|
|
||
|---|---|---|
| .. | ||
| MAmmoTH | ||
| MetaMath | ||
| NEFTune | ||
| config | ||
| data | ||
| evaluation | ||
| models | ||
| trainer | ||
| training_scripts | ||
| README.md | ||
| __init__.py | ||
| main.py | ||
| main_res.png | ||
| overview.png | ||
| requirements.txt | ||
{kind=link}
{kind=link}
README.md
Masked Thought
This repository contains the code of for our paper:
Masked Thought: Simply Masking Partial Reasoning Steps Can Improve
Mathematical Reasoning Learning of Language Models
Changyu Chen, Xiting Wang, Ting-En Lin, Ang Lv, Yuchuan Wu, Xin Gao, Ji-Rong Wen, Rui Yan, Yongbin Li
Paper: https://arxiv.org/abs/2403.02178
1. Overview
We propose to use a simple regularization method Masked thought Fine-Tuning (MFT) for the supervised fine-tuning of mathematical reasoning data.
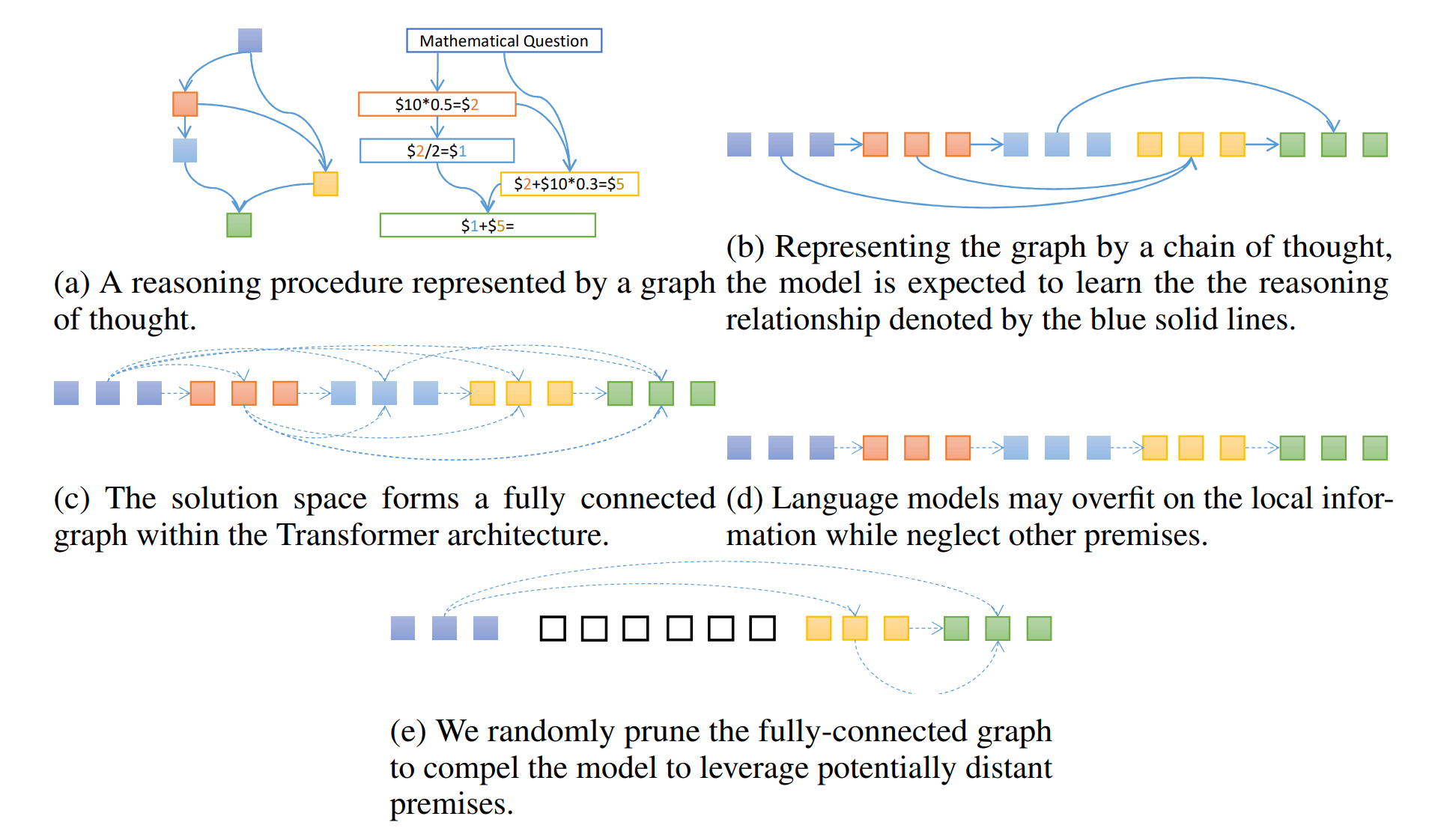
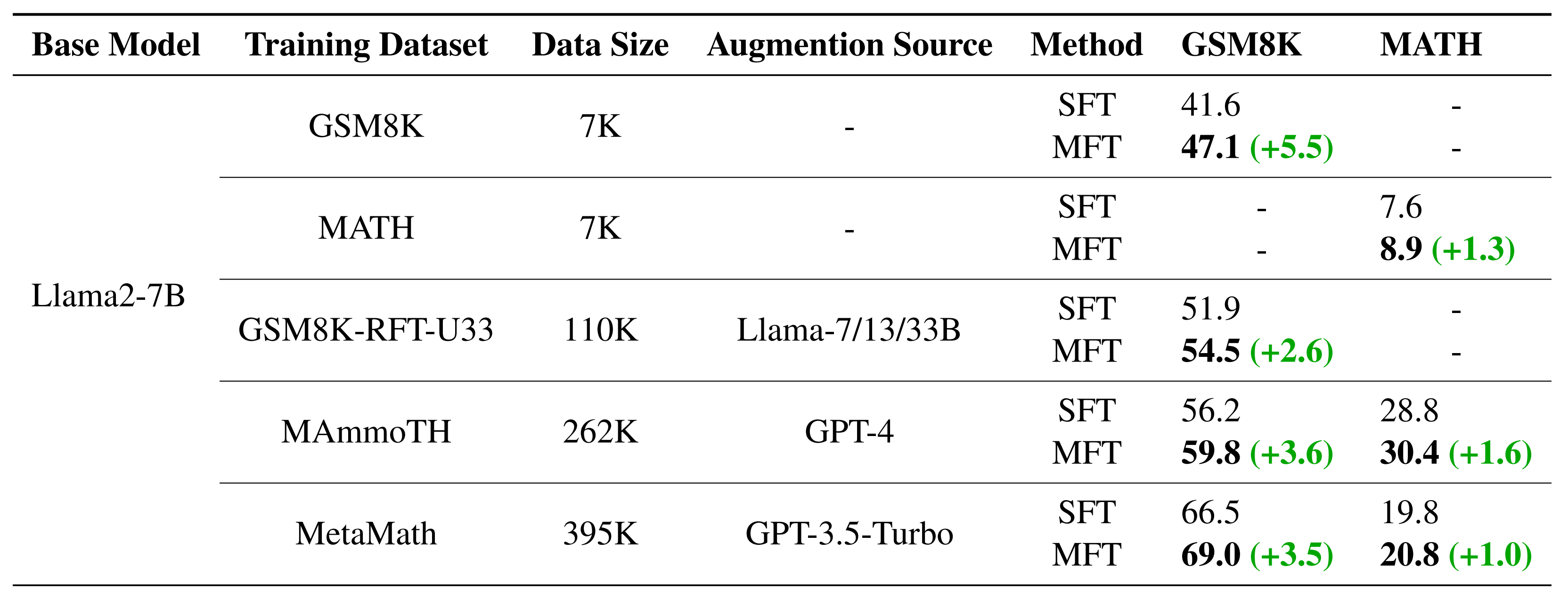
2. Main results
3. Quick Start
1) Installation
conda create -n mask python=3.10
conda activate mask
pip install -r requirements.txt
pip install torch==2.1.0 torchvision==0.16.0 torchaudio==2.1.0 --index-url https://download.pytorch.org/whl/cu118
2) Train
You can start with training GSM8K on Llama-2-7b with the following command, it will take about one hour with 8 NVIDIA A100 GPUs.
bash training_scripts/run_llama2_7b_gsm8k_mft.sh
3) Evaluation
The evaluation take 1 minute using vllm and 1 single A100 GPU.
# exp_name is the experiment identifier in your training script.
bash evluation/run_gen_math_greedy_vllm_1.sh ${exp_name}
python evaluation/get_gsm8k_res.py --model ${exp_name}
For training and evaluation on other datasets and models, you can refer to ./training_scripts, ./MetaMath and ./MAmmoTH.
You can also refer to the repos of MetaMath, MAmmoTH and RFT for more details about their evaluation and datasets.
4. Train with your own code
If you'd like incorporate MFT into your own code, just add the following codes before feeding input_ids to the model. MASK_INDEX can be the token_id of a new added token[mask] or the[pad] in the original tokenizer, depending on your preference.
def mask_target_tokens(input_ids, sources_tokenized, mask_probability, MASK_INDEX, tokenizer):
masked_input_ids = copy.deepcopy(input_ids)
for input_id, source_len in zip(masked_input_ids, sources_tokenized["input_ids_lens"]):
for i in range(source_len, len(input_id)):
if random.random() < mask_probability:
input_id[i] = MASK_INDEX
return masked_input_ids
input_ids = mask_target_tokens(input_ids, sources_tokenized, _mask_probability, MASK_INDEX)
5. Citation
@article{chen2024masked,
title={Masked Thought: Simply Masking Partial Reasoning Steps Can Improve Mathematical Reasoning Learning of Language Models},
author={Chen, Changyu and Wang, Xiting and Lin, Ting-En and Lv, Ang and Wu, Yuchuan and Gao, Xin and Wen, Ji-Rong and Yan, Rui and Li, Yongbin},
journal={arXiv preprint arXiv:2403.02178},
year={2024}
}