|
|
||
|---|---|---|
| .. | ||
| config | ||
| dataset_processing | ||
| docker | ||
| docs | ||
| etc | ||
| img | ||
| output | ||
| scripts | ||
| scripts_exp | ||
| uie | ||
| .gitignore | ||
| README.md | ||
| inference.py | ||
| plot_from_tensorboard.py | ||
| requirements.txt | ||
| run_eval.bash | ||
| run_seq2seq.py | ||
| run_seq2seq_pretrain.bash | ||
| run_seq2seq_record.bash | ||
| run_seq2seq_record_ratio.bash | ||
| run_seq2seq_record_shot.bash | ||
| uie_json.py | ||
README.md
Universal Information Extraction with Meta-Pretrained Self-Retrieval
This code is for ACL 2023 Findings paper "Universal Information Extraction with Meta-Pretrained Self-Retrieval".
Overview
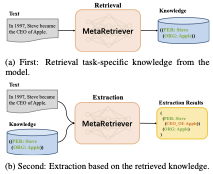
Universal Information Extraction (Universal IE) aims to solve different extraction tasks in a uniform text-to-structure generation manner. Such a generation procedure tends to struggle when there exist complex information structures to be extracted. Retrieving knowledge from external knowledge bases may help models to overcome this problem but it is impossible to construct a knowledge base suitable for various IE tasks. Inspired by the fact that large amount of knowledge are stored in the pretrained language models (PLM) and can be retrieved explicitly, in this paper, we propose MetaRetriever to retrieve task-specific knowledge from PLMs to enhance universal IE. As different IE tasks need different knowledge, we further propose a Meta-Pretraining Algorithm which allows MetaRetriever to quicktly achieve maximum task-specific retrieval performance when fine-tuning on downstream IE tasks. Experimental results show that MetaRetriever achieves the new state-of-the-art on 4 IE tasks, 12 datasets under fully-supervised, low-resource and few-shot scenarios.
Requirements
General
- Python (verified on 3.8)
- CUDA (verified on 10.2)
Python Packages
conda create -n metaretriever python=3.8
conda install -y pytorch==1.8.0 torchvision==0.9.0 torchaudio==0.8.0 cudatoolkit=10.2 -c pytorch
pip install -r requirements.txt
NOTE: Different versions of packages (such as pytorch, transformers, etc.) may lead to different results from the paper. However, the trend should still hold no matter what versions of packages you use.
Usage
Data Preprocess
cd ./dataset_processing/ours
bash download_and_preprocess_data_clean.sh > clean_log.txt
Model Preparation
Please refer to UIE to download UIE model checkpoint and put it under the models dir.
Meta-Pretraining
bash run_seq2seq_pretrain.bash -v -d 0,1,2,3,4,5,6,7 -b 64 -k 1 --lr 1e-4 --warmup_ratio 0.06 -i relation/ours_clean --spot_noise 0.0 --asoc_noise 0.0 -f spotasoc --map_config config/offset_map/closest_offset_en.yaml -m ./models/uie-base-en --random_prompt --epoch 4 --trainer_type meta_pretrain_v2 --use_prompt_tuning_model False --output_dir output/meta-pretrained-model
Meta-Finetuning
- Full Supervision Scenario
. config/exp_conf/large_model_conf.ini && trainer_type=meta_finetune_v2 model_name=meta-pretrained-model dataset_name=relation/conll04 selected_gpus=0,1,2,3,4,5,6,7 BATCH_SIZE=4 use_prompt_tuning_model=False run_time=1 bash scripts_exp/run_exp.bash
- Few-Shot Scenario
. config/exp_conf/base_model_conf_sa_shot.ini && trainer_type=meta_finetune_v2 model_name=meta-pretrained-model dataset_name=relation/conll04 selected_gpus=0,1,2,3,4,5,6,7 BATCH_SIZE=16 use_prompt_tuning_model=False bash scripts_exp/run_exp_shot.bash
- Low-Resource Scenario
. config/exp_conf/base_model_conf_sa_ratio.ini && trainer_type=meta_finetune_v2 model_name=meta-pretrained-model dataset_name=relation/conll04 selected_gpus=0,1,2,3,4,5,6,7 BATCH_SIZE=16 use_prompt_tuning_model=False bash scripts_exp/run_exp_ratio.bash
Citation
If this repository helps you, please cite this paper:
@inproceedings{cong-etal-2023-universal,
title = "Universal Information Extraction with Meta-Pretrained Self-Retrieval",
author = "Cong, Xin and
Yu, Bowen and
Fang, Mengcheng and
Liu, Tingwen and
Yu, Haiyang and
Hu, Zhongkai and
Huang, Fei and
Li, Yongbin and
Wang, Bin",
editor = "Rogers, Anna and
Boyd-Graber, Jordan and
Okazaki, Naoaki",
booktitle = "Findings of the Association for Computational Linguistics: ACL 2023",
month = jul,
year = "2023",
address = "Toronto, Canada",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2023.findings-acl.251",
doi = "10.18653/v1/2023.findings-acl.251",
}