|
|
||
|---|---|---|
| .. | ||
| apis | ||
| data | ||
| figures | ||
| init_database | ||
| lv1-lv2-samples | ||
| lv3-samples | ||
| lv3_apis | ||
| .gitignore | ||
| API-Bank-arxiv-version.pdf | ||
| LICENSE | ||
| README.md | ||
| api_call_extraction.py | ||
| demo.py | ||
| evaluator.py | ||
| evaluator_by_json.py | ||
| lv3_evaluator.py | ||
| requirements.txt | ||
| simulator.py | ||
| tool_manager.py | ||
| utils.py | ||
README.md
API-Bank: A Comprehensive Benchmark for Tool-Augmented LLMs
Minghao Li, Yingxiu Zhao, Bowen Yu, Feifan Song, Hangyu Li, Haiyang Yu, Zhoujun Li, Fei Huang, Yongbin Li
arXiv: [Abstract]/[PDF]
News
- The Lynx model is released on HuggingFace Hub.
- API-Bank is accepted by EMNLP 2023.
- The code and data of API-Bank have been released.
Abstract
Recent research has demonstrated that Large Language Models (LLMs) can enhance their capabilities by utilizing external tools. However, three pivotal questions remain unanswered: (1) How effective are current LLMs in utilizing tools? (2) How can we enhance LLMs' ability to utilize tools? (3) What obstacles need to be overcome to leverage tools? To address these questions, we introduce API-Bank, a groundbreaking benchmark, specifically designed for tool-augmented LLMs. For the first question, we develop a runnable evaluation system consisting of 73 API tools. We annotate 314 tool-use dialogues with 753 API calls to assess the existing LLMs' capabilities in planning, retrieving, and calling APIs. For the second question, we construct a comprehensive training set containing 1,888 tool-use dialogues from 2,138 APIs spanning 1,000 distinct domains. Using this dataset, we train Lynx, a tool-augmented LLM initialized from Alpaca. Experimental results demonstrate that GPT-3.5 exhibits improved tool utilization compared to GPT-3, while GPT-4 excels in planning. However, there is still significant potential for further improvement. Moreover, Lynx surpasses Alpaca's tool utilization performance by more than 26 pts and approaches the effectiveness of GPT-3.5. Through error analysis, we highlight the key challenges for future research in this field to answer the third question.
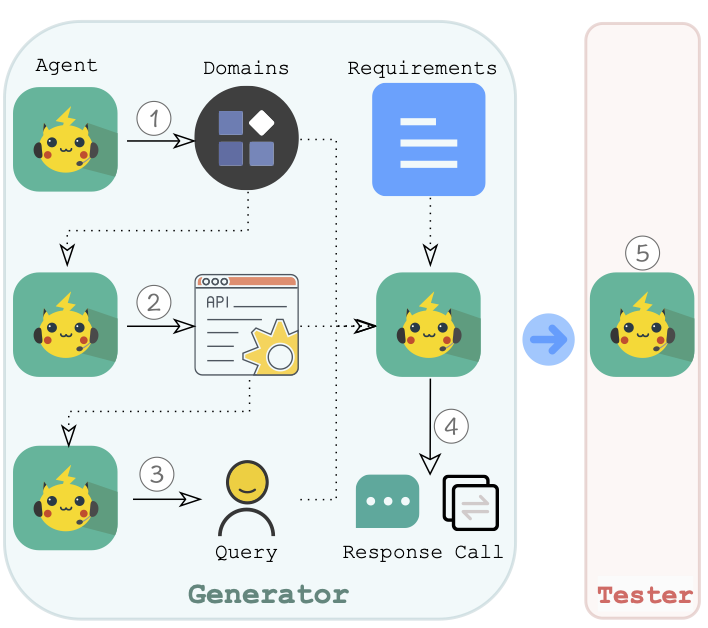
Multi-Agent Dataset Synthesis
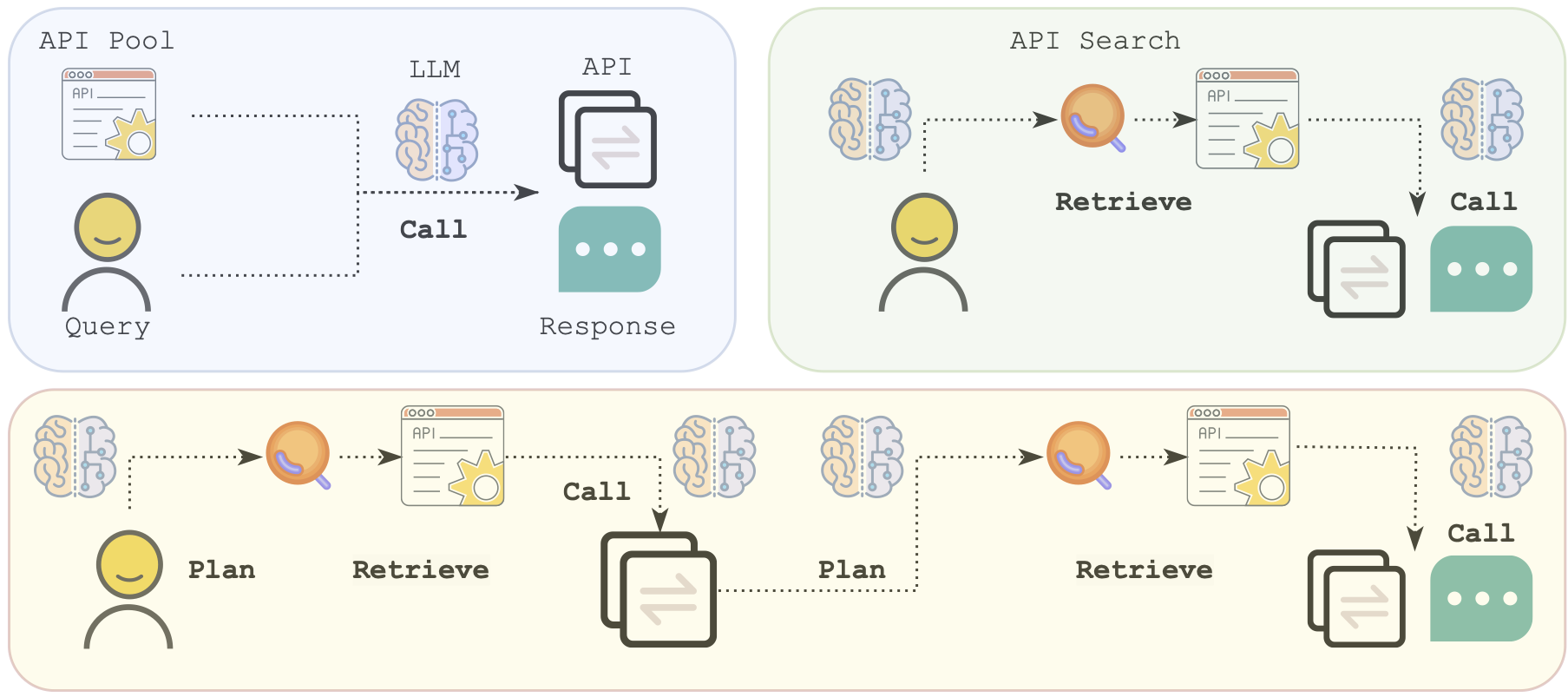
Evaluation Tasks
Demo
As far as we know, there is a conflict between the dependencies of the googletrans package and the dependencies of the gradio package, which may cause the demo not to run properly. There is no good solution, you can uninstall googletrans first when using the demo.
python demo.py
GPT-4
Demo of using GPT-4 to interact with API-Bank:

Alternate links for loading failure:
GitHub: https://github.com/liminghao1630/auxiliary_use/raw/main/gpt-4-demo.gif
JsDelivr: https://cdn.jsdelivr.net/gh/liminghao1630/auxiliary_use/gpt-4-demo.gif
GPT-3.5
Demo of using GPT-3.5 to interact with API-Bank:

Alternate links for loading failure:
GitHub: https://github.com/liminghao1630/auxiliary_use/raw/main/gpt-3.5-demo.gif
JsDelivr: https://cdn.jsdelivr.net/gh/liminghao1630/auxiliary_use/gpt-3.5-demo.gif
Evaluation
The datasets are released on HuggingFace Hub.
The conversation data of level-1 and level-2 are stored in the lv1-lv2-samples directory or test-data, please follow the code in evaluator.py/evaluator_by_json.py to design the evaluation script.
The evaluation of level-3 requires lv3_evaluator.py.
Citation
@misc{li2023apibank,
title={API-Bank: A Benchmark for Tool-Augmented LLMs},
author={Minghao Li and Feifan Song and Bowen Yu and Haiyang Yu and Zhoujun Li and Fei Huang and Yongbin Li},
year={2023},
eprint={2304.08244},
archivePrefix={arXiv},
primaryClass={cs.CL}
}