-class `mlir.ir.OpView` constructor
|
||||
directly, as it takes an `mlir.ir.Operation`, which is likely what you are
|
||||
constructing (i.e. the generated `__init__` method likely adds more API
|
||||
constraints than you want to expose in a custom builder).
|
||||
|
||||
A pattern that comes up frequently is wanting to provide a sugared `__init__`
|
||||
method which has optional or type-polymorphism/implicit conversions but to
|
||||
otherwise want to invoke the default op building logic. For such cases,
|
||||
it is recommended to use an idiom such as:
|
||||
otherwise want to invoke the default op building logic. For such cases, it is
|
||||
recommended to use an idiom such as:
|
||||
|
||||
```python
|
||||
def __init__(self, sugar, spice, *, loc=None, ip=None):
|
||||
|
|
|
|||
|
|
@ -7,34 +7,34 @@ programs.
|
|||
|
||||
## Requirements
|
||||
|
||||
In order to use BufferDeallocation on an arbitrary dialect, several
|
||||
control-flow interfaces have to be implemented when using custom operations.
|
||||
This is particularly important to understand the implicit control-flow
|
||||
dependencies between different parts of the input program. Without implementing
|
||||
the following interfaces, control-flow relations cannot be discovered properly
|
||||
and the resulting program can become invalid:
|
||||
In order to use BufferDeallocation on an arbitrary dialect, several control-flow
|
||||
interfaces have to be implemented when using custom operations. This is
|
||||
particularly important to understand the implicit control-flow dependencies
|
||||
between different parts of the input program. Without implementing the following
|
||||
interfaces, control-flow relations cannot be discovered properly and the
|
||||
resulting program can become invalid:
|
||||
|
||||
* Branch-like terminators should implement the `BranchOpInterface` to query and
|
||||
manipulate associated operands.
|
||||
* Operations involving structured control flow have to implement the
|
||||
`RegionBranchOpInterface` to model inter-region control flow.
|
||||
* Terminators yielding values to their parent operation (in particular in the
|
||||
scope of nested regions within `RegionBranchOpInterface`-based operations),
|
||||
should implement the `ReturnLike` trait to represent logical “value returns”.
|
||||
* Branch-like terminators should implement the `BranchOpInterface` to query
|
||||
and manipulate associated operands.
|
||||
* Operations involving structured control flow have to implement the
|
||||
`RegionBranchOpInterface` to model inter-region control flow.
|
||||
* Terminators yielding values to their parent operation (in particular in the
|
||||
scope of nested regions within `RegionBranchOpInterface`-based operations),
|
||||
should implement the `ReturnLike` trait to represent logical “value
|
||||
returns”.
|
||||
|
||||
Example dialects that are fully compatible are the “std” and “scf” dialects
|
||||
with respect to all implemented interfaces.
|
||||
Example dialects that are fully compatible are the “std” and “scf” dialects with
|
||||
respect to all implemented interfaces.
|
||||
|
||||
During Bufferization, we convert immutable value types (tensors) to mutable
|
||||
types (memref). This conversion is done in several steps and in all of these
|
||||
steps the IR has to fulfill SSA like properties. The usage of memref has
|
||||
to be in the following consecutive order: allocation, write-buffer, read-
|
||||
buffer.
|
||||
In this case, there are only buffer reads allowed after the initial full
|
||||
buffer write is done. In particular, there must be no partial write to a
|
||||
buffer after the initial write has been finished. However, partial writes in
|
||||
the initializing is allowed (fill buffer step by step in a loop e.g.). This
|
||||
means, all buffer writes needs to dominate all buffer reads.
|
||||
steps the IR has to fulfill SSA like properties. The usage of memref has to be
|
||||
in the following consecutive order: allocation, write-buffer, read- buffer. In
|
||||
this case, there are only buffer reads allowed after the initial full buffer
|
||||
write is done. In particular, there must be no partial write to a buffer after
|
||||
the initial write has been finished. However, partial writes in the initializing
|
||||
is allowed (fill buffer step by step in a loop e.g.). This means, all buffer
|
||||
writes needs to dominate all buffer reads.
|
||||
|
||||
Example for breaking the invariant:
|
||||
|
||||
|
|
@ -65,15 +65,15 @@ Furthermore, these ops need to apply the effect `MemoryEffects::Allocate` to a
|
|||
particular result value while not using the resource
|
||||
`SideEffects::AutomaticAllocationScopeResource` (since it is currently reserved
|
||||
for allocations, like `Alloca` that will be automatically deallocated by a
|
||||
parent scope). Allocations that have not been detected in this phase will not
|
||||
be tracked internally, and thus, not deallocated automatically. However,
|
||||
BufferDeallocation is fully compatible with “hybrid” setups in which tracked
|
||||
and untracked allocations are mixed:
|
||||
parent scope). Allocations that have not been detected in this phase will not be
|
||||
tracked internally, and thus, not deallocated automatically. However,
|
||||
BufferDeallocation is fully compatible with “hybrid” setups in which tracked and
|
||||
untracked allocations are mixed:
|
||||
|
||||
```mlir
|
||||
func @mixedAllocation(%arg0: i1) {
|
||||
%0 = alloca() : memref<2xf32> // aliases: %2
|
||||
%1 = alloc() : memref<2xf32> // aliases: %2
|
||||
%0 = memref.alloca() : memref<2xf32> // aliases: %2
|
||||
%1 = memref.alloc() : memref<2xf32> // aliases: %2
|
||||
cond_br %arg0, ^bb1, ^bb2
|
||||
^bb1:
|
||||
use(%0)
|
||||
|
|
@ -98,29 +98,29 @@ The PromoteBuffersToStack-pass converts AllocOps to AllocaOps, if possible. In
|
|||
some cases, it can be useful to use such stack-based buffers instead of
|
||||
heap-based buffers. The conversion is restricted to several constraints like:
|
||||
|
||||
* Control flow
|
||||
* Buffer Size
|
||||
* Dynamic Size
|
||||
* Control flow
|
||||
* Buffer Size
|
||||
* Dynamic Size
|
||||
|
||||
If a buffer is leaving a block, we are not allowed to convert it into an
|
||||
alloca. If the size of the buffer is large, we could convert it, but regarding
|
||||
stack overflow, it makes sense to limit the size of these buffers and only
|
||||
convert small ones. The size can be set via a pass option. The current default
|
||||
value is 1KB. Furthermore, we can not convert buffers with dynamic size, since
|
||||
the dimension is not known a priori.
|
||||
If a buffer is leaving a block, we are not allowed to convert it into an alloca.
|
||||
If the size of the buffer is large, we could convert it, but regarding stack
|
||||
overflow, it makes sense to limit the size of these buffers and only convert
|
||||
small ones. The size can be set via a pass option. The current default value is
|
||||
1KB. Furthermore, we can not convert buffers with dynamic size, since the
|
||||
dimension is not known a priori.
|
||||
|
||||
## Movement and Placement of Allocations
|
||||
|
||||
Using the buffer hoisting pass, all buffer allocations are moved as far upwards
|
||||
as possible in order to group them and make upcoming optimizations easier by
|
||||
limiting the search space. Such a movement is shown in the following graphs.
|
||||
In addition, we are able to statically free an alloc, if we move it into a
|
||||
dominator of all of its uses. This simplifies further optimizations (e.g.
|
||||
buffer fusion) in the future. However, movement of allocations is limited by
|
||||
external data dependencies (in particular in the case of allocations of
|
||||
dynamically shaped types). Furthermore, allocations can be moved out of nested
|
||||
regions, if necessary. In order to move allocations to valid locations with
|
||||
respect to their uses only, we leverage Liveness information.
|
||||
limiting the search space. Such a movement is shown in the following graphs. In
|
||||
addition, we are able to statically free an alloc, if we move it into a
|
||||
dominator of all of its uses. This simplifies further optimizations (e.g. buffer
|
||||
fusion) in the future. However, movement of allocations is limited by external
|
||||
data dependencies (in particular in the case of allocations of dynamically
|
||||
shaped types). Furthermore, allocations can be moved out of nested regions, if
|
||||
necessary. In order to move allocations to valid locations with respect to their
|
||||
uses only, we leverage Liveness information.
|
||||
|
||||
The following code snippets shows a conditional branch before running the
|
||||
BufferHoisting pass:
|
||||
|
|
@ -165,8 +165,8 @@ func @condBranch(%arg0: i1, %arg1: memref<2xf32>, %arg2: memref<2xf32>) {
|
|||
The alloc is moved from bb2 to the beginning and it is passed as an argument to
|
||||
bb3.
|
||||
|
||||
The following example demonstrates an allocation using dynamically shaped
|
||||
types. Due to the data dependency of the allocation to %0, we cannot move the
|
||||
The following example demonstrates an allocation using dynamically shaped types.
|
||||
Due to the data dependency of the allocation to %0, we cannot move the
|
||||
allocation out of bb2 in this case:
|
||||
|
||||
```mlir
|
||||
|
|
@ -216,16 +216,16 @@ func @branch(%arg0: i1) {
|
|||
```
|
||||
|
||||
The first alloc can be safely freed after the live range of its post-dominator
|
||||
block (bb3). The alloc in bb1 has an alias %2 in bb3 that also keeps this
|
||||
buffer alive until the end of bb3. Since we cannot determine the actual
|
||||
branches that will be taken at runtime, we have to ensure that all buffers are
|
||||
freed correctly in bb3 regardless of the branches we will take to reach the
|
||||
exit block. This makes it necessary to introduce a copy for %2, which allows us
|
||||
to free %alloc0 in bb0 and %alloc1 in bb1. Afterwards, we can continue
|
||||
processing all aliases of %2 (none in this case) and we can safely free %2 at
|
||||
the end of the sample program. This sample demonstrates that not all
|
||||
allocations can be safely freed in their associated post-dominator blocks.
|
||||
Instead, we have to pay attention to all of their aliases.
|
||||
block (bb3). The alloc in bb1 has an alias %2 in bb3 that also keeps this buffer
|
||||
alive until the end of bb3. Since we cannot determine the actual branches that
|
||||
will be taken at runtime, we have to ensure that all buffers are freed correctly
|
||||
in bb3 regardless of the branches we will take to reach the exit block. This
|
||||
makes it necessary to introduce a copy for %2, which allows us to free %alloc0
|
||||
in bb0 and %alloc1 in bb1. Afterwards, we can continue processing all aliases of
|
||||
%2 (none in this case) and we can safely free %2 at the end of the sample
|
||||
program. This sample demonstrates that not all allocations can be safely freed
|
||||
in their associated post-dominator blocks. Instead, we have to pay attention to
|
||||
all of their aliases.
|
||||
|
||||
Applying the BufferDeallocation pass to the program above yields the following
|
||||
result:
|
||||
|
|
@ -253,8 +253,7 @@ func @branch(%arg0: i1) {
|
|||
|
||||
Note that a temporary buffer for %2 was introduced to free all allocations
|
||||
properly. Note further that the unnecessary allocation of %3 can be easily
|
||||
removed using one of the post-pass transformations or the canonicalization
|
||||
pass.
|
||||
removed using one of the post-pass transformations or the canonicalization pass.
|
||||
|
||||
The presented example also works with dynamically shaped types.
|
||||
|
||||
|
|
@ -262,9 +261,9 @@ BufferDeallocation performs a fix-point iteration taking all aliases of all
|
|||
tracked allocations into account. We initialize the general iteration process
|
||||
using all tracked allocations and their associated aliases. As soon as we
|
||||
encounter an alias that is not properly dominated by our allocation, we mark
|
||||
this alias as _critical_ (needs to be freed and tracked by the internal
|
||||
fix-point iteration). The following sample demonstrates the presence of
|
||||
critical and non-critical aliases:
|
||||
this alias as *critical* (needs to be freed and tracked by the internal
|
||||
fix-point iteration). The following sample demonstrates the presence of critical
|
||||
and non-critical aliases:
|
||||
|
||||

|
||||
|
||||
|
|
@ -345,8 +344,8 @@ alias can be either a block argument or another value that is returned by an
|
|||
operation. Copies for block arguments are handled by analyzing all predecessor
|
||||
blocks. This is primarily done by querying the `BranchOpInterface` of the
|
||||
associated branch terminators that can jump to the current block. Consider the
|
||||
following example which involves a simple branch and the critical block
|
||||
argument %2:
|
||||
following example which involves a simple branch and the critical block argument
|
||||
%2:
|
||||
|
||||
```mlir
|
||||
custom.br ^bb1(..., %0, : ...)
|
||||
|
|
@ -360,24 +359,24 @@ argument %2:
|
|||
The `BranchOpInterface` allows us to determine the actual values that will be
|
||||
passed to block bb1 and its argument %2 by analyzing its predecessor blocks.
|
||||
Once we have resolved the values %0 and %1 (that are associated with %2 in this
|
||||
sample), we can introduce a temporary buffer and clone its contents into the
|
||||
new buffer. Afterwards, we rewire the branch operands to use the newly
|
||||
allocated buffer instead. However, blocks can have implicitly defined
|
||||
predecessors by parent ops that implement the `RegionBranchOpInterface`. This
|
||||
can be the case if this block argument belongs to the entry block of a region.
|
||||
In this setting, we have to identify all predecessor regions defined by the
|
||||
parent operation. For every region, we need to get all terminator operations
|
||||
implementing the `ReturnLike` trait, indicating that they can branch to our
|
||||
current block. Finally, we can use a similar functionality as described above
|
||||
to add the temporary copy. This time, we can modify the terminator operands
|
||||
directly without touching a high-level interface.
|
||||
sample), we can introduce a temporary buffer and clone its contents into the new
|
||||
buffer. Afterwards, we rewire the branch operands to use the newly allocated
|
||||
buffer instead. However, blocks can have implicitly defined predecessors by
|
||||
parent ops that implement the `RegionBranchOpInterface`. This can be the case if
|
||||
this block argument belongs to the entry block of a region. In this setting, we
|
||||
have to identify all predecessor regions defined by the parent operation. For
|
||||
every region, we need to get all terminator operations implementing the
|
||||
`ReturnLike` trait, indicating that they can branch to our current block.
|
||||
Finally, we can use a similar functionality as described above to add the
|
||||
temporary copy. This time, we can modify the terminator operands directly
|
||||
without touching a high-level interface.
|
||||
|
||||
Consider the following inner-region control-flow sample that uses an imaginary
|
||||
“custom.region_if” operation. It either executes the “then” or “else” region
|
||||
and always continues to the “join” region. The “custom.region_if_yield”
|
||||
operation returns a result to the parent operation. This sample demonstrates
|
||||
the use of the `RegionBranchOpInterface` to determine predecessors in order to
|
||||
infer the high-level control flow:
|
||||
“custom.region_if” operation. It either executes the “then” or “else” region and
|
||||
always continues to the “join” region. The “custom.region_if_yield” operation
|
||||
returns a result to the parent operation. This sample demonstrates the use of
|
||||
the `RegionBranchOpInterface` to determine predecessors in order to infer the
|
||||
high-level control flow:
|
||||
|
||||
```mlir
|
||||
func @inner_region_control_flow(
|
||||
|
|
@ -405,7 +404,7 @@ operation to determine the value of %2 at runtime which creates an alias:
|
|||
|
||||
```mlir
|
||||
func @nested_region_control_flow(%arg0 : index, %arg1 : index) -> memref<?x?xf32> {
|
||||
%0 = cmpi "eq", %arg0, %arg1 : index
|
||||
%0 = arith.cmpi "eq", %arg0, %arg1 : index
|
||||
%1 = memref.alloc(%arg0, %arg0) : memref<?x?xf32>
|
||||
%2 = scf.if %0 -> (memref<?x?xf32>) {
|
||||
scf.yield %1 : memref<?x?xf32> // %2 will be an alias of %1
|
||||
|
|
@ -420,13 +419,13 @@ func @nested_region_control_flow(%arg0 : index, %arg1 : index) -> memref<?x?xf32
|
|||
```
|
||||
|
||||
In this example, a dealloc is inserted to release the buffer within the else
|
||||
block since it cannot be accessed by the remainder of the program. Accessing
|
||||
the `RegionBranchOpInterface`, allows us to infer that %2 is a non-critical
|
||||
alias of %1 which does not need to be tracked.
|
||||
block since it cannot be accessed by the remainder of the program. Accessing the
|
||||
`RegionBranchOpInterface`, allows us to infer that %2 is a non-critical alias of
|
||||
%1 which does not need to be tracked.
|
||||
|
||||
```mlir
|
||||
func @nested_region_control_flow(%arg0: index, %arg1: index) -> memref<?x?xf32> {
|
||||
%0 = cmpi "eq", %arg0, %arg1 : index
|
||||
%0 = arith.cmpi "eq", %arg0, %arg1 : index
|
||||
%1 = memref.alloc(%arg0, %arg0) : memref<?x?xf32>
|
||||
%2 = scf.if %0 -> (memref<?x?xf32>) {
|
||||
scf.yield %1 : memref<?x?xf32>
|
||||
|
|
@ -442,9 +441,9 @@ func @nested_region_control_flow(%arg0: index, %arg1: index) -> memref<?x?xf32>
|
|||
|
||||
Analogous to the previous case, we have to detect all terminator operations in
|
||||
all attached regions of “scf.if” that provides a value to its parent operation
|
||||
(in this sample via scf.yield). Querying the `RegionBranchOpInterface` allows
|
||||
us to determine the regions that “return” a result to their parent operation.
|
||||
Like before, we have to update all `ReturnLike` terminators as described above.
|
||||
(in this sample via scf.yield). Querying the `RegionBranchOpInterface` allows us
|
||||
to determine the regions that “return” a result to their parent operation. Like
|
||||
before, we have to update all `ReturnLike` terminators as described above.
|
||||
Reconsider a slightly adapted version of the “custom.region_if” example from
|
||||
above that uses a nested allocation:
|
||||
|
||||
|
|
@ -468,8 +467,8 @@ func @inner_region_control_flow_div(
|
|||
|
||||
Since the allocation %2 happens in a divergent branch and cannot be safely
|
||||
deallocated in a post-dominator, %arg4 will be considered a critical alias.
|
||||
Furthermore, %arg4 is returned to its parent operation and has an alias %1.
|
||||
This causes BufferDeallocation to introduce additional copies:
|
||||
Furthermore, %arg4 is returned to its parent operation and has an alias %1. This
|
||||
causes BufferDeallocation to introduce additional copies:
|
||||
|
||||
```mlir
|
||||
func @inner_region_control_flow_div(
|
||||
|
|
@ -502,9 +501,9 @@ allocated memory and avoid memory leaks. The deallocation needs to take place
|
|||
after the last use of the given value. The position can be determined by
|
||||
calculating the common post-dominator of all values using their remaining
|
||||
non-critical aliases. A special-case is the presence of back edges: since such
|
||||
edges can cause memory leaks when a newly allocated buffer flows back to
|
||||
another part of the program. In these cases, we need to free the associated
|
||||
buffer instances from the previous iteration by inserting additional deallocs.
|
||||
edges can cause memory leaks when a newly allocated buffer flows back to another
|
||||
part of the program. In these cases, we need to free the associated buffer
|
||||
instances from the previous iteration by inserting additional deallocs.
|
||||
|
||||
Consider the following “scf.for” use case containing a nested structured
|
||||
control-flow if:
|
||||
|
|
@ -518,7 +517,7 @@ func @loop_nested_if(
|
|||
%res: memref<2xf32>) {
|
||||
%0 = scf.for %i = %lb to %ub step %step
|
||||
iter_args(%iterBuf = %buf) -> memref<2xf32> {
|
||||
%1 = cmpi "eq", %i, %ub : index
|
||||
%1 = arith.cmpi "eq", %i, %ub : index
|
||||
%2 = scf.if %1 -> (memref<2xf32>) {
|
||||
%3 = memref.alloc() : memref<2xf32> // makes %2 a critical alias due to a
|
||||
// divergent allocation
|
||||
|
|
@ -534,18 +533,18 @@ func @loop_nested_if(
|
|||
}
|
||||
```
|
||||
|
||||
In this example, the _then_ branch of the nested “scf.if” operation returns a
|
||||
In this example, the *then* branch of the nested “scf.if” operation returns a
|
||||
newly allocated buffer.
|
||||
|
||||
Since this allocation happens in the scope of a divergent branch, %2 becomes a
|
||||
critical alias that needs to be handled. As before, we have to insert
|
||||
additional copies to eliminate this alias using copies of %3 and %iterBuf. This
|
||||
guarantees that %2 will be a newly allocated buffer that is returned in each
|
||||
iteration. However, “returning” %2 to its alias %iterBuf turns %iterBuf into a
|
||||
critical alias as well. In other words, we have to create a copy of %2 to pass
|
||||
it to %iterBuf. Since this jump represents a back edge, and %2 will always be a
|
||||
new buffer, we have to free the buffer from the previous iteration to avoid
|
||||
memory leaks:
|
||||
critical alias that needs to be handled. As before, we have to insert additional
|
||||
copies to eliminate this alias using copies of %3 and %iterBuf. This guarantees
|
||||
that %2 will be a newly allocated buffer that is returned in each iteration.
|
||||
However, “returning” %2 to its alias %iterBuf turns %iterBuf into a critical
|
||||
alias as well. In other words, we have to create a copy of %2 to pass it to
|
||||
%iterBuf. Since this jump represents a back edge, and %2 will always be a new
|
||||
buffer, we have to free the buffer from the previous iteration to avoid memory
|
||||
leaks:
|
||||
|
||||
```mlir
|
||||
func @loop_nested_if(
|
||||
|
|
@ -557,7 +556,7 @@ func @loop_nested_if(
|
|||
%4 = memref.clone %buf : (memref<2xf32>) -> (memref<2xf32>)
|
||||
%0 = scf.for %i = %lb to %ub step %step
|
||||
iter_args(%iterBuf = %4) -> memref<2xf32> {
|
||||
%1 = cmpi "eq", %i, %ub : index
|
||||
%1 = arith.cmpi "eq", %i, %ub : index
|
||||
%2 = scf.if %1 -> (memref<2xf32>) {
|
||||
%3 = memref.alloc() : memref<2xf32> // makes %2 a critical alias
|
||||
use(%3)
|
||||
|
|
@ -612,9 +611,8 @@ During placement of clones it may happen, that unnecessary clones are inserted.
|
|||
If these clones appear with their corresponding dealloc operation within the
|
||||
same block, we can use the canonicalizer to remove these unnecessary operations.
|
||||
Note, that this step needs to take place after the insertion of clones and
|
||||
deallocs in the buffer deallocation step. The canonicalization inludes both,
|
||||
the newly created target value from the clone operation and the source
|
||||
operation.
|
||||
deallocs in the buffer deallocation step. The canonicalization inludes both, the
|
||||
newly created target value from the clone operation and the source operation.
|
||||
|
||||
## Canonicalization of the Source Buffer of the Clone Operation
|
||||
|
||||
|
|
@ -653,9 +651,9 @@ its source. The unused deallocation operation that is defined for this clone
|
|||
operation is also removed.
|
||||
|
||||
Consider the following example where a generic test operation writes the result
|
||||
to %temp and then copies %temp to %result. However, these two operations
|
||||
can be merged into a single step. Canonicalization removes the clone operation
|
||||
and %temp, and replaces the uses of %temp with %result:
|
||||
to %temp and then copies %temp to %result. However, these two operations can be
|
||||
merged into a single step. Canonicalization removes the clone operation and
|
||||
%temp, and replaces the uses of %temp with %result:
|
||||
|
||||
```mlir
|
||||
func @reuseTarget(%arg0: memref<2xf32>, %result: memref<2xf32>){
|
||||
|
|
@ -666,7 +664,7 @@ func @reuseTarget(%arg0: memref<2xf32>, %result: memref<2xf32>){
|
|||
indexing_maps = [#map0, #map0],
|
||||
iterator_types = ["parallel"]} %arg0, %temp {
|
||||
^bb0(%gen2_arg0: f32, %gen2_arg1: f32):
|
||||
%tmp2 = exp %gen2_arg0 : f32
|
||||
%tmp2 = math.exp %gen2_arg0 : f32
|
||||
test.yield %tmp2 : f32
|
||||
}: memref<2xf32>, memref<2xf32>
|
||||
%result = memref.clone %temp : (memref<2xf32>) -> (memref<2xf32>)
|
||||
|
|
@ -685,7 +683,7 @@ func @reuseTarget(%arg0: memref<2xf32>, %result: memref<2xf32>){
|
|||
indexing_maps = [#map0, #map0],
|
||||
iterator_types = ["parallel"]} %arg0, %result {
|
||||
^bb0(%gen2_arg0: f32, %gen2_arg1: f32):
|
||||
%tmp2 = exp %gen2_arg0 : f32
|
||||
%tmp2 = math.exp %gen2_arg0 : f32
|
||||
test.yield %tmp2 : f32
|
||||
}: memref<2xf32>, memref<2xf32>
|
||||
return
|
||||
|
|
@ -697,6 +695,6 @@ func @reuseTarget(%arg0: memref<2xf32>, %result: memref<2xf32>){
|
|||
BufferDeallocation introduces additional clones from “memref” dialect
|
||||
(“memref.clone”). Analogous, all deallocations use the “memref” dialect-free
|
||||
operation “memref.dealloc”. The actual copy process is realized using
|
||||
“test.copy”. Furthermore, buffers are essentially immutable after their
|
||||
creation in a block. Another limitations are known in the case using
|
||||
unstructered control flow.
|
||||
“test.copy”. Furthermore, buffers are essentially immutable after their creation
|
||||
in a block. Another limitations are known in the case using unstructered control
|
||||
flow.
|
||||
|
|
|
|||
|
|
@ -6,8 +6,8 @@
|
|||
|
||||
Bufferization in MLIR is the process of converting the `tensor` type to the
|
||||
`memref` type. MLIR provides a composable system that allows dialects to
|
||||
systematically bufferize a program. This system is a simple application
|
||||
of MLIR's [dialect conversion](DialectConversion.md) infrastructure. The bulk of
|
||||
systematically bufferize a program. This system is a simple application of
|
||||
MLIR's [dialect conversion](DialectConversion.md) infrastructure. The bulk of
|
||||
the code related to bufferization is a set of ordinary `ConversionPattern`'s
|
||||
that dialect authors write for converting ops that operate on `tensor`'s to ops
|
||||
that operate on `memref`'s. A set of conventions and best practices are followed
|
||||
|
|
@ -34,11 +34,12 @@ nor does it do anything particularly intelligent with the placement of buffers
|
|||
w.r.t. control flow. Thus, a realistic compilation pipeline will usually consist
|
||||
of:
|
||||
|
||||
1. Bufferization
|
||||
1. Buffer optimizations such as `buffer-hoisting`, `buffer-loop-hoisting`, and
|
||||
`promote-buffers-to-stack`, which do optimizations that are only exposed
|
||||
after bufferization.
|
||||
1. Finally, running the [buffer deallocation](BufferDeallocationInternals.md) pass.
|
||||
1. Bufferization
|
||||
1. Buffer optimizations such as `buffer-hoisting`, `buffer-loop-hoisting`, and
|
||||
`promote-buffers-to-stack`, which do optimizations that are only exposed
|
||||
after bufferization.
|
||||
1. Finally, running the [buffer deallocation](BufferDeallocationInternals.md)
|
||||
pass.
|
||||
|
||||
After buffer deallocation has been completed, the program will be quite
|
||||
difficult to transform due to the presence of the deallocation ops. Thus, other
|
||||
|
|
@ -46,8 +47,8 @@ optimizations such as linalg fusion on memrefs should be done before that stage.
|
|||
|
||||
## General structure of the bufferization process
|
||||
|
||||
Bufferization consists of running multiple _partial_ bufferization passes,
|
||||
followed by one _finalizing_ bufferization pass.
|
||||
Bufferization consists of running multiple *partial* bufferization passes,
|
||||
followed by one *finalizing* bufferization pass.
|
||||
|
||||
There is typically one partial bufferization pass per dialect (though other
|
||||
subdivisions are possible). For example, for a dialect `X` there will typically
|
||||
|
|
@ -56,7 +57,7 @@ By running pass `X-bufferize` for each dialect `X` in the program, all the ops
|
|||
in the program are incrementally bufferized.
|
||||
|
||||
Partial bufferization passes create programs where only some ops have been
|
||||
bufferized. These passes will create _materializations_ (also sometimes called
|
||||
bufferized. These passes will create *materializations* (also sometimes called
|
||||
"casts") that convert between the `tensor` and `memref` type, which allows
|
||||
bridging between ops that have been bufferized and ops that have not yet been
|
||||
bufferized.
|
||||
|
|
@ -180,8 +181,8 @@ struct TensorBufferizePass : public TensorBufferizeBase<TensorBufferizePass> {
|
|||
```
|
||||
|
||||
The pass has all the hallmarks of a dialect conversion pass that does type
|
||||
conversions: a `TypeConverter`, a `RewritePatternSet`, and a
|
||||
`ConversionTarget`, and a call to `applyPartialConversion`. Note that a function
|
||||
conversions: a `TypeConverter`, a `RewritePatternSet`, and a `ConversionTarget`,
|
||||
and a call to `applyPartialConversion`. Note that a function
|
||||
`populateTensorBufferizePatterns` is separated, so that power users can use the
|
||||
patterns independently, if necessary (such as to combine multiple sets of
|
||||
conversion patterns into a single conversion call, for performance).
|
||||
|
|
@ -190,55 +191,59 @@ One convenient utility provided by the MLIR bufferization infrastructure is the
|
|||
`BufferizeTypeConverter`, which comes pre-loaded with the necessary conversions
|
||||
and materializations between `tensor` and `memref`.
|
||||
|
||||
In this case, the `MemRefOpsDialect` is marked as legal, so the `tensor_load`
|
||||
and `buffer_cast` ops, which are inserted automatically by the dialect
|
||||
conversion framework as materializations, are legal. There is a helper
|
||||
`populateBufferizeMaterializationLegality`
|
||||
In this case, the `MemRefOpsDialect` is marked as legal, so the
|
||||
`memref.tensor_load` and `memref.buffer_cast` ops, which are inserted
|
||||
automatically by the dialect conversion framework as materializations, are
|
||||
legal. There is a helper `populateBufferizeMaterializationLegality`
|
||||
([code](https://github.com/llvm/llvm-project/blob/a0b65a7bcd6065688189b3d678c42ed6af9603db/mlir/include/mlir/Transforms/Bufferize.h#L53))
|
||||
which helps with this in general.
|
||||
|
||||
### Other partial bufferization examples
|
||||
|
||||
- `linalg-bufferize`
|
||||
([code](https://github.com/llvm/llvm-project/blob/bc8acf2ce8ad6e8c9b1d97b2e02d3f4ad26e1d9d/mlir/lib/Dialect/Linalg/Transforms/Bufferize.cpp#L1),
|
||||
[test](https://github.com/llvm/llvm-project/blob/bc8acf2ce8ad6e8c9b1d97b2e02d3f4ad26e1d9d/mlir/test/Dialect/Linalg/bufferize.mlir#L1))
|
||||
- `linalg-bufferize`
|
||||
([code](https://github.com/llvm/llvm-project/blob/bc8acf2ce8ad6e8c9b1d97b2e02d3f4ad26e1d9d/mlir/lib/Dialect/Linalg/Transforms/Bufferize.cpp#L1),
|
||||
[test](https://github.com/llvm/llvm-project/blob/bc8acf2ce8ad6e8c9b1d97b2e02d3f4ad26e1d9d/mlir/test/Dialect/Linalg/bufferize.mlir#L1))
|
||||
|
||||
- Bufferizes the `linalg` dialect.
|
||||
- This is an example of how to simultaneously bufferize all the ops that
|
||||
satisfy a certain OpInterface with a single pattern. Specifically,
|
||||
`BufferizeAnyLinalgOp`
|
||||
([code](https://github.com/llvm/llvm-project/blob/daaaed6bb89044ac58a23f1bb1ccdd12342a5a58/mlir/lib/Dialect/Linalg/Transforms/Bufferize.cpp#L170))
|
||||
bufferizes any ops that implements the `LinalgOp` interface.
|
||||
- Bufferizes the `linalg` dialect.
|
||||
- This is an example of how to simultaneously bufferize all the ops that
|
||||
satisfy a certain OpInterface with a single pattern. Specifically,
|
||||
`BufferizeAnyLinalgOp`
|
||||
([code](https://github.com/llvm/llvm-project/blob/daaaed6bb89044ac58a23f1bb1ccdd12342a5a58/mlir/lib/Dialect/Linalg/Transforms/Bufferize.cpp#L170))
|
||||
bufferizes any ops that implements the `LinalgOp` interface.
|
||||
|
||||
- `scf-bufferize`
|
||||
([code](https://github.com/llvm/llvm-project/blob/bc8acf2ce8ad6e8c9b1d97b2e02d3f4ad26e1d9d/mlir/lib/Dialect/SCF/Transforms/Bufferize.cpp#L1),
|
||||
[test](https://github.com/llvm/llvm-project/blob/bc8acf2ce8ad6e8c9b1d97b2e02d3f4ad26e1d9d/mlir/test/Dialect/SCF/bufferize.mlir#L1))
|
||||
- `scf-bufferize`
|
||||
([code](https://github.com/llvm/llvm-project/blob/bc8acf2ce8ad6e8c9b1d97b2e02d3f4ad26e1d9d/mlir/lib/Dialect/SCF/Transforms/Bufferize.cpp#L1),
|
||||
[test](https://github.com/llvm/llvm-project/blob/bc8acf2ce8ad6e8c9b1d97b2e02d3f4ad26e1d9d/mlir/test/Dialect/SCF/bufferize.mlir#L1))
|
||||
|
||||
- Bufferizes ops from the `scf` dialect.
|
||||
- This is an example of how to bufferize ops that implement
|
||||
`RegionBranchOpInterface` (that is, they use regions to represent control
|
||||
flow).
|
||||
- The bulk of the work is done by
|
||||
`lib/Dialect/SCF/Transforms/StructuralTypeConversions.cpp`
|
||||
([code](https://github.com/llvm/llvm-project/blob/daaaed6bb89044ac58a23f1bb1ccdd12342a5a58/mlir/lib/Dialect/SCF/Transforms/StructuralTypeConversions.cpp#L1)),
|
||||
which is well-commented and covers how to correctly convert ops that contain
|
||||
regions.
|
||||
- Bufferizes ops from the `scf` dialect.
|
||||
- This is an example of how to bufferize ops that implement
|
||||
`RegionBranchOpInterface` (that is, they use regions to represent
|
||||
control flow).
|
||||
- The bulk of the work is done by
|
||||
`lib/Dialect/SCF/Transforms/StructuralTypeConversions.cpp`
|
||||
([code](https://github.com/llvm/llvm-project/blob/daaaed6bb89044ac58a23f1bb1ccdd12342a5a58/mlir/lib/Dialect/SCF/Transforms/StructuralTypeConversions.cpp#L1)),
|
||||
which is well-commented and covers how to correctly convert ops that
|
||||
contain regions.
|
||||
|
||||
- `func-bufferize`
|
||||
([code](https://github.com/llvm/llvm-project/blob/bc8acf2ce8ad6e8c9b1d97b2e02d3f4ad26e1d9d/mlir/lib/Dialect/StandardOps/Transforms/FuncBufferize.cpp#L1),
|
||||
[test](https://github.com/llvm/llvm-project/blob/bc8acf2ce8ad6e8c9b1d97b2e02d3f4ad26e1d9d/mlir/test/Dialect/Standard/func-bufferize.mlir#L1))
|
||||
- `func-bufferize`
|
||||
([code](https://github.com/llvm/llvm-project/blob/bc8acf2ce8ad6e8c9b1d97b2e02d3f4ad26e1d9d/mlir/lib/Dialect/StandardOps/Transforms/FuncBufferize.cpp#L1),
|
||||
[test](https://github.com/llvm/llvm-project/blob/bc8acf2ce8ad6e8c9b1d97b2e02d3f4ad26e1d9d/mlir/test/Dialect/Standard/func-bufferize.mlir#L1))
|
||||
|
||||
- Bufferizes `func`, `call`, and `BranchOpInterface` ops.
|
||||
- This is an example of how to bufferize ops that have multi-block regions.
|
||||
- This is an example of a pass that is not split along dialect subdivisions.
|
||||
- Bufferizes `func`, `call`, and `BranchOpInterface` ops.
|
||||
- This is an example of how to bufferize ops that have multi-block
|
||||
regions.
|
||||
- This is an example of a pass that is not split along dialect
|
||||
subdivisions.
|
||||
|
||||
- `tensor-constant-bufferize`
|
||||
([code](https://github.com/llvm/llvm-project/blob/bc8acf2ce8ad6e8c9b1d97b2e02d3f4ad26e1d9d/mlir/lib/Dialect/StandardOps/Transforms/TensorConstantBufferize.cpp#L1),
|
||||
[test](https://github.com/llvm/llvm-project/blob/bc8acf2ce8ad6e8c9b1d97b2e02d3f4ad26e1d9d/mlir/test/Dialect/Standard/tensor-constant-bufferize.mlir#L1))
|
||||
- Bufferizes only `std.constant` ops of `tensor` type.
|
||||
- This is an example of setting up the legality so that only a subset of
|
||||
`std.constant` ops get bufferized.
|
||||
- This is an example of a pass that is not split along dialect subdivisions.
|
||||
- `tensor-constant-bufferize`
|
||||
([code](https://github.com/llvm/llvm-project/blob/bc8acf2ce8ad6e8c9b1d97b2e02d3f4ad26e1d9d/mlir/lib/Dialect/StandardOps/Transforms/TensorConstantBufferize.cpp#L1),
|
||||
[test](https://github.com/llvm/llvm-project/blob/bc8acf2ce8ad6e8c9b1d97b2e02d3f4ad26e1d9d/mlir/test/Dialect/Standard/tensor-constant-bufferize.mlir#L1))
|
||||
|
||||
- Bufferizes only `arith.constant` ops of `tensor` type.
|
||||
- This is an example of setting up the legality so that only a subset of
|
||||
`std.constant` ops get bufferized.
|
||||
- This is an example of a pass that is not split along dialect
|
||||
subdivisions.
|
||||
|
||||
## How to write a finalizing bufferization pass
|
||||
|
||||
|
|
@ -246,10 +251,10 @@ The contract of a finalizing bufferization pass is that all tensors are gone
|
|||
from the program.
|
||||
|
||||
The easiest way to write a finalizing bufferize pass is to not write one at all!
|
||||
MLIR provides a pass `finalizing-bufferize` which eliminates the `tensor_load` /
|
||||
`buffer_cast` materialization ops inserted by partial bufferization passes
|
||||
and emits an error if that is not sufficient to remove all tensors from the
|
||||
program.
|
||||
MLIR provides a pass `finalizing-bufferize` which eliminates the
|
||||
`memref.tensor_load` / `memref.buffer_cast` materialization ops inserted by
|
||||
partial bufferization passes and emits an error if that is not sufficient to
|
||||
remove all tensors from the program.
|
||||
|
||||
This pass is sufficient when partial bufferization passes have bufferized all
|
||||
the ops in the program, leaving behind only the materializations. When possible,
|
||||
|
|
@ -260,18 +265,17 @@ error, and the IR seen by `finalizing-bufferize` will only contain only one
|
|||
unbufferized op.
|
||||
|
||||
However, before the current bufferization infrastructure was put in place,
|
||||
bufferization could only be done as a single finalizing bufferization
|
||||
mega-pass that used the `populate*BufferizePatterns` functions from multiple
|
||||
dialects to simultaneously bufferize everything at once. Thus, one might see
|
||||
code in downstream projects structured this way. This structure is not
|
||||
recommended in new code. A helper,
|
||||
`populateEliminateBufferizeMaterializationsPatterns`
|
||||
bufferization could only be done as a single finalizing bufferization mega-pass
|
||||
that used the `populate*BufferizePatterns` functions from multiple dialects to
|
||||
simultaneously bufferize everything at once. Thus, one might see code in
|
||||
downstream projects structured this way. This structure is not recommended in
|
||||
new code. A helper, `populateEliminateBufferizeMaterializationsPatterns`
|
||||
([code](https://github.com/llvm/llvm-project/blob/a0b65a7bcd6065688189b3d678c42ed6af9603db/mlir/include/mlir/Transforms/Bufferize.h#L58))
|
||||
is available for such passes to provide patterns that eliminate `tensor_load`
|
||||
and `buffer_cast`.
|
||||
is available for such passes to provide patterns that eliminate
|
||||
`memref.tensor_load` and `memref.buffer_cast`.
|
||||
|
||||
## Changes since [the talk](#the-talk)
|
||||
|
||||
- `func-bufferize` was changed to be a partial conversion pass, and there is a
|
||||
new `finalizing-bufferize` which serves as a general finalizing bufferization
|
||||
pass.
|
||||
- `func-bufferize` was changed to be a partial conversion pass, and there is a
|
||||
new `finalizing-bufferize` which serves as a general finalizing
|
||||
bufferization pass.
|
||||
|
|
|
|||
|
|
@ -68,8 +68,8 @@ class Pattern<
|
|||
|
||||
A declarative rewrite rule contains two main components:
|
||||
|
||||
* A _source pattern_, which is used for matching a DAG of operations.
|
||||
* One or more _result patterns_, which are used for generating DAGs of
|
||||
* A *source pattern*, which is used for matching a DAG of operations.
|
||||
* One or more *result patterns*, which are used for generating DAGs of
|
||||
operations to replace the matched DAG of operations.
|
||||
|
||||
We allow multiple result patterns to support
|
||||
|
|
@ -380,8 +380,8 @@ array attribute). Typically the string should be a function call.
|
|||
##### `NativeCodeCall` placeholders
|
||||
|
||||
In `NativeCodeCall`, we can use placeholders like `$_builder`, `$N` and `$N...`.
|
||||
The former is called _special placeholder_, while the latter is called
|
||||
_positional placeholder_ and _positional range placeholder_.
|
||||
The former is called *special placeholder*, while the latter is called
|
||||
*positional placeholder* and *positional range placeholder*.
|
||||
|
||||
`NativeCodeCall` right now only supports three special placeholders:
|
||||
`$_builder`, `$_loc`, and `$_self`:
|
||||
|
|
@ -405,15 +405,16 @@ def : Pat<(OneAttrOp (NativeCodeCall<"Foo($_self, &$0)"> I32Attr:$val)),
|
|||
```
|
||||
|
||||
In the above, `$_self` is substituted by the defining operation of the first
|
||||
operand of OneAttrOp. Note that we don't support binding name to `NativeCodeCall`
|
||||
in the source pattern. To carry some return values from a helper function, put the
|
||||
names (constraint is optional) in the parameter list and they will be bound to
|
||||
the variables with correspoding type. Then these names must be either passed by
|
||||
reference or pointer to the variable used as argument so that the matched value
|
||||
can be returned. In the same example, `$val` will be bound to a variable with
|
||||
`Attribute` type (as `I32Attr`) and the type of the second argument in `Foo()`
|
||||
could be `Attribute&` or `Attribute*`. Names with attribute constraints will be
|
||||
captured as `Attribute`s while everything else will be treated as `Value`s.
|
||||
operand of OneAttrOp. Note that we don't support binding name to
|
||||
`NativeCodeCall` in the source pattern. To carry some return values from a
|
||||
helper function, put the names (constraint is optional) in the parameter list
|
||||
and they will be bound to the variables with correspoding type. Then these names
|
||||
must be either passed by reference or pointer to the variable used as argument
|
||||
so that the matched value can be returned. In the same example, `$val` will be
|
||||
bound to a variable with `Attribute` type (as `I32Attr`) and the type of the
|
||||
second argument in `Foo()` could be `Attribute&` or `Attribute*`. Names with
|
||||
attribute constraints will be captured as `Attribute`s while everything else
|
||||
will be treated as `Value`s.
|
||||
|
||||
Positional placeholders will be substituted by the `dag` object parameters at
|
||||
the `NativeCodeCall` use site. For example, if we define `SomeCall :
|
||||
|
|
@ -445,9 +446,9 @@ Use `NativeCodeCallVoid` for cases with no return value.
|
|||
The correct number of returned value specified in NativeCodeCall is important.
|
||||
It will be used to verify the consistency of the number of return values.
|
||||
Additionally, `mlir-tblgen` will try to capture the return values of
|
||||
`NativeCodeCall` in the generated code so that it will trigger a later compilation
|
||||
error if a `NativeCodeCall` that doesn't return any result isn't labeled with 0
|
||||
returns.
|
||||
`NativeCodeCall` in the generated code so that it will trigger a later
|
||||
compilation error if a `NativeCodeCall` that doesn't return any result isn't
|
||||
labeled with 0 returns.
|
||||
|
||||
##### Customizing entire op building
|
||||
|
||||
|
|
@ -471,7 +472,7 @@ def : Pat<(... $input, $attr), (createMyOp $input, $attr)>;
|
|||
### Supporting auxiliary ops
|
||||
|
||||
A declarative rewrite rule supports multiple result patterns. One of the
|
||||
purposes is to allow generating _auxiliary ops_. Auxiliary ops are operations
|
||||
purposes is to allow generating *auxiliary ops*. Auxiliary ops are operations
|
||||
used for building the replacement ops; but they are not directly used for
|
||||
replacement themselves.
|
||||
|
||||
|
|
@ -486,17 +487,17 @@ argument to consuming op. But that is not always possible. For example, if we
|
|||
want to allocate memory and store some computation (in pseudocode):
|
||||
|
||||
```mlir
|
||||
%dst = addi %lhs, %rhs
|
||||
%dst = arith.addi %lhs, %rhs
|
||||
```
|
||||
|
||||
into
|
||||
|
||||
```mlir
|
||||
%shape = shape %lhs
|
||||
%mem = alloc %shape
|
||||
%sum = addi %lhs, %rhs
|
||||
store %mem, %sum
|
||||
%dst = load %mem
|
||||
%mem = memref.alloc %shape
|
||||
%sum = arith.addi %lhs, %rhs
|
||||
memref.store %mem, %sum
|
||||
%dst = memref.load %mem
|
||||
```
|
||||
|
||||
We cannot fit in with just one result pattern given `store` does not return a
|
||||
|
|
@ -610,10 +611,10 @@ def : Pattern<(ThreeResultOp ...),
|
|||
Before going into details on variadic op support, we need to define a few terms
|
||||
regarding an op's values.
|
||||
|
||||
* _Value_: either an operand or a result
|
||||
* _Declared operand/result/value_: an operand/result/value statically declared
|
||||
* *Value*: either an operand or a result
|
||||
* *Declared operand/result/value*: an operand/result/value statically declared
|
||||
in ODS of the op
|
||||
* _Actual operand/result/value_: an operand/result/value of an op instance at
|
||||
* *Actual operand/result/value*: an operand/result/value of an op instance at
|
||||
runtime
|
||||
|
||||
The above terms are needed because ops can have multiple results, and some of
|
||||
|
|
@ -754,12 +755,12 @@ builders with return type deduction.
|
|||
The `returnType` directive must be used as a trailing argument to a node
|
||||
describing a replacement op. The directive comes in three forms:
|
||||
|
||||
* `(returnType $value)`: copy the type of the operand or result bound to
|
||||
`value`.
|
||||
* `(returnType "$_builder.getI32Type()")`: a string literal embedding C++. The
|
||||
embedded snippet is expected to return a `Type` or a `TypeRange`.
|
||||
* `(returnType (NativeCodeCall<"myFunc($0)"> $value))`: a DAG node with a native
|
||||
code call that can be passed any bound variables arguments.
|
||||
* `(returnType $value)`: copy the type of the operand or result bound to
|
||||
`value`.
|
||||
* `(returnType "$_builder.getI32Type()")`: a string literal embedding C++. The
|
||||
embedded snippet is expected to return a `Type` or a `TypeRange`.
|
||||
* `(returnType (NativeCodeCall<"myFunc($0)"> $value))`: a DAG node with a
|
||||
native code call that can be passed any bound variables arguments.
|
||||
|
||||
Specify multiple return types with a mix of any of the above. Example:
|
||||
|
||||
|
|
|
|||
|
|
@ -301,7 +301,7 @@ func @bad_branch() {
|
|||
// Expect an error on an adjacent line.
|
||||
func @foo(%a : f32) {
|
||||
// expected-error@+1 {{unknown comparison predicate "foo"}}
|
||||
%result = cmpf "foo", %a, %a : f32
|
||||
%result = arith.cmpf "foo", %a, %a : f32
|
||||
return
|
||||
}
|
||||
|
||||
|
|
|
|||
|
|
@ -66,7 +66,7 @@ legality actions below:
|
|||
|
||||
- This action signals that only some instances of a given operation are
|
||||
legal. This allows for defining fine-tune constraints, e.g. saying that
|
||||
`addi` is only legal when operating on 32-bit integers.
|
||||
`arith.addi` is only legal when operating on 32-bit integers.
|
||||
|
||||
* Illegal
|
||||
|
||||
|
|
|
|||
|
|
@ -13,8 +13,8 @@ core concepts that are used throughout the document.
|
|||
### Dimensions and Symbols
|
||||
|
||||
Dimensions and symbols are the two kinds of identifiers that can appear in the
|
||||
polyhedral structures, and are always of [`index`](Builtin.md/#indextype)
|
||||
type. Dimensions are declared in parentheses and symbols are declared in square
|
||||
polyhedral structures, and are always of [`index`](Builtin.md/#indextype) type.
|
||||
Dimensions are declared in parentheses and symbols are declared in square
|
||||
brackets.
|
||||
|
||||
Examples:
|
||||
|
|
@ -54,36 +54,34 @@ Example:
|
|||
```mlir
|
||||
#affine_map2to3 = affine_map<(d0, d1)[s0] -> (d0, d1 + s0, d1 - s0)>
|
||||
// Binds %N to the s0 symbol in affine_map2to3.
|
||||
%x = alloc()[%N] : memref<40x50xf32, #affine_map2to3>
|
||||
%x = memref.alloc()[%N] : memref<40x50xf32, #affine_map2to3>
|
||||
```
|
||||
|
||||
### Restrictions on Dimensions and Symbols
|
||||
|
||||
The affine dialect imposes certain restrictions on dimension and symbolic
|
||||
identifiers to enable powerful analysis and transformation. An SSA value's use
|
||||
can be bound to a symbolic identifier if that SSA value is either
|
||||
1. a region argument for an op with trait `AffineScope` (eg. `FuncOp`),
|
||||
2. a value defined at the top level of an `AffineScope` op (i.e., immediately
|
||||
enclosed by the latter),
|
||||
3. a value that dominates the `AffineScope` op enclosing the value's use,
|
||||
4. the result of a [`constant` operation](Standard.md/#stdconstant-constantop),
|
||||
5. the result of an [`affine.apply`
|
||||
operation](#affineapply-affineapplyop) that recursively takes as arguments any valid
|
||||
symbolic identifiers, or
|
||||
6. the result of a [`dim` operation](MemRef.md/#memrefdim-mlirmemrefdimop) on either a
|
||||
memref that is an argument to a `AffineScope` op or a memref where the
|
||||
corresponding dimension is either static or a dynamic one in turn bound to a
|
||||
valid symbol.
|
||||
can be bound to a symbolic identifier if that SSA value is either 1. a region
|
||||
argument for an op with trait `AffineScope` (eg. `FuncOp`), 2. a value defined
|
||||
at the top level of an `AffineScope` op (i.e., immediately enclosed by the
|
||||
latter), 3. a value that dominates the `AffineScope` op enclosing the value's
|
||||
use, 4. the result of a
|
||||
[`constant` operation](Standard.md/#stdconstant-constantop), 5. the result of an
|
||||
[`affine.apply` operation](#affineapply-affineapplyop) that recursively takes as
|
||||
arguments any valid symbolic identifiers, or 6. the result of a
|
||||
[`dim` operation](MemRef.md/#memrefdim-mlirmemrefdimop) on either a memref that
|
||||
is an argument to a `AffineScope` op or a memref where the corresponding
|
||||
dimension is either static or a dynamic one in turn bound to a valid symbol.
|
||||
*Note:* if the use of an SSA value is not contained in any op with the
|
||||
`AffineScope` trait, only the rules 4-6 can be applied.
|
||||
|
||||
Note that as a result of rule (3) above, symbol validity is sensitive to the
|
||||
location of the SSA use. Dimensions may be bound not only to anything that a
|
||||
location of the SSA use. Dimensions may be bound not only to anything that a
|
||||
symbol is bound to, but also to induction variables of enclosing
|
||||
[`affine.for`](#affinefor-affineforop) and
|
||||
[`affine.parallel`](#affineparallel-affineparallelop) operations, and the result of an
|
||||
[`affine.apply` operation](#affineapply-affineapplyop) (which recursively may use
|
||||
other dimensions and symbols).
|
||||
[`affine.parallel`](#affineparallel-affineparallelop) operations, and the result
|
||||
of an [`affine.apply` operation](#affineapply-affineapplyop) (which recursively
|
||||
may use other dimensions and symbols).
|
||||
|
||||
### Affine Expressions
|
||||
|
||||
|
|
@ -119,24 +117,24 @@ parenthesization, (2) negation, (3) modulo, multiplication, floordiv, and
|
|||
ceildiv, and (4) addition and subtraction. All of these operators associate from
|
||||
left to right.
|
||||
|
||||
A _multidimensional affine expression_ is a comma separated list of
|
||||
A *multidimensional affine expression* is a comma separated list of
|
||||
one-dimensional affine expressions, with the entire list enclosed in
|
||||
parentheses.
|
||||
|
||||
**Context:** An affine function, informally, is a linear function plus a
|
||||
constant. More formally, a function f defined on a vector $\vec{v} \in
|
||||
\mathbb{Z}^n$ is a multidimensional affine function of $\vec{v}$ if
|
||||
$f(\vec{v})$ can be expressed in the form $M \vec{v} + \vec{c}$ where $M$
|
||||
is a constant matrix from $\mathbb{Z}^{m \times n}$ and $\vec{c}$ is a
|
||||
constant vector from $\mathbb{Z}$. $m$ is the dimensionality of such an
|
||||
affine function. MLIR further extends the definition of an affine function to
|
||||
allow 'floordiv', 'ceildiv', and 'mod' with respect to positive integer
|
||||
constants. Such extensions to affine functions have often been referred to as
|
||||
quasi-affine functions by the polyhedral compiler community. MLIR uses the term
|
||||
'affine map' to refer to these multidimensional quasi-affine functions. As
|
||||
examples, $(i+j+1, j)$, $(i \mod 2, j+i)$, $(j, i/4, i \mod 4)$, $(2i+1,
|
||||
j)$ are two-dimensional affine functions of $(i, j)$, but $(i \cdot j,
|
||||
i^2)$, $(i \mod j, i/j)$ are not affine functions of $(i, j)$.
|
||||
\mathbb{Z}^n$ is a multidimensional affine function of $\vec{v}$ if $f(\vec{v})$
|
||||
can be expressed in the form $M \vec{v} + \vec{c}$ where $M$ is a constant
|
||||
matrix from $\mathbb{Z}^{m \times n}$ and $\vec{c}$ is a constant vector from
|
||||
$\mathbb{Z}$. $m$ is the dimensionality of such an affine function. MLIR further
|
||||
extends the definition of an affine function to allow 'floordiv', 'ceildiv', and
|
||||
'mod' with respect to positive integer constants. Such extensions to affine
|
||||
functions have often been referred to as quasi-affine functions by the
|
||||
polyhedral compiler community. MLIR uses the term 'affine map' to refer to these
|
||||
multidimensional quasi-affine functions. As examples, $(i+j+1, j)$, $(i \mod 2,
|
||||
j+i)$, $(j, i/4, i \mod 4)$, $(2i+1, j)$ are two-dimensional affine functions of
|
||||
$(i, j)$, but $(i \cdot j, i^2)$, $(i \mod j, i/j)$ are not affine functions of
|
||||
$(i, j)$.
|
||||
|
||||
### Affine Maps
|
||||
|
||||
|
|
@ -157,9 +155,9 @@ dimension indices and symbols into a list of results, with affine expressions
|
|||
combining the indices and symbols. Affine maps distinguish between
|
||||
[indices and symbols](#dimensions-and-symbols) because indices are inputs to the
|
||||
affine map when the map is called (through an operation such as
|
||||
[affine.apply](#affineapply-affineapplyop)), whereas symbols are bound when
|
||||
the map is established (e.g. when a memref is formed, establishing a
|
||||
memory [layout map](Builtin.md/#layout-map)).
|
||||
[affine.apply](#affineapply-affineapplyop)), whereas symbols are bound when the
|
||||
map is established (e.g. when a memref is formed, establishing a memory
|
||||
[layout map](Builtin.md/#layout-map)).
|
||||
|
||||
Affine maps are used for various core structures in MLIR. The restrictions we
|
||||
impose on their form allows powerful analysis and transformation, while keeping
|
||||
|
|
@ -192,10 +190,10 @@ Examples:
|
|||
|
||||
// Use an affine mapping definition in an alloc operation, binding the
|
||||
// SSA value %N to the symbol s0.
|
||||
%a = alloc()[%N] : memref<4x4xf32, #affine_map42>
|
||||
%a = memref.alloc()[%N] : memref<4x4xf32, #affine_map42>
|
||||
|
||||
// Same thing with an inline affine mapping definition.
|
||||
%b = alloc()[%N] : memref<4x4xf32, affine_map<(d0, d1)[s0] -> (d0, d0 + d1 + s0 floordiv 2)>>
|
||||
%b = memref.alloc()[%N] : memref<4x4xf32, affine_map<(d0, d1)[s0] -> (d0, d0 + d1 + s0 floordiv 2)>>
|
||||
```
|
||||
|
||||
### Semi-affine maps
|
||||
|
|
@ -378,23 +376,21 @@ operation ::= `affine.dma_Start` ssa-use `[` multi-dim-affine-map-of-ssa-ids `]`
|
|||
The `affine.dma_start` op starts a non-blocking DMA operation that transfers
|
||||
data from a source memref to a destination memref. The source and destination
|
||||
memref need not be of the same dimensionality, but need to have the same
|
||||
elemental type. The operands include the source and destination memref's
|
||||
each followed by its indices, size of the data transfer in terms of the
|
||||
number of elements (of the elemental type of the memref), a tag memref with
|
||||
its indices, and optionally at the end, a stride and a
|
||||
number_of_elements_per_stride arguments. The tag location is used by an
|
||||
AffineDmaWaitOp to check for completion. The indices of the source memref,
|
||||
destination memref, and the tag memref have the same restrictions as any
|
||||
affine.load/store. In particular, index for each memref dimension must be an
|
||||
affine expression of loop induction variables and symbols.
|
||||
The optional stride arguments should be of 'index' type, and specify a
|
||||
stride for the slower memory space (memory space with a lower memory space
|
||||
id), transferring chunks of number_of_elements_per_stride every stride until
|
||||
%num_elements are transferred. Either both or no stride arguments should be
|
||||
specified. The value of 'num_elements' must be a multiple of
|
||||
elemental type. The operands include the source and destination memref's each
|
||||
followed by its indices, size of the data transfer in terms of the number of
|
||||
elements (of the elemental type of the memref), a tag memref with its indices,
|
||||
and optionally at the end, a stride and a number_of_elements_per_stride
|
||||
arguments. The tag location is used by an AffineDmaWaitOp to check for
|
||||
completion. The indices of the source memref, destination memref, and the tag
|
||||
memref have the same restrictions as any affine.load/store. In particular, index
|
||||
for each memref dimension must be an affine expression of loop induction
|
||||
variables and symbols. The optional stride arguments should be of 'index' type,
|
||||
and specify a stride for the slower memory space (memory space with a lower
|
||||
memory space id), transferring chunks of number_of_elements_per_stride every
|
||||
stride until %num_elements are transferred. Either both or no stride arguments
|
||||
should be specified. The value of 'num_elements' must be a multiple of
|
||||
'number_of_elements_per_stride'.
|
||||
|
||||
|
||||
Example:
|
||||
|
||||
```mlir
|
||||
|
|
@ -403,8 +399,8 @@ For example, a DmaStartOp operation that transfers 256 elements of a memref
|
|||
space 1 at indices [%k + 7, %l], would be specified as follows:
|
||||
|
||||
%num_elements = constant 256
|
||||
%idx = constant 0 : index
|
||||
%tag = alloc() : memref<1xi32, 4>
|
||||
%idx = arith.constant 0 : index
|
||||
%tag = memref.alloc() : memref<1xi32, 4>
|
||||
affine.dma_start %src[%i + 3, %j], %dst[%k + 7, %l], %tag[%idx],
|
||||
%num_elements :
|
||||
memref<40x128xf32, 0>, memref<2x1024xf32, 1>, memref<1xi32, 2>
|
||||
|
|
@ -426,10 +422,10 @@ operation ::= `affine.dma_Start` ssa-use `[` multi-dim-affine-map-of-ssa-ids `]`
|
|||
```
|
||||
|
||||
The `affine.dma_start` op blocks until the completion of a DMA operation
|
||||
associated with the tag element '%tag[%index]'. %tag is a memref, and %index
|
||||
has to be an index with the same restrictions as any load/store index.
|
||||
In particular, index for each memref dimension must be an affine expression of
|
||||
loop induction variables and symbols. %num_elements is the number of elements
|
||||
associated with the tag element '%tag[%index]'. %tag is a memref, and %index has
|
||||
to be an index with the same restrictions as any load/store index. In
|
||||
particular, index for each memref dimension must be an affine expression of loop
|
||||
induction variables and symbols. %num_elements is the number of elements
|
||||
associated with the DMA operation. For example:
|
||||
|
||||
Example:
|
||||
|
|
|
|||
|
|
@ -125,14 +125,14 @@ materialized by a lowering into a form that will resemble:
|
|||
#map0 = affine_map<(d0) -> (d0 * 2 + 1)>
|
||||
|
||||
func @example(%arg0: memref<?xf32>, %arg1: memref<?xvector<4xf32>, #map0>) {
|
||||
%c0 = constant 0 : index
|
||||
%c1 = constant 1 : index
|
||||
%0 = dim %arg0, %c0 : memref<?xf32>
|
||||
%c0 = arith.constant 0 : index
|
||||
%c1 = arith.constant 1 : index
|
||||
%0 = memref.dim %arg0, %c0 : memref<?xf32>
|
||||
scf.for %arg2 = %c0 to %0 step %c1 {
|
||||
%1 = load %arg0[%arg2] : memref<?xf32>
|
||||
%2 = load %arg1[%arg2] : memref<?xvector<4xf32>, #map0>
|
||||
%1 = memref.load %arg0[%arg2] : memref<?xf32>
|
||||
%2 = memref.load %arg1[%arg2] : memref<?xvector<4xf32>, #map0>
|
||||
%3 = "some_compute"(%1, %2) : (f32, vector<4xf32>) -> vector<4xf32>
|
||||
store %3, %arg1[%arg2] : memref<?xvector<4xf32>, #map0>
|
||||
memref.store %3, %arg1[%arg2] : memref<?xvector<4xf32>, #map0>
|
||||
}
|
||||
return
|
||||
}
|
||||
|
|
@ -207,16 +207,16 @@ materialized by a lowering into a form that will resemble:
|
|||
#map0 = affine_map<(d0, d1) -> (d0 * 2 + d1 * 2)>
|
||||
|
||||
func @example(%arg0: memref<8x?xf32, #map0>, %arg1: memref<?xvector<4xf32>>) {
|
||||
%c8 = constant 8 : index
|
||||
%c0 = constant 0 : index
|
||||
%c1 = constant 1 : index
|
||||
%0 = dim %arg0, %c1 : memref<8x?xf32, #map0>
|
||||
%c8 = arith.constant 8 : index
|
||||
%c0 = arith.constant 0 : index
|
||||
%c1 = arith.constant 1 : index
|
||||
%0 = memref.dim %arg0, %c1 : memref<8x?xf32, #map0>
|
||||
scf.for %arg2 = %c0 to %0 step %c1 {
|
||||
scf.for %arg3 = %c0 to %c8 step %c1 {
|
||||
%1 = load %arg0[%arg3, %arg2] : memref<8x?xf32, #map0>
|
||||
%2 = load %arg1[%arg3] : memref<?xvector<4xf32>>
|
||||
%1 = memref.load %arg0[%arg3, %arg2] : memref<8x?xf32, #map0>
|
||||
%2 = memref.load %arg1[%arg3] : memref<?xvector<4xf32>>
|
||||
%3 = "some_compute"(%1, %2) : (f32, vector<4xf32>) -> vector<4xf32>
|
||||
store %3, %arg1[%arg3] : memref<?xvector<4xf32>>
|
||||
memref.store %3, %arg1[%arg3] : memref<?xvector<4xf32>>
|
||||
}
|
||||
}
|
||||
return
|
||||
|
|
@ -314,7 +314,7 @@ func @example(%A: memref<?x?xf32>, %B: memref<?x?xf32>, %C: memref<?x?xf32>) {
|
|||
ins(%A, %B: memref<?x?xf32>, memref<?x?xf32>)
|
||||
outs(%C: memref<?x?xf32>) {
|
||||
^bb0(%a: f32, %b: f32, %c: f32):
|
||||
%d = addf %a, %b : f32
|
||||
%d = arith.addf %a, %b : f32
|
||||
linalg.yield %d : f32
|
||||
}
|
||||
|
||||
|
|
@ -330,16 +330,16 @@ by a lowering into a form that will resemble:
|
|||
|
||||
```mlir
|
||||
func @example(%arg0: memref<?x?xf32>, %arg1: memref<?x?xf32>, %arg2: memref<?x?xf32>) {
|
||||
%c0 = constant 0 : index
|
||||
%c1 = constant 1 : index
|
||||
%0 = dim %arg0, %c0 : memref<?x?xf32>
|
||||
%1 = dim %arg0, %c1 : memref<?x?xf32>
|
||||
%c0 = arith.constant 0 : index
|
||||
%c1 = arith.constant 1 : index
|
||||
%0 = memref.dim %arg0, %c0 : memref<?x?xf32>
|
||||
%1 = memref.dim %arg0, %c1 : memref<?x?xf32>
|
||||
scf.for %arg3 = %c0 to %0 step %c1 {
|
||||
scf.for %arg4 = %c0 to %1 step %c1 {
|
||||
%2 = load %arg0[%arg3, %arg4] : memref<?x?xf32>
|
||||
%3 = load %arg1[%arg3, %arg4] : memref<?x?xf32>
|
||||
%4 = addf %2, %3 : f32
|
||||
store %4, %arg2[%arg3, %arg4] : memref<?x?xf32>
|
||||
%2 = memref.load %arg0[%arg3, %arg4] : memref<?x?xf32>
|
||||
%3 = memref.load %arg1[%arg3, %arg4] : memref<?x?xf32>
|
||||
%4 = arith.addf %2, %3 : f32
|
||||
memref.store %4, %arg2[%arg3, %arg4] : memref<?x?xf32>
|
||||
}
|
||||
}
|
||||
return
|
||||
|
|
@ -387,7 +387,7 @@ func @example(%A: memref<?x?xf32>, %B: memref<?x?xf32>, %C: memref<?x?xf32>) {
|
|||
ins(%A, %B: memref<?x?xf32>, memref<?x?xf32>)
|
||||
outs(%C: memref<?x?xf32>) {
|
||||
^bb0(%a: f32, %b: f32, %c: f32):
|
||||
%d = addf %a, %b : f32
|
||||
%d = arith.addf %a, %b : f32
|
||||
linalg.yield %d : f32
|
||||
}
|
||||
return
|
||||
|
|
@ -518,7 +518,7 @@ generally alias the operand `view`. At the moment the existing ops are:
|
|||
|
||||
```
|
||||
* `memref.view`,
|
||||
* `std.subview`,
|
||||
* `memref.subview`,
|
||||
* `memref.transpose`.
|
||||
* `linalg.range`,
|
||||
* `linalg.slice`,
|
||||
|
|
|
|||
|
|
@ -16,7 +16,7 @@ before adding or changing any operation in this dialect.**
|
|||
Syntax:
|
||||
|
||||
```
|
||||
operation ::= `dma_start` ssa-use`[`ssa-use-list`]` `,`
|
||||
operation ::= `memref.dma_start` ssa-use`[`ssa-use-list`]` `,`
|
||||
ssa-use`[`ssa-use-list`]` `,` ssa-use `,`
|
||||
ssa-use`[`ssa-use-list`]` (`,` ssa-use `,` ssa-use)?
|
||||
`:` memref-type `,` memref-type `,` memref-type
|
||||
|
|
@ -39,17 +39,17 @@ computation, and checking for matching start/end operations. The source and
|
|||
destination memref need not be of the same dimensionality, but need to have the
|
||||
same elemental type.
|
||||
|
||||
For example, a `dma_start` operation that transfers 32 vector elements from a
|
||||
memref `%src` at location `[%i, %j]` to memref `%dst` at `[%k, %l]` would be
|
||||
specified as shown below.
|
||||
For example, a `memref.dma_start` operation that transfers 32 vector elements
|
||||
from a memref `%src` at location `[%i, %j]` to memref `%dst` at `[%k, %l]` would
|
||||
be specified as shown below.
|
||||
|
||||
Example:
|
||||
|
||||
```mlir
|
||||
%size = constant 32 : index
|
||||
%tag = alloc() : memref<1 x i32, affine_map<(d0) -> (d0)>, 4>
|
||||
%idx = constant 0 : index
|
||||
dma_start %src[%i, %j], %dst[%k, %l], %size, %tag[%idx] :
|
||||
%size = arith.constant 32 : index
|
||||
%tag = memref.alloc() : memref<1 x i32, affine_map<(d0) -> (d0)>, 4>
|
||||
%idx = arith.constant 0 : index
|
||||
memref.dma_start %src[%i, %j], %dst[%k, %l], %size, %tag[%idx] :
|
||||
memref<40 x 8 x vector<16xf32>, affine_map<(d0, d1) -> (d0, d1)>, 0>,
|
||||
memref<2 x 4 x vector<16xf32>, affine_map<(d0, d1) -> (d0, d1)>, 2>,
|
||||
memref<1 x i32>, affine_map<(d0) -> (d0)>, 4>
|
||||
|
|
@ -60,7 +60,7 @@ dma_start %src[%i, %j], %dst[%k, %l], %size, %tag[%idx] :
|
|||
Syntax:
|
||||
|
||||
```
|
||||
operation ::= `dma_wait` ssa-use`[`ssa-use-list`]` `,` ssa-use `:` memref-type
|
||||
operation ::= `memref.dma_wait` ssa-use`[`ssa-use-list`]` `,` ssa-use `:` memref-type
|
||||
```
|
||||
|
||||
Blocks until the completion of a DMA operation associated with the tag element
|
||||
|
|
@ -72,5 +72,5 @@ load/store indices.
|
|||
Example:
|
||||
|
||||
```mlir
|
||||
dma_wait %tag[%idx], %size : memref<1 x i32, affine_map<(d0) -> (d0)>, 4>
|
||||
memref.dma_wait %tag[%idx], %size : memref<1 x i32, affine_map<(d0) -> (d0)>, 4>
|
||||
```
|
||||
|
|
|
|||
|
|
@ -3,26 +3,27 @@
|
|||
[TOC]
|
||||
|
||||
MLIR supports multi-dimensional `vector` types and custom operations on those
|
||||
types. A generic, retargetable, higher-order ``vector`` type (`n-D` with `n >
|
||||
1`) is a structured type, that carries semantic information useful for
|
||||
transformations. This document discusses retargetable abstractions that exist
|
||||
in MLIR today and operate on ssa-values of type `vector` along with pattern
|
||||
types. A generic, retargetable, higher-order `vector` type (`n-D` with `n > 1`)
|
||||
is a structured type, that carries semantic information useful for
|
||||
transformations. This document discusses retargetable abstractions that exist in
|
||||
MLIR today and operate on ssa-values of type `vector` along with pattern
|
||||
rewrites and lowerings that enable targeting specific instructions on concrete
|
||||
targets. These abstractions serve to separate concerns between operations on
|
||||
`memref` (a.k.a buffers) and operations on ``vector`` values. This is not a
|
||||
new proposal but rather a textual documentation of existing MLIR components
|
||||
along with a rationale.
|
||||
`memref` (a.k.a buffers) and operations on `vector` values. This is not a new
|
||||
proposal but rather a textual documentation of existing MLIR components along
|
||||
with a rationale.
|
||||
|
||||
## Positioning in the Codegen Infrastructure
|
||||
The following diagram, recently presented with the [StructuredOps
|
||||
abstractions](https://drive.google.com/corp/drive/u/0/folders/1sRAsgsd8Bvpm_IxREmZf2agsGU2KvrK-),
|
||||
|
||||
The following diagram, recently presented with the
|
||||
[StructuredOps abstractions](https://drive.google.com/corp/drive/u/0/folders/1sRAsgsd8Bvpm_IxREmZf2agsGU2KvrK-),
|
||||
captures the current codegen paths implemented in MLIR in the various existing
|
||||
lowering paths.
|
||||
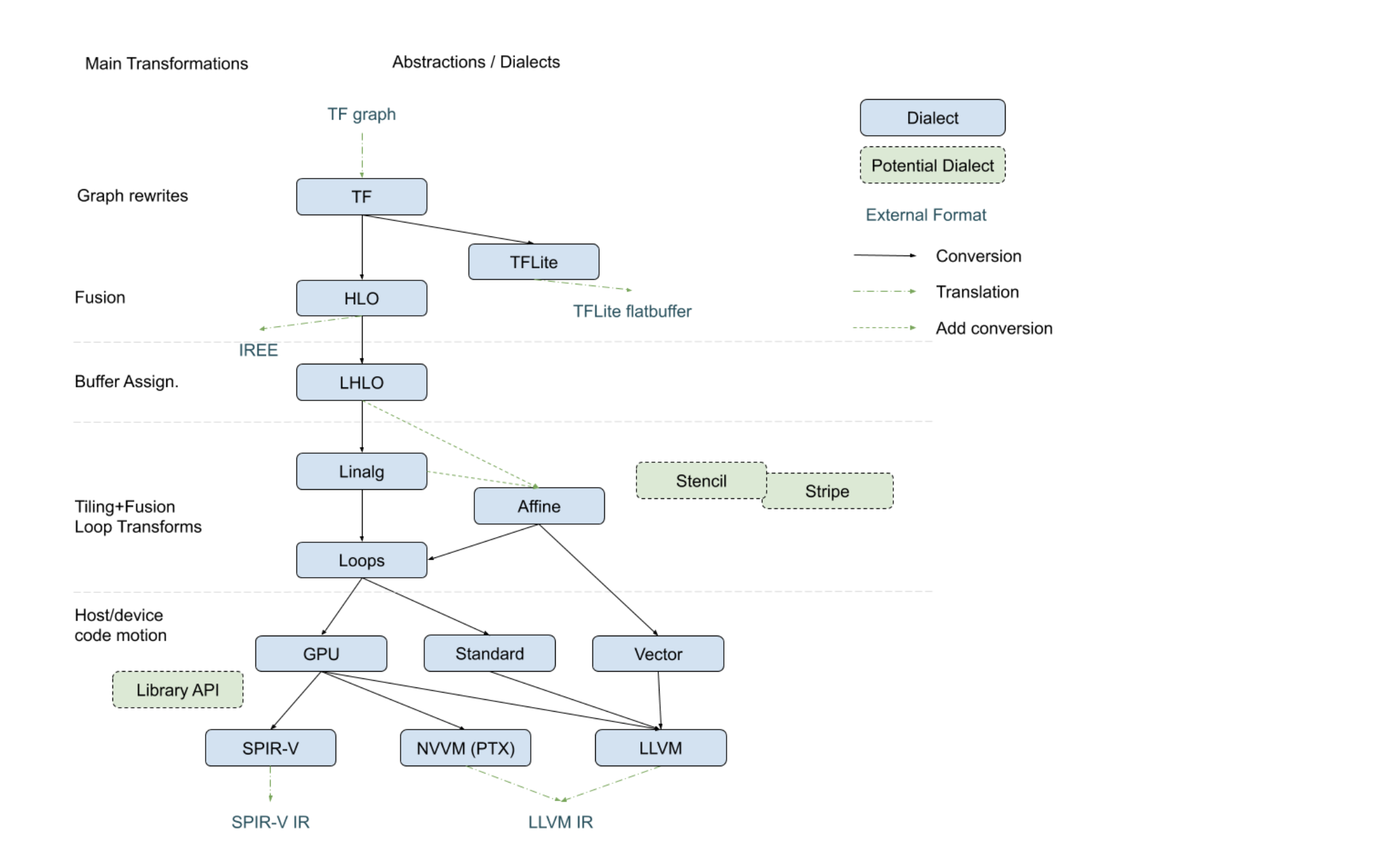
|
||||
|
||||
The following diagram seeks to isolate `vector` dialects from the complexity
|
||||
of the codegen paths and focus on the payload-carrying ops that operate on std
|
||||
and `vector` types. This diagram is not to be taken as set in stone and
|
||||
The following diagram seeks to isolate `vector` dialects from the complexity of
|
||||
the codegen paths and focus on the payload-carrying ops that operate on std and
|
||||
`vector` types. This diagram is not to be taken as set in stone and
|
||||
representative of what exists today but rather illustrates the layering of
|
||||
abstractions in MLIR.
|
||||
|
||||
|
|
@ -31,164 +32,165 @@ abstractions in MLIR.
|
|||
This separates concerns related to (a) defining efficient operations on
|
||||
`vector` types from (b) program analyses + transformations on `memref`, loops
|
||||
and other types of structured ops (be they `HLO`, `LHLO`, `Linalg` or other ).
|
||||
Looking a bit forward in time, we can put a stake in the ground and venture
|
||||
that the higher level of `vector`-level primitives we build and target from
|
||||
codegen (or some user/language level), the simpler our task will be, the more
|
||||
complex patterns can be expressed and the better performance will be.
|
||||
Looking a bit forward in time, we can put a stake in the ground and venture that
|
||||
the higher level of `vector`-level primitives we build and target from codegen
|
||||
(or some user/language level), the simpler our task will be, the more complex
|
||||
patterns can be expressed and the better performance will be.
|
||||
|
||||
## Components of a Generic Retargetable Vector-Level Dialect
|
||||
The existing MLIR `vector`-level dialects are related to the following
|
||||
bottom-up abstractions:
|
||||
|
||||
1. Representation in `LLVMIR` via data structures, instructions and
|
||||
intrinsics. This is referred to as the `LLVM` level.
|
||||
2. Set of machine-specific operations and types that are built to translate
|
||||
almost 1-1 with the HW ISA. This is referred to as the Hardware Vector level;
|
||||
a.k.a `HWV`. For instance, we have (a) the `NVVM` dialect (for `CUDA`) with
|
||||
tensor core ops, (b) accelerator-specific dialects (internal), a potential
|
||||
(future) `CPU` dialect to capture `LLVM` intrinsics more closely and other
|
||||
dialects for specific hardware. Ideally this should be auto-generated as much
|
||||
as possible from the `LLVM` level.
|
||||
3. Set of virtual, machine-agnostic, operations that are informed by costs at
|
||||
the `HWV`-level. This is referred to as the Virtual Vector level; a.k.a
|
||||
`VV`. This is the level that higher-level abstractions (codegen, automatic
|
||||
vectorization, potential vector language, ...) targets.
|
||||
The existing MLIR `vector`-level dialects are related to the following bottom-up
|
||||
abstractions:
|
||||
|
||||
1. Representation in `LLVMIR` via data structures, instructions and intrinsics.
|
||||
This is referred to as the `LLVM` level.
|
||||
2. Set of machine-specific operations and types that are built to translate
|
||||
almost 1-1 with the HW ISA. This is referred to as the Hardware Vector
|
||||
level; a.k.a `HWV`. For instance, we have (a) the `NVVM` dialect (for
|
||||
`CUDA`) with tensor core ops, (b) accelerator-specific dialects (internal),
|
||||
a potential (future) `CPU` dialect to capture `LLVM` intrinsics more closely
|
||||
and other dialects for specific hardware. Ideally this should be
|
||||
auto-generated as much as possible from the `LLVM` level.
|
||||
3. Set of virtual, machine-agnostic, operations that are informed by costs at
|
||||
the `HWV`-level. This is referred to as the Virtual Vector level; a.k.a
|
||||
`VV`. This is the level that higher-level abstractions (codegen, automatic
|
||||
vectorization, potential vector language, ...) targets.
|
||||
|
||||
The existing generic, retargetable, `vector`-level dialect is related to the
|
||||
following top-down rewrites and conversions:
|
||||
|
||||
1. MLIR Rewrite Patterns applied by the MLIR `PatternRewrite` infrastructure
|
||||
to progressively lower to implementations that match closer and closer to the
|
||||
`HWV`. Some patterns are "in-dialect" `VV -> VV` and some are conversions `VV
|
||||
-> HWV`.
|
||||
2. `Virtual Vector -> Hardware Vector` lowering is specified as a set of MLIR
|
||||
lowering patterns that are specified manually for now.
|
||||
3. `Hardware Vector -> LLVM` lowering is a mechanical process that is written
|
||||
manually at the moment and that should be automated, following the `LLVM ->
|
||||
Hardware Vector` ops generation as closely as possible.
|
||||
1. MLIR Rewrite Patterns applied by the MLIR `PatternRewrite` infrastructure to
|
||||
progressively lower to implementations that match closer and closer to the
|
||||
`HWV`. Some patterns are "in-dialect" `VV -> VV` and some are conversions
|
||||
`VV -> HWV`.
|
||||
2. `Virtual Vector -> Hardware Vector` lowering is specified as a set of MLIR
|
||||
lowering patterns that are specified manually for now.
|
||||
3. `Hardware Vector -> LLVM` lowering is a mechanical process that is written
|
||||
manually at the moment and that should be automated, following the `LLVM ->
|
||||
Hardware Vector` ops generation as closely as possible.
|
||||
|
||||
## Short Description of the Existing Infrastructure
|
||||
|
||||
### LLVM level
|
||||
On CPU, the `n-D` `vector` type currently lowers to
|
||||
`!llvm<array<vector>>`. More concretely, `vector<4x8x128xf32>` lowers to
|
||||
`!llvm<[4 x [ 8 x [ 128 x float ]]]>`.
|
||||
There are tradeoffs involved related to how one can access subvectors and how
|
||||
one uses `llvm.extractelement`, `llvm.insertelement` and
|
||||
`llvm.shufflevector`. A [deeper dive section](#DeeperDive) discusses the
|
||||
current lowering choices and tradeoffs.
|
||||
|
||||
On CPU, the `n-D` `vector` type currently lowers to `!llvm<array<vector>>`. More
|
||||
concretely, `vector<4x8x128xf32>` lowers to `!llvm<[4 x [ 8 x [ 128 x float
|
||||
]]]>`. There are tradeoffs involved related to how one can access subvectors and
|
||||
how one uses `llvm.extractelement`, `llvm.insertelement` and
|
||||
`llvm.shufflevector`. A [deeper dive section](#DeeperDive) discusses the current
|
||||
lowering choices and tradeoffs.
|
||||
|
||||
### Hardware Vector Ops
|
||||
Hardware Vector Ops are implemented as one dialect per target.
|
||||
For internal hardware, we are auto-generating the specific HW dialects.
|
||||
For `GPU`, the `NVVM` dialect adds operations such as `mma.sync`, `shfl` and
|
||||
tests.
|
||||
For `CPU` things are somewhat in-flight because the abstraction is close to
|
||||
`LLVMIR`. The jury is still out on whether a generic `CPU` dialect is
|
||||
concretely needed, but it seems reasonable to have the same levels of
|
||||
abstraction for all targets and perform cost-based lowering decisions in MLIR
|
||||
even for `LLVM`.
|
||||
Specialized `CPU` dialects that would capture specific features not well
|
||||
captured by LLVM peephole optimizations of on different types that core MLIR
|
||||
supports (e.g. Scalable Vectors) are welcome future extensions.
|
||||
|
||||
Hardware Vector Ops are implemented as one dialect per target. For internal
|
||||
hardware, we are auto-generating the specific HW dialects. For `GPU`, the `NVVM`
|
||||
dialect adds operations such as `mma.sync`, `shfl` and tests. For `CPU` things
|
||||
are somewhat in-flight because the abstraction is close to `LLVMIR`. The jury is
|
||||
still out on whether a generic `CPU` dialect is concretely needed, but it seems
|
||||
reasonable to have the same levels of abstraction for all targets and perform
|
||||
cost-based lowering decisions in MLIR even for `LLVM`. Specialized `CPU`
|
||||
dialects that would capture specific features not well captured by LLVM peephole
|
||||
optimizations of on different types that core MLIR supports (e.g. Scalable
|
||||
Vectors) are welcome future extensions.
|
||||
|
||||
### Virtual Vector Ops
|
||||
Some existing Standard and Vector Dialect on `n-D` `vector` types comprise:
|
||||
```
|
||||
%2 = std.addf %0, %1 : vector<3x7x8xf32> // -> vector<3x7x8xf32>
|
||||
%2 = std.mulf %0, %1 : vector<3x7x8xf32> // -> vector<3x7x8xf32>
|
||||
%2 = std.splat %1 : vector<3x7x8xf32> // -> vector<3x7x8xf32>
|
||||
|
||||
%1 = vector.extract %0[1]: vector<3x7x8xf32> // -> vector<7x8xf32>
|
||||
%1 = vector.extract %0[1, 5]: vector<3x7x8xf32> // -> vector<8xf32>
|
||||
%2 = vector.outerproduct %0, %1: vector<4xf32>, vector<8xf32> // -> vector<4x8xf32>
|
||||
%3 = vector.outerproduct %0, %1, %2: vector<4xf32>, vector<8xf32> // fma when adding %2
|
||||
%3 = vector.strided_slice %0 {offsets = [2, 2], sizes = [2, 2], strides = [1, 1]}:
|
||||
vector<4x8x16xf32> // Returns a slice of type vector<2x2x16xf32>
|
||||
Some existing Standard and Vector Dialect on `n-D` `vector` types comprise: ```
|
||||
%2 = arith.addf %0, %1 : vector<3x7x8xf32> // -> vector<3x7x8xf32> %2 =
|
||||
arith.mulf %0, %1 : vector<3x7x8xf32> // -> vector<3x7x8xf32> %2 = std.splat
|
||||
%1 : vector<3x7x8xf32> // -> vector<3x7x8xf32>
|
||||
|
||||
%2 = vector.transfer_read %A[%0, %1]
|
||||
{permutation_map = (d0, d1) -> (d0)}: memref<7x?xf32>, vector<4xf32>
|
||||
%1 = vector.extract %0[1]: vector<3x7x8xf32> // -> vector<7x8xf32> %1 =
|
||||
vector.extract %0[1, 5]: vector<3x7x8xf32> // -> vector<8xf32> %2 =
|
||||
vector.outerproduct %0, %1: vector<4xf32>, vector<8xf32> // -> vector<4x8xf32>
|
||||
%3 = vector.outerproduct %0, %1, %2: vector<4xf32>, vector<8xf32> // fma when
|
||||
adding %2 %3 = vector.strided_slice %0 {offsets = [2, 2], sizes = [2, 2],
|
||||
strides = [1, 1]}: vector<4x8x16xf32> // Returns a slice of type
|
||||
vector<2x2x16xf32>
|
||||
|
||||
vector.transfer_write %f1, %A[%i0, %i1, %i2, %i3]
|
||||
{permutation_map = (d0, d1, d2, d3) -> (d3, d1, d0)} :
|
||||
vector<5x4x3xf32>, memref<?x?x?x?xf32>
|
||||
```
|
||||
%2 = vector.transfer_read %A[%0, %1] {permutation_map = (d0, d1) -> (d0)}:
|
||||
memref<7x?xf32>, vector<4xf32>
|
||||
|
||||
The list of Vector is currently undergoing evolutions and is best kept
|
||||
track of by following the evolution of the
|
||||
vector.transfer_write %f1, %A[%i0, %i1, %i2, %i3] {permutation_map = (d0, d1,
|
||||
d2, d3) -> (d3, d1, d0)} : vector<5x4x3xf32>, memref<?x?x?x?xf32> ```
|
||||
|
||||
The list of Vector is currently undergoing evolutions and is best kept track of
|
||||
by following the evolution of the
|
||||
[VectorOps.td](https://github.com/llvm/llvm-project/blob/main/mlir/include/mlir/Dialect/Vector/VectorOps.td)
|
||||
ODS file (markdown documentation is automatically generated locally when
|
||||
building and populates the [Vector
|
||||
doc](https://github.com/llvm/llvm-project/blob/main/mlir/docs/Dialects/Vector.md)). Recent
|
||||
extensions are driven by concrete use cases of interest. A notable such use
|
||||
case is the `vector.contract` op which applies principles of the StructuredOps
|
||||
abstraction to `vector` types.
|
||||
building and populates the
|
||||
[Vector doc](https://github.com/llvm/llvm-project/blob/main/mlir/docs/Dialects/Vector.md)).
|
||||
Recent extensions are driven by concrete use cases of interest. A notable such
|
||||
use case is the `vector.contract` op which applies principles of the
|
||||
StructuredOps abstraction to `vector` types.
|
||||
|
||||
### Virtual Vector Rewrite Patterns
|
||||
|
||||
The following rewrite patterns exist at the `VV->VV` level:
|
||||
|
||||
1. The now retired `MaterializeVector` pass used to legalize ops on a
|
||||
coarse-grained virtual `vector` to a finer-grained virtual `vector` by
|
||||
unrolling. This has been rewritten as a retargetable unroll-and-jam pattern on
|
||||
`vector` ops and `vector` types.
|
||||
2. The lowering of `vector_transfer` ops legalizes `vector` load/store ops to
|
||||
permuted loops over scalar load/stores. This should evolve to loops over
|
||||
`vector` load/stores + `mask` operations as they become available `vector` ops
|
||||
at the `VV` level.
|
||||
1. The now retired `MaterializeVector` pass used to legalize ops on a
|
||||
coarse-grained virtual `vector` to a finer-grained virtual `vector` by
|
||||
unrolling. This has been rewritten as a retargetable unroll-and-jam pattern
|
||||
on `vector` ops and `vector` types.
|
||||
2. The lowering of `vector_transfer` ops legalizes `vector` load/store ops to
|
||||
permuted loops over scalar load/stores. This should evolve to loops over
|
||||
`vector` load/stores + `mask` operations as they become available `vector`
|
||||
ops at the `VV` level.
|
||||
|
||||
The general direction is to add more Virtual Vector level ops and implement
|
||||
more useful `VV -> VV` rewrites as composable patterns that the PatternRewrite
|
||||
The general direction is to add more Virtual Vector level ops and implement more
|
||||
useful `VV -> VV` rewrites as composable patterns that the PatternRewrite
|
||||
infrastructure can apply iteratively.
|
||||
|
||||
### Virtual Vector to Hardware Vector Lowering
|
||||
For now, `VV -> HWV` are specified in C++ (see for instance the
|
||||
[SplatOpLowering for n-D
|
||||
vectors](https://github.com/tensorflow/mlir/commit/0a0c4867c6a6fcb0a2f17ef26a791c1d551fe33d)
|
||||
or the [VectorOuterProductOp
|
||||
lowering](https://github.com/tensorflow/mlir/commit/957b1ca9680b4aacabb3a480fbc4ebd2506334b8)).
|
||||
|
||||
Simple [conversion
|
||||
tests](https://github.com/llvm/llvm-project/blob/main/mlir/test/Conversion/VectorToLLVM/vector-to-llvm.mlir)
|
||||
For now, `VV -> HWV` are specified in C++ (see for instance the
|
||||
[SplatOpLowering for n-D vectors](https://github.com/tensorflow/mlir/commit/0a0c4867c6a6fcb0a2f17ef26a791c1d551fe33d)
|
||||
or the
|
||||
[VectorOuterProductOp lowering](https://github.com/tensorflow/mlir/commit/957b1ca9680b4aacabb3a480fbc4ebd2506334b8)).
|
||||
|
||||
Simple
|
||||
[conversion tests](https://github.com/llvm/llvm-project/blob/main/mlir/test/Conversion/VectorToLLVM/vector-to-llvm.mlir)
|
||||
are available for the `LLVM` target starting from the Virtual Vector Level.
|
||||
|
||||
## Rationale
|
||||
|
||||
### Hardware as `vector` Machines of Minimum Granularity
|
||||
|
||||
Higher-dimensional `vector`s are ubiquitous in modern HPC hardware. One way to
|
||||
think about Generic Retargetable `vector`-Level Dialect is that it operates on
|
||||
`vector` types that are multiples of a "good" `vector` size so the HW can
|
||||
efficiently implement a set of high-level primitives
|
||||
(e.g. `vector<8x8x8x16xf32>` when HW `vector` size is say `vector<4x8xf32>`).
|
||||
efficiently implement a set of high-level primitives (e.g.
|
||||
`vector<8x8x8x16xf32>` when HW `vector` size is say `vector<4x8xf32>`).
|
||||
|
||||
Some notable `vector` sizes of interest include:
|
||||
|
||||
1. CPU: `vector<HW_vector_size * k>`, `vector<core_count * k’ x
|
||||
HW_vector_size * k>` and `vector<socket_count x core_count * k’ x
|
||||
HW_vector_size * k>`
|
||||
2. GPU: `vector<warp_size * k>`, `vector<warp_size * k x float4>` and
|
||||
`vector<warp_size * k x 4 x 4 x 4>` for tensor_core sizes,
|
||||
3. Other accelerators: n-D `vector` as first-class citizens in the HW.
|
||||
1. CPU: `vector<HW_vector_size * k>`, `vector<core_count * k’ x
|
||||
HW_vector_size * k>` and `vector<socket_count x core_count * k’ x
|
||||
HW_vector_size * k>`
|
||||
2. GPU: `vector<warp_size * k>`, `vector<warp_size * k x float4>` and
|
||||
`vector<warp_size * k x 4 x 4 x 4>` for tensor_core sizes,
|
||||
3. Other accelerators: n-D `vector` as first-class citizens in the HW.
|
||||
|
||||
Depending on the target, ops on sizes that are not multiples of the HW
|
||||
`vector` size may either produce slow code (e.g. by going through `LLVM`
|
||||
legalization) or may not legalize at all (e.g. some unsupported accelerator X
|
||||
combination of ops and types).
|
||||
Depending on the target, ops on sizes that are not multiples of the HW `vector`
|
||||
size may either produce slow code (e.g. by going through `LLVM` legalization) or
|
||||
may not legalize at all (e.g. some unsupported accelerator X combination of ops
|
||||
and types).
|
||||
|
||||
### Transformations Problems Avoided
|
||||
|
||||
A `vector<16x32x64xf32>` virtual `vector` is a coarse-grained type that can be
|
||||
“unrolled” to HW-specific sizes. The multi-dimensional unrolling factors are
|
||||
carried in the IR by the `vector` type. After unrolling, traditional
|
||||
instruction-level scheduling can be run.
|
||||
|
||||
The following key transformations (along with the supporting analyses and
|
||||
structural constraints) are completely avoided by operating on a ``vector``
|
||||
structural constraints) are completely avoided by operating on a `vector`
|
||||
`ssa-value` abstraction:
|
||||
|
||||
1. Loop unroll and unroll-and-jam.
|
||||
2. Loop and load-store restructuring for register reuse.
|
||||
3. Load to store forwarding and Mem2reg.
|
||||
4. Coarsening (raising) from finer-grained `vector` form.
|
||||
1. Loop unroll and unroll-and-jam.
|
||||
2. Loop and load-store restructuring for register reuse.
|
||||
3. Load to store forwarding and Mem2reg.
|
||||
4. Coarsening (raising) from finer-grained `vector` form.
|
||||
|
||||
Note that “unrolling” in the context of `vector`s corresponds to partial loop
|
||||
unroll-and-jam and not full unrolling. As a consequence this is expected to
|
||||
|
|
@ -196,73 +198,71 @@ compose with SW pipelining where applicable and does not result in ICache blow
|
|||
up.
|
||||
|
||||
### The Big Out-Of-Scope Piece: Automatic Vectorization
|
||||
One important piece not discussed here is automatic vectorization
|
||||
(automatically raising from scalar to n-D `vector` ops and types). The TL;DR
|
||||
is that when the first "super-vectorization" prototype was implemented, MLIR
|
||||
was nowhere near as mature as it is today. As we continue building more
|
||||
abstractions in `VV -> HWV`, there is an opportunity to revisit vectorization
|
||||
in MLIR.
|
||||
|
||||
One important piece not discussed here is automatic vectorization (automatically
|
||||
raising from scalar to n-D `vector` ops and types). The TL;DR is that when the
|
||||
first "super-vectorization" prototype was implemented, MLIR was nowhere near as
|
||||
mature as it is today. As we continue building more abstractions in `VV -> HWV`,
|
||||
there is an opportunity to revisit vectorization in MLIR.
|
||||
|
||||
Since this topic touches on codegen abstractions, it is technically out of the
|
||||
scope of this survey document but there is a lot to discuss in light of
|
||||
structured op type representations and how a vectorization transformation can
|
||||
be reused across dialects. In particular, MLIR allows the definition of
|
||||
dialects at arbitrary levels of granularity and lends itself favorably to
|
||||
progressive lowering. The argument can be made that automatic vectorization on
|
||||
a loops + ops abstraction is akin to raising structural information that has
|
||||
been lost. Instead, it is possible to revisit vectorization as simple pattern
|
||||
rewrites, provided the IR is in a suitable form. For instance, vectorizing a
|
||||
`linalg.generic` op whose semantics match a `matmul` can be done [quite easily
|
||||
with a
|
||||
pattern](https://github.com/tensorflow/mlir/commit/bff722d6b59ab99b998f0c2b9fccd0267d9f93b5). In
|
||||
fact this pattern is trivial to generalize to any type of contraction when
|
||||
structured op type representations and how a vectorization transformation can be
|
||||
reused across dialects. In particular, MLIR allows the definition of dialects at
|
||||
arbitrary levels of granularity and lends itself favorably to progressive
|
||||
lowering. The argument can be made that automatic vectorization on a loops + ops
|
||||
abstraction is akin to raising structural information that has been lost.
|
||||
Instead, it is possible to revisit vectorization as simple pattern rewrites,
|
||||
provided the IR is in a suitable form. For instance, vectorizing a
|
||||
`linalg.generic` op whose semantics match a `matmul` can be done
|
||||
[quite easily with a pattern](https://github.com/tensorflow/mlir/commit/bff722d6b59ab99b998f0c2b9fccd0267d9f93b5).
|
||||
In fact this pattern is trivial to generalize to any type of contraction when
|
||||
targeting the `vector.contract` op, as well as to any field (`+/*`, `min/+`,
|
||||
`max/+`, `or/and`, `logsumexp/+` ...) . In other words, by operating on a
|
||||
higher level of generic abstractions than affine loops, non-trivial
|
||||
transformations become significantly simpler and composable at a finer
|
||||
granularity.
|
||||
`max/+`, `or/and`, `logsumexp/+` ...) . In other words, by operating on a higher
|
||||
level of generic abstractions than affine loops, non-trivial transformations
|
||||
become significantly simpler and composable at a finer granularity.
|
||||
|
||||
Irrespective of the existence of an auto-vectorizer, one can build a notional
|
||||
vector language based on the VectorOps dialect and build end-to-end models
|
||||
with expressing `vector`s in the IR directly and simple
|
||||
pattern-rewrites. [EDSC](https://github.com/llvm/llvm-project/blob/main/mlir/docs/EDSC.md)s
|
||||
vector language based on the VectorOps dialect and build end-to-end models with
|
||||
expressing `vector`s in the IR directly and simple pattern-rewrites.
|
||||
[EDSC](https://github.com/llvm/llvm-project/blob/main/mlir/docs/EDSC.md)s
|
||||
provide a simple way of driving such a notional language directly in C++.
|
||||
|
||||
## Bikeshed Naming Discussion
|
||||
There are arguments against naming an n-D level of abstraction `vector`
|
||||
because most people associate it with 1-D `vector`s. On the other hand,
|
||||
`vector`s are first-class n-D values in MLIR.
|
||||
The alternative name Tile has been proposed, which conveys higher-D
|
||||
meaning. But it also is one of the most overloaded terms in compilers and
|
||||
hardware.
|
||||
For now, we generally use the `n-D` `vector` name and are open to better
|
||||
suggestions.
|
||||
|
||||
There are arguments against naming an n-D level of abstraction `vector` because
|
||||
most people associate it with 1-D `vector`s. On the other hand, `vector`s are
|
||||
first-class n-D values in MLIR. The alternative name Tile has been proposed,
|
||||
which conveys higher-D meaning. But it also is one of the most overloaded terms
|
||||
in compilers and hardware. For now, we generally use the `n-D` `vector` name and
|
||||
are open to better suggestions.
|
||||
|
||||
## DeeperDive
|
||||
|
||||
This section describes the tradeoffs involved in lowering the MLIR n-D vector
|
||||
type and operations on it to LLVM-IR. Putting aside the [LLVM
|
||||
Matrix](http://lists.llvm.org/pipermail/llvm-dev/2018-October/126871.html)
|
||||
proposal for now, this assumes LLVM only has built-in support for 1-D
|
||||
vector. The relationship with the LLVM Matrix proposal is discussed at the end
|
||||
of this document.
|
||||
type and operations on it to LLVM-IR. Putting aside the
|
||||
[LLVM Matrix](http://lists.llvm.org/pipermail/llvm-dev/2018-October/126871.html)
|
||||
proposal for now, this assumes LLVM only has built-in support for 1-D vector.
|
||||
The relationship with the LLVM Matrix proposal is discussed at the end of this
|
||||
document.
|
||||
|
||||
MLIR does not currently support dynamic vector sizes (i.e. SVE style) so the
|
||||
discussion is limited to static rank and static vector sizes
|
||||
(e.g. `vector<4x8x16x32xf32>`). This section discusses operations on vectors
|
||||
in LLVM and MLIR.
|
||||
discussion is limited to static rank and static vector sizes (e.g.
|
||||
`vector<4x8x16x32xf32>`). This section discusses operations on vectors in LLVM
|
||||
and MLIR.
|
||||
|
||||
LLVM instructions are prefixed by the `llvm.` dialect prefix
|
||||
(e.g. `llvm.insertvalue`). Such ops operate exclusively on 1-D vectors and
|
||||
aggregates following the [LLVM LangRef](https://llvm.org/docs/LangRef.html).
|
||||
MLIR operations are prefixed by the `vector.` dialect prefix
|
||||
(e.g. `vector.insertelement`). Such ops operate exclusively on MLIR `n-D`
|
||||
`vector` types.
|
||||
LLVM instructions are prefixed by the `llvm.` dialect prefix (e.g.
|
||||
`llvm.insertvalue`). Such ops operate exclusively on 1-D vectors and aggregates
|
||||
following the [LLVM LangRef](https://llvm.org/docs/LangRef.html). MLIR
|
||||
operations are prefixed by the `vector.` dialect prefix (e.g.
|
||||
`vector.insertelement`). Such ops operate exclusively on MLIR `n-D` `vector`
|
||||
types.
|
||||
|
||||
### Alternatives For Lowering an n-D Vector Type to LLVM
|
||||
Consider a vector of rank n with static sizes `{s_0, ... s_{n-1}}` (i.e. an
|
||||
MLIR `vector<s_0x...s_{n-1}xf32>`). Lowering such an `n-D` MLIR vector type to
|
||||
an LLVM descriptor can be done by either:
|
||||
|
||||
Consider a vector of rank n with static sizes `{s_0, ... s_{n-1}}` (i.e. an MLIR
|
||||
`vector<s_0x...s_{n-1}xf32>`). Lowering such an `n-D` MLIR vector type to an
|
||||
LLVM descriptor can be done by either:
|
||||
|
||||
1. Flattening to a `1-D` vector: `!llvm<"(s_0*...*s_{n-1})xfloat">` in the MLIR
|
||||
LLVM dialect.
|
||||
|
|
@ -277,33 +277,26 @@ vector<4x8x16x32xf32> to vector<4x4096xf32>` operation, that flattens the most
|
|||
"k" minor dimensions.
|
||||
|
||||
### Constraints Inherited from LLVM (see LangRef)
|
||||
|
||||
The first constraint was already mentioned: LLVM only supports `1-D` `vector`
|
||||
types natively.
|
||||
Additional constraints are related to the difference in LLVM between vector
|
||||
and aggregate types:
|
||||
```
|
||||
“Aggregate Types are a subset of derived types that can contain multiple
|
||||
member types. Arrays and structs are aggregate types. Vectors are not
|
||||
considered to be aggregate types.”.
|
||||
```
|
||||
types natively. Additional constraints are related to the difference in LLVM
|
||||
between vector and aggregate types: `“Aggregate Types are a subset of derived
|
||||
types that can contain multiple member types. Arrays and structs are aggregate
|
||||
types. Vectors are not considered to be aggregate types.”.`
|
||||
|
||||
This distinction is also reflected in some of the operations. For `1-D`
|
||||
vectors, the operations `llvm.extractelement`, `llvm.insertelement`, and
|
||||
This distinction is also reflected in some of the operations. For `1-D` vectors,
|
||||
the operations `llvm.extractelement`, `llvm.insertelement`, and
|
||||
`llvm.shufflevector` apply, with direct support for dynamic indices. For `n-D`
|
||||
vectors with `n>1`, and thus aggregate types at LLVM level, the more
|
||||
restrictive operations `llvm.extractvalue` and `llvm.insertvalue` apply, which
|
||||
only accept static indices. There is no direct shuffling support for aggregate
|
||||
types.
|
||||
vectors with `n>1`, and thus aggregate types at LLVM level, the more restrictive
|
||||
operations `llvm.extractvalue` and `llvm.insertvalue` apply, which only accept
|
||||
static indices. There is no direct shuffling support for aggregate types.
|
||||
|
||||
The next sentence illustrates a recurrent tradeoff, also found in MLIR,
|
||||
between “value types” (subject to SSA use-def chains) and “memory types”
|
||||
(subject to aliasing and side-effects):
|
||||
```
|
||||
“Structures in memory are accessed using ‘load’ and ‘store’ by getting a
|
||||
pointer to a field with the llvm.getelementptr instruction. Structures in
|
||||
registers are accessed using the llvm.extractvalue and llvm.insertvalue
|
||||
instructions.”
|
||||
```
|
||||
The next sentence illustrates a recurrent tradeoff, also found in MLIR, between
|
||||
“value types” (subject to SSA use-def chains) and “memory types” (subject to
|
||||
aliasing and side-effects): `“Structures in memory are accessed using ‘load’ and
|
||||
‘store’ by getting a pointer to a field with the llvm.getelementptr instruction.
|
||||
Structures in registers are accessed using the llvm.extractvalue and
|
||||
llvm.insertvalue instructions.”`
|
||||
|
||||
When transposing this to MLIR, `llvm.getelementptr` works on pointers to `n-D`
|
||||
vectors in memory. For `n-D`, vectors values that live in registers we can use
|
||||
|
|
@ -320,175 +313,176 @@ model, execution on actual HW and what is visible or hidden from codegen. They
|
|||
are discussed in the following sections.
|
||||
|
||||
### Nested Aggregate
|
||||
|
||||
Pros:
|
||||
|
||||
1. Natural encoding n-D vector -> (n-1)-D aggregate over 1-D vector.
|
||||
2. No need for linearization / delinearization logic inserted everywhere.
|
||||
3. `llvm.insertvalue`, `llvm.extractvalue` of `(n-k)-D` aggregate is natural.
|
||||
4. `llvm.insertelement`, `llvm.extractelement`, `llvm.shufflevector` over
|
||||
`1-D` vector type is natural.
|
||||
1. Natural encoding n-D vector -> (n-1)-D aggregate over 1-D vector.
|
||||
2. No need for linearization / delinearization logic inserted everywhere.
|
||||
3. `llvm.insertvalue`, `llvm.extractvalue` of `(n-k)-D` aggregate is natural.
|
||||
4. `llvm.insertelement`, `llvm.extractelement`, `llvm.shufflevector` over `1-D`
|
||||
vector type is natural.
|
||||
|
||||
Cons:
|
||||
|
||||
1. `llvm.insertvalue` / `llvm.extractvalue` does not accept dynamic indices
|
||||
but only static ones.
|
||||
2. Dynamic indexing on the non-most-minor dimension requires roundtrips to
|
||||
memory.
|
||||
3. Special intrinsics and native instructions in LLVM operate on `1-D`
|
||||
vectors. This is not expected to be a practical limitation thanks to a
|
||||
`vector.cast %0: vector<4x8x16x32xf32> to vector<4x4096xf32>` operation, that
|
||||
flattens the most minor dimensions (see the bigger picture in implications on
|
||||
codegen).
|
||||
1. `llvm.insertvalue` / `llvm.extractvalue` does not accept dynamic indices but
|
||||
only static ones.
|
||||
2. Dynamic indexing on the non-most-minor dimension requires roundtrips to
|
||||
memory.
|
||||
3. Special intrinsics and native instructions in LLVM operate on `1-D` vectors.
|
||||
This is not expected to be a practical limitation thanks to a `vector.cast
|
||||
%0: vector<4x8x16x32xf32> to vector<4x4096xf32>` operation, that flattens
|
||||
the most minor dimensions (see the bigger picture in implications on
|
||||
codegen).
|
||||
|
||||
### Flattened 1-D Vector Type
|
||||
|
||||
Pros:
|
||||
|
||||
1. `insertelement` / `extractelement` / `shufflevector` with dynamic indexing
|
||||
is possible over the whole lowered `n-D` vector type.
|
||||
2. Supports special intrinsics and native operations.
|
||||
1. `insertelement` / `extractelement` / `shufflevector` with dynamic indexing
|
||||
is possible over the whole lowered `n-D` vector type.
|
||||
2. Supports special intrinsics and native operations.
|
||||
|
||||
Cons:
|
||||
1. Requires linearization/delinearization logic everywhere, translations are
|
||||
complex.
|
||||
2. Hides away the real HW structure behind dynamic indexing: at the end of the
|
||||
day, HW vector sizes are generally fixed and multiple vectors will be needed
|
||||
to hold a vector that is larger than the HW.
|
||||
3. Unlikely peephole optimizations will result in good code: arbitrary dynamic
|
||||
accesses, especially at HW vector boundaries unlikely to result in regular
|
||||
patterns.
|
||||
Cons: 1. Requires linearization/delinearization logic everywhere, translations
|
||||
are complex. 2. Hides away the real HW structure behind dynamic indexing: at the
|
||||
end of the day, HW vector sizes are generally fixed and multiple vectors will be
|
||||
needed to hold a vector that is larger than the HW. 3. Unlikely peephole
|
||||
optimizations will result in good code: arbitrary dynamic accesses, especially
|
||||
at HW vector boundaries unlikely to result in regular patterns.
|
||||
|
||||
### Discussion
|
||||
|
||||
#### HW Vectors and Implications on the SW and the Programming Model
|
||||
|
||||
As of today, the LLVM model only support `1-D` vector types. This is
|
||||
unsurprising because historically, the vast majority of HW only supports `1-D`
|
||||
vector registers. We note that multiple HW vendors are in the process of
|
||||
evolving to higher-dimensional physical vectors.
|
||||
|
||||
In the following discussion, let's assume the HW vector size is `1-D` and the
|
||||
SW vector size is `n-D`, with `n >= 1`. The same discussion would apply with
|
||||
`2-D` HW `vector` size and `n >= 2`. In this context, most HW exhibit a vector
|
||||
register file. The number of such vectors is fixed.
|
||||
Depending on the rank and sizes of the SW vector abstraction and the HW vector
|
||||
sizes and number of registers, an `n-D` SW vector type may be materialized by
|
||||
a mix of multiple `1-D` HW vector registers + memory locations at a given
|
||||
point in time.
|
||||
In the following discussion, let's assume the HW vector size is `1-D` and the SW
|
||||
vector size is `n-D`, with `n >= 1`. The same discussion would apply with `2-D`
|
||||
HW `vector` size and `n >= 2`. In this context, most HW exhibit a vector
|
||||
register file. The number of such vectors is fixed. Depending on the rank and
|
||||
sizes of the SW vector abstraction and the HW vector sizes and number of
|
||||
registers, an `n-D` SW vector type may be materialized by a mix of multiple
|
||||
`1-D` HW vector registers + memory locations at a given point in time.
|
||||
|
||||
The implication of the physical HW constraints on the programming model are
|
||||
that one cannot index dynamically across hardware registers: a register file
|
||||
can generally not be indexed dynamically. This is because the register number
|
||||
is fixed and one either needs to unroll explicitly to obtain fixed register
|
||||
numbers or go through memory. This is a constraint familiar to CUDA
|
||||
programmers: when declaring a `private float a[4]`; and subsequently indexing
|
||||
with a *dynamic* value results in so-called **local memory** usage
|
||||
(i.e. roundtripping to memory).
|
||||
The implication of the physical HW constraints on the programming model are that
|
||||
one cannot index dynamically across hardware registers: a register file can
|
||||
generally not be indexed dynamically. This is because the register number is
|
||||
fixed and one either needs to unroll explicitly to obtain fixed register numbers
|
||||
or go through memory. This is a constraint familiar to CUDA programmers: when
|
||||
declaring a `private float a[4]`; and subsequently indexing with a *dynamic*
|
||||
value results in so-called **local memory** usage (i.e. roundtripping to
|
||||
memory).
|
||||
|
||||
#### Implication on codegen
|
||||
|
||||
MLIR `n-D` vector types are currently represented as `(n-1)-D` arrays of `1-D`
|
||||
vectors when lowered to LLVM.
|
||||
This introduces the consequences on static vs dynamic indexing discussed
|
||||
previously: `extractelement`, `insertelement` and `shufflevector` on `n-D`
|
||||
vectors in MLIR only support static indices. Dynamic indices are only
|
||||
supported on the most minor `1-D` vector but not the outer `(n-1)-D`.
|
||||
For other cases, explicit load / stores are required.
|
||||
vectors when lowered to LLVM. This introduces the consequences on static vs
|
||||
dynamic indexing discussed previously: `extractelement`, `insertelement` and
|
||||
`shufflevector` on `n-D` vectors in MLIR only support static indices. Dynamic
|
||||
indices are only supported on the most minor `1-D` vector but not the outer
|
||||
`(n-1)-D`. For other cases, explicit load / stores are required.
|
||||
|
||||
The implications on codegen are as follows:
|
||||
|
||||
1. Loops around `vector` values are indirect addressing of vector values, they
|
||||
must operate on explicit load / store operations over `n-D` vector types.
|
||||
2. Once an `n-D` `vector` type is loaded into an SSA value (that may or may
|
||||
not live in `n` registers, with or without spilling, when eventually lowered),
|
||||
it may be unrolled to smaller `k-D` `vector` types and operations that
|
||||
correspond to the HW. This level of MLIR codegen is related to register
|
||||
allocation and spilling that occur much later in the LLVM pipeline.
|
||||
3. HW may support >1-D vectors with intrinsics for indirect addressing within
|
||||
these vectors. These can be targeted thanks to explicit `vector_cast`
|
||||
operations from MLIR `k-D` vector types and operations to LLVM `1-D` vectors +
|
||||
intrinsics.
|
||||
1. Loops around `vector` values are indirect addressing of vector values, they
|
||||
must operate on explicit load / store operations over `n-D` vector types.
|
||||
2. Once an `n-D` `vector` type is loaded into an SSA value (that may or may not
|
||||
live in `n` registers, with or without spilling, when eventually lowered),
|
||||
it may be unrolled to smaller `k-D` `vector` types and operations that
|
||||
correspond to the HW. This level of MLIR codegen is related to register
|
||||
allocation and spilling that occur much later in the LLVM pipeline.
|
||||
3. HW may support >1-D vectors with intrinsics for indirect addressing within
|
||||
these vectors. These can be targeted thanks to explicit `vector_cast`
|
||||
operations from MLIR `k-D` vector types and operations to LLVM `1-D`
|
||||
vectors + intrinsics.
|
||||
|
||||
Alternatively, we argue that directly lowering to a linearized abstraction
|
||||
hides away the codegen complexities related to memory accesses by giving a
|
||||
false impression of magical dynamic indexing across registers. Instead we
|
||||
prefer to make those very explicit in MLIR and allow codegen to explore
|
||||
tradeoffs.
|
||||
Different HW will require different tradeoffs in the sizes involved in steps
|
||||
1., 2. and 3.
|
||||
Alternatively, we argue that directly lowering to a linearized abstraction hides
|
||||
away the codegen complexities related to memory accesses by giving a false
|
||||
impression of magical dynamic indexing across registers. Instead we prefer to
|
||||
make those very explicit in MLIR and allow codegen to explore tradeoffs.
|
||||
Different HW will require different tradeoffs in the sizes involved in steps 1.,
|
||||
2. and 3.
|
||||
|
||||
Decisions made at the MLIR level will have implications at a much later stage
|
||||
in LLVM (after register allocation). We do not envision to expose concerns
|
||||
related to modeling of register allocation and spilling to MLIR
|
||||
explicitly. Instead, each target will expose a set of "good" target operations
|
||||
and `n-D` vector types, associated with costs that `PatterRewriters` at the
|
||||
MLIR level will be able to target. Such costs at the MLIR level will be
|
||||
abstract and used for ranking, not for accurate performance modeling. In the
|
||||
future such costs will be learned.
|
||||
Decisions made at the MLIR level will have implications at a much later stage in
|
||||
LLVM (after register allocation). We do not envision to expose concerns related
|
||||
to modeling of register allocation and spilling to MLIR explicitly. Instead,
|
||||
each target will expose a set of "good" target operations and `n-D` vector
|
||||
types, associated with costs that `PatterRewriters` at the MLIR level will be
|
||||
able to target. Such costs at the MLIR level will be abstract and used for
|
||||
ranking, not for accurate performance modeling. In the future such costs will be
|
||||
learned.
|
||||
|
||||
#### Implication on Lowering to Accelerators
|
||||
To target accelerators that support higher dimensional vectors natively, we
|
||||
can start from either `1-D` or `n-D` vectors in MLIR and use `vector.cast` to
|
||||
|
||||
To target accelerators that support higher dimensional vectors natively, we can
|
||||
start from either `1-D` or `n-D` vectors in MLIR and use `vector.cast` to
|
||||
flatten the most minor dimensions to `1-D` `vector<Kxf32>` where `K` is an
|
||||
appropriate constant. Then, the existing lowering to LLVM-IR immediately
|
||||
applies, with extensions for accelerator-specific intrinsics.
|
||||
|
||||
It is the role of an Accelerator-specific vector dialect (see codegen flow in
|
||||
the figure above) to lower the `vector.cast`. Accelerator -> LLVM lowering
|
||||
would then consist of a bunch of `Accelerator -> Accelerator` rewrites to
|
||||
perform the casts composed with `Accelerator -> LLVM` conversions + intrinsics
|
||||
that operate on `1-D` `vector<Kxf32>`.
|
||||
the figure above) to lower the `vector.cast`. Accelerator -> LLVM lowering would
|
||||
then consist of a bunch of `Accelerator -> Accelerator` rewrites to perform the
|
||||
casts composed with `Accelerator -> LLVM` conversions + intrinsics that operate
|
||||
on `1-D` `vector<Kxf32>`.
|
||||
|
||||
Some of those rewrites may need extra handling, especially if a reduction is
|
||||
involved. For example, `vector.cast %0: vector<K1x...xKnxf32> to
|
||||
vector<Kxf32>` when `K != K1 * … * Kn` and some arbitrary irregular
|
||||
`vector.cast %0: vector<4x4x17xf32> to vector<Kxf32>` may introduce masking
|
||||
and intra-vector shuffling that may not be worthwhile or even feasible,
|
||||
i.e. infinite cost.
|
||||
involved. For example, `vector.cast %0: vector<K1x...xKnxf32> to vector<Kxf32>`
|
||||
when `K != K1 * … * Kn` and some arbitrary irregular `vector.cast %0:
|
||||
vector<4x4x17xf32> to vector<Kxf32>` may introduce masking and intra-vector
|
||||
shuffling that may not be worthwhile or even feasible, i.e. infinite cost.
|
||||
|
||||
However `vector.cast %0: vector<K1x...xKnxf32> to vector<Kxf32>` when `K =
|
||||
K1 * … * Kn` should be close to a noop.
|
||||
However `vector.cast %0: vector<K1x...xKnxf32> to vector<Kxf32>` when `K = K1 *
|
||||
… * Kn` should be close to a noop.
|
||||
|
||||
As we start building accelerator-specific abstractions, we hope to achieve
|
||||
retargetable codegen: the same infra is used for CPU, GPU and accelerators
|
||||
with extra MLIR patterns and costs.
|
||||
retargetable codegen: the same infra is used for CPU, GPU and accelerators with
|
||||
extra MLIR patterns and costs.
|
||||
|
||||
#### Implication on calling external functions that operate on vectors
|
||||
|
||||
It is possible (likely) that we additionally need to linearize when calling an
|
||||
external function.
|
||||
|
||||
### Relationship to LLVM matrix type proposal.
|
||||
|
||||
The LLVM matrix proposal was formulated 1 year ago but seemed to be somewhat
|
||||
stalled until recently. In its current form, it is limited to 2-D matrix types
|
||||
and operations are implemented with LLVM intrinsics.
|
||||
In contrast, MLIR sits at a higher level of abstraction and allows the
|
||||
lowering of generic operations on generic n-D vector types from MLIR to
|
||||
aggregates of 1-D LLVM vectors.
|
||||
In the future, it could make sense to lower to the LLVM matrix abstraction
|
||||
also for CPU even though MLIR will continue needing higher level abstractions.
|
||||
and operations are implemented with LLVM intrinsics. In contrast, MLIR sits at a
|
||||
higher level of abstraction and allows the lowering of generic operations on
|
||||
generic n-D vector types from MLIR to aggregates of 1-D LLVM vectors. In the
|
||||
future, it could make sense to lower to the LLVM matrix abstraction also for CPU
|
||||
even though MLIR will continue needing higher level abstractions.
|
||||
|
||||
On the other hand, one should note that as MLIR is moving to LLVM, this
|
||||
document could become the unifying abstraction that people should target for
|
||||
>1-D vectors and the LLVM matrix proposal can be viewed as a subset of this
|
||||
work.
|
||||
On the other hand, one should note that as MLIR is moving to LLVM, this document
|
||||
could become the unifying abstraction that people should target for
|
||||
|
||||
> 1-D vectors and the LLVM matrix proposal can be viewed as a subset of this
|
||||
> work.
|
||||
|
||||
### Conclusion
|
||||
|
||||
The flattened 1-D vector design in the LLVM matrix proposal is good in a
|
||||
HW-specific world with special intrinsics. This is a good abstraction for
|
||||
register allocation, Instruction-Level-Parallelism and
|
||||
SoftWare-Pipelining/Modulo Scheduling optimizations at the register level.
|
||||
However MLIR codegen operates at a higher level of abstraction where we want
|
||||
to target operations on coarser-grained vectors than the HW size and on which
|
||||
However MLIR codegen operates at a higher level of abstraction where we want to
|
||||
target operations on coarser-grained vectors than the HW size and on which
|
||||
unroll-and-jam is applied and patterns across multiple HW vectors can be
|
||||
matched.
|
||||
|
||||
This makes “nested aggregate type of 1-D vector” an appealing abstraction for
|
||||
lowering from MLIR because:
|
||||
|
||||
1. it does not hide complexity related to the buffer vs value semantics and
|
||||
the memory subsystem and
|
||||
2. it does not rely on LLVM to magically make all the things work from a too
|
||||
low-level abstraction.
|
||||
1. it does not hide complexity related to the buffer vs value semantics and the
|
||||
memory subsystem and
|
||||
2. it does not rely on LLVM to magically make all the things work from a too
|
||||
low-level abstraction.
|
||||
|
||||
The use of special intrinsics in a `1-D` LLVM world is still available thanks
|
||||
to an explicit `vector.cast` op.
|
||||
The use of special intrinsics in a `1-D` LLVM world is still available thanks to
|
||||
an explicit `vector.cast` op.
|
||||
|
||||
## Operations
|
||||
|
||||
|
|
|
|||
|
|
@ -1,35 +1,37 @@
|
|||
The EmitC dialect allows to convert operations from other MLIR dialects to
|
||||
EmitC ops. Those can be translated to C/C++ via the Cpp emitter.
|
||||
The EmitC dialect allows to convert operations from other MLIR dialects to EmitC
|
||||
ops. Those can be translated to C/C++ via the Cpp emitter.
|
||||
|
||||
The following convention is followed:
|
||||
|
||||
* If template arguments are passed to an `emitc.call` operation,
|
||||
C++ is generated.
|
||||
* If tensors are used, C++ is generated.
|
||||
* If multiple return values are used within in a functions or an
|
||||
`emitc.call` operation, C++11 is required.
|
||||
* If floating-point type template arguments are passed to an `emitc.call`
|
||||
operation, C++20 is required.
|
||||
* Else the generated code is compatible with C99.
|
||||
* If template arguments are passed to an `emitc.call` operation, C++ is
|
||||
generated.
|
||||
* If tensors are used, C++ is generated.
|
||||
* If multiple return values are used within in a functions or an `emitc.call`
|
||||
operation, C++11 is required.
|
||||
* If floating-point type template arguments are passed to an `emitc.call`
|
||||
operation, C++20 is required.
|
||||
* Else the generated code is compatible with C99.
|
||||
|
||||
These restrictions are neither inherent to the EmitC dialect itself nor to the
|
||||
Cpp emitter and therefore need to be considered while implementing conversions.
|
||||
|
||||
After the conversion, C/C++ code can be emitted with `mlir-translate`. The tool
|
||||
supports translating MLIR to C/C++ by passing `-mlir-to-cpp`.
|
||||
Furthermore, code with variables declared at top can be generated by passing
|
||||
the additional argument `-declare-variables-at-top`.
|
||||
supports translating MLIR to C/C++ by passing `-mlir-to-cpp`. Furthermore, code
|
||||
with variables declared at top can be generated by passing the additional
|
||||
argument `-declare-variables-at-top`.
|
||||
|
||||
Besides operations part of the EmitC dialect, the Cpp targets supports
|
||||
translating the following operations:
|
||||
|
||||
* 'std' Dialect
|
||||
* `std.br`
|
||||
* `std.call`
|
||||
* `std.cond_br`
|
||||
* `std.constant`
|
||||
* `std.return`
|
||||
* 'scf' Dialect
|
||||
* `scf.for`
|
||||
* `scf.if`
|
||||
* `scf.yield`
|
||||
* 'std' Dialect
|
||||
* `std.br`
|
||||
* `std.call`
|
||||
* `std.cond_br`
|
||||
* `std.constant`
|
||||
* `std.return`
|
||||
* 'scf' Dialect
|
||||
* `scf.for`
|
||||
* `scf.if`
|
||||
* `scf.yield`
|
||||
* 'arith' Dialect
|
||||
* 'arith.constant'
|
||||
|
|
|
|||
|
|
@ -11,17 +11,17 @@ data parallel systems. Beyond its representational capabilities, its single
|
|||
continuous design provides a framework to lower from dataflow graphs to
|
||||
high-performance target-specific code.
|
||||
|
||||
This document defines and describes the key concepts in MLIR, and is intended
|
||||
to be a dry reference document - the [rationale
|
||||
documentation](Rationale/Rationale.md),
|
||||
This document defines and describes the key concepts in MLIR, and is intended to
|
||||
be a dry reference document - the
|
||||
[rationale documentation](Rationale/Rationale.md),
|
||||
[glossary](../getting_started/Glossary.md), and other content are hosted
|
||||
elsewhere.
|
||||
|
||||
MLIR is designed to be used in three different forms: a human-readable textual
|
||||
form suitable for debugging, an in-memory form suitable for programmatic
|
||||
transformations and analysis, and a compact serialized form suitable for
|
||||
storage and transport. The different forms all describe the same semantic
|
||||
content. This document describes the human-readable textual form.
|
||||
transformations and analysis, and a compact serialized form suitable for storage
|
||||
and transport. The different forms all describe the same semantic content. This
|
||||
document describes the human-readable textual form.
|
||||
|
||||
[TOC]
|
||||
|
||||
|
|
@ -29,34 +29,31 @@ content. This document describes the human-readable textual form.
|
|||
|
||||
MLIR is fundamentally based on a graph-like data structure of nodes, called
|
||||
*Operations*, and edges, called *Values*. Each Value is the result of exactly
|
||||
one Operation or Block Argument, and has a *Value Type* defined by the [type
|
||||
system](#type-system). [Operations](#operations) are contained in
|
||||
one Operation or Block Argument, and has a *Value Type* defined by the
|
||||
[type system](#type-system). [Operations](#operations) are contained in
|
||||
[Blocks](#blocks) and Blocks are contained in [Regions](#regions). Operations
|
||||
are also ordered within their containing block and Blocks are ordered in their
|
||||
containing region, although this order may or may not be semantically
|
||||
meaningful in a given [kind of region](Interfaces.md/#regionkindinterfaces)).
|
||||
Operations may also contain regions, enabling hierarchical structures to be
|
||||
represented.
|
||||
containing region, although this order may or may not be semantically meaningful
|
||||
in a given [kind of region](Interfaces.md/#regionkindinterfaces)). Operations
|
||||
may also contain regions, enabling hierarchical structures to be represented.
|
||||
|
||||
Operations can represent many different concepts, from higher-level concepts
|
||||
like function definitions, function calls, buffer allocations, view or slices
|
||||
of buffers, and process creation, to lower-level concepts like
|
||||
target-independent arithmetic, target-specific instructions, configuration
|
||||
registers, and logic gates. These different concepts are represented by
|
||||
different operations in MLIR and the set of operations usable in MLIR can be
|
||||
arbitrarily extended.
|
||||
like function definitions, function calls, buffer allocations, view or slices of
|
||||
buffers, and process creation, to lower-level concepts like target-independent
|
||||
arithmetic, target-specific instructions, configuration registers, and logic
|
||||
gates. These different concepts are represented by different operations in MLIR
|
||||
and the set of operations usable in MLIR can be arbitrarily extended.
|
||||
|
||||
MLIR also provides an extensible framework for transformations on operations,
|
||||
using familiar concepts of compiler [Passes](Passes.md). Enabling an arbitrary
|
||||
set of passes on an arbitrary set of operations results in a significant
|
||||
scaling challenge, since each transformation must potentially take into
|
||||
account the semantics of any operation. MLIR addresses this complexity by
|
||||
allowing operation semantics to be described abstractly using
|
||||
[Traits](Traits.md) and [Interfaces](Interfaces.md), enabling transformations
|
||||
to operate on operations more generically. Traits often describe verification
|
||||
constraints on valid IR, enabling complex invariants to be captured and
|
||||
checked. (see [Op vs
|
||||
Operation](Tutorials/Toy/Ch-2.md/#op-vs-operation-using-mlir-operations))
|
||||
set of passes on an arbitrary set of operations results in a significant scaling
|
||||
challenge, since each transformation must potentially take into account the
|
||||
semantics of any operation. MLIR addresses this complexity by allowing operation
|
||||
semantics to be described abstractly using [Traits](Traits.md) and
|
||||
[Interfaces](Interfaces.md), enabling transformations to operate on operations
|
||||
more generically. Traits often describe verification constraints on valid IR,
|
||||
enabling complex invariants to be captured and checked. (see
|
||||
[Op vs Operation](Tutorials/Toy/Ch-2.md/#op-vs-operation-using-mlir-operations))
|
||||
|
||||
One obvious application of MLIR is to represent an
|
||||
[SSA-based](https://en.wikipedia.org/wiki/Static_single_assignment_form) IR,
|
||||
|
|
@ -76,26 +73,26 @@ Here's an example of an MLIR module:
|
|||
// known. The shapes are assumed to match.
|
||||
func @mul(%A: tensor<100x?xf32>, %B: tensor<?x50xf32>) -> (tensor<100x50xf32>) {
|
||||
// Compute the inner dimension of %A using the dim operation.
|
||||
%n = dim %A, 1 : tensor<100x?xf32>
|
||||
%n = memref.dim %A, 1 : tensor<100x?xf32>
|
||||
|
||||
// Allocate addressable "buffers" and copy tensors %A and %B into them.
|
||||
%A_m = alloc(%n) : memref<100x?xf32>
|
||||
tensor_store %A to %A_m : memref<100x?xf32>
|
||||
%A_m = memref.alloc(%n) : memref<100x?xf32>
|
||||
memref.tensor_store %A to %A_m : memref<100x?xf32>
|
||||
|
||||
%B_m = alloc(%n) : memref<?x50xf32>
|
||||
tensor_store %B to %B_m : memref<?x50xf32>
|
||||
%B_m = memref.alloc(%n) : memref<?x50xf32>
|
||||
memref.tensor_store %B to %B_m : memref<?x50xf32>
|
||||
|
||||
// Call function @multiply passing memrefs as arguments,
|
||||
// and getting returned the result of the multiplication.
|
||||
%C_m = call @multiply(%A_m, %B_m)
|
||||
: (memref<100x?xf32>, memref<?x50xf32>) -> (memref<100x50xf32>)
|
||||
|
||||
dealloc %A_m : memref<100x?xf32>
|
||||
dealloc %B_m : memref<?x50xf32>
|
||||
memref.dealloc %A_m : memref<100x?xf32>
|
||||
memref.dealloc %B_m : memref<?x50xf32>
|
||||
|
||||
// Load the buffer data into a higher level "tensor" value.
|
||||
%C = tensor_load %C_m : memref<100x50xf32>
|
||||
dealloc %C_m : memref<100x50xf32>
|
||||
%C = memref.tensor_load %C_m : memref<100x50xf32>
|
||||
memref.dealloc %C_m : memref<100x50xf32>
|
||||
|
||||
// Call TensorFlow built-in function to print the result tensor.
|
||||
"tf.Print"(%C){message: "mul result"}
|
||||
|
|
@ -108,22 +105,22 @@ func @mul(%A: tensor<100x?xf32>, %B: tensor<?x50xf32>) -> (tensor<100x50xf32>) {
|
|||
func @multiply(%A: memref<100x?xf32>, %B: memref<?x50xf32>)
|
||||
-> (memref<100x50xf32>) {
|
||||
// Compute the inner dimension of %A.
|
||||
%n = dim %A, 1 : memref<100x?xf32>
|
||||
%n = memref.dim %A, 1 : memref<100x?xf32>
|
||||
|
||||
// Allocate memory for the multiplication result.
|
||||
%C = alloc() : memref<100x50xf32>
|
||||
%C = memref.alloc() : memref<100x50xf32>
|
||||
|
||||
// Multiplication loop nest.
|
||||
affine.for %i = 0 to 100 {
|
||||
affine.for %j = 0 to 50 {
|
||||
store 0 to %C[%i, %j] : memref<100x50xf32>
|
||||
memref.store 0 to %C[%i, %j] : memref<100x50xf32>
|
||||
affine.for %k = 0 to %n {
|
||||
%a_v = load %A[%i, %k] : memref<100x?xf32>
|
||||
%b_v = load %B[%k, %j] : memref<?x50xf32>
|
||||
%prod = mulf %a_v, %b_v : f32
|
||||
%c_v = load %C[%i, %j] : memref<100x50xf32>
|
||||
%sum = addf %c_v, %prod : f32
|
||||
store %sum, %C[%i, %j] : memref<100x50xf32>
|
||||
%a_v = memref.load %A[%i, %k] : memref<100x?xf32>
|
||||
%b_v = memref.load %B[%k, %j] : memref<?x50xf32>
|
||||
%prod = arith.mulf %a_v, %b_v : f32
|
||||
%c_v = memref.load %C[%i, %j] : memref<100x50xf32>
|
||||
%sum = arith.addf %c_v, %prod : f32
|
||||
memref.store %sum, %C[%i, %j] : memref<100x50xf32>
|
||||
}
|
||||
}
|
||||
}
|
||||
|
|
@ -134,9 +131,9 @@ func @multiply(%A: memref<100x?xf32>, %B: memref<?x50xf32>)
|
|||
## Notation
|
||||
|
||||
MLIR has a simple and unambiguous grammar, allowing it to reliably round-trip
|
||||
through a textual form. This is important for development of the compiler -
|
||||
e.g. for understanding the state of code as it is being transformed and
|
||||
writing test cases.
|
||||
through a textual form. This is important for development of the compiler - e.g.
|
||||
for understanding the state of code as it is being transformed and writing test
|
||||
cases.
|
||||
|
||||
This document describes the grammar using
|
||||
[Extended Backus-Naur Form (EBNF)](https://en.wikipedia.org/wiki/Extended_Backus%E2%80%93Naur_form).
|
||||
|
|
@ -201,12 +198,12 @@ value-use ::= value-id
|
|||
value-use-list ::= value-use (`,` value-use)*
|
||||
```
|
||||
|
||||
Identifiers name entities such as values, types and functions, and are
|
||||
chosen by the writer of MLIR code. Identifiers may be descriptive (e.g.
|
||||
`%batch_size`, `@matmul`), or may be non-descriptive when they are
|
||||
auto-generated (e.g. `%23`, `@func42`). Identifier names for values may be
|
||||
used in an MLIR text file but are not persisted as part of the IR - the printer
|
||||
will give them anonymous names like `%42`.
|
||||
Identifiers name entities such as values, types and functions, and are chosen by
|
||||
the writer of MLIR code. Identifiers may be descriptive (e.g. `%batch_size`,
|
||||
`@matmul`), or may be non-descriptive when they are auto-generated (e.g. `%23`,
|
||||
`@func42`). Identifier names for values may be used in an MLIR text file but are
|
||||
not persisted as part of the IR - the printer will give them anonymous names
|
||||
like `%42`.
|
||||
|
||||
MLIR guarantees identifiers never collide with keywords by prefixing identifiers
|
||||
with a sigil (e.g. `%`, `#`, `@`, `^`, `!`). In certain unambiguous contexts
|
||||
|
|
@ -214,22 +211,20 @@ with a sigil (e.g. `%`, `#`, `@`, `^`, `!`). In certain unambiguous contexts
|
|||
keywords may be added to future versions of MLIR without danger of collision
|
||||
with existing identifiers.
|
||||
|
||||
Value identifiers are only [in scope](#value-scoping) for the (nested)
|
||||
region in which they are defined and cannot be accessed or referenced
|
||||
outside of that region. Argument identifiers in mapping functions are
|
||||
in scope for the mapping body. Particular operations may further limit
|
||||
which identifiers are in scope in their regions. For instance, the
|
||||
scope of values in a region with [SSA control flow
|
||||
semantics](#control-flow-and-ssacfg-regions) is constrained according
|
||||
to the standard definition of [SSA
|
||||
dominance](https://en.wikipedia.org/wiki/Dominator_\(graph_theory\)). Another
|
||||
example is the [IsolatedFromAbove trait](Traits.md/#isolatedfromabove),
|
||||
which restricts directly accessing values defined in containing
|
||||
regions.
|
||||
Value identifiers are only [in scope](#value-scoping) for the (nested) region in
|
||||
which they are defined and cannot be accessed or referenced outside of that
|
||||
region. Argument identifiers in mapping functions are in scope for the mapping
|
||||
body. Particular operations may further limit which identifiers are in scope in
|
||||
their regions. For instance, the scope of values in a region with
|
||||
[SSA control flow semantics](#control-flow-and-ssacfg-regions) is constrained
|
||||
according to the standard definition of
|
||||
[SSA dominance](https://en.wikipedia.org/wiki/Dominator_\(graph_theory\)).
|
||||
Another example is the [IsolatedFromAbove trait](Traits.md/#isolatedfromabove),
|
||||
which restricts directly accessing values defined in containing regions.
|
||||
|
||||
Function identifiers and mapping identifiers are associated with
|
||||
[Symbols](SymbolsAndSymbolTables.md) and have scoping rules dependent on
|
||||
symbol attributes.
|
||||
[Symbols](SymbolsAndSymbolTables.md) and have scoping rules dependent on symbol
|
||||
attributes.
|
||||
|
||||
## Dialects
|
||||
|
||||
|
|
@ -260,9 +255,9 @@ Dialects provide a modular way in which targets can expose target-specific
|
|||
operations directly through to MLIR. As an example, some targets go through
|
||||
LLVM. LLVM has a rich set of intrinsics for certain target-independent
|
||||
operations (e.g. addition with overflow check) as well as providing access to
|
||||
target-specific operations for the targets it supports (e.g. vector
|
||||
permutation operations). LLVM intrinsics in MLIR are represented via
|
||||
operations that start with an "llvm." name.
|
||||
target-specific operations for the targets it supports (e.g. vector permutation
|
||||
operations). LLVM intrinsics in MLIR are represented via operations that start
|
||||
with an "llvm." name.
|
||||
|
||||
Example:
|
||||
|
||||
|
|
@ -293,21 +288,21 @@ dictionary-attribute ::= `{` (attribute-entry (`,` attribute-entry)*)? `}`
|
|||
trailing-location ::= (`loc` `(` location `)`)?
|
||||
```
|
||||
|
||||
MLIR introduces a uniform concept called _operations_ to enable describing
|
||||
many different levels of abstractions and computations. Operations in MLIR are
|
||||
fully extensible (there is no fixed list of operations) and have
|
||||
application-specific semantics. For example, MLIR supports [target-independent
|
||||
operations](Dialects/Standard.md#memory-operations), [affine
|
||||
operations](Dialects/Affine.md), and [target-specific machine
|
||||
operations](#target-specific-operations).
|
||||
MLIR introduces a uniform concept called *operations* to enable describing many
|
||||
different levels of abstractions and computations. Operations in MLIR are fully
|
||||
extensible (there is no fixed list of operations) and have application-specific
|
||||
semantics. For example, MLIR supports
|
||||
[target-independent operations](Dialects/Standard.md#memory-operations),
|
||||
[affine operations](Dialects/Affine.md), and
|
||||
[target-specific machine operations](#target-specific-operations).
|
||||
|
||||
The internal representation of an operation is simple: an operation is
|
||||
identified by a unique string (e.g. `dim`, `tf.Conv2d`, `x86.repmovsb`,
|
||||
`ppc.eieio`, etc), can return zero or more results, take zero or more
|
||||
operands, has a dictionary of [attributes](#attributes), has zero or more
|
||||
successors, and zero or more enclosed [regions](#regions). The generic printing
|
||||
form includes all these elements literally, with a function type to indicate the
|
||||
types of the results and operands.
|
||||
`ppc.eieio`, etc), can return zero or more results, take zero or more operands,
|
||||
has a dictionary of [attributes](#attributes), has zero or more successors, and
|
||||
zero or more enclosed [regions](#regions). The generic printing form includes
|
||||
all these elements literally, with a function type to indicate the types of the
|
||||
results and operands.
|
||||
|
||||
Example:
|
||||
|
||||
|
|
@ -325,7 +320,7 @@ Example:
|
|||
```
|
||||
|
||||
In addition to the basic syntax above, dialects may register known operations.
|
||||
This allows those dialects to support _custom assembly form_ for parsing and
|
||||
This allows those dialects to support *custom assembly form* for parsing and
|
||||
printing operations. In the operation sets listed below, we show both forms.
|
||||
|
||||
### Builtin Operations
|
||||
|
|
@ -352,27 +347,27 @@ value-id-and-type-list ::= value-id-and-type (`,` value-id-and-type)*
|
|||
block-arg-list ::= `(` value-id-and-type-list? `)`
|
||||
```
|
||||
|
||||
A *Block* is a list of operations. In [SSACFG
|
||||
regions](#control-flow-and-ssacfg-regions), each block represents a compiler
|
||||
[basic block](https://en.wikipedia.org/wiki/Basic_block) where instructions
|
||||
inside the block are executed in order and terminator operations implement
|
||||
control flow branches between basic blocks.
|
||||
A *Block* is a list of operations. In
|
||||
[SSACFG regions](#control-flow-and-ssacfg-regions), each block represents a
|
||||
compiler [basic block](https://en.wikipedia.org/wiki/Basic_block) where
|
||||
instructions inside the block are executed in order and terminator operations
|
||||
implement control flow branches between basic blocks.
|
||||
|
||||
A region with a single block may not include a [terminator
|
||||
operation](#terminator-operations). The enclosing op can opt-out of this
|
||||
requirement with the `NoTerminator` trait. The top-level `ModuleOp` is an
|
||||
example of such operation which defined this trait and whose block body does
|
||||
not have a terminator.
|
||||
A region with a single block may not include a
|
||||
[terminator operation](#terminator-operations). The enclosing op can opt-out of
|
||||
this requirement with the `NoTerminator` trait. The top-level `ModuleOp` is an
|
||||
example of such operation which defined this trait and whose block body does not
|
||||
have a terminator.
|
||||
|
||||
Blocks in MLIR take a list of block arguments, notated in a function-like
|
||||
way. Block arguments are bound to values specified by the semantics of
|
||||
individual operations. Block arguments of the entry block of a region are also
|
||||
arguments to the region and the values bound to these arguments are determined
|
||||
by the semantics of the containing operation. Block arguments of other blocks
|
||||
are determined by the semantics of terminator operations, e.g. Branches, which
|
||||
have the block as a successor. In regions with [control
|
||||
flow](#control-flow-and-ssacfg-regions), MLIR leverages this structure to
|
||||
implicitly represent the passage of control-flow dependent values without the
|
||||
Blocks in MLIR take a list of block arguments, notated in a function-like way.
|
||||
Block arguments are bound to values specified by the semantics of individual
|
||||
operations. Block arguments of the entry block of a region are also arguments to
|
||||
the region and the values bound to these arguments are determined by the
|
||||
semantics of the containing operation. Block arguments of other blocks are
|
||||
determined by the semantics of terminator operations, e.g. Branches, which have
|
||||
the block as a successor. In regions with
|
||||
[control flow](#control-flow-and-ssacfg-regions), MLIR leverages this structure
|
||||
to implicitly represent the passage of control-flow dependent values without the
|
||||
complex nuances of PHI nodes in traditional SSA representations. Note that
|
||||
values which are not control-flow dependent can be referenced directly and do
|
||||
not need to be passed through block arguments.
|
||||
|
|
@ -389,7 +384,7 @@ func @simple(i64, i1) -> i64 {
|
|||
br ^bb3(%a: i64) // Branch passes %a as the argument
|
||||
|
||||
^bb2:
|
||||
%b = addi %a, %a : i64
|
||||
%b = arith.addi %a, %a : i64
|
||||
br ^bb3(%b: i64) // Branch passes %b as the argument
|
||||
|
||||
// ^bb3 receives an argument, named %c, from predecessors
|
||||
|
|
@ -400,21 +395,20 @@ func @simple(i64, i1) -> i64 {
|
|||
br ^bb4(%c, %a : i64, i64)
|
||||
|
||||
^bb4(%d : i64, %e : i64):
|
||||
%0 = addi %d, %e : i64
|
||||
%0 = arith.addi %d, %e : i64
|
||||
return %0 : i64 // Return is also a terminator.
|
||||
}
|
||||
```
|
||||
|
||||
**Context:** The "block argument" representation eliminates a number
|
||||
of special cases from the IR compared to traditional "PHI nodes are
|
||||
operations" SSA IRs (like LLVM). For example, the [parallel copy
|
||||
semantics](http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.524.5461&rep=rep1&type=pdf)
|
||||
of SSA is immediately apparent, and function arguments are no longer a
|
||||
special case: they become arguments to the entry block [[more
|
||||
rationale](Rationale/Rationale.md/#block-arguments-vs-phi-nodes)]. Blocks
|
||||
are also a fundamental concept that cannot be represented by
|
||||
operations because values defined in an operation cannot be accessed
|
||||
outside the operation.
|
||||
**Context:** The "block argument" representation eliminates a number of special
|
||||
cases from the IR compared to traditional "PHI nodes are operations" SSA IRs
|
||||
(like LLVM). For example, the
|
||||
[parallel copy semantics](http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.524.5461&rep=rep1&type=pdf)
|
||||
of SSA is immediately apparent, and function arguments are no longer a special
|
||||
case: they become arguments to the entry block
|
||||
[[more rationale](Rationale/Rationale.md/#block-arguments-vs-phi-nodes)]. Blocks
|
||||
are also a fundamental concept that cannot be represented by operations because
|
||||
values defined in an operation cannot be accessed outside the operation.
|
||||
|
||||
## Regions
|
||||
|
||||
|
|
@ -425,16 +419,15 @@ region is not imposed by the IR. Instead, the containing operation defines the
|
|||
semantics of the regions it contains. MLIR currently defines two kinds of
|
||||
regions: [SSACFG regions](#control-flow-and-ssacfg-regions), which describe
|
||||
control flow between blocks, and [Graph regions](#graph-regions), which do not
|
||||
require control flow between block. The kinds of regions within an operation
|
||||
are described using the
|
||||
[RegionKindInterface](Interfaces.md/#regionkindinterfaces).
|
||||
require control flow between block. The kinds of regions within an operation are
|
||||
described using the [RegionKindInterface](Interfaces.md/#regionkindinterfaces).
|
||||
|
||||
Regions do not have a name or an address, only the blocks contained in a
|
||||
region do. Regions must be contained within operations and have no type or
|
||||
attributes. The first block in the region is a special block called the 'entry
|
||||
block'. The arguments to the entry block are also the arguments of the region
|
||||
itself. The entry block cannot be listed as a successor of any other
|
||||
block. The syntax for a region is as follows:
|
||||
Regions do not have a name or an address, only the blocks contained in a region
|
||||
do. Regions must be contained within operations and have no type or attributes.
|
||||
The first block in the region is a special block called the 'entry block'. The
|
||||
arguments to the entry block are also the arguments of the region itself. The
|
||||
entry block cannot be listed as a successor of any other block. The syntax for a
|
||||
region is as follows:
|
||||
|
||||
```
|
||||
region ::= `{` block* `}`
|
||||
|
|
@ -444,21 +437,20 @@ A function body is an example of a region: it consists of a CFG of blocks and
|
|||
has additional semantic restrictions that other types of regions may not have.
|
||||
For example, in a function body, block terminators must either branch to a
|
||||
different block, or return from a function where the types of the `return`
|
||||
arguments must match the result types of the function signature. Similarly,
|
||||
the function arguments must match the types and count of the region arguments.
|
||||
In general, operations with regions can define these correspondances
|
||||
arbitrarily.
|
||||
arguments must match the result types of the function signature. Similarly, the
|
||||
function arguments must match the types and count of the region arguments. In
|
||||
general, operations with regions can define these correspondances arbitrarily.
|
||||
|
||||
### Value Scoping
|
||||
|
||||
Regions provide hierarchical encapsulation of programs: it is impossible to
|
||||
reference, i.e. branch to, a block which is not in the same region as the
|
||||
source of the reference, i.e. a terminator operation. Similarly, regions
|
||||
provides a natural scoping for value visibility: values defined in a region
|
||||
don't escape to the enclosing region, if any. By default, operations inside a
|
||||
region can reference values defined outside of the region whenever it would
|
||||
have been legal for operands of the enclosing operation to reference those
|
||||
values, but this can be restricted using traits, such as
|
||||
reference, i.e. branch to, a block which is not in the same region as the source
|
||||
of the reference, i.e. a terminator operation. Similarly, regions provides a
|
||||
natural scoping for value visibility: values defined in a region don't escape to
|
||||
the enclosing region, if any. By default, operations inside a region can
|
||||
reference values defined outside of the region whenever it would have been legal
|
||||
for operands of the enclosing operation to reference those values, but this can
|
||||
be restricted using traits, such as
|
||||
[OpTrait::IsolatedFromAbove](Traits.md/#isolatedfromabove), or a custom
|
||||
verifier.
|
||||
|
||||
|
|
@ -466,56 +458,54 @@ Example:
|
|||
|
||||
```mlir
|
||||
"any_op"(%a) ({ // if %a is in-scope in the containing region...
|
||||
// then %a is in-scope here too.
|
||||
// then %a is in-scope here too.
|
||||
%new_value = "another_op"(%a) : (i64) -> (i64)
|
||||
}) : (i64) -> (i64)
|
||||
```
|
||||
|
||||
MLIR defines a generalized 'hierarchical dominance' concept that operates
|
||||
across hierarchy and defines whether a value is 'in scope' and can be used by
|
||||
a particular operation. Whether a value can be used by another operation in
|
||||
the same region is defined by the kind of region. A value defined in a region
|
||||
can be used by an operation which has a parent in the same region, if and only
|
||||
if the parent could use the value. A value defined by an argument to a region
|
||||
can always be used by any operation deeply contained in the region. A value
|
||||
defined in a region can never be used outside of the region.
|
||||
MLIR defines a generalized 'hierarchical dominance' concept that operates across
|
||||
hierarchy and defines whether a value is 'in scope' and can be used by a
|
||||
particular operation. Whether a value can be used by another operation in the
|
||||
same region is defined by the kind of region. A value defined in a region can be
|
||||
used by an operation which has a parent in the same region, if and only if the
|
||||
parent could use the value. A value defined by an argument to a region can
|
||||
always be used by any operation deeply contained in the region. A value defined
|
||||
in a region can never be used outside of the region.
|
||||
|
||||
### Control Flow and SSACFG Regions
|
||||
|
||||
In MLIR, control flow semantics of a region is indicated by
|
||||
[RegionKind::SSACFG](Interfaces.md/#regionkindinterfaces). Informally, these
|
||||
regions support semantics where operations in a region 'execute
|
||||
sequentially'. Before an operation executes, its operands have well-defined
|
||||
values. After an operation executes, the operands have the same values and
|
||||
results also have well-defined values. After an operation executes, the next
|
||||
operation in the block executes until the operation is the terminator operation
|
||||
at the end of a block, in which case some other operation will execute. The
|
||||
determination of the next instruction to execute is the 'passing of control
|
||||
flow'.
|
||||
[RegionKind::SSACFG](Interfaces.md/#regionkindinterfaces). Informally, these
|
||||
regions support semantics where operations in a region 'execute sequentially'.
|
||||
Before an operation executes, its operands have well-defined values. After an
|
||||
operation executes, the operands have the same values and results also have
|
||||
well-defined values. After an operation executes, the next operation in the
|
||||
block executes until the operation is the terminator operation at the end of a
|
||||
block, in which case some other operation will execute. The determination of the
|
||||
next instruction to execute is the 'passing of control flow'.
|
||||
|
||||
In general, when control flow is passed to an operation, MLIR does not
|
||||
restrict when control flow enters or exits the regions contained in that
|
||||
operation. However, when control flow enters a region, it always begins in the
|
||||
first block of the region, called the *entry* block. Terminator operations
|
||||
ending each block represent control flow by explicitly specifying the
|
||||
successor blocks of the block. Control flow can only pass to one of the
|
||||
specified successor blocks as in a `branch` operation, or back to the
|
||||
containing operation as in a `return` operation. Terminator operations without
|
||||
successors can only pass control back to the containing operation. Within
|
||||
these restrictions, the particular semantics of terminator operations is
|
||||
determined by the specific dialect operations involved. Blocks (other than the
|
||||
entry block) that are not listed as a successor of a terminator operation are
|
||||
defined to be unreachable and can be removed without affecting the semantics
|
||||
of the containing operation.
|
||||
In general, when control flow is passed to an operation, MLIR does not restrict
|
||||
when control flow enters or exits the regions contained in that operation.
|
||||
However, when control flow enters a region, it always begins in the first block
|
||||
of the region, called the *entry* block. Terminator operations ending each block
|
||||
represent control flow by explicitly specifying the successor blocks of the
|
||||
block. Control flow can only pass to one of the specified successor blocks as in
|
||||
a `branch` operation, or back to the containing operation as in a `return`
|
||||
operation. Terminator operations without successors can only pass control back
|
||||
to the containing operation. Within these restrictions, the particular semantics
|
||||
of terminator operations is determined by the specific dialect operations
|
||||
involved. Blocks (other than the entry block) that are not listed as a successor
|
||||
of a terminator operation are defined to be unreachable and can be removed
|
||||
without affecting the semantics of the containing operation.
|
||||
|
||||
Although control flow always enters a region through the entry block, control
|
||||
flow may exit a region through any block with an appropriate terminator. The
|
||||
standard dialect leverages this capability to define operations with
|
||||
Single-Entry-Multiple-Exit (SEME) regions, possibly flowing through different
|
||||
blocks in the region and exiting through any block with a `return`
|
||||
operation. This behavior is similar to that of a function body in most
|
||||
programming languages. In addition, control flow may also not reach the end of
|
||||
a block or region, for example if a function call does not return.
|
||||
blocks in the region and exiting through any block with a `return` operation.
|
||||
This behavior is similar to that of a function body in most programming
|
||||
languages. In addition, control flow may also not reach the end of a block or
|
||||
region, for example if a function call does not return.
|
||||
|
||||
Example:
|
||||
|
||||
|
|
@ -548,14 +538,14 @@ func @accelerator_compute(i64, i1) -> i64 { // An SSACFG region
|
|||
An operation containing multiple regions also completely determines the
|
||||
semantics of those regions. In particular, when control flow is passed to an
|
||||
operation, it may transfer control flow to any contained region. When control
|
||||
flow exits a region and is returned to the containing operation, the
|
||||
containing operation may pass control flow to any region in the same
|
||||
operation. An operation may also pass control flow to multiple contained
|
||||
regions concurrently. An operation may also pass control flow into regions
|
||||
that were specified in other operations, in particular those that defined the
|
||||
values or symbols the given operation uses as in a call operation. This
|
||||
passage of control is generally independent of passage of control flow through
|
||||
the basic blocks of the containing region.
|
||||
flow exits a region and is returned to the containing operation, the containing
|
||||
operation may pass control flow to any region in the same operation. An
|
||||
operation may also pass control flow to multiple contained regions concurrently.
|
||||
An operation may also pass control flow into regions that were specified in
|
||||
other operations, in particular those that defined the values or symbols the
|
||||
given operation uses as in a call operation. This passage of control is
|
||||
generally independent of passage of control flow through the basic blocks of the
|
||||
containing region.
|
||||
|
||||
#### Closure
|
||||
|
||||
|
|
@ -579,19 +569,19 @@ streams of data. As usual in MLIR, the particular semantics of a region is
|
|||
completely determined by its containing operation. Graph regions may only
|
||||
contain a single basic block (the entry block).
|
||||
|
||||
**Rationale:** Currently graph regions are arbitrarily limited to a single
|
||||
basic block, although there is no particular semantic reason for this
|
||||
limitation. This limitation has been added to make it easier to stabilize the
|
||||
pass infrastructure and commonly used passes for processing graph regions to
|
||||
properly handle feedback loops. Multi-block regions may be allowed in the
|
||||
future if use cases that require it arise.
|
||||
**Rationale:** Currently graph regions are arbitrarily limited to a single basic
|
||||
block, although there is no particular semantic reason for this limitation. This
|
||||
limitation has been added to make it easier to stabilize the pass infrastructure
|
||||
and commonly used passes for processing graph regions to properly handle
|
||||
feedback loops. Multi-block regions may be allowed in the future if use cases
|
||||
that require it arise.
|
||||
|
||||
In graph regions, MLIR operations naturally represent nodes, while each MLIR
|
||||
value represents a multi-edge connecting a single source node and multiple
|
||||
destination nodes. All values defined in the region as results of operations
|
||||
are in scope within the region and can be accessed by any other operation in
|
||||
the region. In graph regions, the order of operations within a block and the
|
||||
order of blocks in a region is not semantically meaningful and non-terminator
|
||||
destination nodes. All values defined in the region as results of operations are
|
||||
in scope within the region and can be accessed by any other operation in the
|
||||
region. In graph regions, the order of operations within a block and the order
|
||||
of blocks in a region is not semantically meaningful and non-terminator
|
||||
operations may be freely reordered, for instance, by canonicalization. Other
|
||||
kinds of graphs, such as graphs with multiple source nodes and multiple
|
||||
destination nodes, can also be represented by representing graph edges as MLIR
|
||||
|
|
@ -604,7 +594,7 @@ basic blocks.
|
|||
"test.graph_region"() ({ // A Graph region
|
||||
%1 = "op1"(%1, %3) : (i32, i32) -> (i32) // OK: %1, %3 allowed here
|
||||
%2 = "test.ssacfg_region"() ({
|
||||
%5 = "op2"(%1, %2, %3, %4) : (i32, i32, i32, i32) -> (i32) // OK: %1, %2, %3, %4 all defined in the containing region
|
||||
%5 = "op2"(%1, %2, %3, %4) : (i32, i32, i32, i32) -> (i32) // OK: %1, %2, %3, %4 all defined in the containing region
|
||||
}) : () -> (i32)
|
||||
%3 = "op2"(%1, %4) : (i32, i32) -> (i32) // OK: %4 allowed here
|
||||
%4 = "op3"(%1) : (i32) -> (i32)
|
||||
|
|
@ -754,16 +744,17 @@ The top-level attribute dictionary attached to an operation has special
|
|||
semantics. The attribute entries are considered to be of two different kinds
|
||||
based on whether their dictionary key has a dialect prefix:
|
||||
|
||||
- *inherent attributes* are inherent to the definition of an operation's
|
||||
semantics. The operation itself is expected to verify the consistency of these
|
||||
attributes. An example is the `predicate` attribute of the `std.cmpi` op.
|
||||
These attributes must have names that do not start with a dialect prefix.
|
||||
- *inherent attributes* are inherent to the definition of an operation's
|
||||
semantics. The operation itself is expected to verify the consistency of
|
||||
these attributes. An example is the `predicate` attribute of the
|
||||
`arith.cmpi` op. These attributes must have names that do not start with a
|
||||
dialect prefix.
|
||||
|
||||
- *discardable attributes* have semantics defined externally to the operation
|
||||
itself, but must be compatible with the operations's semantics. These
|
||||
attributes must have names that start with a dialect prefix. The dialect
|
||||
indicated by the dialect prefix is expected to verify these attributes. An
|
||||
example is the `gpu.container_module` attribute.
|
||||
- *discardable attributes* have semantics defined externally to the operation
|
||||
itself, but must be compatible with the operations's semantics. These
|
||||
attributes must have names that start with a dialect prefix. The dialect
|
||||
indicated by the dialect prefix is expected to verify these attributes. An
|
||||
example is the `gpu.container_module` attribute.
|
||||
|
||||
Note that attribute values are allowed to themselves be dictionary attributes,
|
||||
but only the top-level dictionary attribute attached to the operation is subject
|
||||
|
|
|
|||
|
|
@ -8,7 +8,7 @@ make sense to make a "revolutionary" change when any individual problem can be
|
|||
fixed in place?
|
||||
|
||||
This document explains that adoption of MLIR to solve graph based problems
|
||||
_isn't_ a revolutionary change: it is an incremental series of steps which build
|
||||
*isn't* a revolutionary change: it is an incremental series of steps which build
|
||||
on each other, each of which delivers local value. This document also addresses
|
||||
some points of confusion that keep coming up.
|
||||
|
||||
|
|
@ -156,7 +156,7 @@ turned into zero:
|
|||
```mlir
|
||||
// RUN: mlir-opt %s -canonicalize | FileCheck %s
|
||||
func @test_subi_zero_cfg(%arg0: i32) -> i32 {
|
||||
%y = subi %arg0, %arg0 : i32
|
||||
%y = arith.subi %arg0, %arg0 : i32
|
||||
return %y: i32
|
||||
}
|
||||
// CHECK-LABEL: func @test_subi_zero_cfg(%arg0: i32)
|
||||
|
|
@ -210,13 +210,13 @@ write tests like this:
|
|||
```mlir
|
||||
// RUN: mlir-opt %s -memref-dependence-check -verify-diagnostics
|
||||
func @different_memrefs() {
|
||||
%m.a = alloc() : memref<100xf32>
|
||||
%m.b = alloc() : memref<100xf32>
|
||||
%c0 = constant 0 : index
|
||||
%c1 = constant 1.0 : f32
|
||||
store %c1, %m.a[%c0] : memref<100xf32>
|
||||
%m.a = memref.alloc() : memref<100xf32>
|
||||
%m.b = memref.alloc() : memref<100xf32>
|
||||
%c0 = arith.constant 0 : index
|
||||
%c1 = arith.constant 1.0 : f32
|
||||
memref.store %c1, %m.a[%c0] : memref<100xf32>
|
||||
// expected-note@-1 {{dependence from memref access 0 to access 1 = false}}
|
||||
%v0 = load %m.b[%c0] : memref<100xf32>
|
||||
%v0 = memref.load %m.b[%c0] : memref<100xf32>
|
||||
return
|
||||
}
|
||||
```
|
||||
|
|
@ -238,8 +238,8 @@ and use this information when available, but because TensorFlow graphs don't
|
|||
capture this (e.g. serialize it to proto), passes have to recompute it on demand
|
||||
with ShapeRefiner.
|
||||
|
||||
The [MLIR Tensor Type](../Dialects/Builtin.md/#rankedtensortype) directly captures shape
|
||||
information, so you can have things like:
|
||||
The [MLIR Tensor Type](../Dialects/Builtin.md/#rankedtensortype) directly
|
||||
captures shape information, so you can have things like:
|
||||
|
||||
```mlir
|
||||
%x = tf.Add %x, %y : tensor<128 x 8 x ? x f32>
|
||||
|
|
@ -254,11 +254,11 @@ and the API is easier to work with from an ergonomics perspective.
|
|||
### Unified Graph Rewriting Infrastructure
|
||||
|
||||
This is still a work in progress, but we have sightlines towards a
|
||||
[general rewriting infrastructure](RationaleGenericDAGRewriter.md) for transforming DAG
|
||||
tiles into other DAG tiles, using a declarative pattern format. DAG to DAG
|
||||
rewriting is a generalized solution for many common compiler optimizations,
|
||||
lowerings, and other rewrites and having an IR enables us to invest in building
|
||||
a single high-quality implementation.
|
||||
[general rewriting infrastructure](RationaleGenericDAGRewriter.md) for
|
||||
transforming DAG tiles into other DAG tiles, using a declarative pattern format.
|
||||
DAG to DAG rewriting is a generalized solution for many common compiler
|
||||
optimizations, lowerings, and other rewrites and having an IR enables us to
|
||||
invest in building a single high-quality implementation.
|
||||
|
||||
Declarative pattern rules are preferable to imperative C++ code for a number of
|
||||
reasons: they are more compact, easier to reason about, can have checkers
|
||||
|
|
|
|||
|
|
@ -58,12 +58,12 @@ polyhedral abstraction.
|
|||
|
||||
Maps, sets, and relations with affine constraints are the core structures
|
||||
underlying a polyhedral representation of high-dimensional loop nests and
|
||||
multidimensional arrays. These structures are represented as textual
|
||||
expressions in a form close to their mathematical form. These structures are
|
||||
used to capture loop nests, tensor data structures, and how they are reordered
|
||||
and mapped for a target architecture. All structured or "conforming" loops are
|
||||
captured as part of the polyhedral information, and so are tensor variables,
|
||||
their layouts, and subscripted accesses to these tensors in memory.
|
||||
multidimensional arrays. These structures are represented as textual expressions
|
||||
in a form close to their mathematical form. These structures are used to capture
|
||||
loop nests, tensor data structures, and how they are reordered and mapped for a
|
||||
target architecture. All structured or "conforming" loops are captured as part
|
||||
of the polyhedral information, and so are tensor variables, their layouts, and
|
||||
subscripted accesses to these tensors in memory.
|
||||
|
||||
The information captured in the IR allows a compact expression of all loop
|
||||
transformations, data remappings, explicit copying necessary for explicitly
|
||||
|
|
@ -113,17 +113,19 @@ n-ranked tensor. This disallows the equivalent of pointer arithmetic or the
|
|||
ability to index into the same memref in other ways (something which C arrays
|
||||
allow for example). Furthermore, for the affine constructs, the compiler can
|
||||
follow use-def chains (e.g. through
|
||||
[affine.apply operations](../Dialects/Affine.md/#affineapply-affineapplyop)) or through
|
||||
the map attributes of [affine operations](../Dialects/Affine.md/#operations)) to
|
||||
precisely analyze references at compile-time using polyhedral techniques. This
|
||||
is possible because of the [restrictions on dimensions and symbols](../Dialects/Affine.md/#restrictions-on-dimensions-and-symbols).
|
||||
[affine.apply operations](../Dialects/Affine.md/#affineapply-affineapplyop)) or
|
||||
through the map attributes of
|
||||
[affine operations](../Dialects/Affine.md/#operations)) to precisely analyze
|
||||
references at compile-time using polyhedral techniques. This is possible because
|
||||
of the
|
||||
[restrictions on dimensions and symbols](../Dialects/Affine.md/#restrictions-on-dimensions-and-symbols).
|
||||
|
||||
A scalar of element-type (a primitive type or a vector type) that is stored in
|
||||
memory is modeled as a 0-d memref. This is also necessary for scalars that are
|
||||
live out of for loops and if conditionals in a function, for which we don't yet
|
||||
have an SSA representation --
|
||||
[an extension](#affineif-and-affinefor-extensions-for-escaping-scalars) to allow that is
|
||||
described later in this doc.
|
||||
[an extension](#affineif-and-affinefor-extensions-for-escaping-scalars) to allow
|
||||
that is described later in this doc.
|
||||
|
||||
### Symbols and types
|
||||
|
||||
|
|
@ -136,7 +138,7 @@ Example:
|
|||
|
||||
```mlir
|
||||
func foo(...) {
|
||||
%A = alloc <8x?xf32, #lmap> (%N)
|
||||
%A = memref.alloc <8x?xf32, #lmap> (%N)
|
||||
...
|
||||
call bar(%A) : (memref<8x?xf32, #lmap>)
|
||||
}
|
||||
|
|
@ -145,7 +147,7 @@ func bar(%A : memref<8x?xf32, #lmap>) {
|
|||
// Type of %A indicates that %A has dynamic shape with 8 rows
|
||||
// and unknown number of columns. The number of columns is queried
|
||||
// dynamically using dim instruction.
|
||||
%N = dim %A, 1 : memref<8x?xf32, #lmap>
|
||||
%N = memref.dim %A, 1 : memref<8x?xf32, #lmap>
|
||||
|
||||
affine.for %i = 0 to 8 {
|
||||
affine.for %j = 0 to %N {
|
||||
|
|
@ -167,9 +169,9 @@ change.
|
|||
|
||||
### Block Arguments vs PHI nodes
|
||||
|
||||
MLIR Regions represent SSA using "[block arguments](../LangRef.md/#blocks)" rather
|
||||
than [PHI instructions](http://llvm.org/docs/LangRef.html#i-phi) used in LLVM.
|
||||
This choice is representationally identical (the same constructs can be
|
||||
MLIR Regions represent SSA using "[block arguments](../LangRef.md/#blocks)"
|
||||
rather than [PHI instructions](http://llvm.org/docs/LangRef.html#i-phi) used in
|
||||
LLVM. This choice is representationally identical (the same constructs can be
|
||||
represented in either form) but block arguments have several advantages:
|
||||
|
||||
1. LLVM PHI nodes always have to be kept at the top of a block, and
|
||||
|
|
@ -220,10 +222,10 @@ to materialize corresponding values. However, the target might lack support for
|
|||
Data layout information such as the bit width or the alignment of types may be
|
||||
target and ABI-specific and thus should be configurable rather than imposed by
|
||||
the compiler. Especially, the layout of compound or `index` types may vary. MLIR
|
||||
specifies default bit widths for certain primitive _types_, in particular for
|
||||
specifies default bit widths for certain primitive *types*, in particular for
|
||||
integers and floats. It is equal to the number that appears in the type
|
||||
definition, e.g. the bit width of `i32` is `32`, so is the bit width of `f32`.
|
||||
The bit width is not _necessarily_ related to the amount of memory (in bytes) or
|
||||
The bit width is not *necessarily* related to the amount of memory (in bytes) or
|
||||
the register size (in bits) that is necessary to store the value of the given
|
||||
type. For example, `vector<3xi57>` is likely to be lowered to a vector of four
|
||||
64-bit integers, so that its storage requirement is `4 x 64 / 8 = 32` bytes,
|
||||
|
|
@ -250,8 +252,9 @@ type provides this as an option to help code reuse and consistency.
|
|||
|
||||
For the standard dialect, the choice is to have signless integer types. An
|
||||
integer value does not have an intrinsic sign, and it's up to the specific op
|
||||
for interpretation. For example, ops like `addi` and `muli` do two's complement
|
||||
arithmetic, but some other operations get a sign, e.g. `divis` vs `diviu`.
|
||||
for interpretation. For example, ops like `arith.addi` and `arith.muli` do two's
|
||||
complement arithmetic, but some other operations get a sign, e.g. `arith.divsi`
|
||||
vs `arith.divui`.
|
||||
|
||||
LLVM uses the [same design](http://llvm.org/docs/LangRef.html#integer-type),
|
||||
which was introduced in a revamp rolled out
|
||||
|
|
@ -279,11 +282,11 @@ an external system, and should aim to reflect its design as closely as possible.
|
|||
|
||||
### Splitting floating point vs integer operations
|
||||
|
||||
The MLIR "standard" operation set splits many integer and floating point
|
||||
operations into different categories, for example `addf` vs `addi` and `cmpf` vs
|
||||
`cmpi`
|
||||
The MLIR "Arithmetic" dialect splits many integer and floating point operations
|
||||
into different categories, for example `arith.addf` vs `arith.addi` and
|
||||
`arith.cmpf` vs `arith.cmpi`
|
||||
([following the design of LLVM](http://llvm.org/docs/LangRef.html#binary-operations)).
|
||||
These instructions _are_ polymorphic on the number of elements in the type
|
||||
These instructions *are* polymorphic on the number of elements in the type
|
||||
though, for example `addf` is used with scalar floats, vectors of floats, and
|
||||
tensors of floats (LLVM does the same thing with its scalar/vector types).
|
||||
|
||||
|
|
@ -308,12 +311,12 @@ an external system, and should aim to reflect its design as closely as possible.
|
|||
|
||||
### Specifying sign in integer comparison operations
|
||||
|
||||
Since integers are [signless](#integer-signedness-semantics), it is necessary to define the
|
||||
sign for integer comparison operations. This sign indicates how to treat the
|
||||
foremost bit of the integer: as sign bit or as most significant bit. For
|
||||
example, comparing two `i4` values `0b1000` and `0b0010` yields different
|
||||
Since integers are [signless](#integer-signedness-semantics), it is necessary to
|
||||
define the sign for integer comparison operations. This sign indicates how to
|
||||
treat the foremost bit of the integer: as sign bit or as most significant bit.
|
||||
For example, comparing two `i4` values `0b1000` and `0b0010` yields different
|
||||
results for unsigned (`8 > 3`) and signed (`-8 < 3`) interpretations. This
|
||||
difference is only significant for _order_ comparisons, but not for _equality_
|
||||
difference is only significant for *order* comparisons, but not for *equality*
|
||||
comparisons. Indeed, for the latter all bits must have the same value
|
||||
independently of the sign. Since both arguments have exactly the same bit width
|
||||
and cannot be padded by this operation, it is impossible to compare two values
|
||||
|
|
@ -491,10 +494,10 @@ dialect wishes to assign a canonical name to a type, it can be done via
|
|||
### Tuple types
|
||||
|
||||
The MLIR type system provides first class support for defining
|
||||
[tuple types](../Dialects/Builtin/#tupletype). This is due to the fact that `Tuple`
|
||||
represents a universal concept that is likely to, and has already begun to,
|
||||
present itself in many different dialects. Though this type is first class in
|
||||
the type system, it merely serves to provide a common mechanism in which to
|
||||
[tuple types](../Dialects/Builtin/#tupletype). This is due to the fact that
|
||||
`Tuple` represents a universal concept that is likely to, and has already begun
|
||||
to, present itself in many different dialects. Though this type is first class
|
||||
in the type system, it merely serves to provide a common mechanism in which to
|
||||
represent this concept in MLIR. As such, MLIR provides no standard operations
|
||||
for interfacing with `tuple` types. It is up to dialect authors to provide
|
||||
operations, e.g. extract_tuple_element, to interpret and manipulate them. When
|
||||
|
|
@ -547,7 +550,7 @@ nested in an outer function that uses affine loops.
|
|||
|
||||
```mlir
|
||||
func @search(%A: memref<?x?xi32>, %S: <?xi32>, %key : i32) {
|
||||
%ni = dim %A, 0 : memref<?x?xi32>
|
||||
%ni = memref.dim %A, 0 : memref<?x?xi32>
|
||||
// This loop can be parallelized
|
||||
affine.for %i = 0 to %ni {
|
||||
call @search_body (%A, %S, %key, %i) : (memref<?x?xi32>, memref<?xi32>, i32, i32)
|
||||
|
|
@ -556,16 +559,16 @@ func @search(%A: memref<?x?xi32>, %S: <?xi32>, %key : i32) {
|
|||
}
|
||||
|
||||
func @search_body(%A: memref<?x?xi32>, %S: memref<?xi32>, %key: i32, %i : i32) {
|
||||
%nj = dim %A, 1 : memref<?x?xi32>
|
||||
%nj = memref.dim %A, 1 : memref<?x?xi32>
|
||||
br ^bb1(0)
|
||||
|
||||
^bb1(%j: i32)
|
||||
%p1 = cmpi "lt", %j, %nj : i32
|
||||
%p1 = arith.cmpi "lt", %j, %nj : i32
|
||||
cond_br %p1, ^bb2, ^bb5
|
||||
|
||||
^bb2:
|
||||
%v = affine.load %A[%i, %j] : memref<?x?xi32>
|
||||
%p2 = cmpi "eq", %v, %key : i32
|
||||
%p2 = arith.cmpi "eq", %v, %key : i32
|
||||
cond_br %p2, ^bb3(%j), ^bb4
|
||||
|
||||
^bb3(%j: i32)
|
||||
|
|
@ -573,7 +576,7 @@ func @search_body(%A: memref<?x?xi32>, %S: memref<?xi32>, %key: i32, %i : i32) {
|
|||
br ^bb5
|
||||
|
||||
^bb4:
|
||||
%jinc = addi %j, 1 : i32
|
||||
%jinc = arith.addi %j, 1 : i32
|
||||
br ^bb1(%jinc)
|
||||
|
||||
^bb5:
|
||||
|
|
@ -728,10 +731,10 @@ At a high level, we have two alternatives here:
|
|||
explicitly propagate the schedule into domains and model all the cleanup
|
||||
code. An example and more detail on the schedule tree form is in the next
|
||||
section.
|
||||
1. Having two different forms of "affine regions": an affine loop tree form
|
||||
and a polyhedral schedule tree form. In the latter, ops could carry
|
||||
attributes capturing domain, scheduling, and other polyhedral code
|
||||
generation options with IntegerSet, AffineMap, and other attributes.
|
||||
1. Having two different forms of "affine regions": an affine loop tree form and
|
||||
a polyhedral schedule tree form. In the latter, ops could carry attributes
|
||||
capturing domain, scheduling, and other polyhedral code generation options
|
||||
with IntegerSet, AffineMap, and other attributes.
|
||||
|
||||
#### Schedule Tree Representation for Affine Regions
|
||||
|
||||
|
|
@ -788,12 +791,11 @@ func @matmul(%A, %B, %C, %M, %N, %K) : (...) { // %M, N, K are symbols
|
|||
|
||||
### Affine Relations
|
||||
|
||||
The current MLIR spec includes affine maps and integer sets, but not
|
||||
affine relations. Affine relations are a natural way to model read and
|
||||
write access information, which can be very useful to capture the
|
||||
behavior of external library calls where no implementation is
|
||||
available, high-performance vendor libraries, or user-provided /
|
||||
user-tuned routines.
|
||||
The current MLIR spec includes affine maps and integer sets, but not affine
|
||||
relations. Affine relations are a natural way to model read and write access
|
||||
information, which can be very useful to capture the behavior of external
|
||||
library calls where no implementation is available, high-performance vendor
|
||||
libraries, or user-provided / user-tuned routines.
|
||||
|
||||
An affine relation is a relation between input and output dimension identifiers
|
||||
while being symbolic on a list of symbolic identifiers and with affine
|
||||
|
|
@ -844,7 +846,7 @@ func @count (%A : memref<128xf32>, %pos : i32) -> f32
|
|||
bb0 (%0, %1: memref<128xf32>, i64):
|
||||
%val = affine.load %A [%pos]
|
||||
%val = affine.load %A [%pos + 1]
|
||||
%p = mulf %val, %val : f32
|
||||
%p = arith.mulf %val, %val : f32
|
||||
return %p : f32
|
||||
}
|
||||
```
|
||||
|
|
|
|||
|
|
@ -58,21 +58,21 @@ Moreover, SPIR-V supports the notion of array stride. Currently only natural
|
|||
strides (based on [`VulkanLayoutUtils`][VulkanLayoutUtils]) are supported. They
|
||||
are also mapped to LLVM array.
|
||||
|
||||
SPIR-V Dialect | LLVM Dialect
|
||||
:-----------------------------------: | :-----------------------------------:
|
||||
`!spv.array<<count> x <element-type>>`| `!llvm.array<<count> x <element-type>>`
|
||||
`!spv.rtarray< <element-type> >` | `!llvm.array<0 x <element-type>>`
|
||||
SPIR-V Dialect | LLVM Dialect
|
||||
:------------------------------------: | :-------------------------------------:
|
||||
`!spv.array<<count> x <element-type>>` | `!llvm.array<<count> x <element-type>>`
|
||||
`!spv.rtarray< <element-type> >` | `!llvm.array<0 x <element-type>>`
|
||||
|
||||
### Struct types
|
||||
|
||||
Members of SPIR-V struct types may have decorations and offset information.
|
||||
Currently, there is **no** support of member decorations conversion for structs.
|
||||
For more information see section on [Decorations](#Decorations-conversion).
|
||||
For more information see section on [Decorations](#Decorations-conversion).
|
||||
|
||||
Usually we expect that each struct member has a natural size and alignment.
|
||||
However, there are cases (*e.g.* in graphics) where one would place struct
|
||||
members explicitly at particular offsets. This case is **not** supported
|
||||
at the moment. Hence, we adhere to the following mapping:
|
||||
However, there are cases (*e.g.* in graphics) where one would place struct
|
||||
members explicitly at particular offsets. This case is **not** supported at the
|
||||
moment. Hence, we adhere to the following mapping:
|
||||
|
||||
* Structs with no offset are modelled as LLVM packed structures.
|
||||
|
||||
|
|
@ -86,14 +86,11 @@ at the moment. Hence, we adhere to the following mapping:
|
|||
a design would require index recalculation in the conversion of ops that
|
||||
involve memory addressing.
|
||||
|
||||
Examples of SPIR-V struct conversion are:
|
||||
```mlir
|
||||
!spv.struct<i8, i32> => !llvm.struct<packed (i8, i32)>
|
||||
!spv.struct<i8 [0], i32 [4]> => !llvm.struct<(i8, i32)>
|
||||
Examples of SPIR-V struct conversion are: ```mlir !spv.struct<i8, i32> =>
|
||||
!llvm.struct<packed (i8, i32)> !spv.struct<i8 [0], i32 [4]> => !llvm.struct<(i8,
|
||||
i32)>
|
||||
|
||||
// error
|
||||
!spv.struct<i8 [0], i32 [8]>
|
||||
```
|
||||
// error !spv.struct<i8 [0], i32 [8]> ```
|
||||
|
||||
### Not implemented types
|
||||
|
||||
|
|
@ -104,10 +101,10 @@ conversion. This includes `ImageType` and `MatrixType`.
|
|||
|
||||
This section describes how SPIR-V Dialect operations are converted to LLVM
|
||||
Dialect. It lists already working conversion patterns, as well as those that are
|
||||
an ongoing work.
|
||||
an ongoing work.
|
||||
|
||||
There are also multiple ops for which there is no clear mapping in LLVM.
|
||||
Conversion for those have to be discussed within the community on the
|
||||
Conversion for those have to be discussed within the community on the
|
||||
case-by-case basis.
|
||||
|
||||
### Arithmetic ops
|
||||
|
|
@ -115,21 +112,21 @@ case-by-case basis.
|
|||
SPIR-V arithmetic ops mostly have a direct equivalent in LLVM Dialect. Such
|
||||
exceptions as `spv.SMod` and `spv.FMod` are rare.
|
||||
|
||||
SPIR-V Dialect op | LLVM Dialect op
|
||||
:-----------------------------------: | :-----------------------------------:
|
||||
`spv.FAdd` | `llvm.fadd`
|
||||
`spv.FDiv` | `llvm.fdiv`
|
||||
`spv.FNegate` | `llvm.fneg`
|
||||
`spv.FMul` | `llvm.fmul`
|
||||
`spv.FRem` | `llvm.frem`
|
||||
`spv.FSub` | `llvm.fsub`
|
||||
`spv.IAdd` | `llvm.add`
|
||||
`spv.IMul` | `llvm.mul`
|
||||
`spv.ISub` | `llvm.sub`
|
||||
`spv.SDiv` | `llvm.sdiv`
|
||||
`spv.SRem` | `llvm.srem`
|
||||
`spv.UDiv` | `llvm.udiv`
|
||||
`spv.UMod` | `llvm.urem`
|
||||
SPIR-V Dialect op | LLVM Dialect op
|
||||
:---------------: | :-------------:
|
||||
`spv.FAdd` | `llvm.fadd`
|
||||
`spv.FDiv` | `llvm.fdiv`
|
||||
`spv.FNegate` | `llvm.fneg`
|
||||
`spv.FMul` | `llvm.fmul`
|
||||
`spv.FRem` | `llvm.frem`
|
||||
`spv.FSub` | `llvm.fsub`
|
||||
`spv.IAdd` | `llvm.add`
|
||||
`spv.IMul` | `llvm.mul`
|
||||
`spv.ISub` | `llvm.sub`
|
||||
`spv.SDiv` | `llvm.sdiv`
|
||||
`spv.SRem` | `llvm.srem`
|
||||
`spv.UDiv` | `llvm.udiv`
|
||||
`spv.UMod` | `llvm.urem`
|
||||
|
||||
### Bitwise ops
|
||||
|
||||
|
|
@ -141,18 +138,18 @@ may have a specific conversion pattern.
|
|||
As with arithmetic ops, most of bitwise ops have a semantically equivalent op in
|
||||
LLVM:
|
||||
|
||||
SPIR-V Dialect op | LLVM Dialect op
|
||||
:-----------------------------------: | :-----------------------------------:
|
||||
`spv.BitwiseAnd` | `llvm.and`
|
||||
`spv.BitwiseOr` | `llvm.or`
|
||||
`spv.BitwiseXor` | `llvm.xor`
|
||||
SPIR-V Dialect op | LLVM Dialect op
|
||||
:---------------: | :-------------:
|
||||
`spv.BitwiseAnd` | `llvm.and`
|
||||
`spv.BitwiseOr` | `llvm.or`
|
||||
`spv.BitwiseXor` | `llvm.xor`
|
||||
|
||||
Also, some of bitwise ops can be modelled with LLVM intrinsics:
|
||||
|
||||
SPIR-V Dialect op | LLVM Dialect intrinsic
|
||||
:-----------------------------------: | :-----------------------------------:
|
||||
`spv.BitCount` | `llvm.intr.ctpop`
|
||||
`spv.BitReverse` | `llvm.intr.bitreverse`
|
||||
SPIR-V Dialect op | LLVM Dialect intrinsic
|
||||
:---------------: | :--------------------:
|
||||
`spv.BitCount` | `llvm.intr.ctpop`
|
||||
`spv.BitReverse` | `llvm.intr.bitreverse`
|
||||
|
||||
#### `spv.Not`
|
||||
|
||||
|
|
@ -170,9 +167,8 @@ SPIR-V dialect has three bitfield ops: `spv.BitFieldInsert`,
|
|||
outline the general design of conversion patterns for this ops, and then
|
||||
describe each of them.
|
||||
|
||||
All of these ops take `base`, `offset` and `count` (`insert` for
|
||||
`spv.BitFieldInsert`) as arguments. There are two important things
|
||||
to note:
|
||||
All of these ops take `base`, `offset` and `count` (`insert` for
|
||||
`spv.BitFieldInsert`) as arguments. There are two important things to note:
|
||||
|
||||
* `offset` and `count` are always scalar. This means that we can have the
|
||||
following case:
|
||||
|
|
@ -220,10 +216,9 @@ and their operands.
|
|||
##### `spv.BitFieldInsert`
|
||||
|
||||
This operation is implemented as a series of LLVM Dialect operations. First step
|
||||
would be to create a mask with bits set outside
|
||||
[`offset`, `offset` + `count` - 1]. Then, unchanged bits are extracted from
|
||||
`base` that are outside of [`offset`, `offset` + `count` - 1]. The result is
|
||||
`or`ed with shifted `insert`.
|
||||
would be to create a mask with bits set outside [`offset`, `offset` + `count` -
|
||||
1]. Then, unchanged bits are extracted from `base` that are outside of
|
||||
[`offset`, `offset` + `count` - 1]. The result is `or`ed with shifted `insert`.
|
||||
|
||||
```mlir
|
||||
// Create mask
|
||||
|
|
@ -284,73 +279,79 @@ and the mask is applied.
|
|||
|
||||
#### Direct conversions
|
||||
|
||||
SPIR-V Dialect op | LLVM Dialect op
|
||||
:-----------------------------------: | :-----------------------------------:
|
||||
`spv.ConvertFToS` | `llvm.fptosi`
|
||||
`spv.ConvertFToU` | `llvm.fptoui`
|
||||
`spv.ConvertSToF` | `llvm.sitofp`
|
||||
`spv.ConvertUToF` | `llvm.uitofp`
|
||||
SPIR-V Dialect op | LLVM Dialect op
|
||||
:---------------: | :-------------:
|
||||
`spv.ConvertFToS` | `llvm.fptosi`
|
||||
`spv.ConvertFToU` | `llvm.fptoui`
|
||||
`spv.ConvertSToF` | `llvm.sitofp`
|
||||
`spv.ConvertUToF` | `llvm.uitofp`
|
||||
|
||||
#### spv.Bitcast
|
||||
|
||||
This operation has a direct counterpart in LLVM: `llvm.bitcast`. It is treated
|
||||
separately since it also supports pointer to pointer bit pattern-preserving type
|
||||
conversion, apart from regular scalar or vector of numerical type.
|
||||
|
||||
#### Special cases
|
||||
|
||||
Special cases include `spv.FConvert`, `spv.SConvert` and `spv.UConvert`. These
|
||||
operations are either a truncate or extend. Let's denote the operand component
|
||||
width as A, and result component width as R. Then, the following mappings are
|
||||
used:
|
||||
|
||||
##### `spv.FConvert`
|
||||
Case | LLVM Dialect op
|
||||
:-------------: | :-----------------------------------:
|
||||
A < R | `llvm.fpext`
|
||||
A > R | `llvm.fptrunc`
|
||||
##### `spv.FConvert`
|
||||
|
||||
##### `spv.SConvert`
|
||||
Case | LLVM Dialect op
|
||||
:-------------: | :-----------------------------------:
|
||||
A < R | `llvm.sext`
|
||||
A > R | `llvm.trunc`
|
||||
Case | LLVM Dialect op
|
||||
:---: | :-------------:
|
||||
A < R | `llvm.fpext`
|
||||
A > R | `llvm.fptrunc`
|
||||
|
||||
##### `spv.UConvert`
|
||||
Case | LLVM Dialect op
|
||||
:-------------: | :-----------------------------------:
|
||||
A < R | `llvm.zext`
|
||||
A > R | `llvm.trunc`
|
||||
##### `spv.SConvert`
|
||||
|
||||
Case | LLVM Dialect op
|
||||
:---: | :-------------:
|
||||
A < R | `llvm.sext`
|
||||
A > R | `llvm.trunc`
|
||||
|
||||
##### `spv.UConvert`
|
||||
|
||||
Case | LLVM Dialect op
|
||||
:---: | :-------------:
|
||||
A < R | `llvm.zext`
|
||||
A > R | `llvm.trunc`
|
||||
|
||||
The case when A = R is not possible, based on SPIR-V Dialect specification:
|
||||
|
||||
> The component width cannot equal the component width in Result Type.
|
||||
|
||||
### Comparison ops
|
||||
|
||||
SPIR-V comparison ops are mapped to LLVM `icmp` and `fcmp` operations.
|
||||
|
||||
SPIR-V Dialect op | LLVM Dialect op
|
||||
:-----------------------------------: | :-----------------------------------:
|
||||
`spv.IEqual` | `llvm.icmp "eq"`
|
||||
`spv.INotEqual` | `llvm.icmp "ne"`
|
||||
`spv.FOrdEqual` | `llvm.fcmp "oeq"`
|
||||
`spv.FOrdGreaterThan` | `llvm.fcmp "ogt"`
|
||||
`spv.FOrdGreaterThanEqual` | `llvm.fcmp "oge"`
|
||||
`spv.FOrdLessThan` | `llvm.fcmp "olt"`
|
||||
`spv.FOrdLessThanEqual` | `llvm.fcmp "ole"`
|
||||
`spv.FOrdNotEqual` | `llvm.fcmp "one"`
|
||||
`spv.FUnordEqual` | `llvm.fcmp "ueq"`
|
||||
`spv.FUnordGreaterThan` | `llvm.fcmp "ugt"`
|
||||
`spv.FUnordGreaterThanEqual` | `llvm.fcmp "uge"`
|
||||
`spv.FUnordLessThan` | `llvm.fcmp "ult"`
|
||||
`spv.FUnordLessThanEqual` | `llvm.fcmp "ule"`
|
||||
`spv.FUnordNotEqual` | `llvm.fcmp "une"`
|
||||
`spv.SGreaterThan` | `llvm.icmp "sgt"`
|
||||
`spv.SGreaterThanEqual` | `llvm.icmp "sge"`
|
||||
`spv.SLessThan` | `llvm.icmp "slt"`
|
||||
`spv.SLessThanEqual` | `llvm.icmp "sle"`
|
||||
`spv.UGreaterThan` | `llvm.icmp "ugt"`
|
||||
`spv.UGreaterThanEqual` | `llvm.icmp "uge"`
|
||||
`spv.ULessThan` | `llvm.icmp "ult"`
|
||||
`spv.ULessThanEqual` | `llvm.icmp "ule"`
|
||||
SPIR-V Dialect op | LLVM Dialect op
|
||||
:--------------------------: | :---------------:
|
||||
`spv.IEqual` | `llvm.icmp "eq"`
|
||||
`spv.INotEqual` | `llvm.icmp "ne"`
|
||||
`spv.FOrdEqual` | `llvm.fcmp "oeq"`
|
||||
`spv.FOrdGreaterThan` | `llvm.fcmp "ogt"`
|
||||
`spv.FOrdGreaterThanEqual` | `llvm.fcmp "oge"`
|
||||
`spv.FOrdLessThan` | `llvm.fcmp "olt"`
|
||||
`spv.FOrdLessThanEqual` | `llvm.fcmp "ole"`
|
||||
`spv.FOrdNotEqual` | `llvm.fcmp "one"`
|
||||
`spv.FUnordEqual` | `llvm.fcmp "ueq"`
|
||||
`spv.FUnordGreaterThan` | `llvm.fcmp "ugt"`
|
||||
`spv.FUnordGreaterThanEqual` | `llvm.fcmp "uge"`
|
||||
`spv.FUnordLessThan` | `llvm.fcmp "ult"`
|
||||
`spv.FUnordLessThanEqual` | `llvm.fcmp "ule"`
|
||||
`spv.FUnordNotEqual` | `llvm.fcmp "une"`
|
||||
`spv.SGreaterThan` | `llvm.icmp "sgt"`
|
||||
`spv.SGreaterThanEqual` | `llvm.icmp "sge"`
|
||||
`spv.SLessThan` | `llvm.icmp "slt"`
|
||||
`spv.SLessThanEqual` | `llvm.icmp "sle"`
|
||||
`spv.UGreaterThan` | `llvm.icmp "ugt"`
|
||||
`spv.UGreaterThanEqual` | `llvm.icmp "uge"`
|
||||
`spv.ULessThan` | `llvm.icmp "ult"`
|
||||
`spv.ULessThanEqual` | `llvm.icmp "ule"`
|
||||
|
||||
### Composite ops
|
||||
|
||||
|
|
@ -359,12 +360,12 @@ Currently, conversion supports rewrite patterns for `spv.CompositeExtract` and
|
|||
composite object is a vector, and when the composite object is of a non-vector
|
||||
type (*i.e.* struct, array or runtime array).
|
||||
|
||||
Composite type | SPIR-V Dialect op | LLVM Dialect op
|
||||
:-------------: | :--------------------: | :--------------------:
|
||||
vector | `spv.CompositeExtract` | `llvm.extractelement`
|
||||
vector | `spv.CompositeInsert` | `llvm.insertelement`
|
||||
non-vector | `spv.CompositeExtract` | `llvm.extractvalue`
|
||||
non-vector | `spv.CompositeInsert` | `llvm.insertvalue`
|
||||
Composite type | SPIR-V Dialect op | LLVM Dialect op
|
||||
:------------: | :--------------------: | :-------------------:
|
||||
vector | `spv.CompositeExtract` | `llvm.extractelement`
|
||||
vector | `spv.CompositeInsert` | `llvm.insertelement`
|
||||
non-vector | `spv.CompositeExtract` | `llvm.extractvalue`
|
||||
non-vector | `spv.CompositeInsert` | `llvm.insertvalue`
|
||||
|
||||
### `spv.EntryPoint` and `spv.ExecutionMode`
|
||||
|
||||
|
|
@ -381,7 +382,7 @@ entry points in LLVM. At the moment, we use the following approach:
|
|||
struct global variable that stores the execution mode id and any variables
|
||||
associated with it. In C, the struct has the structure shown below.
|
||||
|
||||
```C
|
||||
```c
|
||||
// No values are associated // There are values that are associated
|
||||
// with this entry point. // with this entry point.
|
||||
struct { struct {
|
||||
|
|
@ -406,12 +407,12 @@ Logical ops follow a similar pattern as bitwise ops, with the difference that
|
|||
they operate on `i1` or vector of `i1` values. The following mapping is used to
|
||||
emulate SPIR-V ops behaviour:
|
||||
|
||||
SPIR-V Dialect op | LLVM Dialect op
|
||||
:-----------------------------------: | :-----------------------------------:
|
||||
`spv.LogicalAnd` | `llvm.and`
|
||||
`spv.LogicalOr` | `llvm.or`
|
||||
`spv.LogicalEqual` | `llvm.icmp "eq"`
|
||||
`spv.LogicalNotEqual` | `llvm.icmp "ne"`
|
||||
SPIR-V Dialect op | LLVM Dialect op
|
||||
:-------------------: | :--------------:
|
||||
`spv.LogicalAnd` | `llvm.and`
|
||||
`spv.LogicalOr` | `llvm.or`
|
||||
`spv.LogicalEqual` | `llvm.icmp "eq"`
|
||||
`spv.LogicalNotEqual` | `llvm.icmp "ne"`
|
||||
|
||||
`spv.LogicalNot` has the same conversion pattern as bitwise `spv.Not`. It is
|
||||
modelled with `xor` operation with a mask with all bits set.
|
||||
|
|
@ -468,13 +469,13 @@ following cases, based on the value of the attribute:
|
|||
|
||||
#### `spv.GlobalVariable` and `spv.mlir.addressof`
|
||||
|
||||
`spv.GlobalVariable` is modelled with `llvm.mlir.global` op. However, there
|
||||
is a difference that has to be pointed out.
|
||||
`spv.GlobalVariable` is modelled with `llvm.mlir.global` op. However, there is a
|
||||
difference that has to be pointed out.
|
||||
|
||||
In SPIR-V dialect, the global variable returns a pointer, whereas in LLVM
|
||||
dialect the global holds an actual value. This difference is handled by
|
||||
`spv.mlir.addressof` and `llvm.mlir.addressof` ops that both return a pointer and
|
||||
are used to reference the global.
|
||||
`spv.mlir.addressof` and `llvm.mlir.addressof` ops that both return a pointer
|
||||
and are used to reference the global.
|
||||
|
||||
```mlir
|
||||
// Original SPIR-V module
|
||||
|
|
@ -496,9 +497,9 @@ module {
|
|||
}
|
||||
```
|
||||
|
||||
The SPIR-V to LLVM conversion does not involve modelling of workgroups.
|
||||
Hence, we say that only current invocation is in conversion's scope. This means
|
||||
that global variables with pointers of `Input`, `Output`, and `Private` storage
|
||||
The SPIR-V to LLVM conversion does not involve modelling of workgroups. Hence,
|
||||
we say that only current invocation is in conversion's scope. This means that
|
||||
global variables with pointers of `Input`, `Output`, and `Private` storage
|
||||
classes are supported. Also, `StorageBuffer` storage class is allowed for
|
||||
executing [`mlir-spirv-cpu-runner`](#mlir-spirv-cpu-runner).
|
||||
|
||||
|
|
@ -510,8 +511,8 @@ Currently `llvm.mlir.global`s are created with `private` linkage for `Private`
|
|||
storage class and `External` for other storage classes, based on SPIR-V spec:
|
||||
|
||||
> By default, functions and global variables are private to a module and cannot
|
||||
be accessed by other modules. However, a module may be written to export or
|
||||
import functions and global (module scope) variables.
|
||||
> be accessed by other modules. However, a module may be written to export or
|
||||
> import functions and global (module scope) variables.
|
||||
|
||||
If the global variable's pointer has `Input` storage class, then a `constant`
|
||||
flag is added to LLVM op:
|
||||
|
|
@ -554,10 +555,10 @@ There are multiple SPIR-V ops that do not fit in a particular group but can be
|
|||
converted directly to LLVM dialect. Their conversion is addressed in this
|
||||
section.
|
||||
|
||||
SPIR-V Dialect op | LLVM Dialect op
|
||||
:-----------------------------------: | :-----------------------------------:
|
||||
`spv.Select` | `llvm.select`
|
||||
`spv.Undef` | `llvm.mlir.undef`
|
||||
SPIR-V Dialect op | LLVM Dialect op
|
||||
:---------------: | :---------------:
|
||||
`spv.Select` | `llvm.select`
|
||||
`spv.Undef` | `llvm.mlir.undef`
|
||||
|
||||
### Shift ops
|
||||
|
||||
|
|
@ -665,10 +666,10 @@ spv.FunctionCall @bar(%0) : (i32) -> () => llvm.call @bar(%0) : (f32) ->
|
|||
|
||||
### `spv.mlir.selection` and `spv.mlir.loop`
|
||||
|
||||
Control flow within `spv.mlir.selection` and `spv.mlir.loop` is lowered directly to LLVM
|
||||
via branch ops. The conversion can only be applied to selection or loop with all
|
||||
blocks being reachable. Moreover, selection and loop control attributes (such as
|
||||
`Flatten` or `Unroll`) are not supported at the moment.
|
||||
Control flow within `spv.mlir.selection` and `spv.mlir.loop` is lowered directly
|
||||
to LLVM via branch ops. The conversion can only be applied to selection or loop
|
||||
with all blocks being reachable. Moreover, selection and loop control attributes
|
||||
(such as `Flatten` or `Unroll`) are not supported at the moment.
|
||||
|
||||
```mlir
|
||||
// Conversion of selection
|
||||
|
|
@ -727,20 +728,20 @@ mapped to LLVM Dialect.
|
|||
|
||||
### Direct conversions
|
||||
|
||||
SPIR-V Dialect op | LLVM Dialect op
|
||||
:-----------------------------------: | :-----------------------------------:
|
||||
`spv.GLSL.Ceil` | `llvm.intr.ceil`
|
||||
`spv.GLSL.Cos` | `llvm.intr.cos`
|
||||
`spv.GLSL.Exp` | `llvm.intr.exp`
|
||||
`spv.GLSL.FAbs` | `llvm.intr.fabs`
|
||||
`spv.GLSL.Floor` | `llvm.intr.floor`
|
||||
`spv.GLSL.FMax` | `llvm.intr.maxnum`
|
||||
`spv.GLSL.FMin` | `llvm.intr.minnum`
|
||||
`spv.GLSL.Log` | `llvm.intr.log`
|
||||
`spv.GLSL.Sin` | `llvm.intr.sin`
|
||||
`spv.GLSL.Sqrt` | `llvm.intr.sqrt`
|
||||
`spv.GLSL.SMax` | `llvm.intr.smax`
|
||||
`spv.GLSL.SMin` | `llvm.intr.smin`
|
||||
SPIR-V Dialect op | LLVM Dialect op
|
||||
:---------------: | :----------------:
|
||||
`spv.GLSL.Ceil` | `llvm.intr.ceil`
|
||||
`spv.GLSL.Cos` | `llvm.intr.cos`
|
||||
`spv.GLSL.Exp` | `llvm.intr.exp`
|
||||
`spv.GLSL.FAbs` | `llvm.intr.fabs`
|
||||
`spv.GLSL.Floor` | `llvm.intr.floor`
|
||||
`spv.GLSL.FMax` | `llvm.intr.maxnum`
|
||||
`spv.GLSL.FMin` | `llvm.intr.minnum`
|
||||
`spv.GLSL.Log` | `llvm.intr.log`
|
||||
`spv.GLSL.Sin` | `llvm.intr.sin`
|
||||
`spv.GLSL.Sqrt` | `llvm.intr.sqrt`
|
||||
`spv.GLSL.SMax` | `llvm.intr.smax`
|
||||
`spv.GLSL.SMin` | `llvm.intr.smin`
|
||||
|
||||
### Special cases
|
||||
|
||||
|
|
@ -760,7 +761,8 @@ SPIR-V Dialect op | LLVM Dialect op
|
|||
%res = fdiv %sin, %cos : f32
|
||||
```
|
||||
|
||||
`spv.Tanh` is modelled using the equality `tanh(x) = {exp(2x) - 1}/{exp(2x) + 1}`:
|
||||
`spv.Tanh` is modelled using the equality `tanh(x) = {exp(2x) - 1}/{exp(2x) +
|
||||
1}`:
|
||||
|
||||
```mlir
|
||||
%two = llvm.mlir.constant(2.0: f32) : f32
|
||||
|
|
@ -778,20 +780,23 @@ This section describes the conversion of function-related operations from SPIR-V
|
|||
to LLVM dialect.
|
||||
|
||||
### `spv.func`
|
||||
This op declares or defines a SPIR-V function and it is converted to `llvm.func`.
|
||||
This conversion handles signature conversion, and function control attributes
|
||||
remapping to LLVM dialect function [`passthrough` attribute](Dialects/LLVM.md/#attribute-pass-through).
|
||||
|
||||
The following mapping is used to map [SPIR-V function control][SPIRVFunctionAttributes] to
|
||||
This op declares or defines a SPIR-V function and it is converted to
|
||||
`llvm.func`. This conversion handles signature conversion, and function control
|
||||
attributes remapping to LLVM dialect function
|
||||
[`passthrough` attribute](Dialects/LLVM.md/#attribute-pass-through).
|
||||
|
||||
The following mapping is used to map
|
||||
[SPIR-V function control][SPIRVFunctionAttributes] to
|
||||
[LLVM function attributes][LLVMFunctionAttributes]:
|
||||
|
||||
SPIR-V Function Control Attributes | LLVM Function Attributes
|
||||
:-----------------------------------: | :-----------------------------------:
|
||||
None | No function attributes passed
|
||||
Inline | `alwaysinline`
|
||||
DontInline | `noinline`
|
||||
Pure | `readonly`
|
||||
Const | `readnone`
|
||||
SPIR-V Function Control Attributes | LLVM Function Attributes
|
||||
:--------------------------------: | :---------------------------:
|
||||
None | No function attributes passed
|
||||
Inline | `alwaysinline`
|
||||
DontInline | `noinline`
|
||||
Pure | `readonly`
|
||||
Const | `readnone`
|
||||
|
||||
### `spv.Return` and `spv.ReturnValue`
|
||||
|
||||
|
|
@ -816,10 +821,8 @@ to LLVM ops. At the moment, SPIR-V module attributes are ignored.
|
|||
SPIR-V to LLVM dialect conversion. Currently, only single-threaded kernel is
|
||||
supported.
|
||||
|
||||
To build the runner, add the following option to `cmake`:
|
||||
```bash
|
||||
-DMLIR_ENABLE_SPIRV_CPU_RUNNER=1
|
||||
```
|
||||
To build the runner, add the following option to `cmake`: `bash
|
||||
-DMLIR_ENABLE_SPIRV_CPU_RUNNER=1`
|
||||
|
||||
### Pipeline
|
||||
|
||||
|
|
@ -857,7 +860,7 @@ gpu.module @foo {
|
|||
|
||||
func @main() {
|
||||
// Fill the buffer with some data
|
||||
%buffer = alloc : memref<8xi32>
|
||||
%buffer = memref.alloc : memref<8xi32>
|
||||
%data = ...
|
||||
call fillBuffer(%buffer, %data)
|
||||
|
||||
|
|
@ -880,7 +883,7 @@ spv.module @__spv__foo /*VCE triple and other metadata here*/ {
|
|||
|
||||
func @main() {
|
||||
// Fill the buffer with some data.
|
||||
%buffer = alloc : memref<8xi32>
|
||||
%buffer = memref.alloc : memref<8xi32>
|
||||
%data = ...
|
||||
call fillBuffer(%buffer, %data)
|
||||
|
||||
|
|
|
|||
|
|
@ -2,11 +2,11 @@
|
|||
|
||||
[TOC]
|
||||
|
||||
With [Regions](LangRef.md/#regions), the multi-level aspect of MLIR is structural
|
||||
in the IR. A lot of infrastructure within the compiler is built around this
|
||||
nesting structure; including the processing of operations within the
|
||||
[pass manager](PassManagement.md/#pass-manager). One advantage of the MLIR design
|
||||
is that it is able to process operations in parallel, utilizing multiple
|
||||
With [Regions](LangRef.md/#regions), the multi-level aspect of MLIR is
|
||||
structural in the IR. A lot of infrastructure within the compiler is built
|
||||
around this nesting structure; including the processing of operations within the
|
||||
[pass manager](PassManagement.md/#pass-manager). One advantage of the MLIR
|
||||
design is that it is able to process operations in parallel, utilizing multiple
|
||||
threads. This is possible due to a property of the IR known as
|
||||
[`IsolatedFromAbove`](Traits.md/#isolatedfromabove).
|
||||
|
||||
|
|
@ -137,13 +137,13 @@ operations that materialize SSA values from a symbol reference. Each has
|
|||
different trade offs depending on the situation. A function call may directly
|
||||
use a `SymbolRef` as the callee, whereas a reference to a global variable might
|
||||
use a materialization operation so that the variable can be used in other
|
||||
operations like `std.addi`.
|
||||
[`llvm.mlir.addressof`](Dialects/LLVM.md/#llvmmliraddressof-mlirllvmaddressofop) is one example of
|
||||
such an operation.
|
||||
operations like `arith.addi`.
|
||||
[`llvm.mlir.addressof`](Dialects/LLVM.md/#llvmmliraddressof-mlirllvmaddressofop)
|
||||
is one example of such an operation.
|
||||
|
||||
See the `LangRef` definition of the
|
||||
[`SymbolRefAttr`](Dialects/Builtin.md/#symbolrefattr) for more information
|
||||
about the structure of this attribute.
|
||||
[`SymbolRefAttr`](Dialects/Builtin.md/#symbolrefattr) for more information about
|
||||
the structure of this attribute.
|
||||
|
||||
Operations that reference a `Symbol` and want to perform verification and
|
||||
general mutation of the symbol should implement the `SymbolUserOpInterface` to
|
||||
|
|
|
|||
|
|
@ -305,8 +305,8 @@ func @foo(%arg0: i32, %arg1: i64) -> (i32, i64) {
|
|||
return %arg0, %arg1 : i32, i64
|
||||
}
|
||||
func @bar() {
|
||||
%0 = constant 42 : i32
|
||||
%1 = constant 17 : i64
|
||||
%0 = arith.constant 42 : i32
|
||||
%1 = arith.constant 17 : i64
|
||||
%2:2 = call @foo(%0, %1) : (i32, i64) -> (i32, i64)
|
||||
"use_i32"(%2#0) : (i32) -> ()
|
||||
"use_i64"(%2#1) : (i64) -> ()
|
||||
|
|
@ -768,7 +768,7 @@ Examples:
|
|||
An access to a memref with indices:
|
||||
|
||||
```mlir
|
||||
%0 = load %m[%1,%2,%3,%4] : memref<?x?x4x8xf32, offset: ?>
|
||||
%0 = memref.load %m[%1,%2,%3,%4] : memref<?x?x4x8xf32, offset: ?>
|
||||
```
|
||||
|
||||
is transformed into the equivalent of the following code:
|
||||
|
|
@ -779,27 +779,27 @@ is transformed into the equivalent of the following code:
|
|||
// dynamic, extract the stride value from the descriptor.
|
||||
%stride1 = llvm.extractvalue[4, 0] : !llvm.struct<(ptr<f32>, ptr<f32>, i64,
|
||||
array<4xi64>, array<4xi64>)>
|
||||
%addr1 = muli %stride1, %1 : i64
|
||||
%addr1 = arith.muli %stride1, %1 : i64
|
||||
|
||||
// When the stride or, in absence of explicit strides, the trailing sizes are
|
||||
// known statically, this value is used as a constant. The natural value of
|
||||
// strides is the product of all sizes following the current dimension.
|
||||
%stride2 = llvm.mlir.constant(32 : index) : i64
|
||||
%addr2 = muli %stride2, %2 : i64
|
||||
%addr3 = addi %addr1, %addr2 : i64
|
||||
%addr2 = arith.muli %stride2, %2 : i64
|
||||
%addr3 = arith.addi %addr1, %addr2 : i64
|
||||
|
||||
%stride3 = llvm.mlir.constant(8 : index) : i64
|
||||
%addr4 = muli %stride3, %3 : i64
|
||||
%addr5 = addi %addr3, %addr4 : i64
|
||||
%addr4 = arith.muli %stride3, %3 : i64
|
||||
%addr5 = arith.addi %addr3, %addr4 : i64
|
||||
|
||||
// Multiplication with the known unit stride can be omitted.
|
||||
%addr6 = addi %addr5, %4 : i64
|
||||
%addr6 = arith.addi %addr5, %4 : i64
|
||||
|
||||
// If the linear offset is known to be zero, it can also be omitted. If it is
|
||||
// dynamic, it is extracted from the descriptor.
|
||||
%offset = llvm.extractvalue[2] : !llvm.struct<(ptr<f32>, ptr<f32>, i64,
|
||||
array<4xi64>, array<4xi64>)>
|
||||
%addr7 = addi %addr6, %offset : i64
|
||||
%addr7 = arith.addi %addr6, %offset : i64
|
||||
|
||||
// All accesses are based on the aligned pointer.
|
||||
%aligned = llvm.extractvalue[1] : !llvm.struct<(ptr<f32>, ptr<f32>, i64,
|
||||
|
|
|
|||
|
|
@ -56,13 +56,12 @@ Note: It is generally good practice to define the implementation of the
|
|||
`verifyTrait` hook out-of-line as a free function when possible to avoid
|
||||
instantiating the implementation for every concrete operation type.
|
||||
|
||||
Operation traits may also provide a `foldTrait` hook that is called when
|
||||
folding the concrete operation. The trait folders will only be invoked if
|
||||
the concrete operation fold is either not implemented, fails, or performs
|
||||
an in-place fold.
|
||||
Operation traits may also provide a `foldTrait` hook that is called when folding
|
||||
the concrete operation. The trait folders will only be invoked if the concrete
|
||||
operation fold is either not implemented, fails, or performs an in-place fold.
|
||||
|
||||
The following signature of fold will be called if it is implemented
|
||||
and the op has a single result.
|
||||
The following signature of fold will be called if it is implemented and the op
|
||||
has a single result.
|
||||
|
||||
```c++
|
||||
template <typename ConcreteType>
|
||||
|
|
@ -76,8 +75,8 @@ public:
|
|||
};
|
||||
```
|
||||
|
||||
Otherwise, if the operation has a single result and the above signature is
|
||||
not implemented, or the operation has multiple results, then the following signature
|
||||
Otherwise, if the operation has a single result and the above signature is not
|
||||
implemented, or the operation has multiple results, then the following signature
|
||||
will be used (if implemented):
|
||||
|
||||
```c++
|
||||
|
|
@ -200,9 +199,9 @@ defined at the top-level of such operations, or appear as region arguments for
|
|||
such operations automatically become valid symbols for the polyhedral scope
|
||||
defined by that operation. As a result, such SSA values could be used as the
|
||||
operands or index operands of various affine dialect operations like affine.for,
|
||||
affine.load, and affine.store. The polyhedral scope defined by an operation
|
||||
with this trait includes all operations in its region excluding operations that
|
||||
are nested inside of other operations that themselves have this trait.
|
||||
affine.load, and affine.store. The polyhedral scope defined by an operation with
|
||||
this trait includes all operations in its region excluding operations that are
|
||||
nested inside of other operations that themselves have this trait.
|
||||
|
||||
### AutomaticAllocationScope
|
||||
|
||||
|
|
@ -211,7 +210,8 @@ are nested inside of other operations that themselves have this trait.
|
|||
This trait is carried by region holding operations that define a new scope for
|
||||
automatic allocation. Such allocations are automatically freed when control is
|
||||
transferred back from the regions of such operations. As an example, allocations
|
||||
performed by [`memref.alloca`](Dialects/MemRef.md/#memrefalloca-mlirmemrefallocaop) are
|
||||
performed by
|
||||
[`memref.alloca`](Dialects/MemRef.md/#memrefalloca-mlirmemrefallocaop) are
|
||||
automatically freed when control leaves the region of its closest surrounding op
|
||||
that has the trait AutomaticAllocationScope.
|
||||
|
||||
|
|
@ -241,7 +241,7 @@ Y op X`
|
|||
|
||||
### ElementwiseMappable
|
||||
|
||||
* `OpTrait::ElementwiseMappable` -- `ElementwiseMappable`
|
||||
* `OpTrait::ElementwiseMappable` -- `ElementwiseMappable`
|
||||
|
||||
This trait tags scalar ops that also can be applied to vectors/tensors, with
|
||||
their semantics on vectors/tensors being elementwise application. This trait
|
||||
|
|
@ -300,7 +300,7 @@ that the following is invalid if `foo.region_op` is defined as
|
|||
`IsolatedFromAbove`:
|
||||
|
||||
```mlir
|
||||
%result = constant 10 : i32
|
||||
%result = arith.constant 10 : i32
|
||||
foo.region_op {
|
||||
foo.yield %result : i32
|
||||
}
|
||||
|
|
@ -311,14 +311,13 @@ to have [passes](PassManagement.md) scheduled under them.
|
|||
|
||||
### MemRefsNormalizable
|
||||
|
||||
* `OpTrait::MemRefsNormalizable` -- `MemRefsNormalizable`
|
||||
* `OpTrait::MemRefsNormalizable` -- `MemRefsNormalizable`
|
||||
|
||||
This trait is used to flag operations that consume or produce
|
||||
values of `MemRef` type where those references can be 'normalized'.
|
||||
In cases where an associated `MemRef` has a
|
||||
non-identity memory-layout specification, such normalizable operations can be
|
||||
modified so that the `MemRef` has an identity layout specification.
|
||||
This can be implemented by associating the operation with its own
|
||||
This trait is used to flag operations that consume or produce values of `MemRef`
|
||||
type where those references can be 'normalized'. In cases where an associated
|
||||
`MemRef` has a non-identity memory-layout specification, such normalizable
|
||||
operations can be modified so that the `MemRef` has an identity layout
|
||||
specification. This can be implemented by associating the operation with its own
|
||||
index expression that can express the equivalent of the memory-layout
|
||||
specification of the MemRef type. See [the -normalize-memrefs pass].
|
||||
(https://mlir.llvm.org/docs/Passes/#-normalize-memrefs-normalize-memrefs)
|
||||
|
|
|
|||
|
|
@ -15,20 +15,20 @@ part of the program and is limited: it doesn't support representing our
|
|||
`Affine` for the computation heavy part of Toy, and in the
|
||||
[next chapter](Ch-6.md) directly target the `LLVM IR` dialect for lowering
|
||||
`print`. As part of this lowering, we will be lowering from the
|
||||
[TensorType](../../Dialects/Builtin.md/#rankedtensortype) that `Toy`
|
||||
operates on to the [MemRefType](../../Dialects/Builtin.md/#memreftype) that is
|
||||
indexed via an affine loop-nest. Tensors represent an abstract value-typed
|
||||
sequence of data, meaning that they don't live in any memory. MemRefs, on the
|
||||
other hand, represent lower level buffer access, as they are concrete
|
||||
references to a region of memory.
|
||||
[TensorType](../../Dialects/Builtin.md/#rankedtensortype) that `Toy` operates on
|
||||
to the [MemRefType](../../Dialects/Builtin.md/#memreftype) that is indexed via
|
||||
an affine loop-nest. Tensors represent an abstract value-typed sequence of data,
|
||||
meaning that they don't live in any memory. MemRefs, on the other hand,
|
||||
represent lower level buffer access, as they are concrete references to a region
|
||||
of memory.
|
||||
|
||||
# Dialect Conversions
|
||||
|
||||
MLIR has many different dialects, so it is important to have a unified framework
|
||||
for [converting](../../../getting_started/Glossary.md/#conversion) between them. This is where the
|
||||
`DialectConversion` framework comes into play. This framework allows for
|
||||
transforming a set of *illegal* operations to a set of *legal* ones. To use this
|
||||
framework, we need to provide two things (and an optional third):
|
||||
for [converting](../../../getting_started/Glossary.md/#conversion) between them.
|
||||
This is where the `DialectConversion` framework comes into play. This framework
|
||||
allows for transforming a set of *illegal* operations to a set of *legal* ones.
|
||||
To use this framework, we need to provide two things (and an optional third):
|
||||
|
||||
* A [Conversion Target](../../DialectConversion.md/#conversion-target)
|
||||
|
||||
|
|
@ -40,8 +40,8 @@ framework, we need to provide two things (and an optional third):
|
|||
* A set of
|
||||
[Rewrite Patterns](../../DialectConversion.md/#rewrite-pattern-specification)
|
||||
|
||||
- This is the set of [patterns](../QuickstartRewrites.md) used to
|
||||
convert *illegal* operations into a set of zero or more *legal* ones.
|
||||
- This is the set of [patterns](../QuickstartRewrites.md) used to convert
|
||||
*illegal* operations into a set of zero or more *legal* ones.
|
||||
|
||||
* Optionally, a [Type Converter](../../DialectConversion.md/#type-conversion).
|
||||
|
||||
|
|
@ -63,9 +63,9 @@ void ToyToAffineLoweringPass::runOnFunction() {
|
|||
|
||||
// We define the specific operations, or dialects, that are legal targets for
|
||||
// this lowering. In our case, we are lowering to a combination of the
|
||||
// `Affine`, `MemRef` and `Standard` dialects.
|
||||
target.addLegalDialect<mlir::AffineDialect, mlir::memref::MemRefDialect,
|
||||
mlir::StandardOpsDialect>();
|
||||
// `Affine`, `Arithmetic`, `MemRef`, and `Standard` dialects.
|
||||
target.addLegalDialect<AffineDialect, arith::ArithmeticDialect,
|
||||
memref::MemRefDialect, StandardOpsDialect>();
|
||||
|
||||
// We also define the Toy dialect as Illegal so that the conversion will fail
|
||||
// if any of these operations are *not* converted. Given that we actually want
|
||||
|
|
@ -77,11 +77,10 @@ void ToyToAffineLoweringPass::runOnFunction() {
|
|||
}
|
||||
```
|
||||
|
||||
Above, we first set the toy dialect to illegal, and then the print operation
|
||||
as legal. We could have done this the other way around.
|
||||
Individual operations always take precedence over the (more generic) dialect
|
||||
definitions, so the order doesn't matter. See `ConversionTarget::getOpInfo`
|
||||
for the details.
|
||||
Above, we first set the toy dialect to illegal, and then the print operation as
|
||||
legal. We could have done this the other way around. Individual operations
|
||||
always take precedence over the (more generic) dialect definitions, so the order
|
||||
doesn't matter. See `ConversionTarget::getOpInfo` for the details.
|
||||
|
||||
## Conversion Patterns
|
||||
|
||||
|
|
@ -97,9 +96,9 @@ additional `operands` parameter containing operands that have been
|
|||
remapped/replaced. This is used when dealing with type conversions, as the
|
||||
pattern will want to operate on values of the new type but match against the
|
||||
old. For our lowering, this invariant will be useful as it translates from the
|
||||
[TensorType](../../Dialects/Builtin.md/#rankedtensortype) currently
|
||||
being operated on to the [MemRefType](../../Dialects/Builtin.md/#memreftype).
|
||||
Let's look at a snippet of lowering the `toy.transpose` operation:
|
||||
[TensorType](../../Dialects/Builtin.md/#rankedtensortype) currently being
|
||||
operated on to the [MemRefType](../../Dialects/Builtin.md/#memreftype). Let's
|
||||
look at a snippet of lowering the `toy.transpose` operation:
|
||||
|
||||
```c++
|
||||
/// Lower the `toy.transpose` operation to an affine loop nest.
|
||||
|
|
@ -185,29 +184,29 @@ many ways to go about this, each with their own tradeoffs:
|
|||
|
||||
* Generate `load` operations from the buffer
|
||||
|
||||
One option is to generate `load` operations from the buffer type to materialize
|
||||
an instance of the value type. This allows for the definition of the `toy.print`
|
||||
operation to remain unchanged. The downside to this approach is that the
|
||||
optimizations on the `affine` dialect are limited, because the `load` will
|
||||
actually involve a full copy that is only visible *after* our optimizations have
|
||||
been performed.
|
||||
One option is to generate `load` operations from the buffer type to
|
||||
materialize an instance of the value type. This allows for the definition of
|
||||
the `toy.print` operation to remain unchanged. The downside to this approach
|
||||
is that the optimizations on the `affine` dialect are limited, because the
|
||||
`load` will actually involve a full copy that is only visible *after* our
|
||||
optimizations have been performed.
|
||||
|
||||
* Generate a new version of `toy.print` that operates on the lowered type
|
||||
|
||||
Another option would be to have another, lowered, variant of `toy.print` that
|
||||
operates on the lowered type. The benefit of this option is that there is no
|
||||
hidden, unnecessary copy to the optimizer. The downside is that another
|
||||
operation definition is needed that may duplicate many aspects of the first.
|
||||
Defining a base class in [ODS](../../OpDefinitions.md) may simplify this, but
|
||||
you still need to treat these operations separately.
|
||||
Another option would be to have another, lowered, variant of `toy.print`
|
||||
that operates on the lowered type. The benefit of this option is that there
|
||||
is no hidden, unnecessary copy to the optimizer. The downside is that
|
||||
another operation definition is needed that may duplicate many aspects of
|
||||
the first. Defining a base class in [ODS](../../OpDefinitions.md) may
|
||||
simplify this, but you still need to treat these operations separately.
|
||||
|
||||
* Update `toy.print` to allow for operating on the lowered type
|
||||
|
||||
A third option is to update the current definition of `toy.print` to allow for
|
||||
operating the on the lowered type. The benefit of this approach is that it is
|
||||
simple, does not introduce an additional hidden copy, and does not require
|
||||
another operation definition. The downside to this option is that it requires
|
||||
mixing abstraction levels in the `Toy` dialect.
|
||||
A third option is to update the current definition of `toy.print` to allow
|
||||
for operating the on the lowered type. The benefit of this approach is that
|
||||
it is simple, does not introduce an additional hidden copy, and does not
|
||||
require another operation definition. The downside to this option is that it
|
||||
requires mixing abstraction levels in the `Toy` dialect.
|
||||
|
||||
For the sake of simplicity, we will use the third option for this lowering. This
|
||||
involves updating the type constraints on the PrintOp in the operation
|
||||
|
|
@ -241,17 +240,17 @@ With affine lowering added to our pipeline, we can now generate:
|
|||
|
||||
```mlir
|
||||
func @main() {
|
||||
%cst = constant 1.000000e+00 : f64
|
||||
%cst_0 = constant 2.000000e+00 : f64
|
||||
%cst_1 = constant 3.000000e+00 : f64
|
||||
%cst_2 = constant 4.000000e+00 : f64
|
||||
%cst_3 = constant 5.000000e+00 : f64
|
||||
%cst_4 = constant 6.000000e+00 : f64
|
||||
%cst = arith.constant 1.000000e+00 : f64
|
||||
%cst_0 = arith.constant 2.000000e+00 : f64
|
||||
%cst_1 = arith.constant 3.000000e+00 : f64
|
||||
%cst_2 = arith.constant 4.000000e+00 : f64
|
||||
%cst_3 = arith.constant 5.000000e+00 : f64
|
||||
%cst_4 = arith.constant 6.000000e+00 : f64
|
||||
|
||||
// Allocating buffers for the inputs and outputs.
|
||||
%0 = alloc() : memref<3x2xf64>
|
||||
%1 = alloc() : memref<3x2xf64>
|
||||
%2 = alloc() : memref<2x3xf64>
|
||||
%0 = memref.alloc() : memref<3x2xf64>
|
||||
%1 = memref.alloc() : memref<3x2xf64>
|
||||
%2 = memref.alloc() : memref<2x3xf64>
|
||||
|
||||
// Initialize the input buffer with the constant values.
|
||||
affine.store %cst, %2[0, 0] : memref<2x3xf64>
|
||||
|
|
@ -275,16 +274,16 @@ func @main() {
|
|||
affine.for %arg1 = 0 to 2 {
|
||||
%3 = affine.load %1[%arg0, %arg1] : memref<3x2xf64>
|
||||
%4 = affine.load %1[%arg0, %arg1] : memref<3x2xf64>
|
||||
%5 = mulf %3, %4 : f64
|
||||
%5 = arith.mulf %3, %4 : f64
|
||||
affine.store %5, %0[%arg0, %arg1] : memref<3x2xf64>
|
||||
}
|
||||
}
|
||||
|
||||
// Print the value held by the buffer.
|
||||
toy.print %0 : memref<3x2xf64>
|
||||
dealloc %2 : memref<2x3xf64>
|
||||
dealloc %1 : memref<3x2xf64>
|
||||
dealloc %0 : memref<3x2xf64>
|
||||
memref.dealloc %2 : memref<2x3xf64>
|
||||
memref.dealloc %1 : memref<3x2xf64>
|
||||
memref.dealloc %0 : memref<3x2xf64>
|
||||
return
|
||||
}
|
||||
```
|
||||
|
|
@ -299,16 +298,16 @@ the pipeline gives the following result:
|
|||
|
||||
```mlir
|
||||
func @main() {
|
||||
%cst = constant 1.000000e+00 : f64
|
||||
%cst_0 = constant 2.000000e+00 : f64
|
||||
%cst_1 = constant 3.000000e+00 : f64
|
||||
%cst_2 = constant 4.000000e+00 : f64
|
||||
%cst_3 = constant 5.000000e+00 : f64
|
||||
%cst_4 = constant 6.000000e+00 : f64
|
||||
%cst = arith.constant 1.000000e+00 : f64
|
||||
%cst_0 = arith.constant 2.000000e+00 : f64
|
||||
%cst_1 = arith.constant 3.000000e+00 : f64
|
||||
%cst_2 = arith.constant 4.000000e+00 : f64
|
||||
%cst_3 = arith.constant 5.000000e+00 : f64
|
||||
%cst_4 = arith.constant 6.000000e+00 : f64
|
||||
|
||||
// Allocating buffers for the inputs and outputs.
|
||||
%0 = alloc() : memref<3x2xf64>
|
||||
%1 = alloc() : memref<2x3xf64>
|
||||
%0 = memref.alloc() : memref<3x2xf64>
|
||||
%1 = memref.alloc() : memref<2x3xf64>
|
||||
|
||||
// Initialize the input buffer with the constant values.
|
||||
affine.store %cst, %1[0, 0] : memref<2x3xf64>
|
||||
|
|
@ -324,15 +323,15 @@ func @main() {
|
|||
%2 = affine.load %1[%arg1, %arg0] : memref<2x3xf64>
|
||||
|
||||
// Multiply and store into the output buffer.
|
||||
%3 = mulf %2, %2 : f64
|
||||
%3 = arith.mulf %2, %2 : f64
|
||||
affine.store %3, %0[%arg0, %arg1] : memref<3x2xf64>
|
||||
}
|
||||
}
|
||||
|
||||
// Print the value held by the buffer.
|
||||
toy.print %0 : memref<3x2xf64>
|
||||
dealloc %1 : memref<2x3xf64>
|
||||
dealloc %0 : memref<3x2xf64>
|
||||
memref.dealloc %1 : memref<2x3xf64>
|
||||
memref.dealloc %0 : memref<3x2xf64>
|
||||
return
|
||||
}
|
||||
```
|
||||
|
|
|
|||
|
|
@ -16,12 +16,13 @@ lowered all but one of the `toy` operations, with the last being `toy.print`.
|
|||
Before going over the conversion to LLVM, let's lower the `toy.print` operation.
|
||||
We will lower this operation to a non-affine loop nest that invokes `printf` for
|
||||
each element. Note that, because the dialect conversion framework supports
|
||||
[transitive lowering](../../../getting_started/Glossary.md/#transitive-lowering), we don't need to
|
||||
directly emit operations in the LLVM dialect. By transitive lowering, we mean
|
||||
that the conversion framework may apply multiple patterns to fully legalize an
|
||||
operation. In this example, we are generating a structured loop nest instead of
|
||||
the branch-form in the LLVM dialect. As long as we then have a lowering from the
|
||||
loop operations to LLVM, the lowering will still succeed.
|
||||
[transitive lowering](../../../getting_started/Glossary.md/#transitive-lowering),
|
||||
we don't need to directly emit operations in the LLVM dialect. By transitive
|
||||
lowering, we mean that the conversion framework may apply multiple patterns to
|
||||
fully legalize an operation. In this example, we are generating a structured
|
||||
loop nest instead of the branch-form in the LLVM dialect. As long as we then
|
||||
have a lowering from the loop operations to LLVM, the lowering will still
|
||||
succeed.
|
||||
|
||||
During lowering we can get, or build, the declaration for printf as so:
|
||||
|
||||
|
|
@ -84,15 +85,17 @@ enough for our use case.
|
|||
|
||||
Now that the conversion target has been defined, we need to provide the patterns
|
||||
used for lowering. At this point in the compilation process, we have a
|
||||
combination of `toy`, `affine`, and `std` operations. Luckily, the `std` and
|
||||
`affine` dialects already provide the set of patterns needed to transform them
|
||||
into LLVM dialect. These patterns allow for lowering the IR in multiple stages
|
||||
by relying on [transitive lowering](../../../getting_started/Glossary.md/#transitive-lowering).
|
||||
combination of `toy`, `affine`, `arith`, and `std` operations. Luckily, the
|
||||
`affine`, `arith`, and `std` dialects already provide the set of patterns needed
|
||||
to transform them into LLVM dialect. These patterns allow for lowering the IR in
|
||||
multiple stages by relying on
|
||||
[transitive lowering](../../../getting_started/Glossary.md/#transitive-lowering).
|
||||
|
||||
```c++
|
||||
mlir::RewritePatternSet patterns(&getContext());
|
||||
mlir::populateAffineToStdConversionPatterns(patterns, &getContext());
|
||||
mlir::populateLoopToStdConversionPatterns(patterns, &getContext());
|
||||
mlir::populateArithmeticToLLVMConversionPatterns(typeConverter, patterns);
|
||||
mlir::populateStdToLLVMConversionPatterns(typeConverter, patterns);
|
||||
|
||||
// The only remaining operation, to lower from the `toy` dialect, is the
|
||||
|
|
@ -200,7 +203,7 @@ define void @main() {
|
|||
%106 = mul i64 %100, 1
|
||||
%107 = add i64 %105, %106
|
||||
%108 = getelementptr double, double* %103, i64 %107
|
||||
%109 = load double, double* %108
|
||||
%109 = memref.load double, double* %108
|
||||
%110 = call i32 (i8*, ...) @printf(i8* getelementptr inbounds ([4 x i8], [4 x i8]* @frmt_spec, i64 0, i64 0), double %109)
|
||||
%111 = add i64 %100, 1
|
||||
br label %99
|
||||
|
|
@ -322,7 +325,7 @@ You can also play with `-emit=mlir`, `-emit=mlir-affine`, `-emit=mlir-llvm`, and
|
|||
[`--print-ir-after-all`](../../PassManagement.md/#ir-printing) to track the
|
||||
evolution of the IR throughout the pipeline.
|
||||
|
||||
The example code used throughout this section can be found in
|
||||
The example code used throughout this section can be found in
|
||||
test/Examples/Toy/Ch6/llvm-lowering.mlir.
|
||||
|
||||
So far, we have worked with primitive data types. In the
|
||||
|
|
|
|||
{kind=link}
|
|
@ -414,6 +414,6 @@
|
|||
id="tspan3407"
|
||||
x="21.911886"
|
||||
y="15.884925"
|
||||
style="font-size:5.64444px;fill:#008000;stroke-width:0.264583">%0 = alloc()</tspan></text>
|
||||
style="font-size:5.64444px;fill:#008000;stroke-width:0.264583">%0 = memref.alloc()</tspan></text>
|
||||
</g>
|
||||
</svg>
|
||||
|
|
|
|||
|
Before Width: | Height: | Size: 15 KiB After Width: | Height: | Size: 15 KiB |
{kind=link}
|
|
@ -353,7 +353,7 @@
|
|||
transform="translate(8.4353227,-0.28369449)"><tspan
|
||||
x="73.476562"
|
||||
y="74.182797"><tspan
|
||||
style="fill:#d40000;fill-opacity:1">%0 = alloc()</tspan><tspan
|
||||
style="fill:#d40000;fill-opacity:1">%0 = memref.alloc()</tspan><tspan
|
||||
style="font-size:5.64444px">
|
||||
</tspan></tspan><tspan
|
||||
x="73.476562"
|
||||
|
|
|
|||
|
Before Width: | Height: | Size: 15 KiB After Width: | Height: | Size: 15 KiB |
{kind=link}
|
|
@ -676,7 +676,7 @@
|
|||
id="tspan9336"
|
||||
x="137.07773"
|
||||
y="78.674141"
|
||||
style="font-size:5.64444px;fill:#999999;stroke-width:0.264583">%1 = alloc(%0)</tspan><tspan
|
||||
style="font-size:5.64444px;fill:#999999;stroke-width:0.264583">%1 = memref.alloc(%0)</tspan><tspan
|
||||
sodipodi:role="line"
|
||||
x="137.07773"
|
||||
y="85.729691"
|
||||
|
|
@ -728,7 +728,7 @@
|
|||
id="tspan9336-0"
|
||||
x="-45.424786"
|
||||
y="77.928955"
|
||||
style="font-size:5.64444px;fill:#008000;stroke-width:0.264583">%5 = alloc(%d0)</tspan><tspan
|
||||
style="font-size:5.64444px;fill:#008000;stroke-width:0.264583">%5 = memref.alloc(%d0)</tspan><tspan
|
||||
sodipodi:role="line"
|
||||
x="-45.424786"
|
||||
y="84.984505"
|
||||
|
|
@ -744,7 +744,7 @@
|
|||
id="tspan9336-2"
|
||||
x="135.37999"
|
||||
y="198.54033"
|
||||
style="font-size:5.64444px;fill:#008000;stroke-width:0.264583">%6 = alloc(%d1)</tspan><tspan
|
||||
style="font-size:5.64444px;fill:#008000;stroke-width:0.264583">%6 = memref.alloc(%d1)</tspan><tspan
|
||||
sodipodi:role="line"
|
||||
x="135.37999"
|
||||
y="205.59589"
|
||||
|
|
|
|||
|
Before Width: | Height: | Size: 28 KiB After Width: | Height: | Size: 28 KiB |
{kind=link}
|
|
@ -676,7 +676,7 @@
|
|||
id="tspan9336"
|
||||
x="137.07773"
|
||||
y="78.674141"
|
||||
style="font-size:5.64444px;fill:#d40000;stroke-width:0.264583">%1 = alloc(%0)</tspan><tspan
|
||||
style="font-size:5.64444px;fill:#d40000;stroke-width:0.264583">%1 = memref.alloc(%0)</tspan><tspan
|
||||
sodipodi:role="line"
|
||||
x="137.07773"
|
||||
y="85.729691"
|
||||
|
|
|
|||
|
Before Width: | Height: | Size: 26 KiB After Width: | Height: | Size: 26 KiB |
|
|
@ -3,6 +3,7 @@ get_property(conversion_libs GLOBAL PROPERTY MLIR_CONVERSION_LIBS)
|
|||
set(LIBS
|
||||
${dialect_libs}
|
||||
${conversion_libs}
|
||||
MLIRArithmetic
|
||||
MLIROptLib
|
||||
MLIRStandalone
|
||||
)
|
||||
|
|
|
|||
|
|
@ -6,6 +6,7 @@
|
|||
//
|
||||
//===----------------------------------------------------------------------===//
|
||||
|
||||
#include "mlir/Dialect/Arithmetic/IR/Arithmetic.h"
|
||||
#include "mlir/IR/Dialect.h"
|
||||
#include "mlir/IR/MLIRContext.h"
|
||||
#include "mlir/InitAllDialects.h"
|
||||
|
|
@ -26,8 +27,8 @@ int main(int argc, char **argv) {
|
|||
// TODO: Register standalone passes here.
|
||||
|
||||
mlir::DialectRegistry registry;
|
||||
registry.insert<mlir::standalone::StandaloneDialect>();
|
||||
registry.insert<mlir::StandardOpsDialect>();
|
||||
registry.insert<mlir::standalone::StandaloneDialect,
|
||||
mlir::arith::ArithmeticDialect, mlir::StandardOpsDialect>();
|
||||
// Add the following to include *all* MLIR Core dialects, or selectively
|
||||
// include what you need like above. You only need to register dialects that
|
||||
// will be *parsed* by the tool, not the one generated
|
||||
|
|
|
|||
|
|
@ -3,7 +3,7 @@
|
|||
module {
|
||||
// CHECK-LABEL: func @bar()
|
||||
func @bar() {
|
||||
%0 = constant 1 : i32
|
||||
%0 = arith.constant 1 : i32
|
||||
// CHECK: %{{.*}} = standalone.foo %{{.*}} : i32
|
||||
%res = standalone.foo %0 : i32
|
||||
return
|
||||
|
|
|
|||
|
|
@ -16,6 +16,7 @@
|
|||
#include "toy/Passes.h"
|
||||
|
||||
#include "mlir/Dialect/Affine/IR/AffineOps.h"
|
||||
#include "mlir/Dialect/Arithmetic/IR/Arithmetic.h"
|
||||
#include "mlir/Dialect/MemRef/IR/MemRef.h"
|
||||
#include "mlir/Dialect/StandardOps/IR/Ops.h"
|
||||
#include "mlir/Pass/Pass.h"
|
||||
|
|
@ -124,8 +125,8 @@ struct BinaryOpLowering : public ConversionPattern {
|
|||
return success();
|
||||
}
|
||||
};
|
||||
using AddOpLowering = BinaryOpLowering<toy::AddOp, AddFOp>;
|
||||
using MulOpLowering = BinaryOpLowering<toy::MulOp, MulFOp>;
|
||||
using AddOpLowering = BinaryOpLowering<toy::AddOp, arith::AddFOp>;
|
||||
using MulOpLowering = BinaryOpLowering<toy::MulOp, arith::MulFOp>;
|
||||
|
||||
//===----------------------------------------------------------------------===//
|
||||
// ToyToAffine RewritePatterns: Constant operations
|
||||
|
|
@ -154,10 +155,12 @@ struct ConstantOpLowering : public OpRewritePattern<toy::ConstantOp> {
|
|||
if (!valueShape.empty()) {
|
||||
for (auto i : llvm::seq<int64_t>(
|
||||
0, *std::max_element(valueShape.begin(), valueShape.end())))
|
||||
constantIndices.push_back(rewriter.create<ConstantIndexOp>(loc, i));
|
||||
constantIndices.push_back(
|
||||
rewriter.create<arith::ConstantIndexOp>(loc, i));
|
||||
} else {
|
||||
// This is the case of a tensor of rank 0.
|
||||
constantIndices.push_back(rewriter.create<ConstantIndexOp>(loc, 0));
|
||||
constantIndices.push_back(
|
||||
rewriter.create<arith::ConstantIndexOp>(loc, 0));
|
||||
}
|
||||
|
||||
// The constant operation represents a multi-dimensional constant, so we
|
||||
|
|
@ -171,7 +174,7 @@ struct ConstantOpLowering : public OpRewritePattern<toy::ConstantOp> {
|
|||
// we store the element at the given index.
|
||||
if (dimension == valueShape.size()) {
|
||||
rewriter.create<AffineStoreOp>(
|
||||
loc, rewriter.create<ConstantOp>(loc, *valueIt++), alloc,
|
||||
loc, rewriter.create<arith::ConstantOp>(loc, *valueIt++), alloc,
|
||||
llvm::makeArrayRef(indices));
|
||||
return;
|
||||
}
|
||||
|
|
@ -284,9 +287,9 @@ void ToyToAffineLoweringPass::runOnFunction() {
|
|||
|
||||
// We define the specific operations, or dialects, that are legal targets for
|
||||
// this lowering. In our case, we are lowering to a combination of the
|
||||
// `Affine`, `MemRef` and `Standard` dialects.
|
||||
target.addLegalDialect<AffineDialect, memref::MemRefDialect,
|
||||
StandardOpsDialect>();
|
||||
// `Affine`, `Arithmetic`, `MemRef`, and `Standard` dialects.
|
||||
target.addLegalDialect<AffineDialect, arith::ArithmeticDialect,
|
||||
memref::MemRefDialect, StandardOpsDialect>();
|
||||
|
||||
// We also define the Toy dialect as Illegal so that the conversion will fail
|
||||
// if any of these operations are *not* converted. Given that we actually want
|
||||
|
|
|
|||
|
|
@ -16,6 +16,7 @@
|
|||
#include "toy/Passes.h"
|
||||
|
||||
#include "mlir/Dialect/Affine/IR/AffineOps.h"
|
||||
#include "mlir/Dialect/Arithmetic/IR/Arithmetic.h"
|
||||
#include "mlir/Dialect/MemRef/IR/MemRef.h"
|
||||
#include "mlir/Dialect/StandardOps/IR/Ops.h"
|
||||
#include "mlir/Pass/Pass.h"
|
||||
|
|
@ -124,8 +125,8 @@ struct BinaryOpLowering : public ConversionPattern {
|
|||
return success();
|
||||
}
|
||||
};
|
||||
using AddOpLowering = BinaryOpLowering<toy::AddOp, AddFOp>;
|
||||
using MulOpLowering = BinaryOpLowering<toy::MulOp, MulFOp>;
|
||||
using AddOpLowering = BinaryOpLowering<toy::AddOp, arith::AddFOp>;
|
||||
using MulOpLowering = BinaryOpLowering<toy::MulOp, arith::MulFOp>;
|
||||
|
||||
//===----------------------------------------------------------------------===//
|
||||
// ToyToAffine RewritePatterns: Constant operations
|
||||
|
|
@ -154,10 +155,12 @@ struct ConstantOpLowering : public OpRewritePattern<toy::ConstantOp> {
|
|||
if (!valueShape.empty()) {
|
||||
for (auto i : llvm::seq<int64_t>(
|
||||
0, *std::max_element(valueShape.begin(), valueShape.end())))
|
||||
constantIndices.push_back(rewriter.create<ConstantIndexOp>(loc, i));
|
||||
constantIndices.push_back(
|
||||
rewriter.create<arith::ConstantIndexOp>(loc, i));
|
||||
} else {
|
||||
// This is the case of a tensor of rank 0.
|
||||
constantIndices.push_back(rewriter.create<ConstantIndexOp>(loc, 0));
|
||||
constantIndices.push_back(
|
||||
rewriter.create<arith::ConstantIndexOp>(loc, 0));
|
||||
}
|
||||
// The constant operation represents a multi-dimensional constant, so we
|
||||
// will need to generate a store for each of the elements. The following
|
||||
|
|
@ -170,7 +173,7 @@ struct ConstantOpLowering : public OpRewritePattern<toy::ConstantOp> {
|
|||
// we store the element at the given index.
|
||||
if (dimension == valueShape.size()) {
|
||||
rewriter.create<AffineStoreOp>(
|
||||
loc, rewriter.create<ConstantOp>(loc, *valueIt++), alloc,
|
||||
loc, rewriter.create<arith::ConstantOp>(loc, *valueIt++), alloc,
|
||||
llvm::makeArrayRef(indices));
|
||||
return;
|
||||
}
|
||||
|
|
@ -283,9 +286,9 @@ void ToyToAffineLoweringPass::runOnFunction() {
|
|||
|
||||
// We define the specific operations, or dialects, that are legal targets for
|
||||
// this lowering. In our case, we are lowering to a combination of the
|
||||
// `Affine`, `MemRef` and `Standard` dialects.
|
||||
target.addLegalDialect<AffineDialect, memref::MemRefDialect,
|
||||
StandardOpsDialect>();
|
||||
// `Affine`, `Arithmetic`, `MemRef`, and `Standard` dialects.
|
||||
target.addLegalDialect<AffineDialect, arith::ArithmeticDialect,
|
||||
memref::MemRefDialect, StandardOpsDialect>();
|
||||
|
||||
// We also define the Toy dialect as Illegal so that the conversion will fail
|
||||
// if any of these operations are *not* converted. Given that we actually want
|
||||
|
|
|
|||
|
|
@ -25,6 +25,7 @@
|
|||
#include "toy/Passes.h"
|
||||
|
||||
#include "mlir/Conversion/AffineToStandard/AffineToStandard.h"
|
||||
#include "mlir/Conversion/ArithmeticToLLVM/ArithmeticToLLVM.h"
|
||||
#include "mlir/Conversion/LLVMCommon/ConversionTarget.h"
|
||||
#include "mlir/Conversion/LLVMCommon/TypeConverter.h"
|
||||
#include "mlir/Conversion/MemRefToLLVM/MemRefToLLVM.h"
|
||||
|
|
@ -32,6 +33,7 @@
|
|||
#include "mlir/Conversion/StandardToLLVM/ConvertStandardToLLVM.h"
|
||||
#include "mlir/Conversion/StandardToLLVM/ConvertStandardToLLVMPass.h"
|
||||
#include "mlir/Dialect/Affine/IR/AffineOps.h"
|
||||
#include "mlir/Dialect/Arithmetic/IR/Arithmetic.h"
|
||||
#include "mlir/Dialect/LLVMIR/LLVMDialect.h"
|
||||
#include "mlir/Dialect/MemRef/IR/MemRef.h"
|
||||
#include "mlir/Dialect/SCF/SCF.h"
|
||||
|
|
@ -73,9 +75,10 @@ public:
|
|||
// Create a loop for each of the dimensions within the shape.
|
||||
SmallVector<Value, 4> loopIvs;
|
||||
for (unsigned i = 0, e = memRefShape.size(); i != e; ++i) {
|
||||
auto lowerBound = rewriter.create<ConstantIndexOp>(loc, 0);
|
||||
auto upperBound = rewriter.create<ConstantIndexOp>(loc, memRefShape[i]);
|
||||
auto step = rewriter.create<ConstantIndexOp>(loc, 1);
|
||||
auto lowerBound = rewriter.create<arith::ConstantIndexOp>(loc, 0);
|
||||
auto upperBound =
|
||||
rewriter.create<arith::ConstantIndexOp>(loc, memRefShape[i]);
|
||||
auto step = rewriter.create<arith::ConstantIndexOp>(loc, 1);
|
||||
auto loop =
|
||||
rewriter.create<scf::ForOp>(loc, lowerBound, upperBound, step);
|
||||
for (Operation &nested : *loop.getBody())
|
||||
|
|
@ -198,6 +201,8 @@ void ToyToLLVMLoweringPass::runOnOperation() {
|
|||
RewritePatternSet patterns(&getContext());
|
||||
populateAffineToStdConversionPatterns(patterns);
|
||||
populateLoopToStdConversionPatterns(patterns);
|
||||
mlir::arith::populateArithmeticToLLVMConversionPatterns(typeConverter,
|
||||
patterns);
|
||||
populateMemRefToLLVMConversionPatterns(typeConverter, patterns);
|
||||
populateStdToLLVMConversionPatterns(typeConverter, patterns);
|
||||
|
||||
|
|
|
|||
|
|
@ -16,6 +16,7 @@
|
|||
#include "toy/Passes.h"
|
||||
|
||||
#include "mlir/Dialect/Affine/IR/AffineOps.h"
|
||||
#include "mlir/Dialect/Arithmetic/IR/Arithmetic.h"
|
||||
#include "mlir/Dialect/MemRef/IR/MemRef.h"
|
||||
#include "mlir/Dialect/StandardOps/IR/Ops.h"
|
||||
#include "mlir/Pass/Pass.h"
|
||||
|
|
@ -124,8 +125,8 @@ struct BinaryOpLowering : public ConversionPattern {
|
|||
return success();
|
||||
}
|
||||
};
|
||||
using AddOpLowering = BinaryOpLowering<toy::AddOp, AddFOp>;
|
||||
using MulOpLowering = BinaryOpLowering<toy::MulOp, MulFOp>;
|
||||
using AddOpLowering = BinaryOpLowering<toy::AddOp, arith::AddFOp>;
|
||||
using MulOpLowering = BinaryOpLowering<toy::MulOp, arith::MulFOp>;
|
||||
|
||||
//===----------------------------------------------------------------------===//
|
||||
// ToyToAffine RewritePatterns: Constant operations
|
||||
|
|
@ -154,10 +155,12 @@ struct ConstantOpLowering : public OpRewritePattern<toy::ConstantOp> {
|
|||
if (!valueShape.empty()) {
|
||||
for (auto i : llvm::seq<int64_t>(
|
||||
0, *std::max_element(valueShape.begin(), valueShape.end())))
|
||||
constantIndices.push_back(rewriter.create<ConstantIndexOp>(loc, i));
|
||||
constantIndices.push_back(
|
||||
rewriter.create<arith::ConstantIndexOp>(loc, i));
|
||||
} else {
|
||||
// This is the case of a tensor of rank 0.
|
||||
constantIndices.push_back(rewriter.create<ConstantIndexOp>(loc, 0));
|
||||
constantIndices.push_back(
|
||||
rewriter.create<arith::ConstantIndexOp>(loc, 0));
|
||||
}
|
||||
|
||||
// The constant operation represents a multi-dimensional constant, so we
|
||||
|
|
@ -171,7 +174,7 @@ struct ConstantOpLowering : public OpRewritePattern<toy::ConstantOp> {
|
|||
// we store the element at the given index.
|
||||
if (dimension == valueShape.size()) {
|
||||
rewriter.create<AffineStoreOp>(
|
||||
loc, rewriter.create<ConstantOp>(loc, *valueIt++), alloc,
|
||||
loc, rewriter.create<arith::ConstantOp>(loc, *valueIt++), alloc,
|
||||
llvm::makeArrayRef(indices));
|
||||
return;
|
||||
}
|
||||
|
|
@ -284,9 +287,9 @@ void ToyToAffineLoweringPass::runOnFunction() {
|
|||
|
||||
// We define the specific operations, or dialects, that are legal targets for
|
||||
// this lowering. In our case, we are lowering to a combination of the
|
||||
// `Affine`, `MemRef` and `Standard` dialects.
|
||||
target.addLegalDialect<AffineDialect, memref::MemRefDialect,
|
||||
StandardOpsDialect>();
|
||||
// `Affine`, `Arithmetic`, `MemRef`, and `Standard` dialects.
|
||||
target.addLegalDialect<AffineDialect, arith::ArithmeticDialect,
|
||||
memref::MemRefDialect, StandardOpsDialect>();
|
||||
|
||||
// We also define the Toy dialect as Illegal so that the conversion will fail
|
||||
// if any of these operations are *not* converted. Given that we actually want
|
||||
|
|
|
|||
|
|
@ -25,6 +25,7 @@
|
|||
#include "toy/Passes.h"
|
||||
|
||||
#include "mlir/Conversion/AffineToStandard/AffineToStandard.h"
|
||||
#include "mlir/Conversion/ArithmeticToLLVM/ArithmeticToLLVM.h"
|
||||
#include "mlir/Conversion/LLVMCommon/ConversionTarget.h"
|
||||
#include "mlir/Conversion/LLVMCommon/TypeConverter.h"
|
||||
#include "mlir/Conversion/MemRefToLLVM/MemRefToLLVM.h"
|
||||
|
|
@ -32,6 +33,7 @@
|
|||
#include "mlir/Conversion/StandardToLLVM/ConvertStandardToLLVM.h"
|
||||
#include "mlir/Conversion/StandardToLLVM/ConvertStandardToLLVMPass.h"
|
||||
#include "mlir/Dialect/Affine/IR/AffineOps.h"
|
||||
#include "mlir/Dialect/Arithmetic/IR/Arithmetic.h"
|
||||
#include "mlir/Dialect/LLVMIR/LLVMDialect.h"
|
||||
#include "mlir/Dialect/MemRef/IR/MemRef.h"
|
||||
#include "mlir/Dialect/SCF/SCF.h"
|
||||
|
|
@ -73,9 +75,10 @@ public:
|
|||
// Create a loop for each of the dimensions within the shape.
|
||||
SmallVector<Value, 4> loopIvs;
|
||||
for (unsigned i = 0, e = memRefShape.size(); i != e; ++i) {
|
||||
auto lowerBound = rewriter.create<ConstantIndexOp>(loc, 0);
|
||||
auto upperBound = rewriter.create<ConstantIndexOp>(loc, memRefShape[i]);
|
||||
auto step = rewriter.create<ConstantIndexOp>(loc, 1);
|
||||
auto lowerBound = rewriter.create<arith::ConstantIndexOp>(loc, 0);
|
||||
auto upperBound =
|
||||
rewriter.create<arith::ConstantIndexOp>(loc, memRefShape[i]);
|
||||
auto step = rewriter.create<arith::ConstantIndexOp>(loc, 1);
|
||||
auto loop =
|
||||
rewriter.create<scf::ForOp>(loc, lowerBound, upperBound, step);
|
||||
for (Operation &nested : *loop.getBody())
|
||||
|
|
@ -198,6 +201,8 @@ void ToyToLLVMLoweringPass::runOnOperation() {
|
|||
RewritePatternSet patterns(&getContext());
|
||||
populateAffineToStdConversionPatterns(patterns);
|
||||
populateLoopToStdConversionPatterns(patterns);
|
||||
mlir::arith::populateArithmeticToLLVMConversionPatterns(typeConverter,
|
||||
patterns);
|
||||
populateMemRefToLLVMConversionPatterns(typeConverter, patterns);
|
||||
populateStdToLLVMConversionPatterns(typeConverter, patterns);
|
||||
|
||||
|
|
|
|||
|
|
@ -0,0 +1,28 @@
|
|||
//===- ArithmeticToLLVM.h - Arith to LLVM dialect conversion ----*- C++ -*-===//
|
||||
//
|
||||
// Part of the LLVM Project, under the Apache License v2.0 with LLVM Exceptions.
|
||||
// See https://llvm.org/LICENSE.txt for license information.
|
||||
// SPDX-License-Identifier: Apache-2.0 WITH LLVM-exception
|
||||
//
|
||||
//===----------------------------------------------------------------------===//
|
||||
|
||||
#ifndef MLIR_CONVERSION_ARITHMETICTOLLVM_ARITHMETICTOLLVM_H
|
||||
#define MLIR_CONVERSION_ARITHMETICTOLLVM_ARITHMETICTOLLVM_H
|
||||
|
||||
#include <memory>
|
||||
|
||||
namespace mlir {
|
||||
|
||||
class LLVMTypeConverter;
|
||||
class RewritePatternSet;
|
||||
class Pass;
|
||||
|
||||
namespace arith {
|
||||
void populateArithmeticToLLVMConversionPatterns(LLVMTypeConverter &converter,
|
||||
RewritePatternSet &patterns);
|
||||
|
||||
std::unique_ptr<Pass> createConvertArithmeticToLLVMPass();
|
||||
} // end namespace arith
|
||||
} // end namespace mlir
|
||||
|
||||
#endif // MLIR_CONVERSION_ARITHMETICTOLLVM_ARITHMETICTOLLVM_H
|
||||
|
|
@ -0,0 +1,28 @@
|
|||
//===- ArithmeticToSPIRV.h - Convert Arith to SPIRV dialect -----*- C++ -*-===//
|
||||
//
|
||||
// Part of the LLVM Project, under the Apache License v2.0 with LLVM Exceptions.
|
||||
// See https://llvm.org/LICENSE.txt for license information.
|
||||
// SPDX-License-Identifier: Apache-2.0 WITH LLVM-exception
|
||||
//
|
||||
//===----------------------------------------------------------------------===//
|
||||
|
||||
#ifndef MLIR_CONVERSION_ARITHMETICTOSPIRV_ARITHMETICTOSPIRV_H
|
||||
#define MLIR_CONVERSION_ARITHMETICTOSPIRV_ARITHMETICTOSPIRV_H
|
||||
|
||||
#include <memory>
|
||||
|
||||
namespace mlir {
|
||||
|
||||
class SPIRVTypeConverter;
|
||||
class RewritePatternSet;
|
||||
class Pass;
|
||||
|
||||
namespace arith {
|
||||
void populateArithmeticToSPIRVPatterns(SPIRVTypeConverter &typeConverter,
|
||||
RewritePatternSet &patterns);
|
||||
|
||||
std::unique_ptr<Pass> createConvertArithmeticToSPIRVPass();
|
||||
} // end namespace arith
|
||||
} // end namespace mlir
|
||||
|
||||
#endif // MLIR_CONVERSION_ARITHMETICTOSPIRV_ARITHMETICTOSPIRV_H
|
||||
|
|
@ -10,6 +10,8 @@
|
|||
#define MLIR_CONVERSION_PASSES_H
|
||||
|
||||
#include "mlir/Conversion/AffineToStandard/AffineToStandard.h"
|
||||
#include "mlir/Conversion/ArithmeticToLLVM/ArithmeticToLLVM.h"
|
||||
#include "mlir/Conversion/ArithmeticToSPIRV/ArithmeticToSPIRV.h"
|
||||
#include "mlir/Conversion/ArmNeon2dToIntr/ArmNeon2dToIntr.h"
|
||||
#include "mlir/Conversion/AsyncToLLVM/AsyncToLLVM.h"
|
||||
#include "mlir/Conversion/ComplexToLLVM/ComplexToLLVM.h"
|
||||
|
|
|
|||
|
|
@ -39,10 +39,10 @@ def ConvertAffineToStandard : Pass<"lower-affine"> {
|
|||
%d0 = <...>
|
||||
%d1 = <...>
|
||||
%s0 = <...>
|
||||
%0 = constant 2 : index
|
||||
%1 = muli %0, %d1
|
||||
%2 = addi %d0, %1
|
||||
%r = addi %2, %s0
|
||||
%0 = arith.constant 2 : index
|
||||
%1 = arith.muli %0, %d1
|
||||
%2 = arith.addi %d0, %1
|
||||
%r = arith.addi %2, %s0
|
||||
```
|
||||
|
||||
#### Input invariant
|
||||
|
|
@ -74,6 +74,40 @@ def ConvertAffineToStandard : Pass<"lower-affine"> {
|
|||
];
|
||||
}
|
||||
|
||||
//===----------------------------------------------------------------------===//
|
||||
// ArithmeticToLLVM
|
||||
//===----------------------------------------------------------------------===//
|
||||
|
||||
def ConvertArithmeticToLLVM : FunctionPass<"convert-arith-to-llvm"> {
|
||||
let summary = "Convert Arithmetic dialect to LLVM dialect";
|
||||
let description = [{
|
||||
This pass converts supported Arithmetic ops to LLVM dialect instructions.
|
||||
}];
|
||||
let constructor = "mlir::arith::createConvertArithmeticToLLVMPass()";
|
||||
let dependentDialects = ["LLVM::LLVMDialect"];
|
||||
let options = [
|
||||
Option<"indexBitwidth", "index-bitwidth", "unsigned",
|
||||
/*default=kDeriveIndexBitwidthFromDataLayout*/"0",
|
||||
"Bitwidth of the index type, 0 to use size of machine word">,
|
||||
];
|
||||
}
|
||||
|
||||
//===----------------------------------------------------------------------===//
|
||||
// ArithmeticToSPIRV
|
||||
//===----------------------------------------------------------------------===//
|
||||
|
||||
def ConvertArithmeticToSPIRV : FunctionPass<"convert-arith-to-spirv"> {
|
||||
let summary = "Convert Arithmetic dialect to SPIR-V dialect";
|
||||
let constructor = "mlir::arith::createConvertArithmeticToSPIRVPass()";
|
||||
let dependentDialects = ["spirv::SPIRVDialect"];
|
||||
let options = [
|
||||
Option<"emulateNon32BitScalarTypes", "emulate-non-32-bit-scalar-types",
|
||||
"bool", /*default=*/"true",
|
||||
"Emulate non-32-bit scalar types with 32-bit ones if "
|
||||
"missing native support">
|
||||
];
|
||||
}
|
||||
|
||||
//===----------------------------------------------------------------------===//
|
||||
// AsyncToLLVM
|
||||
//===----------------------------------------------------------------------===//
|
||||
|
|
@ -86,7 +120,10 @@ def ConvertAsyncToLLVM : Pass<"convert-async-to-llvm", "ModuleOp"> {
|
|||
API to execute them.
|
||||
}];
|
||||
let constructor = "mlir::createConvertAsyncToLLVMPass()";
|
||||
let dependentDialects = ["LLVM::LLVMDialect"];
|
||||
let dependentDialects = [
|
||||
"arith::ArithmeticDialect",
|
||||
"LLVM::LLVMDialect",
|
||||
];
|
||||
}
|
||||
|
||||
//===----------------------------------------------------------------------===//
|
||||
|
|
@ -106,11 +143,7 @@ def ConvertComplexToLLVM : Pass<"convert-complex-to-llvm", "ModuleOp"> {
|
|||
def ConvertComplexToStandard : FunctionPass<"convert-complex-to-standard"> {
|
||||
let summary = "Convert Complex dialect to standard dialect";
|
||||
let constructor = "mlir::createConvertComplexToStandardPass()";
|
||||
let dependentDialects = [
|
||||
"complex::ComplexDialect",
|
||||
"math::MathDialect",
|
||||
"StandardOpsDialect"
|
||||
];
|
||||
let dependentDialects = ["math::MathDialect"];
|
||||
}
|
||||
|
||||
//===----------------------------------------------------------------------===//
|
||||
|
|
@ -136,7 +169,11 @@ def LowerHostCodeToLLVM : Pass<"lower-host-to-llvm", "ModuleOp"> {
|
|||
def ConvertGpuOpsToNVVMOps : Pass<"convert-gpu-to-nvvm", "gpu::GPUModuleOp"> {
|
||||
let summary = "Generate NVVM operations for gpu operations";
|
||||
let constructor = "mlir::createLowerGpuOpsToNVVMOpsPass()";
|
||||
let dependentDialects = ["NVVM::NVVMDialect", "memref::MemRefDialect"];
|
||||
let dependentDialects = [
|
||||
"memref::MemRefDialect",
|
||||
"NVVM::NVVMDialect",
|
||||
"StandardOpsDialect",
|
||||
];
|
||||
let options = [
|
||||
Option<"indexBitwidth", "index-bitwidth", "unsigned",
|
||||
/*default=kDeriveIndexBitwidthFromDataLayout*/"0",
|
||||
|
|
@ -252,7 +289,11 @@ def ConvertMathToLibm : Pass<"convert-math-to-libm", "ModuleOp"> {
|
|||
This pass converts supported Math ops to libm calls.
|
||||
}];
|
||||
let constructor = "mlir::createConvertMathToLibmPass()";
|
||||
let dependentDialects = ["StandardOpsDialect", "vector::VectorDialect"];
|
||||
let dependentDialects = [
|
||||
"arith::ArithmeticDialect",
|
||||
"StandardOpsDialect",
|
||||
"vector::VectorDialect",
|
||||
];
|
||||
}
|
||||
|
||||
//===----------------------------------------------------------------------===//
|
||||
|
|
@ -448,7 +489,6 @@ def ConvertShapeToStandard : Pass<"convert-shape-to-std", "ModuleOp"> {
|
|||
let dependentDialects = [
|
||||
"StandardOpsDialect",
|
||||
"scf::SCFDialect",
|
||||
"tensor::TensorDialect"
|
||||
];
|
||||
}
|
||||
|
||||
|
|
@ -583,7 +623,11 @@ def TosaToSCF : Pass<"tosa-to-scf"> {
|
|||
|
||||
def TosaToStandard : Pass<"tosa-to-standard"> {
|
||||
let summary = "Lower TOSA to the Standard dialect";
|
||||
let dependentDialects = ["StandardOpsDialect", "tensor::TensorDialect"];
|
||||
let dependentDialects = [
|
||||
"arith::ArithmeticDialect",
|
||||
"StandardOpsDialect",
|
||||
"tensor::TensorDialect",
|
||||
];
|
||||
let description = [{
|
||||
Pass that converts TOSA operations to the equivalent operations using the
|
||||
operations in the Standard dialect.
|
||||
|
|
|
|||
|
|
@ -37,7 +37,7 @@ class RewritePatternSet;
|
|||
/// affine.for %I = 0 to 9 {
|
||||
/// %dim = dim %A, 0 : memref<?x?x?xf32>
|
||||
/// %add = affine.apply %I + %a
|
||||
/// %cmp = cmpi "slt", %add, %dim : index
|
||||
/// %cmp = arith.cmpi "slt", %add, %dim : index
|
||||
/// scf.if %cmp {
|
||||
/// %vec_2d = load %1[%I] : memref<9xvector<17x15xf32>>
|
||||
/// vector.transfer_write %vec_2d, %A[%add, %b, %c] :
|
||||
|
|
|
|||
|
|
@ -23,6 +23,7 @@ def Affine_Dialect : Dialect {
|
|||
let name = "affine";
|
||||
let cppNamespace = "mlir";
|
||||
let hasConstantMaterializer = 1;
|
||||
let dependentDialects = ["arith::ArithmeticDialect"];
|
||||
}
|
||||
|
||||
// Base class for Affine dialect ops.
|
||||
|
|
@ -201,7 +202,7 @@ def AffineForOp : Affine_Op<"for",
|
|||
%sum = affine.for %i = 0 to 10 step 2
|
||||
iter_args(%sum_iter = %sum_0) -> (f32) {
|
||||
%t = affine.load %buffer[%i] : memref<1024xf32>
|
||||
%sum_next = addf %sum_iter, %t : f32
|
||||
%sum_next = arith.addf %sum_iter, %t : f32
|
||||
// Yield current iteration sum to next iteration %sum_iter or to %sum
|
||||
// if final iteration.
|
||||
affine.yield %sum_next : f32
|
||||
|
|
@ -213,8 +214,8 @@ def AffineForOp : Affine_Op<"for",
|
|||
```mlir
|
||||
%res:2 = affine.for %i = 0 to 128 iter_args(%arg0 = %init0, %arg1 = %init1)
|
||||
-> (index, index) {
|
||||
%y0 = addi %arg0, %c1 : index
|
||||
%y1 = addi %arg1, %c2 : index
|
||||
%y0 = arith.addi %arg0, %c1 : index
|
||||
%y1 = arith.addi %arg1, %c2 : index
|
||||
affine.yield %y0, %y1 : index, index
|
||||
}
|
||||
```
|
||||
|
|
@ -656,7 +657,7 @@ def AffineParallelOp : Affine_Op<"parallel",
|
|||
%0 = affine.parallel (%kx, %ky) = (0, 0) to (2, 2) reduce ("addf") {
|
||||
%1 = affine.load %D[%x + %kx, %y + %ky] : memref<100x100xf32>
|
||||
%2 = affine.load %K[%kx, %ky] : memref<3x3xf32>
|
||||
%3 = mulf %1, %2 : f32
|
||||
%3 = arith.mulf %1, %2 : f32
|
||||
affine.yield %3 : f32
|
||||
}
|
||||
affine.store %0, O[%x, %y] : memref<98x98xf32>
|
||||
|
|
|
|||
|
|
@ -112,7 +112,7 @@ def AffineScalarReplacement : FunctionPass<"affine-scalrep"> {
|
|||
affine.for %i1 = 0 to 10 {
|
||||
affine.store %cf7, %m[%i0, %i1] : memref<10x10xf32>
|
||||
%v0 = affine.load %m[%i0, %i1] : memref<10x10xf32>
|
||||
%v1 = addf %v0, %v0 : f32
|
||||
%v1 = arith.addf %v0, %v0 : f32
|
||||
}
|
||||
}
|
||||
return %m : memref<10x10xf32>
|
||||
|
|
@ -129,7 +129,7 @@ def AffineScalarReplacement : FunctionPass<"affine-scalrep"> {
|
|||
affine.for %arg0 = 0 to 10 {
|
||||
affine.for %arg1 = 0 to 10 {
|
||||
affine.store %cst, %0[%arg0, %arg1] : memref<10x10xf32>
|
||||
%1 = addf %cst, %cst : f32
|
||||
%1 = arith.addf %cst, %cst : f32
|
||||
}
|
||||
}
|
||||
return %0 : memref<10x10xf32>
|
||||
|
|
|
|||
|
|
@ -1 +1,2 @@
|
|||
add_subdirectory(IR)
|
||||
add_subdirectory(Transforms)
|
||||
|
|
|
|||
|
|
@ -10,6 +10,7 @@
|
|||
|
||||
#include "mlir/IR/Dialect.h"
|
||||
#include "mlir/IR/OpDefinition.h"
|
||||
#include "mlir/IR/OpImplementation.h"
|
||||
#include "mlir/Interfaces/CastInterfaces.h"
|
||||
#include "mlir/Interfaces/SideEffectInterfaces.h"
|
||||
#include "mlir/Interfaces/VectorInterfaces.h"
|
||||
|
|
@ -33,6 +34,64 @@
|
|||
#define GET_OP_CLASSES
|
||||
#include "mlir/Dialect/Arithmetic/IR/ArithmeticOps.h.inc"
|
||||
|
||||
namespace mlir {
|
||||
namespace arith {
|
||||
|
||||
/// Specialization of `arith.constant` op that returns an integer value.
|
||||
class ConstantIntOp : public arith::ConstantOp {
|
||||
public:
|
||||
using arith::ConstantOp::ConstantOp;
|
||||
|
||||
/// Build a constant int op that produces an integer of the specified width.
|
||||
static void build(OpBuilder &builder, OperationState &result, int64_t value,
|
||||
unsigned width);
|
||||
|
||||
/// Build a constant int op that produces an integer of the specified type,
|
||||
/// which must be an integer type.
|
||||
static void build(OpBuilder &builder, OperationState &result, int64_t value,
|
||||
Type type);
|
||||
|
||||
inline int64_t value() {
|
||||
return arith::ConstantOp::value().cast<IntegerAttr>().getInt();
|
||||
}
|
||||
|
||||
static bool classof(Operation *op);
|
||||
};
|
||||
|
||||
/// Specialization of `arith.constant` op that returns a floating point value.
|
||||
class ConstantFloatOp : public arith::ConstantOp {
|
||||
public:
|
||||
using arith::ConstantOp::ConstantOp;
|
||||
|
||||
/// Build a constant float op that produces a float of the specified type.
|
||||
static void build(OpBuilder &builder, OperationState &result,
|
||||
const APFloat &value, FloatType type);
|
||||
|
||||
inline APFloat value() {
|
||||
return arith::ConstantOp::value().cast<FloatAttr>().getValue();
|
||||
}
|
||||
|
||||
static bool classof(Operation *op);
|
||||
};
|
||||
|
||||
/// Specialization of `arith.constant` op that returns an integer of index type.
|
||||
class ConstantIndexOp : public arith::ConstantOp {
|
||||
public:
|
||||
using arith::ConstantOp::ConstantOp;
|
||||
|
||||
/// Build a constant int op that produces an index.
|
||||
static void build(OpBuilder &builder, OperationState &result, int64_t value);
|
||||
|
||||
inline int64_t value() {
|
||||
return arith::ConstantOp::value().cast<IntegerAttr>().getInt();
|
||||
}
|
||||
|
||||
static bool classof(Operation *op);
|
||||
};
|
||||
|
||||
} // end namespace arith
|
||||
} // end namespace mlir
|
||||
|
||||
//===----------------------------------------------------------------------===//
|
||||
// Utility Functions
|
||||
//===----------------------------------------------------------------------===//
|
||||
|
|
|
|||
|
|
@ -20,6 +20,8 @@ def Arithmetic_Dialect : Dialect {
|
|||
ops, bitwise and shift ops, cast ops, and compare ops. Operations in this
|
||||
dialect also accept vectors and tensors of integers or floats.
|
||||
}];
|
||||
|
||||
let hasConstantMaterializer = 1;
|
||||
}
|
||||
|
||||
// The predicate indicates the type of the comparison to perform:
|
||||
|
|
|
|||
|
|
@ -13,6 +13,7 @@ include "mlir/Dialect/Arithmetic/IR/ArithmeticBase.td"
|
|||
include "mlir/Interfaces/CastInterfaces.td"
|
||||
include "mlir/Interfaces/SideEffectInterfaces.td"
|
||||
include "mlir/Interfaces/VectorInterfaces.td"
|
||||
include "mlir/IR/OpAsmInterface.td"
|
||||
|
||||
// Base class for Arithmetic dialect ops. Ops in this dialect have no side
|
||||
// effects and can be applied element-wise to vectors and tensors.
|
||||
|
|
@ -119,12 +120,14 @@ class Arith_CompareOp<string mnemonic, list<OpTrait> traits = []> :
|
|||
//===----------------------------------------------------------------------===//
|
||||
|
||||
def Arith_ConstantOp : Op<Arithmetic_Dialect, "constant",
|
||||
[ConstantLike, NoSideEffect, TypesMatchWith<
|
||||
"result type has same type as the attribute value",
|
||||
[ConstantLike, NoSideEffect,
|
||||
DeclareOpInterfaceMethods<OpAsmOpInterface, ["getAsmResultNames"]>,
|
||||
TypesMatchWith<
|
||||
"result and attribute have the same type",
|
||||
"value", "result", "$_self">]> {
|
||||
let summary = "integer or floating point constant";
|
||||
let description = [{
|
||||
The `const` operation produces an SSA value equal to some integer or
|
||||
The `constant` operation produces an SSA value equal to some integer or
|
||||
floating-point constant specified by an attribute. This is the way MLIR
|
||||
forms simple integer and floating point constants.
|
||||
|
||||
|
|
@ -140,7 +143,14 @@ def Arith_ConstantOp : Op<Arithmetic_Dialect, "constant",
|
|||
}];
|
||||
|
||||
let arguments = (ins AnyAttr:$value);
|
||||
let results = (outs SignlessIntegerOrFloatLike:$result);
|
||||
// TODO: Disallow arith.constant to return anything other than a signless
|
||||
// integer or float like. Downstream users of Arithmetic should only be
|
||||
// working with signless integers, floats, or vectors/tensors thereof.
|
||||
// However, it is necessary to allow arith.constant to return vectors/tensors
|
||||
// of strings and signed/unsigned integers (for now) as an artefact of
|
||||
// splitting the Standard dialect.
|
||||
let results = (outs /*SignlessIntegerOrFloatLike*/AnyType:$result);
|
||||
let verifier = [{ return ::verify(*this); }];
|
||||
|
||||
let builders = [
|
||||
OpBuilder<(ins "Attribute":$value),
|
||||
|
|
@ -149,6 +159,12 @@ def Arith_ConstantOp : Op<Arithmetic_Dialect, "constant",
|
|||
[{ build($_builder, $_state, type, value); }]>,
|
||||
];
|
||||
|
||||
let extraClassDeclaration = [{
|
||||
/// Whether the constant op can be constructed with a particular value and
|
||||
/// type.
|
||||
static bool isBuildableWith(Attribute value, Type type);
|
||||
}];
|
||||
|
||||
let hasFolder = 1;
|
||||
let assemblyFormat = "attr-dict $value";
|
||||
}
|
||||
|
|
@ -351,13 +367,13 @@ def Arith_RemSIOp : Arith_IntBinaryOp<"remsi"> {
|
|||
|
||||
```mlir
|
||||
// Scalar signed integer division remainder.
|
||||
%a = remsi %b, %c : i64
|
||||
%a = arith.remsi %b, %c : i64
|
||||
|
||||
// SIMD vector element-wise division remainder.
|
||||
%f = remsi %g, %h : vector<4xi32>
|
||||
%f = arith.remsi %g, %h : vector<4xi32>
|
||||
|
||||
// Tensor element-wise integer division remainder.
|
||||
%x = remsi %y, %z : tensor<4x?xi8>
|
||||
%x = arith.remsi %y, %z : tensor<4x?xi8>
|
||||
```
|
||||
}];
|
||||
let hasFolder = 1;
|
||||
|
|
@ -717,10 +733,10 @@ def Arith_TruncIOp : Arith_IToICastOp<"trunci"> {
|
|||
|
||||
```mlir
|
||||
%1 = arith.constant 21 : i5 // %1 is 0b10101
|
||||
%2 = trunci %1 : i5 to i4 // %2 is 0b0101
|
||||
%3 = trunci %1 : i5 to i3 // %3 is 0b101
|
||||
%2 = arith.trunci %1 : i5 to i4 // %2 is 0b0101
|
||||
%3 = arith.trunci %1 : i5 to i3 // %3 is 0b101
|
||||
|
||||
%5 = trunci %0 : vector<2 x i32> to vector<2 x i16>
|
||||
%5 = arith.trunci %0 : vector<2 x i32> to vector<2 x i16>
|
||||
```
|
||||
}];
|
||||
|
||||
|
|
@ -803,7 +819,14 @@ def Arith_FPToSIOp : Arith_FToICastOp<"fptosi"> {
|
|||
// IndexCastOp
|
||||
//===----------------------------------------------------------------------===//
|
||||
|
||||
def Arith_IndexCastOp : Arith_IToICastOp<"index_cast"> {
|
||||
// Index cast can convert between memrefs of signless integers and indices too.
|
||||
def IndexCastTypeConstraint : TypeConstraint<Or<[
|
||||
SignlessIntegerLike.predicate,
|
||||
MemRefOf<[AnySignlessInteger, Index]>.predicate]>,
|
||||
"signless-integer-like or memref of signless-integer">;
|
||||
|
||||
def Arith_IndexCastOp : Arith_CastOp<"index_cast", IndexCastTypeConstraint,
|
||||
IndexCastTypeConstraint> {
|
||||
let summary = "cast between index and integer types";
|
||||
let description = [{
|
||||
Casts between scalar or vector integers and corresponding 'index' scalar or
|
||||
|
|
@ -820,8 +843,15 @@ def Arith_IndexCastOp : Arith_IToICastOp<"index_cast"> {
|
|||
// BitcastOp
|
||||
//===----------------------------------------------------------------------===//
|
||||
|
||||
def Arith_BitcastOp : Arith_CastOp<"bitcast", SignlessIntegerOrFloatLike,
|
||||
SignlessIntegerOrFloatLike> {
|
||||
// Bitcast can convert between memrefs of signless integers, indices, and
|
||||
// floats too.
|
||||
def BitcastTypeConstraint : TypeConstraint<Or<[
|
||||
SignlessIntegerOrFloatLike.predicate,
|
||||
MemRefOf<[AnySignlessInteger, Index, AnyFloat]>.predicate]>,
|
||||
"signless-integer-or-float-like or memref of signless-integer or float">;
|
||||
|
||||
def Arith_BitcastOp : Arith_CastOp<"bitcast", BitcastTypeConstraint,
|
||||
BitcastTypeConstraint> {
|
||||
let summary = "bitcast between values of equal bit width";
|
||||
let description = [{
|
||||
Bitcast an integer or floating point value to an integer or floating point
|
||||
|
|
@ -927,10 +957,10 @@ def Arith_CmpIOp : Arith_CompareOp<"cmpi"> {
|
|||
|
||||
let extraClassDeclaration = [{
|
||||
static StringRef getPredicateAttrName() { return "predicate"; }
|
||||
static CmpIPredicate getPredicateByName(StringRef name);
|
||||
static arith::CmpIPredicate getPredicateByName(StringRef name);
|
||||
|
||||
CmpIPredicate getPredicate() {
|
||||
return (CmpIPredicate) (*this)->getAttrOfType<IntegerAttr>(
|
||||
arith::CmpIPredicate getPredicate() {
|
||||
return (arith::CmpIPredicate) (*this)->getAttrOfType<IntegerAttr>(
|
||||
getPredicateAttrName()).getInt();
|
||||
}
|
||||
}];
|
||||
|
|
@ -983,10 +1013,10 @@ def Arith_CmpFOp : Arith_CompareOp<"cmpf"> {
|
|||
|
||||
let extraClassDeclaration = [{
|
||||
static StringRef getPredicateAttrName() { return "predicate"; }
|
||||
static CmpFPredicate getPredicateByName(StringRef name);
|
||||
static arith::CmpFPredicate getPredicateByName(StringRef name);
|
||||
|
||||
CmpFPredicate getPredicate() {
|
||||
return (CmpFPredicate) (*this)->getAttrOfType<IntegerAttr>(
|
||||
arith::CmpFPredicate getPredicate() {
|
||||
return (arith::CmpFPredicate) (*this)->getAttrOfType<IntegerAttr>(
|
||||
getPredicateAttrName()).getInt();
|
||||
}
|
||||
}];
|
||||
|
|
|
|||
|
|
@ -0,0 +1,5 @@
|
|||
set(LLVM_TARGET_DEFINITIONS Passes.td)
|
||||
mlir_tablegen(Passes.h.inc -gen-pass-decls -name Arithmetic)
|
||||
add_public_tablegen_target(MLIRArithmeticTransformsIncGen)
|
||||
|
||||
add_mlir_doc(Passes ArithmeticPasses ./ -gen-pass-doc)
|
||||
|
|
@ -0,0 +1,42 @@
|
|||
//===- Passes.h - Pass Entrypoints ------------------------------*- C++ -*-===//
|
||||
//
|
||||
// Part of the LLVM Project, under the Apache License v2.0 with LLVM Exceptions.
|
||||
// See https://llvm.org/LICENSE.txt for license information.
|
||||
// SPDX-License-Identifier: Apache-2.0 WITH LLVM-exception
|
||||
//
|
||||
//===----------------------------------------------------------------------===//
|
||||
|
||||
#ifndef MLIR_DIALECT_ARITHMETIC_TRANSFORMS_PASSES_H_
|
||||
#define MLIR_DIALECT_ARITHMETIC_TRANSFORMS_PASSES_H_
|
||||
|
||||
#include "mlir/Pass/Pass.h"
|
||||
#include "mlir/Transforms/Bufferize.h"
|
||||
|
||||
namespace mlir {
|
||||
namespace arith {
|
||||
|
||||
/// Add patterns to bufferize Arithmetic ops.
|
||||
void populateArithmeticBufferizePatterns(BufferizeTypeConverter &typeConverter,
|
||||
RewritePatternSet &patterns);
|
||||
|
||||
/// Create a pass to bufferize Arithmetic ops.
|
||||
std::unique_ptr<Pass> createArithmeticBufferizePass();
|
||||
|
||||
/// Add patterns to expand Arithmetic ops for LLVM lowering.
|
||||
void populateArithmeticExpandOpsPatterns(RewritePatternSet &patterns);
|
||||
|
||||
/// Create a pass to legalize Arithmetic ops for LLVM lowering.
|
||||
std::unique_ptr<Pass> createArithmeticExpandOpsPass();
|
||||
|
||||
//===----------------------------------------------------------------------===//
|
||||
// Registration
|
||||
//===----------------------------------------------------------------------===//
|
||||
|
||||
/// Generate the code for registering passes.
|
||||
#define GEN_PASS_REGISTRATION
|
||||
#include "mlir/Dialect/Arithmetic/Transforms/Passes.h.inc"
|
||||
|
||||
} // end namespace arith
|
||||
} // end namespace mlir
|
||||
|
||||
#endif // MLIR_DIALECT_ARITHMETIC_TRANSFORMS_PASSES_H_
|
||||
|
|
@ -0,0 +1,26 @@
|
|||
//===-- Passes.td - Arithmetic pass definition file --------*- tablegen -*-===//
|
||||
//
|
||||
// Part of the LLVM Project, under the Apache License v2.0 with LLVM Exceptions.
|
||||
// See https://llvm.org/LICENSE.txt for license information.
|
||||
// SPDX-License-Identifier: Apache-2.0 WITH LLVM-exception
|
||||
//
|
||||
//===----------------------------------------------------------------------===//
|
||||
|
||||
#ifndef MLIR_DIALECT_ARITHMETIC_TRANSFORMS_PASSES
|
||||
#define MLIR_DIALECT_ARITHMETIC_TRANSFORMS_PASSES
|
||||
|
||||
include "mlir/Pass/PassBase.td"
|
||||
|
||||
def ArithmeticBufferize : FunctionPass<"arith-bufferize"> {
|
||||
let summary = "Bufferize Arithmetic dialect ops.";
|
||||
let constructor = "mlir::arith::createArithmeticBufferizePass()";
|
||||
let dependentDialects = ["memref::MemRefDialect"];
|
||||
}
|
||||
|
||||
def ArithmeticExpandOps : FunctionPass<"arith-expand"> {
|
||||
let summary = "Legalize Arithmetic ops to be convertible to LLVM.";
|
||||
let constructor = "mlir::arith::createArithmeticExpandOpsPass()";
|
||||
let dependentDialects = ["StandardOpsDialect"];
|
||||
}
|
||||
|
||||
#endif // MLIR_DIALECT_ARITHMETIC_TRANSFORMS_PASSES
|
||||
|
|
@ -15,7 +15,7 @@
|
|||
|
||||
include "mlir/Interfaces/SideEffectInterfaces.td"
|
||||
include "mlir/Dialect/LLVMIR/LLVMOpBase.td"
|
||||
include "mlir/Dialect/StandardOps/IR/StandardOpsBase.td"
|
||||
include "mlir/Dialect/Arithmetic/IR/ArithmeticBase.td"
|
||||
include "mlir/Dialect/ArmSVE/ArmSVEOpBase.td"
|
||||
|
||||
//===----------------------------------------------------------------------===//
|
||||
|
|
@ -460,24 +460,24 @@ def ScalableCmpFOp : ArmSVE_Op<"cmpf", [NoSideEffect, SameTypeOperands,
|
|||
```
|
||||
}];
|
||||
let arguments = (ins
|
||||
CmpFPredicateAttr:$predicate,
|
||||
Arith_CmpFPredicateAttr:$predicate,
|
||||
ScalableVectorOf<[AnyFloat]>:$lhs,
|
||||
ScalableVectorOf<[AnyFloat]>:$rhs // TODO: This should support a simple scalar
|
||||
);
|
||||
let results = (outs ScalableVectorOf<[I1]>:$result);
|
||||
|
||||
let builders = [
|
||||
OpBuilder<(ins "CmpFPredicate":$predicate, "Value":$lhs,
|
||||
OpBuilder<(ins "arith::CmpFPredicate":$predicate, "Value":$lhs,
|
||||
"Value":$rhs), [{
|
||||
buildScalableCmpFOp($_builder, $_state, predicate, lhs, rhs);
|
||||
}]>];
|
||||
|
||||
let extraClassDeclaration = [{
|
||||
static StringRef getPredicateAttrName() { return "predicate"; }
|
||||
static CmpFPredicate getPredicateByName(StringRef name);
|
||||
static arith::CmpFPredicate getPredicateByName(StringRef name);
|
||||
|
||||
CmpFPredicate getPredicate() {
|
||||
return (CmpFPredicate)(*this)->getAttrOfType<IntegerAttr>(
|
||||
arith::CmpFPredicate getPredicate() {
|
||||
return (arith::CmpFPredicate) (*this)->getAttrOfType<IntegerAttr>(
|
||||
getPredicateAttrName()).getInt();
|
||||
}
|
||||
}];
|
||||
|
|
@ -520,24 +520,24 @@ def ScalableCmpIOp : ArmSVE_Op<"cmpi", [NoSideEffect, SameTypeOperands,
|
|||
}];
|
||||
|
||||
let arguments = (ins
|
||||
CmpIPredicateAttr:$predicate,
|
||||
Arith_CmpIPredicateAttr:$predicate,
|
||||
ScalableVectorOf<[I8, I16, I32, I64]>:$lhs,
|
||||
ScalableVectorOf<[I8, I16, I32, I64]>:$rhs
|
||||
);
|
||||
let results = (outs ScalableVectorOf<[I1]>:$result);
|
||||
|
||||
let builders = [
|
||||
OpBuilder<(ins "CmpIPredicate":$predicate, "Value":$lhs,
|
||||
OpBuilder<(ins "arith::CmpIPredicate":$predicate, "Value":$lhs,
|
||||
"Value":$rhs), [{
|
||||
buildScalableCmpIOp($_builder, $_state, predicate, lhs, rhs);
|
||||
}]>];
|
||||
|
||||
let extraClassDeclaration = [{
|
||||
static StringRef getPredicateAttrName() { return "predicate"; }
|
||||
static CmpIPredicate getPredicateByName(StringRef name);
|
||||
static arith::CmpIPredicate getPredicateByName(StringRef name);
|
||||
|
||||
CmpIPredicate getPredicate() {
|
||||
return (CmpIPredicate)(*this)->getAttrOfType<IntegerAttr>(
|
||||
arith::CmpIPredicate getPredicate() {
|
||||
return (arith::CmpIPredicate) (*this)->getAttrOfType<IntegerAttr>(
|
||||
getPredicateAttrName()).getInt();
|
||||
}
|
||||
}];
|
||||
|
|
|
|||
|
|
@ -32,7 +32,11 @@ def AsyncParallelFor : Pass<"async-parallel-for", "ModuleOp"> {
|
|||
"The minimum task size for sharding parallel operation.">
|
||||
];
|
||||
|
||||
let dependentDialects = ["async::AsyncDialect", "scf::SCFDialect"];
|
||||
let dependentDialects = [
|
||||
"arith::ArithmeticDialect",
|
||||
"async::AsyncDialect",
|
||||
"scf::SCFDialect"
|
||||
];
|
||||
}
|
||||
|
||||
def AsyncToAsyncRuntime : Pass<"async-to-async-runtime", "ModuleOp"> {
|
||||
|
|
|
|||
|
|
@ -9,6 +9,8 @@
|
|||
#ifndef MLIR_DIALECT_COMPLEX_IR_COMPLEX_H_
|
||||
#define MLIR_DIALECT_COMPLEX_IR_COMPLEX_H_
|
||||
|
||||
#include "mlir/Dialect/Arithmetic/IR/Arithmetic.h"
|
||||
#include "mlir/Dialect/StandardOps/IR/Ops.h"
|
||||
#include "mlir/IR/BuiltinTypes.h"
|
||||
#include "mlir/IR/Dialect.h"
|
||||
#include "mlir/IR/OpDefinition.h"
|
||||
|
|
|
|||
|
|
@ -18,6 +18,9 @@ def Complex_Dialect : Dialect {
|
|||
The complex dialect is intended to hold complex numbers creation and
|
||||
arithmetic ops.
|
||||
}];
|
||||
|
||||
let dependentDialects = ["arith::ArithmeticDialect", "StandardOpsDialect"];
|
||||
let hasConstantMaterializer = 1;
|
||||
}
|
||||
|
||||
#endif // COMPLEX_BASE
|
||||
|
|
|
|||
|
|
@ -51,6 +51,8 @@ def GPU_Dialect : Dialect {
|
|||
/// space.
|
||||
static unsigned getPrivateAddressSpace() { return 5; }
|
||||
}];
|
||||
|
||||
let dependentDialects = ["arith::ArithmeticDialect"];
|
||||
}
|
||||
|
||||
def GPU_AsyncToken : DialectType<
|
||||
|
|
|
|||
|
|
@ -14,6 +14,7 @@
|
|||
#ifndef MLIR_DIALECT_GPU_GPUDIALECT_H
|
||||
#define MLIR_DIALECT_GPU_GPUDIALECT_H
|
||||
|
||||
#include "mlir/Dialect/Arithmetic/IR/Arithmetic.h"
|
||||
#include "mlir/Dialect/DLTI/Traits.h"
|
||||
#include "mlir/IR/Builders.h"
|
||||
#include "mlir/IR/BuiltinTypes.h"
|
||||
|
|
|
|||
|
|
@ -627,7 +627,7 @@ def GPU_AllReduceOp : GPU_Op<"all_reduce",
|
|||
%1 = "gpu.all_reduce"(%0) ({}) { op = "add" } : (f32) -> (f32)
|
||||
%2 = "gpu.all_reduce"(%0) ({
|
||||
^bb(%lhs : f32, %rhs : f32):
|
||||
%sum = addf %lhs, %rhs : f32
|
||||
%sum = arith.addf %lhs, %rhs : f32
|
||||
"gpu.yield"(%sum) : (f32) -> ()
|
||||
}) : (f32) -> (f32)
|
||||
```
|
||||
|
|
|
|||
|
|
@ -33,11 +33,16 @@ def Linalg_Dialect : Dialect {
|
|||
}];
|
||||
let cppNamespace = "::mlir::linalg";
|
||||
let dependentDialects = [
|
||||
"AffineDialect", "math::MathDialect", "memref::MemRefDialect",
|
||||
"StandardOpsDialect", "tensor::TensorDialect"
|
||||
"arith::ArithmeticDialect",
|
||||
"AffineDialect",
|
||||
"math::MathDialect",
|
||||
"memref::MemRefDialect",
|
||||
"StandardOpsDialect",
|
||||
"tensor::TensorDialect",
|
||||
];
|
||||
let hasCanonicalizer = 1;
|
||||
let hasOperationAttrVerify = 1;
|
||||
let hasConstantMaterializer = 1;
|
||||
let extraClassDeclaration = [{
|
||||
/// Attribute name used to to memoize indexing maps for named ops.
|
||||
constexpr const static ::llvm::StringLiteral
|
||||
|
|
|
|||
|
|
@ -283,8 +283,8 @@ def GenericOp : LinalgStructuredBase_Op<"generic", [
|
|||
outs(%C : memref<?x?xf32, stride_specification>)
|
||||
{other-optional-attributes} {
|
||||
^bb0(%a: f32, %b: f32, %c: f32) :
|
||||
%d = mulf %a, %b: f32
|
||||
%e = addf %c, %d: f32
|
||||
%d = arith.mulf %a, %b: f32
|
||||
%e = arith.addf %c, %d: f32
|
||||
linalg.yield %e : f32
|
||||
}
|
||||
```
|
||||
|
|
@ -306,8 +306,8 @@ def GenericOp : LinalgStructuredBase_Op<"generic", [
|
|||
%a = load %A[%m, %k] : memref<?x?xf32, stride_specification>
|
||||
%b = load %B[%k, %n] : memref<?x?xf32, stride_specification>
|
||||
%c = load %C[%m, %n] : memref<?x?xf32, stride_specification>
|
||||
%d = mulf %a, %b: f32
|
||||
%e = addf %c, %d: f32
|
||||
%d = arith.mulf %a, %b: f32
|
||||
%e = arith.addf %c, %d: f32
|
||||
store %e, %C[%m, %n] : memref<?x?x?xf32, stride_specification>
|
||||
}
|
||||
}
|
||||
|
|
|
|||
|
|
@ -10,6 +10,7 @@
|
|||
#define MLIR_DIALECT_LINALG_LINALGTYPES_H_
|
||||
|
||||
#include "mlir/Dialect/Affine/IR/AffineOps.h"
|
||||
#include "mlir/Dialect/Arithmetic/IR/Arithmetic.h"
|
||||
#include "mlir/Dialect/Math/IR/Math.h"
|
||||
#include "mlir/Dialect/MemRef/IR/MemRef.h"
|
||||
#include "mlir/Dialect/StandardOps/IR/Ops.h"
|
||||
|
|
|
|||
|
|
@ -143,7 +143,7 @@ def LinalgBufferize : Pass<"linalg-bufferize", "FuncOp"> {
|
|||
let dependentDialects = [
|
||||
"linalg::LinalgDialect",
|
||||
"AffineDialect",
|
||||
"memref::MemRefDialect"
|
||||
"memref::MemRefDialect",
|
||||
];
|
||||
}
|
||||
|
||||
|
|
|
|||
|
|
@ -271,7 +271,7 @@ enum class DistributionMethod {
|
|||
/// to
|
||||
///
|
||||
/// %iv = %lb + %procId * %step
|
||||
/// %cond = cmpi "slt", %iv, %ub
|
||||
/// %cond = arith.cmpi "slt", %iv, %ub
|
||||
/// scf.if %cond {
|
||||
/// ...
|
||||
/// }
|
||||
|
|
|
|||
|
|
@ -9,6 +9,7 @@
|
|||
#ifndef MLIR_DIALECT_MEMREF_IR_MEMREF_H_
|
||||
#define MLIR_DIALECT_MEMREF_IR_MEMREF_H_
|
||||
|
||||
#include "mlir/Dialect/Arithmetic/IR/Arithmetic.h"
|
||||
#include "mlir/Dialect/Tensor/IR/Tensor.h"
|
||||
#include "mlir/Dialect/Utils/ReshapeOpsUtils.h"
|
||||
#include "mlir/IR/Dialect.h"
|
||||
|
|
|
|||
|
|
@ -19,7 +19,7 @@ def MemRef_Dialect : Dialect {
|
|||
manipulation ops, which are not strongly associated with any particular
|
||||
other dialect or domain abstraction.
|
||||
}];
|
||||
let dependentDialects = ["tensor::TensorDialect"];
|
||||
let dependentDialects = ["arith::ArithmeticDialect", "tensor::TensorDialect"];
|
||||
let hasConstantMaterializer = 1;
|
||||
}
|
||||
|
||||
|
|
|
|||
|
|
@ -158,7 +158,7 @@ def WsLoopOp : OpenMP_Op<"wsloop", [AttrSizedOperandSegments,
|
|||
omp.wsloop (%i1, %i2) : index = (%c0, %c0) to (%c10, %c10) step (%c1, %c1) {
|
||||
%a = load %arrA[%i1, %i2] : memref<?x?xf32>
|
||||
%b = load %arrB[%i1, %i2] : memref<?x?xf32>
|
||||
%sum = addf %a, %b : f32
|
||||
%sum = arith.addf %a, %b : f32
|
||||
store %sum, %arrC[%i1, %i2] : memref<?x?xf32>
|
||||
omp.yield
|
||||
}
|
||||
|
|
|
|||
|
|
@ -94,18 +94,18 @@ def SCFForToWhileLoop
|
|||
```mlir
|
||||
# Before:
|
||||
scf.for %i = %c0 to %arg1 step %c1 {
|
||||
%0 = addi %arg2, %arg2 : i32
|
||||
%0 = arith.addi %arg2, %arg2 : i32
|
||||
memref.store %0, %arg0[%i] : memref<?xi32>
|
||||
}
|
||||
|
||||
# After:
|
||||
%0 = scf.while (%i = %c0) : (index) -> index {
|
||||
%1 = cmpi slt, %i, %arg1 : index
|
||||
%1 = arith.cmpi slt, %i, %arg1 : index
|
||||
scf.condition(%1) %i : index
|
||||
} do {
|
||||
^bb0(%i: index): // no predecessors
|
||||
%1 = addi %i, %c1 : index
|
||||
%2 = addi %arg2, %arg2 : i32
|
||||
%1 = arith.addi %i, %c1 : index
|
||||
%2 = arith.addi %arg2, %arg2 : i32
|
||||
memref.store %2, %arg0[%i] : memref<?xi32>
|
||||
scf.yield %1 : index
|
||||
}
|
||||
|
|
|
|||
|
|
@ -13,6 +13,7 @@
|
|||
#ifndef MLIR_DIALECT_SCF_H_
|
||||
#define MLIR_DIALECT_SCF_H_
|
||||
|
||||
#include "mlir/Dialect/Arithmetic/IR/Arithmetic.h"
|
||||
#include "mlir/IR/Attributes.h"
|
||||
#include "mlir/IR/Builders.h"
|
||||
#include "mlir/IR/Dialect.h"
|
||||
|
|
@ -86,9 +87,9 @@ LoopNest buildLoopNest(
|
|||
/// expect the body building functions to return their current value.
|
||||
/// The built nested scf::For are captured in `capturedLoops` when non-null.
|
||||
LoopNest buildLoopNest(OpBuilder &builder, Location loc, ValueRange lbs,
|
||||
ValueRange ubs, ValueRange steps,
|
||||
function_ref<void(OpBuilder &, Location, ValueRange)>
|
||||
bodyBuilder = nullptr);
|
||||
ValueRange ubs, ValueRange steps,
|
||||
function_ref<void(OpBuilder &, Location, ValueRange)>
|
||||
bodyBuilder = nullptr);
|
||||
|
||||
} // end namespace scf
|
||||
} // end namespace mlir
|
||||
|
|
|
|||
|
|
@ -20,6 +20,7 @@ include "mlir/Interfaces/SideEffectInterfaces.td"
|
|||
def SCF_Dialect : Dialect {
|
||||
let name = "scf";
|
||||
let cppNamespace = "::mlir::scf";
|
||||
let dependentDialects = ["arith::ArithmeticDialect"];
|
||||
}
|
||||
|
||||
// Base class for SCF dialect ops.
|
||||
|
|
@ -170,7 +171,7 @@ def ForOp : SCF_Op<"for",
|
|||
%sum = scf.for %iv = %lb to %ub step %step
|
||||
iter_args(%sum_iter = %sum_0) -> (f32) {
|
||||
%t = load %buffer[%iv] : memref<1024xf32>
|
||||
%sum_next = addf %sum_iter, %t : f32
|
||||
%sum_next = arith.addf %sum_iter, %t : f32
|
||||
// Yield current iteration sum to next iteration %sum_iter or to %sum
|
||||
// if final iteration.
|
||||
scf.yield %sum_next : f32
|
||||
|
|
@ -194,9 +195,9 @@ def ForOp : SCF_Op<"for",
|
|||
%sum = scf.for %iv = %lb to %ub step %step
|
||||
iter_args(%sum_iter = %sum_0) -> (f32) {
|
||||
%t = load %buffer[%iv] : memref<1024xf32>
|
||||
%cond = cmpf "ugt", %t, %c0 : f32
|
||||
%cond = arith.cmpf "ugt", %t, %c0 : f32
|
||||
%sum_next = scf.if %cond -> (f32) {
|
||||
%new_sum = addf %sum_iter, %t : f32
|
||||
%new_sum = arith.addf %sum_iter, %t : f32
|
||||
scf.yield %new_sum : f32
|
||||
} else {
|
||||
scf.yield %sum_iter : f32
|
||||
|
|
@ -451,7 +452,7 @@ def ParallelOp : SCF_Op<"parallel",
|
|||
%elem_to_reduce = load %buffer[%iv] : memref<100xf32>
|
||||
scf.reduce(%elem_to_reduce) : f32 {
|
||||
^bb0(%lhs : f32, %rhs: f32):
|
||||
%res = addf %lhs, %rhs : f32
|
||||
%res = arith.addf %lhs, %rhs : f32
|
||||
scf.reduce.return %res : f32
|
||||
}
|
||||
}
|
||||
|
|
@ -519,7 +520,7 @@ def ReduceOp : SCF_Op<"reduce", [HasParent<"ParallelOp">]> {
|
|||
%operand = constant 1.0 : f32
|
||||
scf.reduce(%operand) : f32 {
|
||||
^bb0(%lhs : f32, %rhs: f32):
|
||||
%res = addf %lhs, %rhs : f32
|
||||
%res = arith.addf %lhs, %rhs : f32
|
||||
scf.reduce.return %res : f32
|
||||
}
|
||||
```
|
||||
|
|
|
|||
|
|
@ -14,6 +14,7 @@
|
|||
#ifndef MLIR_SHAPE_IR_SHAPE_H
|
||||
#define MLIR_SHAPE_IR_SHAPE_H
|
||||
|
||||
#include "mlir/Dialect/Arithmetic/IR/Arithmetic.h"
|
||||
#include "mlir/Dialect/Tensor/IR/Tensor.h"
|
||||
#include "mlir/IR/BuiltinOps.h"
|
||||
#include "mlir/IR/Dialect.h"
|
||||
|
|
|
|||
|
|
@ -35,7 +35,7 @@ def ShapeDialect : Dialect {
|
|||
}];
|
||||
|
||||
let cppNamespace = "::mlir::shape";
|
||||
let dependentDialects = ["tensor::TensorDialect"];
|
||||
let dependentDialects = ["arith::ArithmeticDialect", "tensor::TensorDialect"];
|
||||
|
||||
let hasConstantMaterializer = 1;
|
||||
let hasOperationAttrVerify = 1;
|
||||
|
|
|
|||
|
|
@ -43,8 +43,8 @@ def Sparsification : Pass<"sparsification", "ModuleOp"> {
|
|||
ins(%arga, %argb: tensor<?x?xf64, #SparseMatrix>, tensor<?xf64>)
|
||||
outs(%argx: tensor<?xf64>) {
|
||||
^bb(%a: f64, %b: f64, %x: f64):
|
||||
%0 = mulf %a, %b : f64
|
||||
%1 = addf %x, %0 : f64
|
||||
%0 = arith.mulf %a, %b : f64
|
||||
%1 = arith.addf %x, %0 : f64
|
||||
linalg.yield %1 : f64
|
||||
} -> tensor<?xf64>
|
||||
return %0 : tensor<?xf64>
|
||||
|
|
@ -54,6 +54,7 @@ def Sparsification : Pass<"sparsification", "ModuleOp"> {
|
|||
let constructor = "mlir::createSparsificationPass()";
|
||||
let dependentDialects = [
|
||||
"AffineDialect",
|
||||
"arith::ArithmeticDialect",
|
||||
"LLVM::LLVMDialect",
|
||||
"memref::MemRefDialect",
|
||||
"scf::SCFDialect",
|
||||
|
|
@ -103,6 +104,7 @@ def SparseTensorConversion : Pass<"sparse-tensor-conversion", "ModuleOp"> {
|
|||
}];
|
||||
let constructor = "mlir::createSparseTensorConversionPass()";
|
||||
let dependentDialects = [
|
||||
"arith::ArithmeticDialect",
|
||||
"LLVM::LLVMDialect",
|
||||
"memref::MemRefDialect",
|
||||
"scf::SCFDialect",
|
||||
|
|
|
|||