Here is the big TTY and Serial patch set for 4.9-rc1.
It also includes some drivers/dma/ changes, as those were needed by some
serial drivers, and they were all acked by the DMA maintainer. Also in
here is the long-suffering ACPI SPCR patchset, which was passed around
from maintainer to maintainer like a hot-potato. Seems I was the
sucker^Wlucky one. All of those patches have been acked by the various
subsystem maintainers as well.
All of this has been in linux-next with no reported issues.
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
-----BEGIN PGP SIGNATURE-----
iFYEABECABYFAlfyNjEPHGdyZWdAa3JvYWguY29tAAoJEDFH1A3bLfspwIcAn2uN
qCD8xQJ0Cs61hD1nUzhNygG8AJ94I4zz/fPGpyh/CtJfLQwtUdLhNA==
=Rken
-----END PGP SIGNATURE-----
Merge tag 'tty-4.9-rc1' of git://git.kernel.org/pub/scm/linux/kernel/git/gregkh/tty
Pull tty and serial updates from Greg KH:
"Here is the big tty and serial patch set for 4.9-rc1.
It also includes some drivers/dma/ changes, as those were needed by
some serial drivers, and they were all acked by the DMA maintainer.
Also in here is the long-suffering ACPI SPCR patchset, which was
passed around from maintainer to maintainer like a hot-potato. Seems I
was the sucker^Wlucky one. All of those patches have been acked by the
various subsystem maintainers as well.
All of this has been in linux-next with no reported issues"
* tag 'tty-4.9-rc1' of git://git.kernel.org/pub/scm/linux/kernel/git/gregkh/tty: (111 commits)
Revert "serial: pl011: add console matching function"
MAINTAINERS: update entry for atmel_serial driver
serial: pl011: add console matching function
ARM64: ACPI: enable ACPI_SPCR_TABLE
ACPI: parse SPCR and enable matching console
of/serial: move earlycon early_param handling to serial
Revert "drivers/tty: Explicitly pass current to show_stack"
tty: amba-pl011: Don't complain on -EPROBE_DEFER when no irq
nios2: dts: 10m50: Add tx-threshold parameter
serial: 8250: Set Altera 16550 TX FIFO Threshold
serial: 8250: of: Load TX FIFO Threshold from DT
Documentation: dt: serial: Add TX FIFO threshold parameter
drivers/tty: Explicitly pass current to show_stack
serial: imx: Fix DCD reading
serial: stm32: mark symbols static where possible
serial: xuartps: Add some register initialisation to cdns_early_console_setup()
serial: xuartps: Removed unwanted checks while reading the error conditions
serial: xuartps: Rewrite the interrupt handling logic
serial: stm32: use mapbase instead of membase for DMA
tty/serial: atmel: fix fractional baud rate computation
...
Here are the "big" driver core patches for 4.9-rc1. Also in here are a
number of debugfs fixes that cropped up due to the changes that happened
in 4.8 for that filesystem. Overall, nothing major, just a few fixes
and cleanups.
All of these have been in linux-next with no reported issues.
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
-----BEGIN PGP SIGNATURE-----
iFYEABECABYFAlfyNw4PHGdyZWdAa3JvYWguY29tAAoJEDFH1A3bLfspLVYAoNXr
FXBHGb2tNT/1PLfvUCwd5PqWAJ9Khb5WAHtvjTmEN1zabz45aSbcrA==
=Uz6V
-----END PGP SIGNATURE-----
Merge tag 'driver-core-4.9-rc1' of git://git.kernel.org/pub/scm/linux/kernel/git/gregkh/driver-core
Pull driver core updates from Greg KH:
"Here are the "big" driver core patches for 4.9-rc1. Also in here are a
number of debugfs fixes that cropped up due to the changes that
happened in 4.8 for that filesystem. Overall, nothing major, just a
few fixes and cleanups.
All of these have been in linux-next with no reported issues"
* tag 'driver-core-4.9-rc1' of git://git.kernel.org/pub/scm/linux/kernel/git/gregkh/driver-core: (23 commits)
drivers: dma-coherent: Move spinlock in dma_alloc_from_coherent()
drivers: dma-coherent: Fix DMA coherent size for less than page
MAINTAINERS: extend firmware_class maintainer list
debugfs: propagate release() call result
driver-core: platform: Catch errors from calls to irq_get_irq_data
sysfs print name of undiscoverable attribute group
carl9170: fix debugfs crashes
b43legacy: fix debugfs crash
b43: fix debugfs crash
debugfs: introduce a public file_operations accessor
device core: Remove deprecated create_singlethread_workqueue
drivers/base dmam_declare_coherent_memory leaks
platform: don't return 0 from platform_get_irq[_byname]() on error
cpu: clean up register_cpu func
dma-mapping: use vma_pages().
drivers: dma-coherent: use vma_pages().
attribute_container: Fix typo
base: soc: make it explicitly non-modular
drivers: base: dma-mapping: page align the size when unmap_kernel_range
platform driver: fix use-after-free in platform_device_del()
...
Here's the "big" char and misc driver update for 4.9-rc1.
Lots of little things here, all over the driver tree for subsystems that
flow through me. Nothing major that I can discern, full details are in
the shortlog.
All have been in the linux-next tree with no reported issues.
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
-----BEGIN PGP SIGNATURE-----
iFUEABECABYFAlfyOIQPHGdyZWdAa3JvYWguY29tAAoJEDFH1A3bLfsp9OQAlRy3
gSKfQUlXjTs96Bx/I5PtWysAn0r8nyKZoP1oSgsTddOCEeXngTXc
=4uPs
-----END PGP SIGNATURE-----
Merge tag 'char-misc-4.9-rc1' of git://git.kernel.org/pub/scm/linux/kernel/git/gregkh/char-misc
Pull char/misc driver updates from Greg KH:
"Here's the "big" char and misc driver update for 4.9-rc1.
Lots of little things here, all over the driver tree for subsystems
that flow through me. Nothing major that I can discern, full details
are in the shortlog.
All have been in the linux-next tree with no reported issues"
* tag 'char-misc-4.9-rc1' of git://git.kernel.org/pub/scm/linux/kernel/git/gregkh/char-misc: (144 commits)
drivers/misc/hpilo: Changes to support new security states in iLO5 FW
at25: fix debug and error messaging
misc/genwqe: ensure zero initialization
vme: fake: remove unexpected unlock in fake_master_set()
vme: fake: mark symbols static where possible
spmi: pmic-arb: Return an error code if sanity check fails
Drivers: hv: get rid of id in struct vmbus_channel
Drivers: hv: make VMBus bus ids persistent
mcb: Add a dma_device to mcb_device
mcb: Enable PCI bus mastering by default
mei: stop the stall timer worker if not needed
clk: probe common clock drivers earlier
vme: fake: fix build for 64-bit dma_addr_t
ttyprintk: Neaten and simplify printing
mei: me: add kaby point device ids
coresight: tmc: mark symbols static where possible
coresight: perf: deal with error condition properly
Drivers: hv: hv_util: Avoid dynamic allocation in time synch
fpga manager: Add hardware dependency to Zynq driver
Drivers: hv: utils: Support TimeSync version 4.0 protocol samples.
...
Pull CPU hotplug updates from Thomas Gleixner:
"Yet another batch of cpu hotplug core updates and conversions:
- Provide core infrastructure for multi instance drivers so the
drivers do not have to keep custom lists.
- Convert custom lists to the new infrastructure. The block-mq custom
list conversion comes through the block tree and makes the diffstat
tip over to more lines removed than added.
- Handle unbalanced hotplug enable/disable calls more gracefully.
- Remove the obsolete CPU_STARTING/DYING notifier support.
- Convert another batch of notifier users.
The relayfs changes which conflicted with the conversion have been
shipped to me by Andrew.
The remaining lot is targeted for 4.10 so that we finally can remove
the rest of the notifiers"
* 'smp-hotplug-for-linus' of git://git.kernel.org/pub/scm/linux/kernel/git/tip/tip: (46 commits)
cpufreq: Fix up conversion to hotplug state machine
blk/mq: Reserve hotplug states for block multiqueue
x86/apic/uv: Convert to hotplug state machine
s390/mm/pfault: Convert to hotplug state machine
mips/loongson/smp: Convert to hotplug state machine
mips/octeon/smp: Convert to hotplug state machine
fault-injection/cpu: Convert to hotplug state machine
padata: Convert to hotplug state machine
cpufreq: Convert to hotplug state machine
ACPI/processor: Convert to hotplug state machine
virtio scsi: Convert to hotplug state machine
oprofile/timer: Convert to hotplug state machine
block/softirq: Convert to hotplug state machine
lib/irq_poll: Convert to hotplug state machine
x86/microcode: Convert to hotplug state machine
sh/SH-X3 SMP: Convert to hotplug state machine
ia64/mca: Convert to hotplug state machine
ARM/OMAP/wakeupgen: Convert to hotplug state machine
ARM/shmobile: Convert to hotplug state machine
arm64/FP/SIMD: Convert to hotplug state machine
...
Pull irq updates from Thomas Gleixner:
"The irq departement proudly presents:
- A rework of the core infrastructure to optimally spread interrupt
for multiqueue devices. The first version was a bit naive and
failed to take thread siblings and other details into account.
Developed in cooperation with Christoph and Keith.
- Proper delegation of softirqs to ksoftirqd, so if ksoftirqd is
active then no further softirq processsing on interrupt return
happens. Otherwise we try to delegate and still run another batch
of network packets in the irq return path, which then tries to
delegate to ksoftirqd .....
- A proper machine parseable sysfs based alternative for
/proc/interrupts.
- ACPI support for the GICV3-ITS and ARM interrupt remapping
- Two new irq chips from the ARM SoC zoo: STM32-EXTI and MVEBU-PIC
- A new irq chip for the JCore (SuperH)
- The usual pile of small fixlets in core and irqchip drivers"
* 'irq-core-for-linus' of git://git.kernel.org/pub/scm/linux/kernel/git/tip/tip: (42 commits)
softirq: Let ksoftirqd do its job
genirq: Make function __irq_do_set_handler() static
ARM/dts: Add EXTI controller node to stm32f429
ARM/STM32: Select external interrupts controller
drivers/irqchip: Add STM32 external interrupts support
Documentation/dt-bindings: Document STM32 EXTI controller bindings
irqchip/mips-gic: Use for_each_set_bit to iterate over local IRQs
pci/msi: Retrieve affinity for a vector
genirq/affinity: Remove old irq spread infrastructure
genirq/msi: Switch to new irq spreading infrastructure
genirq/affinity: Provide smarter irq spreading infrastructure
genirq/msi: Add cpumask allocation to alloc_msi_entry
genirq: Expose interrupt information through sysfs
irqchip/gicv3-its: Use MADT ITS subtable to do PCI/MSI domain initialization
irqchip/gicv3-its: Factor out PCI-MSI part that might be reused for ACPI
irqchip/gicv3-its: Probe ITS in the ACPI way
irqchip/gicv3-its: Refactor ITS DT init code to prepare for ACPI
irqchip/gicv3-its: Cleanup for ITS domain initialization
PCI/MSI: Setup MSI domain on a per-device basis using IORT ACPI table
ACPI: Add new IORT functions to support MSI domain handling
...
Pull timer updates from Thomas Gleixner:
"A rather smalish set of updates for timers and timekeeping:
- Two core fixes to prevent potential undefinded behaviour about
which gcc is complaining rightfully.
- A fix to prevent stopping the tick on an (soon) offline CPU so it
can complete the shutdown procedure.
- Wait for clocks to stabilize before making decisions, so a not yet
validated clock is not rejected.
- The usual pile of fixes to the various clocksource drivers.
- Core code typo and include fixlets"
* 'timers-core-for-linus' of git://git.kernel.org/pub/scm/linux/kernel/git/tip/tip:
timekeeping: Include the correct header for errno definitions
clocksource/drivers/ti-32k: Prevent ftrace recursion
clocksource/mips-gic-timer: Stop checking cpu_has_counter
clocksource/mips-gic-timer: Print an error if IRQ setup fails
tick/nohz: Prevent stopping the tick on an offline CPU
clocksource/drivers/oxnas: Add OX820 compatible
clocksource/drivers/timer-atmel-pit: Simplify IRQ handler
clocksource/drivers/timer-atmel-pit: Remove uselesss WARN_ON_ONCE
clocksource/drivers/timer-atmel-pit: Drop at91sam926x_pit_common_init
clocksource/drivers/moxart: Replace panic by pr_err
clocksource/drivers/moxart: Replace setup_irq by request_irq
clocksource/drivers/moxart: Add Aspeed support
clocksource/drivers/moxart: Use struct to hold state
clocksource/drivers/moxart: Refactor enable/disable
time: Avoid undefined behaviour in ktime_add_safe()
time: Avoid undefined behaviour in timespec64_add_safe()
timekeeping: Prints the amounts of time spent during suspend
clocksource: Defer override invalidation unless clock is unstable
hrtimer: Spelling fixes
since pipe_lock is the outermost now, we don't need to drop/regain
socket locks around the call of splice_to_pipe() from skb_splice_bits(),
which kills the need to have a socket-specific callback; we can just
call splice_to_pipe() and be done with that.
Signed-off-by: Al Viro <viro@zeniv.linux.org.uk>
single-buffer analogue of splice_to_pipe(); vmsplice_to_pipe() switched
to that, leaving splice_to_pipe() only for ->splice_read() instances
(and that only until they are converted as well).
Signed-off-by: Al Viro <viro@zeniv.linux.org.uk>
Pull x86 vdso updates from Ingo Molnar:
"The main changes in this cycle centered around adding support for
32-bit compatible C/R of the vDSO on 64-bit kernels, by Dmitry
Safonov"
* 'x86-vdso-for-linus' of git://git.kernel.org/pub/scm/linux/kernel/git/tip/tip:
x86/vdso: Use CONFIG_X86_X32_ABI to enable vdso prctl
x86/vdso: Only define map_vdso_randomized() if CONFIG_X86_64
x86/vdso: Only define prctl_map_vdso() if CONFIG_CHECKPOINT_RESTORE
x86/signal: Add SA_{X32,IA32}_ABI sa_flags
x86/ptrace: Down with test_thread_flag(TIF_IA32)
x86/coredump: Use pr_reg size, rather that TIF_IA32 flag
x86/arch_prctl/vdso: Add ARCH_MAP_VDSO_*
x86/vdso: Replace calculate_addr in map_vdso() with addr
x86/vdso: Unmap vdso blob on vvar mapping failure
Pull low-level x86 updates from Ingo Molnar:
"In this cycle this topic tree has become one of those 'super topics'
that accumulated a lot of changes:
- Add CONFIG_VMAP_STACK=y support to the core kernel and enable it on
x86 - preceded by an array of changes. v4.8 saw preparatory changes
in this area already - this is the rest of the work. Includes the
thread stack caching performance optimization. (Andy Lutomirski)
- switch_to() cleanups and all around enhancements. (Brian Gerst)
- A large number of dumpstack infrastructure enhancements and an
unwinder abstraction. The secret long term plan is safe(r) live
patching plus maybe another attempt at debuginfo based unwinding -
but all these current bits are standalone enhancements in a frame
pointer based debug environment as well. (Josh Poimboeuf)
- More __ro_after_init and const annotations. (Kees Cook)
- Enable KASLR for the vmemmap memory region. (Thomas Garnier)"
[ The virtually mapped stack changes are pretty fundamental, and not
x86-specific per se, even if they are only used on x86 right now. ]
* 'x86-asm-for-linus' of git://git.kernel.org/pub/scm/linux/kernel/git/tip/tip: (70 commits)
x86/asm: Get rid of __read_cr4_safe()
thread_info: Use unsigned long for flags
x86/alternatives: Add stack frame dependency to alternative_call_2()
x86/dumpstack: Fix show_stack() task pointer regression
x86/dumpstack: Remove dump_trace() and related callbacks
x86/dumpstack: Convert show_trace_log_lvl() to use the new unwinder
oprofile/x86: Convert x86_backtrace() to use the new unwinder
x86/stacktrace: Convert save_stack_trace_*() to use the new unwinder
perf/x86: Convert perf_callchain_kernel() to use the new unwinder
x86/unwind: Add new unwind interface and implementations
x86/dumpstack: Remove NULL task pointer convention
fork: Optimize task creation by caching two thread stacks per CPU if CONFIG_VMAP_STACK=y
sched/core: Free the stack early if CONFIG_THREAD_INFO_IN_TASK
lib/syscall: Pin the task stack in collect_syscall()
x86/process: Pin the target stack in get_wchan()
x86/dumpstack: Pin the target stack when dumping it
kthread: Pin the stack via try_get_task_stack()/put_task_stack() in to_live_kthread() function
sched/core: Add try_get_task_stack() and put_task_stack()
x86/entry/64: Fix a minor comment rebase error
iommu/amd: Don't put completion-wait semaphore on stack
...
Pull x86 apic updates from Ingo Molnar:
"The main changes are:
- Persistent CPU/node numbering across CPU hotplug/unplug events.
This is a pretty involved series of changes that first fetches all
the information during bootup and then uses it for the various
hotplug/unplug methods. (Gu Zheng, Dou Liyang)
- IO-APIC hot-add/remove fixes and enhancements. (Rui Wang)
- ... various fixes, cleanups and enhancements"
* 'x86-apic-for-linus' of git://git.kernel.org/pub/scm/linux/kernel/git/tip/tip: (22 commits)
x86/apic: Fix silent & fatal merge conflict in __generic_processor_info()
acpi: Fix broken error check in map_processor()
acpi: Validate processor id when mapping the processor
acpi: Provide mechanism to validate processors in the ACPI tables
x86/acpi: Set persistent cpuid <-> nodeid mapping when booting
x86/acpi: Enable MADT APIs to return disabled apicids
x86/acpi: Introduce persistent storage for cpuid <-> apicid mapping
x86/acpi: Enable acpi to register all possible cpus at boot time
x86/numa: Online memory-less nodes at boot time
x86/apic: Get rid of apic_version[] array
x86/apic: Order irq_enter/exit() calls correctly vs. ack_APIC_irq()
x86/ioapic: Ignore root bridges without a companion ACPI device
x86/apic: Update comment about disabling processor focus
x86/smpboot: Check APIC ID before setting up default routing
x86/ioapic: Fix IOAPIC failing to request resource
x86/ioapic: Fix lost IOAPIC resource after hot-removal and hotadd
x86/ioapic: Fix setup_res() failing to get resource
x86/ioapic: Support hot-removal of IOAPICs present during boot
x86/ioapic: Change prototype of acpi_ioapic_add()
x86/apic, ACPI: Fix incorrect assignment when handling apic/x2apic entries
...
of_gpiochip_add() and of_gpiochip_remove() are only used locally
in the gpio subsystem so move these functions to the local
header.
Signed-off-by: Linus Walleij <linus.walleij@linaro.org>
Pull RAS updates from Ingo Molnar:
"The main changes were:
- Lots of enhancements for AMD SMCA (Scalable MCA
features/extensions) systems: extract, decode and print more
hardware error information and add matching support on the
injection/testing side as well. (Yazn Ghannam)
- Various MCE handling improvements on modern Intel Xeons. (Tony
Luck)
- Plus misc fixes and enhancements"
* 'ras-core-for-linus' of git://git.kernel.org/pub/scm/linux/kernel/git/tip/tip: (21 commits)
x86/RAS/mce_amd_inj: Remove debugfs dir recursively on exit
x86/RAS/mce_amd_inj: Fix signed wrap around when decrementing index 'i'
x86/RAS/mce_amd_inj: Fix some W= warnings
x86/MCE/AMD, EDAC: Handle reserved bank 4 on Fam17h properly
x86/mce/AMD: Extract the error address on SMCA systems
x86/mce, EDAC/mce_amd: Print MCA_SYND and MCA_IPID during MCE on SMCA systems
x86/mce/AMD: Save MCA_IPID in MCE struct on SMCA systems
x86/mce/AMD: Ensure the deferred error interrupt is of type APIC on SMCA systems
x86/mce/AMD: Update sysfs bank names for SMCA systems
x86/mce/AMD, EDAC/mce_amd: Define and use tables for known SMCA IP types
EDAC/mce_amd: Use SMCA prefix for error descriptions arrays
EDAC/mce_amd: Add missing SMCA error descriptions
x86/mce/AMD: Read MSRs on the CPU allocating the threshold blocks
x86/RAS: Add syndrome support to mce_amd_inj
EDAC/mce_amd: Print syndrome register value on SMCA systems
x86/mce: Add support for new MCA_SYND register
x86/mce/AMD: Use msr_ops.misc() in allocate_threshold_blocks()
x86/mce: Drop X86_FEATURE_MCE_RECOVERY and the related model string test
x86/mce: Improve memcpy_mcsafe()
x86/mce: Add PCI quirks to identify Xeons with machine check recovery
...
Pull perf updates from Ingo Molnar:
"The main kernel side changes were:
- uprobes enhancements (Masami Hiramatsu)
- Uncore group events enhancements (David Carrillo-Cisneros)
- x86 Intel: Add support for Skylake server uncore PMUs (Kan Liang)
- x86 Intel: LBR cleanups and enhancements, for better branch
annotation tracking (Peter Zijlstra)
- x86 Intel: Add support for PTWRITE and power event tracing
(Alexander Shishkin)
- ... various fixes, cleanups and smaller enhancements.
Lots of tooling changes - a couple of highlights:
- Support event group view with hierarchy mode in 'perf top' and
'perf report' (Namhyung Kim)
e.g.:
$ perf record -e '{cycles,instructions}' make
$ perf report --hierarchy --stdio
...
# Overhead Command / Shared Object / Symbol
# ...................... ..................................
...
25.74% 27.18%sh
19.96% 24.14%libc-2.24.so
9.55% 14.64%[.] __strcmp_sse2
1.54% 0.00%[.] __tfind
1.07% 1.13%[.] _int_malloc
0.95% 0.00%[.] __strchr_sse2
0.89% 1.39%[.] __tsearch
0.76% 0.00%[.] strlen
- Add branch stack / basic block info to 'perf annotate --stdio',
where for each branch, we add an asm comment after the instruction
with information on how often it was taken and predicted. See
example with color output at:
http://vger.kernel.org/~acme/perf/annotate_basic_blocks.png
(Peter Zijlstra)
- Add support for using symbols in address filters with Intel PT and
ARM CoreSight (hardware assisted tracing facilities) (Adrian
Hunter, Mathieu Poirier)
- Add support for interacting with Coresight PMU ETMs/PTMs, that are
IP blocks to perform hardware assisted tracing on a ARM CPU core
(Mathieu Poirier)
- Support generating cross arch probes, i.e. if you specify a vmlinux
file for different arch than the one in the host machine,
$ perf probe --definition function_name args
will generate the probe definition string needed to append to the
target machine /sys/kernel/debug/tracing/kprobes_events file, using
scripting (Masami Hiramatsu).
- Allow configuring the default 'perf report -s' sort order in
~/.perfconfig, for instance, "sym,dso" may be more fitting for
kernel developers. (Arnaldo Carvalho de Melo)
- ... plus lots of other changes, refactorings, features and fixes"
* 'perf-core-for-linus' of git://git.kernel.org/pub/scm/linux/kernel/git/tip/tip: (149 commits)
perf tests: Add dwarf unwind test for powerpc
perf probe: Match linkage name with mangled name
perf probe: Fix to cut off incompatible chars from group name
perf probe: Skip if the function address is 0
perf probe: Ignore the error of finding inline instance
perf intel-pt: Fix decoding when there are address filters
perf intel-pt: Enable decoder to handle TIP.PGD with missing IP
perf intel-pt: Read address filter from AUXTRACE_INFO event
perf intel-pt: Record address filter in AUXTRACE_INFO event
perf intel-pt: Add a helper function for processing AUXTRACE_INFO
perf intel-pt: Fix missing error codes processing auxtrace_info
perf intel-pt: Add support for recording the max non-turbo ratio
perf intel-pt: Fix snapshot overlap detection decoder errors
perf probe: Increase debug level of SDT debug messages
perf record: Add support for using symbols in address filters
perf symbols: Add dso__last_symbol()
perf record: Fix error paths
perf record: Rename label 'out_symbol_exit'
perf script: Fix vanished idle symbols
perf evsel: Add support for address filters
...
Pull locking updates from Ingo Molnar:
"The main changes in this cycle were:
- rwsem micro-optimizations (Davidlohr Bueso)
- Improve the implementation and optimize the performance of
percpu-rwsems. (Peter Zijlstra.)
- Convert all lglock users to better facilities such as percpu-rwsems
or percpu-spinlocks and remove lglocks. (Peter Zijlstra)
- Remove the ticket (spin)lock implementation. (Peter Zijlstra)
- Korean translation of memory-barriers.txt and related fixes to the
English document. (SeongJae Park)
- misc fixes and cleanups"
* 'locking-core-for-linus' of git://git.kernel.org/pub/scm/linux/kernel/git/tip/tip: (24 commits)
x86/cmpxchg, locking/atomics: Remove superfluous definitions
x86, locking/spinlocks: Remove ticket (spin)lock implementation
locking/lglock: Remove lglock implementation
stop_machine: Remove stop_cpus_lock and lg_double_lock/unlock()
fs/locks: Use percpu_down_read_preempt_disable()
locking/percpu-rwsem: Add down_read_preempt_disable()
fs/locks: Replace lg_local with a per-cpu spinlock
fs/locks: Replace lg_global with a percpu-rwsem
locking/percpu-rwsem: Add DEFINE_STATIC_PERCPU_RWSEMand percpu_rwsem_assert_held()
locking/pv-qspinlock: Use cmpxchg_release() in __pv_queued_spin_unlock()
locking/rwsem, x86: Drop a bogus cc clobber
futex: Add some more function commentry
locking/hung_task: Show all locks
locking/rwsem: Scan the wait_list for readers only once
locking/rwsem: Remove a few useless comments
locking/rwsem: Return void in __rwsem_mark_wake()
locking, rcu, cgroup: Avoid synchronize_sched() in __cgroup_procs_write()
locking/Documentation: Add Korean translation
locking/Documentation: Fix a typo of example result
locking/Documentation: Fix wrong section reference
...
Pull EFI updates from Ingo Molnar:
"Main changes in this cycle were:
- Refactor the EFI memory map code into architecture neutral files
and allow drivers to permanently reserve EFI boot services regions
on x86, as well as ARM/arm64. (Matt Fleming)
- Add ARM support for the EFI ESRT driver. (Ard Biesheuvel)
- Make the EFI runtime services and efivar API interruptible by
swapping spinlocks for semaphores. (Sylvain Chouleur)
- Provide the EFI identity mapping for kexec which allows kexec to
work on SGI/UV platforms with requiring the "noefi" kernel command
line parameter. (Alex Thorlton)
- Add debugfs node to dump EFI page tables on arm64. (Ard Biesheuvel)
- Merge the EFI test driver being carried out of tree until now in
the FWTS project. (Ivan Hu)
- Expand the list of flags for classifying EFI regions as "RAM" on
arm64 so we align with the UEFI spec. (Ard Biesheuvel)
- Optimise out the EFI mixed mode if it's unsupported (CONFIG_X86_32)
or disabled (CONFIG_EFI_MIXED=n) and switch the early EFI boot
services function table for direct calls, alleviating us from
having to maintain the custom function table. (Lukas Wunner)
- Miscellaneous cleanups and fixes"
* 'efi-core-for-linus' of git://git.kernel.org/pub/scm/linux/kernel/git/tip/tip: (30 commits)
x86/efi: Round EFI memmap reservations to EFI_PAGE_SIZE
x86/efi: Allow invocation of arbitrary boot services
x86/efi: Optimize away setup_gop32/64 if unused
x86/efi: Use kmalloc_array() in efi_call_phys_prolog()
efi/arm64: Treat regions with WT/WC set but WB cleared as memory
efi: Add efi_test driver for exporting UEFI runtime service interfaces
x86/efi: Defer efi_esrt_init until after memblock_x86_fill
efi/arm64: Add debugfs node to dump UEFI runtime page tables
x86/efi: Remove unused find_bits() function
fs/efivarfs: Fix double kfree() in error path
x86/efi: Map in physical addresses in efi_map_region_fixed
lib/ucs2_string: Speed up ucs2_utf8size()
firmware-gsmi: Delete an unnecessary check before the function call "dma_pool_destroy"
x86/efi: Initialize status to ensure garbage is not returned on small size
efi: Replace runtime services spinlock with semaphore
efi: Don't use spinlocks for efi vars
efi: Use a file local lock for efivars
efi/arm*: esrt: Add missing call to efi_esrt_init()
efi/esrt: Use memremap not ioremap to access ESRT table in memory
x86/efi-bgrt: Use efi_mem_reserve() to avoid copying image data
...
Pull core SMP updates from Ingo Molnar:
"Two main change is generic vCPU pinning and physical CPU SMP-call
support, for Xen to be able to perform certain calls on specific
physical CPUs - by Juergen Gross"
* 'core-smp-for-linus' of git://git.kernel.org/pub/scm/linux/kernel/git/tip/tip:
smp: Allocate smp_call_on_cpu() workqueue on stack too
hwmon: Use smp_call_on_cpu() for dell-smm i8k
dcdbas: Make use of smp_call_on_cpu()
xen: Add xen_pin_vcpu() to support calling functions on a dedicated pCPU
smp: Add function to execute a function synchronously on a CPU
virt, sched: Add generic vCPU pinning support
xen: Sync xen header
Pull RCU updates from Ingo Molnar:
"The main changes in this cycle were:
- Expedited grace-period changes, most notably avoiding having user
threads drive expedited grace periods, using a workqueue instead.
- Miscellaneous fixes, including a performance fix for lists that was
sent with the lists modifications.
- CPU hotplug updates, most notably providing exact CPU-online
tracking for RCU. This will in turn allow removal of the checks
supporting RCU's prior heuristic that was based on the assumption
that CPUs would take no longer than one jiffy to come online.
- Torture-test updates.
- Documentation updates"
* 'core-rcu-for-linus' of git://git.kernel.org/pub/scm/linux/kernel/git/tip/tip: (22 commits)
list: Expand list_first_entry_or_null()
torture: TOROUT_STRING(): Insert a space between flag and message
rcuperf: Consistently insert space between flag and message
rcutorture: Print out barrier error as document says
torture: Add task state to writer-task stall printk()s
torture: Convert torture_shutdown() to hrtimer
rcutorture: Convert to hotplug state machine
cpu/hotplug: Get rid of CPU_STARTING reference
rcu: Provide exact CPU-online tracking for RCU
rcu: Avoid redundant quiescent-state chasing
rcu: Don't use modular infrastructure in non-modular code
sched: Make wake_up_nohz_cpu() handle CPUs going offline
rcu: Use rcu_gp_kthread_wake() to wake up grace period kthreads
rcu: Use RCU's online-CPU state for expedited IPI retry
rcu: Exclude RCU-offline CPUs from expedited grace periods
rcu: Make expedited RCU CPU stall warnings respond to controls
rcu: Stop disabling expedited RCU CPU stall warnings
rcu: Drive expedited grace periods from workqueue
rcu: Consolidate expedited grace period machinery
documentation: Record reason for rcu_head two-byte alignment
...
- Update of the ACPICA code in the kernel to upstream revision 20160831 with
the following major changes:
* New mechanism for GPE masking.
* Fixes for issues related to the LoadTable operator and table loading.
* Fixes for issues related to so-called module-level code (MLC), that is
AML that doesn't belong to any methods.
* Change of the return value of the _OSI method to reflect the Windows
behavior.
* GAS (Generic Address Structure) support fix related to 32-bit FADT
addresses.
* Elimination of unnecessary FADT version 2 support.
* ACPI tools fixes and cleanups.
From Bob Moore, Lv Zheng, and Jung-uk Kim.
- ACPI sysfs interface updates to fix GPE handling (on top of the new GPE
masking mechanism in ACPICA) and issues related to table loading (Lv Zheng).
- New watchdog driver based on the ACPI WDAT (ACPI Watchdog Action Table),
needed on some platforms to replace the iTCO watchdog that doesn't work there
and related updates of the intel_pmc_ipc, i2c/i801 and MFD/lcp_ich drivers
(Mika Westerberg).
- Driver core fix to prevent it from leaking secondary fwnode objects during
device removal (Lukas Wunner).
- New definitions of built-in properties for UART in ACPI-based x86 SoC drivers
and a 8250_dw driver quirk for the APM X-Gene SoC (Heikki Krogerus).
- New device ID for the Vulcan SPI controller and constification of local
strucures in the AMD SoC (APD) ACPI driver (Kamlakant Patel, Julia Lawall).
- Fix for a bug causing the allocation of PCI resorces to fail if
ACPI-enumerated child platform devices are registered below the PCI
devices in question (Mika Westerberg).
- Change of the default polarity for PCI legacy IRQs to high on systems
booting wth ACPI on platforms with a GIC interrupt controller model
fixing the discrepancy between the specification and HW behavior (Lorenzo
Pieralisi).
- Fixes for the handling of system suspend/resume in the ACPI EC driver and
update of that driver to make it cope with the cases when the EC device
defined in the ECDT has to be used throughout the entire system life cycle
(Lv Zheng).
- Update of the ACPI CPPC library to allow it to batch requests sent over the
PCC channel (to reduce overhead), to support the fixed functional hardware
(FFH) CPPC registers access type, to notify the mailbox framework about TX
completions when the interrupt flag is set for the PCC mailbox, and to
support HW-Reduced Communication Subspace type 2 (Ashwin Chaugule, Prashanth
Prakash, Srinivas Pandruvada, Hoan Tran).
- ACPI button driver fix and documentation update related to the handling of
laptop lids (Lv Zheng).
- ACPI battery driver initialization fix (Carlos Garnacho).
- ACPI GPIO enumeration documentation update (Mika Westerberg).
- Assorted updates of the core ACPI bus type code (Lukas Wunner, Lv Zheng).
- Assorted cleanups of the ACPI table parsing code and the x86-specific ACPI
code (Al Stone).
- Fixes for assorted ACPI-related issues found in linux-next (Wei Yongjun).
-----BEGIN PGP SIGNATURE-----
Version: GnuPG v2.0.22 (GNU/Linux)
iQIcBAABCAAGBQJX8Y5+AAoJEILEb/54YlRx73oP/RiAi86NKjOj+GfYceVe37jn
6lSqoMugjgTQHRYvYiQCjJ/BR0GzQZqUkz9TAu1Op14+rhTH3OhSfPizzJWCpVfA
G9l9ZRQNnsKNs14bbYmWtmWduh46dFLVFJqo+M/0H3ZMFZu6Adcb+1SBtXHUoQ6L
z69ngFxTu3yRvqS4cmm5h7SOx5W2uZZl8zViJW8jgyGhUBStG87gzR6wsYBldGCk
XFxcaGWBXRccWGAQLSwfs0psQccEooCqbpsDqaUdrK/mI0rsQr88f25ZxEE7Zw7H
bv3py1cgJBZRq36L7eBGQXjIE7YQey6qG2lug2zsUJWe+vzy2vHjHVJHuBXKKgv3
txOA6QZx63UgEyN3zFT7K5ek6uOnkKdeE+s+Laj+K/x4V2R6gbtgO011EVcXy+bI
NvqsO76tfPHpwrn5s1VVc5lcEBEPHKHb+WulHrqhSSU4ivk0gtJDeSI+c8xta6YT
XwSry5tozDLkG1uEZqkyY1XTlOUAHO8E6YcrlOv2z1+mG7L8OH/vCp1apzgexsZA
1683AH5cwKc3KaP+4QdKGdxY2BDxb7OTVh3cGy4kAYb6tqQ/vj7vlRiJvtaMBtFw
xJn3buuagwJzKtgebpA565opvyFAfUX/RNFlTP63aXAefSAgq6KLq70vKFxkIZto
H1LpUbmiEbuBml8CBGb1
=xDOQ
-----END PGP SIGNATURE-----
Merge tag 'acpi-4.9-rc1' of git://git.kernel.org/pub/scm/linux/kernel/git/rafael/linux-pm
Pull ACPI updates from Rafael Wysocki:
"First off, the ACPICA code in the kernel is updated to upstream
revision 20160831 that brings in a few bug fixes and cleanups. In
particular, it is possible to mask GPEs now (and the sysfs interface
for GPE control is fixed on top of that), problems related to the
table loading mechanism are fixed and all code related to FADT version
2 (which has never been part of the ACPI specification) is dropped.
On the new features front, there is a new watchdog driver based on the
ACPI WDAT (ACPI Watchdog Action Table), needed on some platforms to
replace the iTCO watchdog that doesn't work there, and some UART
devices get new definitions of built-in properties (to be accessed via
the generic device properties API).
Also, included is a fix for an ACPI-related PCI resorces allocation
issue and a few problems in the EC driver and in the button and
battery drivers are fixed.
In addition to that, the ACPI CPPC library is updated to make batching
of requests sent over the PCC channel possible (which reduces the PCC
usage overhead substantially in some cases) and to support functional
fixed hardware (FFH) type of CPPC registers access (which will allow
CPPC to be used on x86 too in the future).
As usual, there are some assorted fixes and cleanups too.
Specifics:
- Update of the ACPICA code in the kernel to upstream revision
20160831 with the following major changes:
* New mechanism for GPE masking.
* Fixes for issues related to the LoadTable operator and table
loading.
* Fixes for issues related to so-called module-level code (MLC),
that is AML that doesn't belong to any methods.
* Change of the return value of the _OSI method to reflect the
Windows behavior.
* GAS (Generic Address Structure) support fix related to 32-bit
FADT addresses.
* Elimination of unnecessary FADT version 2 support.
* ACPI tools fixes and cleanups.
From Bob Moore, Lv Zheng, and Jung-uk Kim.
- ACPI sysfs interface updates to fix GPE handling (on top of the new
GPE masking mechanism in ACPICA) and issues related to table
loading (Lv Zheng).
- New watchdog driver based on the ACPI WDAT (ACPI Watchdog Action
Table), needed on some platforms to replace the iTCO watchdog that
doesn't work there and related updates of the intel_pmc_ipc,
i2c/i801 and MFD/lcp_ich drivers (Mika Westerberg).
- Driver core fix to prevent it from leaking secondary fwnode objects
during device removal (Lukas Wunner).
- New definitions of built-in properties for UART in ACPI-based x86
SoC drivers and a 8250_dw driver quirk for the APM X-Gene SoC
(Heikki Krogerus).
- New device ID for the Vulcan SPI controller and constification of
local strucures in the AMD SoC (APD) ACPI driver (Kamlakant Patel,
Julia Lawall).
- Fix for a bug causing the allocation of PCI resorces to fail if
ACPI-enumerated child platform devices are registered below the PCI
devices in question (Mika Westerberg).
- Change of the default polarity for PCI legacy IRQs to high on
systems booting wth ACPI on platforms with a GIC interrupt
controller model fixing the discrepancy between the specification
and HW behavior (Lorenzo Pieralisi).
- Fixes for the handling of system suspend/resume in the ACPI EC
driver and update of that driver to make it cope with the cases
when the EC device defined in the ECDT has to be used throughout
the entire system life cycle (Lv Zheng).
- Update of the ACPI CPPC library to allow it to batch requests sent
over the PCC channel (to reduce overhead), to support the fixed
functional hardware (FFH) CPPC registers access type, to notify the
mailbox framework about TX completions when the interrupt flag is
set for the PCC mailbox, and to support HW-Reduced Communication
Subspace type 2 (Ashwin Chaugule, Prashanth Prakash, Srinivas
Pandruvada, Hoan Tran).
- ACPI button driver fix and documentation update related to the
handling of laptop lids (Lv Zheng).
- ACPI battery driver initialization fix (Carlos Garnacho).
- ACPI GPIO enumeration documentation update (Mika Westerberg).
- Assorted updates of the core ACPI bus type code (Lukas Wunner, Lv
Zheng).
- Assorted cleanups of the ACPI table parsing code and the
x86-specific ACPI code (Al Stone).
- Fixes for assorted ACPI-related issues found in linux-next (Wei
Yongjun)"
* tag 'acpi-4.9-rc1' of git://git.kernel.org/pub/scm/linux/kernel/git/rafael/linux-pm: (98 commits)
ACPI / documentation: Use recommended name in GPIO property names
watchdog: wdat_wdt: Fix warning for using 0 as NULL
watchdog: wdat_wdt: fix return value check in wdat_wdt_probe()
platform/x86: intel_pmc_ipc: Do not create iTCO watchdog when WDAT table exists
i2c: i801: Do not create iTCO watchdog when WDAT table exists
mfd: lpc_ich: Do not create iTCO watchdog when WDAT table exists
ACPI / bus: Adjust ACPI subsystem initialization for new table loading mode
ACPICA: Parser: Fix a regression in LoadTable support
ACPICA: Tables: Fix "UNLOAD" code path lock issues
ACPI / watchdog: Add support for WDAT hardware watchdog
ACPI / platform: Pay attention to parent device's resources
PCI: Add pci_find_resource()
ACPI / CPPC: Support PCC with interrupt flag
ACPI / sysfs: Update sysfs signature handling code
ACPI / sysfs: Fix an issue for LoadTable opcode
ACPICA: Tables: Fix a regression in acpi_tb_find_table()
ACPI / tables: Remove duplicated include from tables.c
ACPI / APD: constify local structures
x86: ACPI: make variable names clearer in acpi_parse_madt_lapic_entries()
x86: ACPI: remove extraneous white space after semicolon
...
- Add a mechanism for passing hints from the scheduler to cpufreq governors
via their utilization update callbacks and use it to introduce "IOwait
boosting" into the schedutil governor and intel_pstate that will make them
boost performance if the enqueued task was previously waiting on I/O
(Rafael Wysocki).
- Fix a schedutil governor problem that causes it to overestimate utilization
if SMT is in use (Steve Muckle).
- Update defconfigs trying to use the schedutil governor as a module which is
not possible any more (Javier Martinez Canillas).
- Update the intel_pstate's pstate_sample tracepoint to take "IOwait boosting"
into account (Srinivas Pandruvada).
- Fix a problem in the cpufreq core causing it to mishandle the initialization
of CPUs registered after the cpufreq driver (Viresh Kumar, Rafael Wysocki).
- Make the cpufreq-dt driver support per-policy governor tunables, clean it
up and update its Kconfig description (Viresh Kumar).
- Add support for more ARM platforms to the cpufreq-dt driver (Chanwoo Choi,
Dave Gerlach, Geert Uytterhoeven).
- Make the cpufreq CPPC driver report frequencies in KHz to avoid user space
compatiblility issues (Al Stone, Hoan Tran).
- Clean up a few cpufreq drivers (st, kirkwood, SCPI) a bit (Colin Ian King,
Markus Elfring).
- Constify some local structures in the intel_pstate driver (Julia Lawall).
- Add a Documentation/cpu-freq/ entry to MAINTAINERS (Jean Delvare).
- Add support for PM domain removal to the generic power domains (genpd)
framework, add new DT helper functions to it and make it always enable
debugfs support if available (Jon Hunter, Tomeu Vizoso).
- Clean up the generic power domains (genpd) framework and make it avoid
measuring power-on and power-off latencies during system-wide PM transitions
(Ulf Hansson).
- Add support for the RockChip DFI controller and the rk3399 DMC to the
devfreq framework (Lin Huang, Axel Lin, Arnd Bergmann).
- Add COMPILE_TEST to the devfreq framework (Krzysztof Kozlowski, Stephen
Rothwell).
- Fix a minor issue in the exynos-ppmu devfreq driver and fix up devfreq
Kconfig indentation style (Wei Yongjun, Jisheng Zhang).
- Fix the system suspend interface to make suspend-to-idle work if platform
suspend operations have not been registered (Sudeep Holla).
- Make it possible to use hibernation with PAGE_POISONING_ZERO enabled
(Anisse Astier).
- Increas the default timeout of the system suspend/resume watchdog and make it
depend on EXPERT (Chen Yu).
- Make the operating performance points (OPP) framework avoid using OPPs that
aren't supported by the platform and fix a build warning in it (Dave Gerlach,
Arnd Bergmann).
- Fix the ARM cpuidle driver's return value (Christophe Jaillet).
- Make the SmartReflex AVS (Adaptive Voltage Scaling) driver use more common
logging style (Joe Perches).
-----BEGIN PGP SIGNATURE-----
Version: GnuPG v2.0.22 (GNU/Linux)
iQIcBAABCAAGBQJX8Y32AAoJEILEb/54YlRx8e0P/27zu8Lb6Aks1S2Zx9GEW0qr
DvrO4kklCHqi3DgHlyFOYetf9cxMrUluojVJofnoSDvgAayWyg7VAd4gtOrMGCXG
pJVJM73itcOUK+DsAVvoWJY3hk15nX77n2aiXPN2GqaMqennlQusdfzTmjCasqpm
M84j+JwFYlJcfyMCcF5kGWqS7QBjzxhA0CjytUX1i3pL3NqRALZUEpaHwBD1W+4r
tcF/jYTy3RsghCbuC6HoPxEF9NMOFGxeAXogmu6NvGu8gy0GqtywRSRrs5wA1a0z
ZDAJ8krrFbzuFPMdjNIE8wtTeziofS5i9piQx3JlIMH3HpNGN86BRXVfzuHzJj11
6ZMUI/FJy+fYukIXOEeVLtsLHUnMcMux8Jq1UF6N0InahaR9nbsjmGOmXh72+Scx
7VJ+29l0oVwX6wkw/DjPP3rb1Swd1i3yY0/3uRoJ174mYTjhRGbrbDkIjPiDeuM5
2Cx7QunscOjFmaNtPyr8niQ+7YhMEpn8VIbGNaX5ABz0fGftfi8nDHqliSNa391Z
nK6YoKD0O6R0JHE6GavvJTcuMS9qE+HHHOwymWKxEdE9KYk0JUqen3gj1sSTaAZT
BIPBsn6XlorqNy3dnqtWTHV7Nf0al9huolWvrL90s6g4Bh2BzTzDVydSgNWTMDUi
G64nP0q1sJTqdoe30uvk
=NYkv
-----END PGP SIGNATURE-----
Merge tag 'pm-4.9-rc1' of git://git.kernel.org/pub/scm/linux/kernel/git/rafael/linux-pm
Pull power management updates from Rafael Wysocki:
"Traditionally, cpufreq is the area with the greatest number of
changes, but there are fewer of them than last time. There also is
some activity in the generic power domains and the devfreq frameworks,
a couple of system suspend and hibernation fixes and some assorted
changes in other places.
One new feature is the cpufreq change to allow the scheduler to pass
hints to the governors' utilization update callbacks and some code
rework based on that. Another one is the support for domain removal in
the generic power domains framework. Also it is now possible to use
hibernation with PAGE_POISONING_ZERO enabled and devfreq supports the
RockChip DFI controller and the rk3399 DMC.
The rest of the changes is mostly fixes and cleanups in a number of
places.
Specifics:
- Add a mechanism for passing hints from the scheduler to cpufreq
governors via their utilization update callbacks and use it to
introduce "IOwait boosting" into the schedutil governor and
intel_pstate that will make them boost performance if the enqueued
task was previously waiting on I/O (Rafael Wysocki).
- Fix a schedutil governor problem that causes it to overestimate
utilization if SMT is in use (Steve Muckle).
- Update defconfigs trying to use the schedutil governor as a module
which is not possible any more (Javier Martinez Canillas).
- Update the intel_pstate's pstate_sample tracepoint to take "IOwait
boosting" into account (Srinivas Pandruvada).
- Fix a problem in the cpufreq core causing it to mishandle the
initialization of CPUs registered after the cpufreq driver (Viresh
Kumar, Rafael Wysocki).
- Make the cpufreq-dt driver support per-policy governor tunables,
clean it up and update its Kconfig description (Viresh Kumar).
- Add support for more ARM platforms to the cpufreq-dt driver
(Chanwoo Choi, Dave Gerlach, Geert Uytterhoeven).
- Make the cpufreq CPPC driver report frequencies in KHz to avoid
user space compatiblility issues (Al Stone, Hoan Tran).
- Clean up a few cpufreq drivers (st, kirkwood, SCPI) a bit (Colin
Ian King, Markus Elfring).
- Constify some local structures in the intel_pstate driver (Julia
Lawall).
- Add a Documentation/cpu-freq/ entry to MAINTAINERS (Jean Delvare).
- Add support for PM domain removal to the generic power domains
(genpd) framework, add new DT helper functions to it and make it
always enable debugfs support if available (Jon Hunter, Tomeu
Vizoso).
- Clean up the generic power domains (genpd) framework and make it
avoid measuring power-on and power-off latencies during system-wide
PM transitions (Ulf Hansson).
- Add support for the RockChip DFI controller and the rk3399 DMC to
the devfreq framework (Lin Huang, Axel Lin, Arnd Bergmann).
- Add COMPILE_TEST to the devfreq framework (Krzysztof Kozlowski,
Stephen Rothwell).
- Fix a minor issue in the exynos-ppmu devfreq driver and fix up
devfreq Kconfig indentation style (Wei Yongjun, Jisheng Zhang).
- Fix the system suspend interface to make suspend-to-idle work if
platform suspend operations have not been registered (Sudeep
Holla).
- Make it possible to use hibernation with PAGE_POISONING_ZERO
enabled (Anisse Astier).
- Increas the default timeout of the system suspend/resume watchdog
and make it depend on EXPERT (Chen Yu).
- Make the operating performance points (OPP) framework avoid using
OPPs that aren't supported by the platform and fix a build warning
in it (Dave Gerlach, Arnd Bergmann).
- Fix the ARM cpuidle driver's return value (Christophe Jaillet).
- Make the SmartReflex AVS (Adaptive Voltage Scaling) driver use more
common logging style (Joe Perches)"
* tag 'pm-4.9-rc1' of git://git.kernel.org/pub/scm/linux/kernel/git/rafael/linux-pm: (58 commits)
PM / OPP: Don't support OPP if it provides supported-hw but platform does not
cpufreq: st: add missing \n to end of dev_err message
cpufreq: kirkwood: add missing \n to end of dev_err messages
PM / Domains: Rename pm_genpd_sync_poweron|poweroff()
PM / Domains: Don't measure latency of ->power_on|off() during system PM
PM / Domains: Remove redundant system PM callbacks
PM / Domains: Simplify detaching a device from its genpd
PM / devfreq: rk3399_dmc: Remove explictly regulator_put call in .remove
PM / devfreq: rockchip: add PM_DEVFREQ_EVENT dependency
PM / OPP: avoid maybe-uninitialized warning
PM / Domains: Allow holes in genpd_data.domains array
cpufreq: CPPC: Avoid overflow when calculating desired_perf
cpufreq: ti: Use generic platdev driver
cpufreq: intel_pstate: Add io_boost trace
partial revert of "PM / devfreq: Add COMPILE_TEST for build coverage"
cpufreq: intel_pstate: Use IOWAIT flag in Atom algorithm
cpufreq: schedutil: Add iowait boosting
cpufreq / sched: SCHED_CPUFREQ_IOWAIT flag to indicate iowait condition
PM / Domains: Add support for removing nested PM domains by provider
PM / Domains: Add support for removing PM domains
...
Add a new fallocate mode flag that explicitly unshares blocks on
filesystems that support such features. The new flag can only
be used with an allocate-mode fallocate call.
Signed-off-by: Darrick J. Wong <darrick.wong@oracle.com>
- Support for execute-only page permissions
- Support for hibernate and DEBUG_PAGEALLOC
- Support for heterogeneous systems with mismatches cache line sizes
- Errata workarounds (A53 843419 update and QorIQ A-008585 timer bug)
- arm64 PMU perf updates, including cpumasks for heterogeneous systems
- Set UTS_MACHINE for building rpm packages
- Yet another head.S tidy-up
- Some cleanups and refactoring, particularly in the NUMA code
- Lots of random, non-critical fixes across the board
-----BEGIN PGP SIGNATURE-----
Version: GnuPG v1
iQEcBAABCgAGBQJX7k31AAoJELescNyEwWM0XX0H/iOaWCfKlWOhvBsStGUCsLrK
XryTzQT2KjdnLKf3jwP+1ateCuBR5ROurYxoDCX5/7mD63c5KiI338Vbv61a1lE1
AAwjt1stmQVUg/j+kqnuQwB/0DYg+2C8se3D3q5Iyn7zc19cDZJEGcBHNrvLMufc
XgHrgHgl/rzBDDlHJXleknDFge/MfhU5/Q1vJMRRb4JYrpAtmIokzCO75CYMRcCT
ND2QbmppKtsyuFPGUTVbAFzJlP6dGKb3eruYta7/ct5d0pJQxav3u98D2yWGfjdM
YaYq1EmX5Pol7rWumqLtk0+mA9yCFcKLLc+PrJu20Vx0UkvOq8G8Xt70sHNvZU8=
=gdPM
-----END PGP SIGNATURE-----
Merge tag 'arm64-upstream' of git://git.kernel.org/pub/scm/linux/kernel/git/arm64/linux
Pull arm64 updates from Will Deacon:
"It's a bit all over the place this time with no "killer feature" to
speak of. Support for mismatched cache line sizes should help people
seeing whacky JIT failures on some SoCs, and the big.LITTLE perf
updates have been a long time coming, but a lot of the changes here
are cleanups.
We stray outside arch/arm64 in a few areas: the arch/arm/ arch_timer
workaround is acked by Russell, the DT/OF bits are acked by Rob, the
arch_timer clocksource changes acked by Marc, CPU hotplug by tglx and
jump_label by Peter (all CC'd).
Summary:
- Support for execute-only page permissions
- Support for hibernate and DEBUG_PAGEALLOC
- Support for heterogeneous systems with mismatches cache line sizes
- Errata workarounds (A53 843419 update and QorIQ A-008585 timer bug)
- arm64 PMU perf updates, including cpumasks for heterogeneous systems
- Set UTS_MACHINE for building rpm packages
- Yet another head.S tidy-up
- Some cleanups and refactoring, particularly in the NUMA code
- Lots of random, non-critical fixes across the board"
* tag 'arm64-upstream' of git://git.kernel.org/pub/scm/linux/kernel/git/arm64/linux: (100 commits)
arm64: tlbflush.h: add __tlbi() macro
arm64: Kconfig: remove SMP dependence for NUMA
arm64: Kconfig: select OF/ACPI_NUMA under NUMA config
arm64: fix dump_backtrace/unwind_frame with NULL tsk
arm/arm64: arch_timer: Use archdata to indicate vdso suitability
arm64: arch_timer: Work around QorIQ Erratum A-008585
arm64: arch_timer: Add device tree binding for A-008585 erratum
arm64: Correctly bounds check virt_addr_valid
arm64: migrate exception table users off module.h and onto extable.h
arm64: pmu: Hoist pmu platform device name
arm64: pmu: Probe default hw/cache counters
arm64: pmu: add fallback probe table
MAINTAINERS: Update ARM PMU PROFILING AND DEBUGGING entry
arm64: Improve kprobes test for atomic sequence
arm64/kvm: use alternative auto-nop
arm64: use alternative auto-nop
arm64: alternative: add auto-nop infrastructure
arm64: lse: convert lse alternatives NOP padding to use __nops
arm64: barriers: introduce nops and __nops macros for NOP sequences
arm64: sysreg: replace open-coded mrs_s/msr_s with {read,write}_sysreg_s
...
* pci/hotplug:
x86/PCI: VMD: Request userspace control of PCIe hotplug indicators
PCI: pciehp: Allow exclusive userspace control of indicators
PCI: pciehp: Remove useless pciehp_get_latch_status() calls
PCI: pciehp: Clean up dmesg "Slot(%s)" messages
PCI: pciehp: Remove unnecessary guard
PCI: pciehp: Don't re-read Slot Status when handling surprise event
PCI: pciehp: Don't re-read Slot Status when queuing hotplug event
PCI: pciehp: Process all hotplug events before looking for new ones
PCI: pciehp: Return IRQ_NONE when we can't read interrupt status
PCI: pciehp: Rename pcie_isr() locals for clarity
PCI: pciehp: Clear attention LED on device add
In order to be able to lock a rproc driver implementations only when
used by a client, we must differ between the dereference operation of a
client and the implementation itself.
This patch brings no functional change.
Signed-off-by: Bjorn Andersson <bjorn.andersson@linaro.org>
Pull networking fixes from David Miller:
1) Fix wrong TCP checksums on MTU probing when checksum offloading is
disabled, from Douglas Caetano dos Santos.
2) Fix qdisc backlog updates in qfq and sfb schedulers, from Cong Wang.
3) Route lookup flow key protocol value is wrong in ip6gre_xmit_other(),
fix from Lance Richardson.
4) Scheduling while atomic in multicast routing code of ipv4 and ipv6,
fix from Nikolay Aleksandrov.
5) Fix packet alignment in fec driver, from Eric Nelson.
6) Fix perf regression in sctp due to struct layout and cache misses,
from Xin Long.
* git://git.kernel.org/pub/scm/linux/kernel/git/davem/net:
sctp: fix the issue sctp_diag uses lock_sock in rcu_read_lock
sctp: change to check peer prsctp_capable when using prsctp polices
sctp: remove prsctp_param from sctp_chunk
sctp: move sent_count to the memory hole in sctp_chunk
tg3: Avoid NULL pointer dereference in tg3_io_error_detected()
act_ife: Fix false encoding
act_ife: Fix external mac header on encode
VSOCK: Don't dec ack backlog twice for rejected connections
Revert "net: ethernet: bcmgenet: use phydev from struct net_device"
net: fec: align IP header in hardware
net: fec: remove QUIRK_HAS_RACC from i.mx27
net: fec: remove QUIRK_HAS_RACC from i.mx25
ipmr, ip6mr: fix scheduling while atomic and a deadlock with ipmr_get_route
ip6_gre: fix flowi6_proto value in ip6gre_xmit_other()
tcp: fix a compile error in DBGUNDO()
tcp: fix wrong checksum calculation on MTU probing
sch_sfb: keep backlog updated with qlen
sch_qfq: keep backlog updated with qlen
can: dev: fix deadlock reported after bus-off
* pm-cpufreq: (24 commits)
cpufreq: st: add missing \n to end of dev_err message
cpufreq: kirkwood: add missing \n to end of dev_err messages
cpufreq: CPPC: Avoid overflow when calculating desired_perf
cpufreq: ti: Use generic platdev driver
cpufreq: intel_pstate: Add io_boost trace
cpufreq: intel_pstate: Use IOWAIT flag in Atom algorithm
cpufreq: schedutil: Add iowait boosting
cpufreq / sched: SCHED_CPUFREQ_IOWAIT flag to indicate iowait condition
cpufreq: CPPC: Force reporting values in KHz to fix user space interface
cpufreq: create link to policy only for registered CPUs
intel_pstate: constify local structures
cpufreq: dt: Support governor tunables per policy
cpufreq: dt: Update kconfig description
cpufreq: dt: Remove unused code
MAINTAINERS: Add Documentation/cpu-freq/
cpufreq: dt: Add support for r8a7792
cpufreq / sched: ignore SMT when determining max cpu capacity
cpufreq: Drop unnecessary check from cpufreq_policy_alloc()
ARM: multi_v7_defconfig: Don't attempt to enable schedutil governor as module
ARM: exynos_defconfig: Don't attempt to enable schedutil governor as module
...
* pm-domains:
PM / Domains: Rename pm_genpd_sync_poweron|poweroff()
PM / Domains: Don't measure latency of ->power_on|off() during system PM
PM / Domains: Remove redundant system PM callbacks
PM / Domains: Simplify detaching a device from its genpd
PM / Domains: Allow holes in genpd_data.domains array
PM / Domains: Add support for removing nested PM domains by provider
PM / Domains: Add support for removing PM domains
PM / Domains: Store the provider in the PM domain structure
PM / Domains: Prepare for adding support to remove PM domains
PM / Domains: Verify the PM domain is present when adding a provider
PM / Domains: Don't expose xlate and provider helper functions
PM / Domains: Don't expose generic_pm_domain structure to clients
staging: board: Remove calls to of_genpd_get_from_provider()
ARM: EXYNOS: Remove calls to of_genpd_get_from_provider()
PM / Domains: Add new helper functions for device-tree
PM / Domains: Always enable debugfs support if available
* acpi-wdat:
watchdog: wdat_wdt: Fix warning for using 0 as NULL
watchdog: wdat_wdt: fix return value check in wdat_wdt_probe()
platform/x86: intel_pmc_ipc: Do not create iTCO watchdog when WDAT table exists
i2c: i801: Do not create iTCO watchdog when WDAT table exists
mfd: lpc_ich: Do not create iTCO watchdog when WDAT table exists
ACPI / watchdog: Add support for WDAT hardware watchdog
* acpi-ec:
ACPI / EC: Fix issues related to boot_ec
ACPI / EC: Fix a gap that ECDT EC cannot handle EC events
ACPI / EC: Fix a memory leakage issue in acpi_ec_add()
ACPI / EC: Cleanup first_ec/boot_ec code
ACPI / EC: Enable event freeze mode to improve event handling for suspend process
ACPI / EC: Add PM operations to improve event handling for suspend process
ACPI / EC: Add PM operations to improve event handling for resume process
ACPI / EC: Fix an issue that SCI_EVT cannot be detected after event is enabled
ACPI / EC: Add EC_FLAGS_QUERY_ENABLED to reveal a hidden logic
ACPI / EC: Add PM operations for suspend/resume noirq stage
* acpi-sysfs:
ACPI / sysfs: Update sysfs signature handling code
ACPI / sysfs: Fix an issue for LoadTable opcode
ACPI / sysfs: Use new GPE masking mechanism in GPE interface
* acpi-pci:
ACPI / platform: Pay attention to parent device's resources
PCI: Add pci_find_resource()
ACPI / PCI: fix GIC irq model default PCI IRQ polarity
* acpi-tables:
ACPI / tables: Remove duplicated include from tables.c
ACPI / tables: do not report the number of entries ignored by acpi_parse_entries()
ACPI / tables: fix acpi_parse_entries_array() so it traverses all subtables
ACPI / tables: fix incorrect counts returned by acpi_parse_entries_array()
Before we add more libnvdimm-private fields to nd_mapping make it clear
which parameters are input vs libnvdimm internals. Use struct
nd_mapping_desc instead of struct nd_mapping in nd_region_desc and make
struct nd_mapping private to libnvdimm.
Signed-off-by: Dan Williams <dan.j.williams@intel.com>
nvdimm_clear_poison cleared the user-visible badblocks, and sent
commands to the NVDIMM to clear the areas marked as 'poison', but it
neglected to clear the same areas from the internal poison_list which is
used to marshal ARS results before sorting them by namespace. As a
result, once on-demand ARS functionality was added:
37b137f nfit, libnvdimm: allow an ARS scrub to be triggered on demand
A scrub triggered from either sysfs or an MCE was found to be adding
stale entries that had been cleared from gendisk->badblocks, but were
still present in nvdimm_bus->poison_list. Additionally, the stale entries
could be triggered into producing stale disk->badblocks by simply disabling
and re-enabling the namespace or region.
This adds the missing step of clearing poison_list entries when clearing
poison, so that it is always in sync with badblocks.
Fixes: 37b137f ("nfit, libnvdimm: allow an ARS scrub to be triggered on demand")
Signed-off-by: Vishal Verma <vishal.l.verma@intel.com>
Signed-off-by: Dan Williams <dan.j.williams@intel.com>
This fixes commit d76eebfa17 ("include/linux/property.h: fix build
issues with gcc-4.4.4").
With that commit we get the following compile error when using the
PROPERTY_ENTRY_INTEGER_ARRAY macro.
include/linux/property.h:201:39: error: `u32_data' undeclared (first
use in this function)
PROPERTY_ENTRY_INTEGER_ARRAY(_name_, u32, _val_)
^
include/linux/property.h:193:17: note: in definition of macro
`PROPERTY_ENTRY_INTEGER_ARRAY'
{ .pointer = { _type_##_data = _val_ } }, \
^
This needs a '.' to reference the union member. It seems this was just
overlooked here since it is done correctly in similar constructs in
other parts of the original commit.
This fix is in preparation of upcoming commits that will use this macro.
Fixes: commit d76eebfa17 ("include/linux/property.h: fix build issues with gcc-4.4.4")
Link: http://lkml.kernel.org/r/2de3b929290d88a723ed829a3e3cbd02044714df.1475114627.git.johnyoun@synopsys.com
Signed-off-by: John Youn <johnyoun@synopsys.com>
Cc: "Rafael J. Wysocki" <rafael.j.wysocki@intel.com>
Signed-off-by: Andrew Morton <akpm@linux-foundation.org>
Signed-off-by: Linus Torvalds <torvalds@linux-foundation.org>
Antonio reports the following crash when using fuse under memory pressure:
kernel BUG at /build/linux-a2WvEb/linux-4.4.0/mm/workingset.c:346!
invalid opcode: 0000 [#1] SMP
Modules linked in: all of them
CPU: 2 PID: 63 Comm: kswapd0 Not tainted 4.4.0-36-generic #55-Ubuntu
Hardware name: System manufacturer System Product Name/P8H67-M PRO, BIOS 3904 04/27/2013
task: ffff88040cae6040 ti: ffff880407488000 task.ti: ffff880407488000
RIP: shadow_lru_isolate+0x181/0x190
Call Trace:
__list_lru_walk_one.isra.3+0x8f/0x130
list_lru_walk_one+0x23/0x30
scan_shadow_nodes+0x34/0x50
shrink_slab.part.40+0x1ed/0x3d0
shrink_zone+0x2ca/0x2e0
kswapd+0x51e/0x990
kthread+0xd8/0xf0
ret_from_fork+0x3f/0x70
which corresponds to the following sanity check in the shadow node
tracking:
BUG_ON(node->count & RADIX_TREE_COUNT_MASK);
The workingset code tracks radix tree nodes that exclusively contain
shadow entries of evicted pages in them, and this (somewhat obscure)
line checks whether there are real pages left that would interfere with
reclaim of the radix tree node under memory pressure.
While discussing ways how fuse might sneak pages into the radix tree
past the workingset code, Miklos pointed to replace_page_cache_page(),
and indeed there is a problem there: it properly accounts for the old
page being removed - __delete_from_page_cache() does that - but then
does a raw raw radix_tree_insert(), not accounting for the replacement
page. Eventually the page count bits in node->count underflow while
leaving the node incorrectly linked to the shadow node LRU.
To address this, make sure replace_page_cache_page() uses the tracked
page insertion code, page_cache_tree_insert(). This fixes the page
accounting and makes sure page-containing nodes are properly unlinked
from the shadow node LRU again.
Also, make the sanity checks a bit less obscure by using the helpers for
checking the number of pages and shadows in a radix tree node.
Fixes: 449dd6984d ("mm: keep page cache radix tree nodes in check")
Link: http://lkml.kernel.org/r/20160919155822.29498-1-hannes@cmpxchg.org
Signed-off-by: Johannes Weiner <hannes@cmpxchg.org>
Reported-by: Antonio SJ Musumeci <trapexit@spawn.link>
Debugged-by: Miklos Szeredi <miklos@szeredi.hu>
Cc: <stable@vger.kernel.org> [3.15+]
Signed-off-by: Andrew Morton <akpm@linux-foundation.org>
Signed-off-by: Linus Torvalds <torvalds@linux-foundation.org>
Currently, a single hash algorithm is used to hash the auth_cred for
the credcache for all rpc_auth types. Add a hash_cred() function to
the rpc_authops struct to allow a hash function specific to each
auth flavor.
Signed-off-by: Frank Sorenson <sorenson@redhat.com>
Signed-off-by: Anna Schumaker <Anna.Schumaker@Netapp.com>
CAI Qian <caiqian@redhat.com> pointed out that the semantics
of shared subtrees make it possible to create an exponentially
increasing number of mounts in a mount namespace.
mkdir /tmp/1 /tmp/2
mount --make-rshared /
for i in $(seq 1 20) ; do mount --bind /tmp/1 /tmp/2 ; done
Will create create 2^20 or 1048576 mounts, which is a practical problem
as some people have managed to hit this by accident.
As such CVE-2016-6213 was assigned.
Ian Kent <raven@themaw.net> described the situation for autofs users
as follows:
> The number of mounts for direct mount maps is usually not very large because of
> the way they are implemented, large direct mount maps can have performance
> problems. There can be anywhere from a few (likely case a few hundred) to less
> than 10000, plus mounts that have been triggered and not yet expired.
>
> Indirect mounts have one autofs mount at the root plus the number of mounts that
> have been triggered and not yet expired.
>
> The number of autofs indirect map entries can range from a few to the common
> case of several thousand and in rare cases up to between 30000 and 50000. I've
> not heard of people with maps larger than 50000 entries.
>
> The larger the number of map entries the greater the possibility for a large
> number of active mounts so it's not hard to expect cases of a 1000 or somewhat
> more active mounts.
So I am setting the default number of mounts allowed per mount
namespace at 100,000. This is more than enough for any use case I
know of, but small enough to quickly stop an exponential increase
in mounts. Which should be perfect to catch misconfigurations and
malfunctioning programs.
For anyone who needs a higher limit this can be changed by writing
to the new /proc/sys/fs/mount-max sysctl.
Tested-by: CAI Qian <caiqian@redhat.com>
Signed-off-by: "Eric W. Biederman" <ebiederm@xmission.com>
Previously, we used cp_version only to detect recoverable dnodes.
In order to avoid same garbage cp_version, we needed to truncate the next
dnode during checkpoint, resulting in additional discard or data write.
If we can distinguish this by using crc in addition to cp_version, we can
remove this overhead.
There is backward compatibility concern where it changes node_footer layout.
So, this patch introduces a new checkpoint flag, CP_CRC_RECOVERY_FLAG, to
detect new layout. New layout will be activated only when this flag is set.
Signed-off-by: Jaegeuk Kim <jaegeuk@kernel.org>
Install the callbacks via the state machine.
Signed-off-by: Sebastian Andrzej Siewior <bigeasy@linutronix.de>
Signed-off-by: Boris Ostrovsky <boris.ostrovsky@oracle.com>
Signed-off-by: David Vrabel <david.vrabel@citrix.com>
Switch to new CPU hotplug infrastructure.
Signed-off-by: Boris Ostrovsky <boris.ostrovsky@oracle.com>
Suggested-by: Sebastian Andrzej Siewior <bigeasy@linutronix.de>
Signed-off-by: David Vrabel <david.vrabel@citrix.com>
Introduce light versions of u64_stats helpers for context where
either preempt or IRQs are disabled. This way we can make this library
usable by scheduler irqtime accounting which currenty implement its
ad-hoc version.
Signed-off-by: Frederic Weisbecker <fweisbec@gmail.com>
Cc: Eric Dumazet <eric.dumazet@gmail.com>
Cc: Linus Torvalds <torvalds@linux-foundation.org>
Cc: Mike Galbraith <efault@gmx.de>
Cc: Paolo Bonzini <pbonzini@redhat.com>
Cc: Peter Zijlstra <peterz@infradead.org>
Cc: Rik van Riel <riel@redhat.com>
Cc: Thomas Gleixner <tglx@linutronix.de>
Cc: Wanpeng Li <wanpeng.li@hotmail.com>
Link: http://lkml.kernel.org/r/1474849761-12678-4-git-send-email-fweisbec@gmail.com
Signed-off-by: Ingo Molnar <mingo@kernel.org>
Rename the ia64 only set_curr_task() function to free up the name.
Signed-off-by: Peter Zijlstra (Intel) <peterz@infradead.org>
Cc: Linus Torvalds <torvalds@linux-foundation.org>
Cc: Mike Galbraith <efault@gmx.de>
Cc: Peter Zijlstra <peterz@infradead.org>
Cc: Thomas Gleixner <tglx@linutronix.de>
Cc: Tony Luck <tony.luck@intel.com>
Cc: linux-kernel@vger.kernel.org
Signed-off-by: Ingo Molnar <mingo@kernel.org>
select_idle_siblings() is a known pain point for a number of
workloads; it either does too much or not enough and sometimes just
does plain wrong.
This rewrite attempts to address a number of issues (but sadly not
all).
The current code does an unconditional sched_domain iteration; with
the intent of finding an idle core (on SMT hardware). The problems
which this patch tries to address are:
- its pointless to look for idle cores if the machine is real busy;
at which point you're just wasting cycles.
- it's behaviour is inconsistent between SMT and !SMT hardware in
that !SMT hardware ends up doing a scan for any idle CPU in the LLC
domain, while SMT hardware does a scan for idle cores and if that
fails, falls back to a scan for idle threads on the 'target' core.
The new code replaces the sched_domain scan with 3 explicit scans:
1) search for an idle core in the LLC
2) search for an idle CPU in the LLC
3) search for an idle thread in the 'target' core
where 1 and 3 are conditional on SMT support and 1 and 2 have runtime
heuristics to skip the step.
Step 1) is conditional on sd_llc_shared->has_idle_cores; when a cpu
goes idle and sd_llc_shared->has_idle_cores is false, we scan all SMT
siblings of the CPU going idle. Similarly, we clear
sd_llc_shared->has_idle_cores when we fail to find an idle core.
Step 2) tracks the average cost of the scan and compares this to the
average idle time guestimate for the CPU doing the wakeup. There is a
significant fudge factor involved to deal with the variability of the
averages. Esp. hackbench was sensitive to this.
Step 3) is unconditional; we assume (also per step 1) that scanning
all SMT siblings in a core is 'cheap'.
With this; SMT systems gain step 2, which cures a few benchmarks --
notably one from Facebook.
One 'feature' of the sched_domain iteration, which we preserve in the
new code, is that it would start scanning from the 'target' CPU,
instead of scanning the cpumask in cpu id order. This avoids multiple
CPUs in the LLC scanning for idle to gang up and find the same CPU
quite as much. The down side is that tasks can end up hopping across
the LLC for no apparent reason.
Signed-off-by: Peter Zijlstra (Intel) <peterz@infradead.org>
Cc: Linus Torvalds <torvalds@linux-foundation.org>
Cc: Mike Galbraith <efault@gmx.de>
Cc: Peter Zijlstra <peterz@infradead.org>
Cc: Thomas Gleixner <tglx@linutronix.de>
Cc: linux-kernel@vger.kernel.org
Signed-off-by: Ingo Molnar <mingo@kernel.org>
Move the nr_busy_cpus thing from its hacky sd->parent->groups->sgc
location into the much more natural sched_domain_shared location.
Signed-off-by: Peter Zijlstra (Intel) <peterz@infradead.org>
Cc: Linus Torvalds <torvalds@linux-foundation.org>
Cc: Mike Galbraith <efault@gmx.de>
Cc: Peter Zijlstra <peterz@infradead.org>
Cc: Thomas Gleixner <tglx@linutronix.de>
Cc: linux-kernel@vger.kernel.org
Signed-off-by: Ingo Molnar <mingo@kernel.org>
Since struct sched_domain is strictly per cpu; introduce a structure
that is shared between all 'identical' sched_domains.
Limit to SD_SHARE_PKG_RESOURCES domains for now, as we'll only use it
for shared cache state; if another use comes up later we can easily
relax this.
While the sched_group's are normally shared between CPUs, these are
not natural to use when we need some shared state on a domain level --
since that would require the domain to have a parent, which is not a
given.
Signed-off-by: Peter Zijlstra (Intel) <peterz@infradead.org>
Cc: Linus Torvalds <torvalds@linux-foundation.org>
Cc: Mike Galbraith <efault@gmx.de>
Cc: Peter Zijlstra <peterz@infradead.org>
Cc: Thomas Gleixner <tglx@linutronix.de>
Cc: linux-kernel@vger.kernel.org
Signed-off-by: Ingo Molnar <mingo@kernel.org>
The partial initialization of wait_queue_t in prepare_to_wait_event() looks
ugly. This was done to shrink .text, but we can simply add the new helper
which does the full initialization and shrink the compiled code a bit more.
And. This way prepare_to_wait_event() can have more users. In particular we
are ready to remove the signal_pending_state() checks from wait_bit_action_f
helpers and change __wait_on_bit_lock() to use prepare_to_wait_event().
Signed-off-by: Oleg Nesterov <oleg@redhat.com>
Signed-off-by: Peter Zijlstra (Intel) <peterz@infradead.org>
Cc: Al Viro <viro@ZenIV.linux.org.uk>
Cc: Bart Van Assche <bvanassche@acm.org>
Cc: Johannes Weiner <hannes@cmpxchg.org>
Cc: Linus Torvalds <torvalds@linux-foundation.org>
Cc: Mike Galbraith <efault@gmx.de>
Cc: Neil Brown <neilb@suse.de>
Cc: Peter Zijlstra <peterz@infradead.org>
Cc: Thomas Gleixner <tglx@linutronix.de>
Link: http://lkml.kernel.org/r/20160906140055.GA6167@redhat.com
Signed-off-by: Ingo Molnar <mingo@kernel.org>
__wait_on_bit_lock() doesn't need abort_exclusive_wait() too. Right
now it can't use prepare_to_wait_event() (see the next change), but
it can do the additional finish_wait() if action() fails.
abort_exclusive_wait() no longer has callers, remove it.
Signed-off-by: Oleg Nesterov <oleg@redhat.com>
Signed-off-by: Peter Zijlstra (Intel) <peterz@infradead.org>
Cc: Al Viro <viro@ZenIV.linux.org.uk>
Cc: Bart Van Assche <bvanassche@acm.org>
Cc: Johannes Weiner <hannes@cmpxchg.org>
Cc: Linus Torvalds <torvalds@linux-foundation.org>
Cc: Mike Galbraith <efault@gmx.de>
Cc: Neil Brown <neilb@suse.de>
Cc: Peter Zijlstra <peterz@infradead.org>
Cc: Thomas Gleixner <tglx@linutronix.de>
Link: http://lkml.kernel.org/r/20160906140053.GA6164@redhat.com
Signed-off-by: Ingo Molnar <mingo@kernel.org>
___wait_event() doesn't really need abort_exclusive_wait(), we can simply
change prepare_to_wait_event() to remove the waiter from q->task_list if
it was interrupted.
This simplifies the code/logic, and this way prepare_to_wait_event() can
have more users, see the next change.
Signed-off-by: Oleg Nesterov <oleg@redhat.com>
Signed-off-by: Peter Zijlstra (Intel) <peterz@infradead.org>
Cc: Al Viro <viro@ZenIV.linux.org.uk>
Cc: Bart Van Assche <bvanassche@acm.org>
Cc: Johannes Weiner <hannes@cmpxchg.org>
Cc: Linus Torvalds <torvalds@linux-foundation.org>
Cc: Mike Galbraith <efault@gmx.de>
Cc: Neil Brown <neilb@suse.de>
Cc: Peter Zijlstra <peterz@infradead.org>
Cc: Thomas Gleixner <tglx@linutronix.de>
Link: http://lkml.kernel.org/r/20160908164815.GA18801@redhat.com
Signed-off-by: Ingo Molnar <mingo@kernel.org>
--
include/linux/wait.h | 7 +------
kernel/sched/wait.c | 35 +++++++++++++++++++++++++----------
2 files changed, 26 insertions(+), 16 deletions(-)
Otherwise this logic only works if mode is "compatible" with another
exclusive waiter.
If some wq has both TASK_INTERRUPTIBLE and TASK_UNINTERRUPTIBLE waiters,
abort_exclusive_wait() won't wait an uninterruptible waiter.
The main user is __wait_on_bit_lock() and currently it is fine but only
because TASK_KILLABLE includes TASK_UNINTERRUPTIBLE and we do not have
lock_page_interruptible() yet.
Just use TASK_NORMAL and remove the "mode" arg from abort_exclusive_wait().
Yes, this means that (say) wake_up_interruptible() can wake up the non-
interruptible waiter(s), but I think this is fine. And in fact I think
that abort_exclusive_wait() must die, see the next change.
Signed-off-by: Oleg Nesterov <oleg@redhat.com>
Signed-off-by: Peter Zijlstra (Intel) <peterz@infradead.org>
Cc: Al Viro <viro@ZenIV.linux.org.uk>
Cc: Bart Van Assche <bvanassche@acm.org>
Cc: Johannes Weiner <hannes@cmpxchg.org>
Cc: Linus Torvalds <torvalds@linux-foundation.org>
Cc: Mike Galbraith <efault@gmx.de>
Cc: Neil Brown <neilb@suse.de>
Cc: Peter Zijlstra <peterz@infradead.org>
Cc: Thomas Gleixner <tglx@linutronix.de>
Link: http://lkml.kernel.org/r/20160906140047.GA6157@redhat.com
Signed-off-by: Ingo Molnar <mingo@kernel.org>
This implements:
https://tools.ietf.org/html/rfc7559
Backoff is performed according to RFC3315 section 14:
https://tools.ietf.org/html/rfc3315#section-14
We allow setting /proc/sys/net/ipv6/conf/*/router_solicitations
to a negative value meaning an unlimited number of retransmits,
and we make this the new default (inline with the RFC).
We also add a new setting:
/proc/sys/net/ipv6/conf/*/router_solicitation_max_interval
defaulting to 1 hour (per RFC recommendation).
Signed-off-by: Maciej Żenczykowski <maze@google.com>
Acked-by: Erik Kline <ek@google.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
kbuild test robot reports:
In file included from include/linux/skbuff.h:34:0,
from include/linux/icmpv6.h:4,
from include/linux/ipv6.h:75,
from include/net/ipv6.h:16,
from include/linux/sunrpc/clnt.h:27,
from include/linux/nfs_fs.h:30,
from fs/lockd/clntlock.c:13:
include/linux/dma-mapping.h: In function 'dma_map_resource':
>> include/linux/dma-mapping.h:274:16: warning: unused variable 'pfn' [-Wunused-variable]
unsigned long pfn = __phys_to_pfn(phys_addr);
^~~
The pfn value is only used once in the call to pfn_valid(), remove the
variable and calculate the pfn when it's needed. Note that the kbuild
report is old and PHYS_PFN() is now used instead of __phys_to_pfn() to
calculate the pfn.
Signed-off-by: Niklas Söderlund <niklas.soderlund+renesas@ragnatech.se>
Signed-off-by: Vinod Koul <vinod.koul@intel.com>
kbuild test robot reports:
In file included from include/linux/skbuff.h:34:0,
from include/linux/tcp.h:21,
from drivers/net/ethernet/amd/xgbe/xgbe-drv.c:119:
include/linux/dma-mapping.h: In function 'dma_map_resource':
>> include/linux/dma-mapping.h:274:22: error: implicit declaration of function '__phys_to_pfn' [-Werror=implicit-function-declaration]
unsigned long pfn = __phys_to_pfn(phys_addr);
^~~~~~~~~~~~~
ia64 does not provide __phys_to_pfn(), use the PHYS_PFN() alias.
Signed-off-by: Niklas Söderlund <niklas.soderlund+renesas@ragnatech.se>
Signed-off-by: Vinod Koul <vinod.koul@intel.com>
Trival fix, dev_warn messages are missing a \n, so add it.
Signed-off-by: Colin Ian King <colin.king@canonical.com>
Reviewed-by: Benjamin Tissoires <benjamin.tissoires@redhat.com>
Signed-off-by: Jiri Kosina <jkosina@suse.cz>
Suppose you have a map array value that is something like this
struct foo {
unsigned iter;
int array[SOME_CONSTANT];
};
You can easily insert this into an array, but you cannot modify the contents of
foo->array[] after the fact. This is because we have no way to verify we won't
go off the end of the array at verification time. This patch provides a start
for this work. We accomplish this by keeping track of a minimum and maximum
value a register could be while we're checking the code. Then at the time we
try to do an access into a MAP_VALUE we verify that the maximum offset into that
region is a valid access into that memory region. So in practice, code such as
this
unsigned index = 0;
if (foo->iter >= SOME_CONSTANT)
foo->iter = index;
else
index = foo->iter++;
foo->array[index] = bar;
would be allowed, as we can verify that index will always be between 0 and
SOME_CONSTANT-1. If you wish to use signed values you'll have to have an extra
check to make sure the index isn't less than 0, or do something like index %=
SOME_CONSTANT.
Signed-off-by: Josef Bacik <jbacik@fb.com>
Acked-by: Alexei Starovoitov <ast@kernel.org>
Signed-off-by: David S. Miller <davem@davemloft.net>
When CONFIG_DMA_API_DEBUG is enabled we need to preserve unmapping address
even if "unmap" is a no-op for our architecutre because we need
debug_dma_unmap_page() to correctly cleanup all of the debug bookkeeping.
Failing to do so results in a false positive warnings about previously
mapped areas never being unmapped.
Link: http://lkml.kernel.org/r/1474387125-3713-1-git-send-email-andrew.smirnov@gmail.com
Signed-off-by: Andrey Smirnov <andrew.smirnov@gmail.com>
Reviewed-by: Robin Murphy <robin.murphy@arm.com>
Cc: Joerg Roedel <jroedel@suse.de>
Cc: Will Deacon <will.deacon@arm.com>
Cc: Zhen Lei <thunder.leizhen@huawei.com>
Cc: "Luis R. Rodriguez" <mcgrof@suse.com>
Cc: Christian Borntraeger <borntraeger@de.ibm.com>
Cc: Geliang Tang <geliangtang@163.com>
Signed-off-by: Andrew Morton <akpm@linux-foundation.org>
Signed-off-by: Linus Torvalds <torvalds@linux-foundation.org>
The HTC GPIO driver is a pure GPIO driver and I just can not
see what it is doing inside MFD. Let's just move it to GPIO
and take this opportunity to move the platform data to
<linux/platform_data/gpio-htc-egpio.h>
Cc: arm@kernel.org
Cc: Russell King <linux@armlinux.org.uk>
Acked-by: Lee Jones <lee.jones@linaro.org>
Acked-by: Arnd Bergmann <arnd@arndb.de>
Signed-off-by: Linus Walleij <linus.walleij@linaro.org>
'ARM Server Base Boot Requiremets' [1] mentions SPCR (Serial Port
Console Redirection Table) [2] as a mandatory ACPI table that
specifies the configuration of serial console.
Defer initialization of DT earlycon until ACPI/DT decision is made.
Parse the ACPI SPCR table, setup earlycon if required,
enable specified console.
Thanks to Peter Hurley for explaining how this should work.
[1] http://infocenter.arm.com/help/index.jsp?topic=/com.arm.doc.den0044a/index.html
[2] https://msdn.microsoft.com/en-us/library/windows/hardware/dn639132(v=vs.85).aspx
Signed-off-by: Aleksey Makarov <aleksey.makarov@linaro.org>
Acked-by: Rafael J. Wysocki <rafael.j.wysocki@intel.com>
Reviewed-by: Peter Hurley <peter@hurleysoftware.com>
Tested-by: Kefeng Wang <wangkefeng.wang@huawei.com>
Tested-by: Christopher Covington <cov@codeaurora.org>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
We have multiple "earlycon" early_param handlers - merge the DT one into
the main earlycon one. It's a cleanup that also will be useful
to defer setting up DT console until ACPI/DT decision is made.
Rename the exported function to avoid clashing with the function from
arch/microblaze/kernel/prom.c
Signed-off-by: Leif Lindholm <leif.lindholm@linaro.org>
Signed-off-by: Aleksey Makarov <aleksey.makarov@linaro.org>
Acked-by: Rob Herring <robh@kernel.org>
Acked-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
Reviewed-by: Peter Hurley <peter@hurleysoftware.com>
Tested-by: Kefeng Wang <wangkefeng.wang@huawei.com>
Tested-by: Christopher Covington <cov@codeaurora.org>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
The DMAengine driver for omap-dma use three function calls from the
plat-omap legacy driver. When the DMAengine driver is built when ARCH_OMAP
is not set, the compilation will fail due to missing symbols.
Add empty inline functions to allow the DMAengine driver to be compiled
with COMPILE_TEST.
Signed-off-by: Peter Ujfalusi <peter.ujfalusi@ti.com>
Signed-off-by: Vinod Koul <vinod.koul@intel.com>
-----BEGIN PGP SIGNATURE-----
iQEcBAABAgAGBQJX6H4uAAoJEHm+PkMAQRiG5sMH/3yzrMiUCSokdS+cvY+jgKAG
JS58JmRvBPz2mRaU3MRPBGRDeCz/Nc9LggL2ZcgM+E1ZYirlYyQfIED3lkqk5R07
kIN1wmb+kQhXyU4IY3fEX7joqyKC6zOy4DUChPkBQU0/0+VUmdVmcJvsuPlnMZtf
g95m0BdYTui+eDezASRqOEp3Lb5ONL4c3ao4yBP0LHF033ctj3VJQiyi5uERPZJ0
5e6Mo7Wxn78t9WqJLQAiEH46kTwT2plNlxf3XXqTenfIdbWhqE873HPGeSMa3VQV
VywXTpCpSPQsA8BYg66qIbebdKOhs9MOviHVfqDtwQlvwhjlBDya0gNHfI5fSy4=
=Y/L5
-----END PGP SIGNATURE-----
Merge tag 'v4.8-rc8' into drm-next
Linux 4.8-rc8
There was a lot of fallout in the imx/amdgpu/i915 drivers, so backmerge
it now to avoid troubles.
* tag 'v4.8-rc8': (1442 commits)
Linux 4.8-rc8
fault_in_multipages_readable() throws set-but-unused error
mm: check VMA flags to avoid invalid PROT_NONE NUMA balancing
radix tree: fix sibling entry handling in radix_tree_descend()
radix tree test suite: Test radix_tree_replace_slot() for multiorder entries
fix memory leaks in tracing_buffers_splice_read()
tracing: Move mutex to protect against resetting of seq data
MIPS: Fix delay slot emulation count in debugfs
MIPS: SMP: Fix possibility of deadlock when bringing CPUs online
mm: delete unnecessary and unsafe init_tlb_ubc()
huge tmpfs: fix Committed_AS leak
shmem: fix tmpfs to handle the huge= option properly
blk-mq: skip unmapped queues in blk_mq_alloc_request_hctx
MIPS: Fix pre-r6 emulation FPU initialisation
arm64: kgdb: handle read-only text / modules
arm64: Call numa_store_cpu_info() earlier.
locking/hung_task: Fix typo in CONFIG_DETECT_HUNG_TASK help text
nvme-rdma: only clear queue flags after successful connect
i2c: qup: skip qup_i2c_suspend if the device is already runtime suspended
perf/core: Limit matching exclusive events to one PMU
...
Export the base definitions and the xattr representation of POSIX ACLs
to user space.
Signed-off-by: Andreas Gruenbacher <agruenba@redhat.com>
Signed-off-by: Al Viro <viro@zeniv.linux.org.uk>
Remove the unnecessary typedefs and the zero-length a_entries array in
struct posix_acl_xattr_header.
Signed-off-by: Andreas Gruenbacher <agruenba@redhat.com>
Signed-off-by: Al Viro <viro@zeniv.linux.org.uk>
After 7e8e385aaf ("x86/compat: Remove sys32_vm86_warning"), this
function has become unused, so we can remove it as well.
Link: http://lkml.kernel.org/r/20160617142903.3070388-1-arnd@arndb.de
Signed-off-by: Arnd Bergmann <arnd@arndb.de>
Cc: Alexander Viro <viro@zeniv.linux.org.uk>
Cc: "Theodore Ts'o" <tytso@mit.edu>
Cc: Arnaldo Carvalho de Melo <acme@redhat.com>
Signed-off-by: Andrew Morton <akpm@linux-foundation.org>
current_fs_time() is used for inode timestamps.
Change the signature of the function to take inode pointer
instead of superblock as per Linus's suggestion.
Also, move the api under vfs as per the discussion on the
thread: https://lkml.org/lkml/2016/6/9/36 . As per Arnd's
suggestion on the thread, changing the function name.
current_fs_time() will be deleted after all the references
to it are replaced by current_time().
There was a bug reported by kbuild test bot with the change
as some of the calls to current_time() were made before the
super_block was initialized. Catch these accidental assignments
as timespec_trunc() does for wrong granularities. This allows
for the function to work right even in these circumstances.
But, adds a warning to make the user aware of the bug.
A coccinelle script was used to identify all the current
.alloc_inode super_block callbacks that updated inode timestamps.
proc filesystem was the only one that was modifying inode times
as part of this callback. The series includes a patch to fix that.
Note that timespec_trunc() will also be moved to fs/inode.c
in a separate patch when this will need to be revamped for
bounds checking purposes.
Signed-off-by: Deepa Dinamani <deepa.kernel@gmail.com>
Reviewed-by: Arnd Bergmann <arnd@arndb.de>
Signed-off-by: Al Viro <viro@zeniv.linux.org.uk>
* the only remaining callers of "short" fault-ins are just as happy with generic
variants (both in lib/iov_iter.c); switch them to multipage variants, kill the
"short" ones
* rename the multipage variants to now available plain ones.
* get rid of compat macro defining iov_iter_fault_in_multipage_readable by
expanding it in its only user.
Signed-off-by: Al Viro <viro@zeniv.linux.org.uk>
Save the position of the error reporting capability so it doesn't need to
be rediscovered during error handling.
Signed-off-by: Keith Busch <keith.busch@intel.com>
Signed-off-by: Bjorn Helgaas <bhelgaas@google.com>
CC: Lukas Wunner <lukas@wunner.de>
In some cases (e.g. when the SEQ4_STATUS_EXPIRED_ALL_STATE_REVOKED sequence
flag is set) we may already know that the stateid was revoked and that the
only valid operation we can call is FREE_STATEID. In those cases, allow
the stateid to carry the information in the type field, so that we skip
the redundant call to TEST_STATEID.
Signed-off-by: Trond Myklebust <trond.myklebust@primarydata.com>
Tested-by: Oleg Drokin <green@linuxhacker.ru>
Signed-off-by: Anna Schumaker <Anna.Schumaker@Netapp.com>
The problem with previous code was it rounded values in wrong
place and produced wrong baud rate in some cases.
Signed-off-by: Alexey Starikovskiy <aystarik@gmail.com>
[nicolas.ferre@atmel.com: port to newer kernel and add commit log]
Signed-off-by: Nicolas Ferre <nicolas.ferre@atmel.com>
Reviewed-by: Boris Brezillon <boris.brezillon@free-electrons.com>
Reviewed-by: Uwe Kleine-König <u.kleine-koenig@pengutronix.de>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
The auto incremented counter is not being used anymore, get rid of it.
Signed-off-by: Vitaly Kuznetsov <vkuznets@redhat.com>
Signed-off-by: K. Y. Srinivasan <kys@microsoft.com>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
When performing DMA operations on a MCB device, the device needed
for using the DMA API is "mcb_device->bus_carrier".
This is rather lengthy, so a shortcut is introduced to struct mcb_device
in order to ensure the MCB device driver uses the correct device for DMA
operations.
Signed-off-by: Michael Moese <michael.moese@men.de>
Signed-off-by: Johannes Thumshirn <jthumshirn@suse.de>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
This is trivial to do:
- add flags argument to simple_rename()
- check if flags doesn't have any other than RENAME_NOREPLACE
- assign simple_rename() to .rename2 instead of .rename
Filesystems converted:
hugetlbfs, ramfs, bpf.
Debugfs uses simple_rename() to implement debugfs_rename(), which is for
debugfs instances to rename files internally, not for userspace filesystem
access. For this case pass zero flags to simple_rename().
Signed-off-by: Miklos Szeredi <mszeredi@redhat.com>
Acked-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
Cc: Alexei Starovoitov <ast@kernel.org>
Added one additional parameter to thermal_zone_device_update() to provide
caller with an optional capability to specify reason.
Currently this event is used by user space governor to trigger different
processing based on event code. Also it saves an additional call to read
temperature when the event is received.
The following events are cuurently defined:
- Unspecified event
- New temperature sample
- Trip point violated
- Trip point changed
- thermal device up and down
- thermal device power capability changed
Signed-off-by: Srinivas Pandruvada <srinivas.pandruvada@linux.intel.com>
Signed-off-by: Zhang Rui <rui.zhang@intel.com>
The .get_trend callback in struct thermal_zone_device_ops has
the prototype:
int (*get_trend) (struct thermal_zone_device *, int,
enum thermal_trend *);
whereas the .get_trend callback in struct thermal_zone_of_device_ops
has:
int (*get_trend)(void *, long *);
Streamline both prototypes and add the trip argument to the OF callback
aswell and use enum thermal_trend * instead of an integer pointer.
While the OF prototype may be the better one, this should be decided at
framework level and not on OF level.
Signed-off-by: Sascha Hauer <s.hauer@pengutronix.de>
Signed-off-by: Caesar Wang <wxt@rock-chips.com>
Cc: Zhang Rui <rui.zhang@intel.com>
Cc: Eduardo Valentin <edubezval@gmail.com>
Cc: linux-pm@vger.kernel.org
Reviewed-by: Keerthy <j-keerthy@ti.com>
Signed-off-by: Eduardo Valentin <edubezval@gmail.com>
Signed-off-by: Zhang Rui <rui.zhang@intel.com>
This adds support for hardware-tracked trip points to the device tree
thermal sensor framework.
The framework supports an arbitrary number of trip points. Whenever
the current temperature is updated, the trip points immediately
below and above the current temperature are found. A .set_trips
callback is then called with the temperatures. If there is no trip
point above or below the current temperature, the passed trip
temperature will be -INT_MAX or INT_MAX respectively. In this callback,
the driver should program the hardware such that it is notified
when either of these trip points are triggered. When a trip point
is triggered, the driver should call `thermal_zone_device_update'
for the respective thermal zone. This will cause the trip points
to be updated again.
If .set_trips is not implemented, the framework behaves as before.
This patch is based on an earlier version from Mikko Perttunen
<mikko.perttunen@kapsi.fi>
Signed-off-by: Sascha Hauer <s.hauer@pengutronix.de>
Signed-off-by: Caesar Wang <wxt@rock-chips.com>
Cc: Zhang Rui <rui.zhang@intel.com>
Cc: Eduardo Valentin <edubezval@gmail.com>
Cc: linux-pm@vger.kernel.org
Reviewed-by: Javi Merino <javi.merino@arm.com>
Signed-off-by: Eduardo Valentin <edubezval@gmail.com>
Signed-off-by: Zhang Rui <rui.zhang@intel.com>
Add apis for platform thermal drivers to query for slope and offset
attributes, which might be needed for temperature calculations.
Signed-off-by: Rajendra Nayak <rnayak@codeaurora.org>
Signed-off-by: Eduardo Valentin <edubezval@gmail.com>
Signed-off-by: Zhang Rui <rui.zhang@intel.com>
Bring in the upstream modifications so we can fixup the silent merge
conflict which is introduced by this merge.
Signed-off-by: Thomas Gleixner <tglx@linutronix.de>
The core uses it for polling. Give drivers a proper define handle this
case like for other response types.
Signed-off-by: Wolfram Sang <wsa+renesas@sang-engineering.com>
Signed-off-by: Ulf Hansson <ulf.hansson@linaro.org>
A host controller driver exposes its capability using caps flag
MMC_CAP_CMD_DURING_TFR. A driver with that capability can accept requests
that are marked mrq->cap_cmd_during_tfr = true. Then the driver informs the
upper layers when the command line is available for further commands by
calling mmc_command_done(). Because of that, the driver will not then
automatically send STOP commands, and it is the responsibility of the upper
layer to send a STOP command if it is required.
For requests submitted through the mmc_wait_for_req() interface, the caller
sets mrq->cap_cmd_during_tfr = true which causes mmc_wait_for_req() in fact
not to wait. The caller can then send commands that do not use the data
lines. Finally the caller can wait for the transfer to complete by calling
mmc_wait_for_req_done() which is now exported.
For requests submitted through the mmc_start_req() interface, the caller
again sets mrq->cap_cmd_during_tfr = true, but mmc_start_req() anyway does
not wait. The caller can then send commands that do not use the data
lines. Finally the caller can wait for the transfer to complete in the
normal way i.e. calling mmc_start_req() again.
Irrespective of how a cap_cmd_during_tfr request is started,
mmc_is_req_done() can be called if the upper layer needs to determine if
the request is done. However the appropriate waiting function (either
mmc_wait_for_req_done() or mmc_start_req()) must still be called.
The implementation consists primarily of a new completion
mrq->cmd_completion which notifies when the command line is available for
further commands. That completion is completed by mmc_command_done().
When there is an ongoing data transfer, calls to mmc_wait_for_req() will
automatically wait on that completion, so the caller does not have to do
anything special.
Note, in the case of errors, the driver may call mmc_request_done() without
calling mmc_command_done() because mmc_request_done() always calls
mmc_command_done().
Signed-off-by: Adrian Hunter <adrian.hunter@intel.com>
Signed-off-by: Ulf Hansson <ulf.hansson@linaro.org>
Dwmmc host controller may in unknown state when entering kernel boot. One
example is when booting from eMMC, bootloader need initialize MMC host
controller into some state so it can read. In order to make sure MMC host
controller in a clean initial state, this reset support is added.
With this patch, a 'resets' property can be added into dw_mmc device
tree node. The hardware logic is: dwmmc host controller IP receives a reset
signal from a 'reset provider' (eg. power management unit). The 'resets'
property points to this reset signal. So, during dwmmc driver probe,
it can use this signal to reset itself.
Refer to [1] for more information.
[1] Documentation/devicetree/bindings/reset/reset.txt
Signed-off-by: Guodong Xu <guodong.xu@linaro.org>
Signed-off-by: Xinwei Kong <kong.kongxinwei@hisilicon.com>
Signed-off-by: Zhangfei Gao <zhangfei.gao@linaro.org>
Reviewed-by: Shawn Lin <shawn.lin@rock-chips.com>
Signed-off-by: Jaehoon Chung <jh80.chung@samsung.com>
Signed-off-by: Ulf Hansson <ulf.hansson@linaro.org>
The SD Status register contains several important fields related to the
SD Card proprietary features.
Those fields may be used by user space applications for vendor specific
usage.
None of those fields are exported today by the driver to user space.
In this patch, we are reading the SD Status register and exporting
(using MMC_DEV_ATTR) the SD Status register to the user space.
Signed-off-by: Uri Yanai <uri.yanai@sandisk.com>
Signed-off-by: Ulf Hansson <ulf.hansson@linaro.org>
This patch updates the s3c24xx dma driver to be able to pass a
dma_slave_map array via the platform data. This is needed to
be able to use the new, simpler dmaengine API [1].
I used the virtual DMA channels as a parameter for the dma_filter
function. By doing that, I could reuse the existing filter function in
drivers/dma/s3c24xx-dma.c.
I have tested this on my mini2440 board with the audio driver.
According to my observations, dma_request_slave_channel in the
function dmaengine_pcm_new in the file
sound/soc/soc-generic-dmaengine-pcm.c now returns a valid DMA channel
whereas before no DMA channel was returned at that point.
Entries for DMACH_XD0, DMACH_XD1 and DMACH_TIMER are missing because I
don't realy know which driver to use for these.
[1]
http://lists.infradead.org/pipermail/linux-arm-kernel/2015-December/393635.html
Signed-off-by: Sam Van Den Berge <sam.van.den.berge@telenet.be>
Reviewed-by: Sylwester Nawrocki <s.nawrocki@samsung.com>
Acked-by: Arnd Bergmann <arnd@arndb.de>
Acked-by: Krzysztof Kozlowski <krzk@kernel.org>
Signed-off-by: Vinod Koul <vinod.koul@intel.com>
To get more coverage, enable COMPILE_TEST for this driver.
While at it, to fix build on other archs, select MMP_SRAM only for ARCH_MMP
and also fix the platform header
Suggested-by: Arnd Bergmann <arnd@arndb.de>
Acked-by: Zhangfei Gao <zhangfei.gao@linaro.org>
Signed-off-by: Vinod Koul <vinod.koul@intel.com>
Map/Unmap a device MMIO resource from a physical address. If no dma_map_ops
method is available the operation is a no-op.
Signed-off-by: Niklas Söderlund <niklas.soderlund+renesas@ragnatech.se>
Acked-by: Arnd Bergmann <arnd@arndb.de>
Signed-off-by: Vinod Koul <vinod.koul@intel.com>
A MMIO mapped resource can not be represented by a struct page so a new
debug type is needed to handle this. This patch add such type and
functionality to add/remove entries and how to translate them to a
physical address.
Signed-off-by: Niklas Söderlund <niklas.soderlund+renesas@ragnatech.se>
Acked-by: Arnd Bergmann <arnd@arndb.de>
Signed-off-by: Vinod Koul <vinod.koul@intel.com>
Add methods to handle mapping of device resources from a physical
address. This is needed for example to be able to map MMIO FIFO
registers to a IOMMU.
Signed-off-by: Niklas Söderlund <niklas.soderlund+renesas@ragnatech.se>
Reviewed-by: Laurent Pinchart <laurent.pinchart@ideasonboard.com>
Acked-by: Arnd Bergmann <arnd@arndb.de>
Signed-off-by: Vinod Koul <vinod.koul@intel.com>
When building XFS with -Werror, it now fails with:
include/linux/pagemap.h: In function 'fault_in_multipages_readable':
include/linux/pagemap.h:602:16: error: variable 'c' set but not used [-Werror=unused-but-set-variable]
volatile char c;
^
This is a regression caused by commit e23d4159b1 ("fix
fault_in_multipages_...() on architectures with no-op access_ok()").
Fix it by re-adding the "(void)c" trick taht was previously used to make
the compiler think the variable is used.
Signed-off-by: Dave Chinner <dchinner@redhat.com>
Cc: Al Viro <viro@zeniv.linux.org.uk>
Signed-off-by: Linus Torvalds <torvalds@linux-foundation.org>
Conflicts:
net/netfilter/core.c
net/netfilter/nf_tables_netdev.c
Resolve two conflicts before pull request for David's net-next tree:
1) Between c73c248490 ("netfilter: nf_tables_netdev: remove redundant
ip_hdr assignment") from the net tree and commit ddc8b6027a
("netfilter: introduce nft_set_pktinfo_{ipv4, ipv6}_validate()").
2) Between e8bffe0cf9 ("net: Add _nf_(un)register_hooks symbols") and
Aaron Conole's patches to replace list_head with single linked list.
Signed-off-by: Pablo Neira Ayuso <pablo@netfilter.org>
The netfilter hook list never uses the prev pointer, and so can be trimmed to
be a simple singly-linked list.
In addition to having a more light weight structure for hook traversal,
struct net becomes 5568 bytes (down from 6400) and struct net_device becomes
2176 bytes (down from 2240).
Signed-off-by: Aaron Conole <aconole@bytheb.org>
Signed-off-by: Florian Westphal <fw@strlen.de>
Signed-off-by: Pablo Neira Ayuso <pablo@netfilter.org>
This makes things simpler because we can store the head of the list
in the nf_state structure without worrying about concurrent add/delete
of hook elements from the list.
A future commit will make use of this to implement a simpler
linked-list.
Signed-off-by: Florian Westphal <fw@strlen.de>
Signed-off-by: Aaron Conole <aconole@bytheb.org>
Signed-off-by: Pablo Neira Ayuso <pablo@netfilter.org>
Move the vf to VST 802.1ad mode (mlx4 VST QinQ mode) by setting vf vlan
protocol to 802.1ad.
VST 802.1ad mode in mlx4, is used for STAG strip/insertion by PF, while
the CTAG is set by the VF.
Read current vlan protocol as part of the vf configuration state.
Upon setting vf vlan protocol to 802.1ad, we use a mechanism of handshake
to verify that both the vf and the pf driver version support it.
The handshake uses the command QUERY_FUNC_CAP:
- The vf sets a pre-defined support bit in input modifier.
- A pf that supports the feature sends the request to the vf through a
pre-defined field in the output mailbox.
- In case vf does not support the feature, the pf will fail the control
command (in this case, IP link tool command to set the vf vlan
protocol to 802.1ad).
No change in VST 802.1Q mode.
Signed-off-by: Moshe Shemesh <moshe@mellanox.com>
Signed-off-by: Tariq Toukan <tariqt@mellanox.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Introduce new rtnl UAPI that exposes a list of vlans per VF, giving
the ability for user-space application to specify it for the VF, as an
option to support 802.1ad.
We adjusted IP Link tool to support this option.
For future use cases, the new UAPI supports multiple vlans. For now we
limit the list size to a single vlan in kernel.
Add IFLA_VF_VLAN_LIST in addition to IFLA_VF_VLAN to keep backward
compatibility with older versions of IP Link tool.
Add a vlan protocol parameter to the ndo_set_vf_vlan callback.
We kept 802.1Q as the drivers' default vlan protocol.
Suitable ip link tool command examples:
Set vf vlan protocol 802.1ad:
ip link set eth0 vf 1 vlan 100 proto 802.1ad
Set vf to VST (802.1Q) mode:
ip link set eth0 vf 1 vlan 100 proto 802.1Q
Or by omitting the new parameter
ip link set eth0 vf 1 vlan 100
Signed-off-by: Moshe Shemesh <moshe@mellanox.com>
Signed-off-by: Tariq Toukan <tariqt@mellanox.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Check device capability to support VF vlan protocol 802.1ad mode.
Add vport attribute vlan protocol.
Init vport vlan protocol by default to 802.1Q.
Add update QP support for VF vlan protocol 802.1ad.
Add func capability vlan_offload_disable to disable all
vlan HW acceleration on VF while the VF is set to VF vlan protocol
802.1ad mode.
No change in VF vlan protocol 802.1Q (VST) mode.
Signed-off-by: Moshe Shemesh <moshe@mellanox.com>
Signed-off-by: Tariq Toukan <tariqt@mellanox.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
This define is needed by i2c_adapter_depth() to detect if we don't
exceed the maximum number of lock subclasses. Make it visible even
if lockdep is disabled.
Signed-off-by: Bartosz Golaszewski <bgolaszewski@baylibre.com>
Acked-by: Peter Rosin <peda@axentia.se>
Acked-by: Peter Zijlstra (Intel) <peterz@infradead.org>
Signed-off-by: Wolfram Sang <wsa@the-dreams.de>
For crazy setups in which an i2c gpio expander is behind an i2c gpio
multiplexer controlled by a gpio provided a second expander using the
same device driver we need to explicitly tell lockdep how to handle
nested locking.
Export i2c_adapter_depth() as public API to be reused outside of i2c
core code.
Signed-off-by: Bartosz Golaszewski <bgolaszewski@baylibre.com>
Acked-by: Peter Rosin <peda@axentia.se>
Acked-by: Peter Zijlstra (Intel) <peterz@infradead.org>
Signed-off-by: Wolfram Sang <wsa@the-dreams.de>
The generic THREAD_INFO_IN_TASK definition of thread_info::flags is a
u32, matching x86 prior to the introduction of THREAD_INFO_IN_TASK.
However, common helpers like test_ti_thread_flag() implicitly assume
that thread_info::flags has at least the size and alignment of unsigned
long, and relying on padding and alignment provided by other elements of
task_struct is somewhat fragile. Additionally, some architectures use
more that 32 bits for thread_info::flags, and others may need to in
future.
With THREAD_INFO_IN_TASK, task struct follows thread_info with a long
field, and thus we no longer save any space as we did back in commit:
affa219b60 ("x86: change thread_info's flag field back to 32 bits")
Given all this, it makes more sense for the generic thread_info::flags
to be an unsigned long.
In fact given <linux/thread_info.h> contains/uses the helpers mentioned
above, BE arches *must* use unsigned long (or something of the same size)
today, or they wouldn't work.
Make it so.
Signed-off-by: Mark Rutland <mark.rutland@arm.com>
Cc: Andrew Morton <akpm@linux-foundation.org>
Cc: Andy Lutomirski <luto@kernel.org>
Cc: Borislav Petkov <bp@alien8.de>
Cc: Brian Gerst <brgerst@gmail.com>
Cc: Denys Vlasenko <dvlasenk@redhat.com>
Cc: H. Peter Anvin <hpa@zytor.com>
Cc: Josh Poimboeuf <jpoimboe@redhat.com>
Cc: Kees Cook <keescook@chromium.org>
Cc: Linus Torvalds <torvalds@linux-foundation.org>
Cc: Peter Zijlstra <peterz@infradead.org>
Cc: Thomas Gleixner <tglx@linutronix.de>
Link: http://lkml.kernel.org/r/1474651447-30447-1-git-send-email-mark.rutland@arm.com
Signed-off-by: Ingo Molnar <mingo@kernel.org>
Since the watchdog framework centrializes the IOCTL interfaces of device
drivers now, SETPRETIMEOUT and GETPRETIMEOUT need to be added in the
common code.
Signed-off-by: Robin Gong <b38343@freescale.com>
Signed-off-by: Wolfram Sang <wsa+renesas@sang-engineering.com>
[vzapolskiy: added conditional pretimeout sysfs attribute visibility]
Signed-off-by: Vladimir Zapolskiy <vladimir_zapolskiy@mentor.com>
Reviewed-by: Guenter Roeck <linux@roeck-us.net>
Signed-off-by: Guenter Roeck <linux@roeck-us.net>
Signed-off-by: Wim Van Sebroeck <wim@iguana.be>
Starting from Intel Skylake the iTCO watchdog timer registers were moved to
reside in the same register space with SMBus host controller. Not all
needed registers are available though and we need to unhide P2SB (Primary
to Sideband) device briefly to be able to read status of required NO_REBOOT
bit. The i2c-i801.c SMBus driver used to handle this and creation of the
iTCO watchdog platform device.
Windows, on the other hand, does not use the iTCO watchdog hardware
directly even if it is available. Instead it relies on ACPI Watchdog Action
Table (WDAT) table to describe the watchdog hardware to the OS. This table
contains necessary information about the the hardware and also set of
actions which are executed by a driver as needed.
This patch implements a new watchdog driver that takes advantage of the
ACPI WDAT table. We split the functionality into two parts: first part
enumerates the WDAT table and if found, populates resources and creates
platform device for the actual driver. The second part is the driver
itself.
The reason for the split is that this way we can make the driver itself to
be a module and loaded automatically if the WDAT table is found. Otherwise
the module is not loaded.
Signed-off-by: Mika Westerberg <mika.westerberg@linux.intel.com>
Reviewed-by: Guenter Roeck <linux@roeck-us.net>
Signed-off-by: Rafael J. Wysocki <rafael.j.wysocki@intel.com>
The "num" is the number of clk_hw entries in the structure, so
"unsigned int" would be a better fit. (size_t looks like data
size we count by byte.)
Besides, struct clk_onecell_data already uses unsigned int for
"clk_num".
Signed-off-by: Masahiro Yamada <yamada.masahiro@socionext.com>
Signed-off-by: Stephen Boyd <sboyd@codeaurora.org>
Avoid that sparse complains about blkg_hint manipulations.
Fixes: a637120e49 ("blkcg: use radix tree to index blkgs from blkcg")
Signed-off-by: Bart Van Assche <bart.vanassche@sandisk.com>
Acked-by: Tejun Heo <tj@kernel.org>
Signed-off-by: Jens Axboe <axboe@fb.com>
Support Remote Invalidation. A private message is exchanged with
the client upon RDMA transport connect that indicates whether
Send With Invalidation may be used by the server to send RPC
replies. The invalidate_rkey is arbitrarily chosen from among
rkeys present in the RPC-over-RDMA header's chunk lists.
Send With Invalidate improves performance only when clients can
recognize, while processing an RPC reply, that an rkey has already
been invalidated. That has been submitted as a separate change.
In the future, the RPC-over-RDMA protocol might support Remote
Invalidation properly. The protocol needs to enable signaling
between peers to indicate when Remote Invalidation can be used
for each individual RPC.
Signed-off-by: Chuck Lever <chuck.lever@oracle.com>
Reviewed-by: Sagi Grimberg <sagi@grimberg.me>
Signed-off-by: J. Bruce Fields <bfields@redhat.com>
Introduce data structure used by both client and server to exchange
implementation details during RDMA/CM connection establishment.
This is an experimental out-of-band exchange between Linux
RPC-over-RDMA Version One implementations, replacing the deprecated
CCP (see RFC 5666bis). The purpose of this extension is to enable
prototyping of features that might be introduced in a subsequent
version of RPC-over-RDMA.
Suggested by Christoph Hellwig and Devesh Sharma.
Signed-off-by: Chuck Lever <chuck.lever@oracle.com>
Reviewed-by: Sagi Grimberg <sagi@grimberg.me>
Signed-off-by: J. Bruce Fields <bfields@redhat.com>
The ctxt's count field is overloaded to mean the number of pages in
the ctxt->page array and the number of SGEs in the ctxt->sge array.
Typically these two numbers are the same.
However, when an inline RPC reply is constructed from an xdr_buf
with a tail iovec, the head and tail often occupy the same page,
but each are DMA mapped independently. In that case, ->count equals
the number of pages, but it does not equal the number of SGEs.
There's one more SGE, for the tail iovec. Hence there is one more
DMA mapping than there are pages in the ctxt->page array.
This isn't a real problem until the server's iommu is enabled. Then
each RPC reply that has content in that iovec orphans a DMA mapping
that consists of real resources.
krb5i and krb5p always populate that tail iovec. After a couple
million sent krb5i/p RPC replies, the NFS server starts behaving
erratically. Reboot is needed to clear the problem.
Fixes: 9d11b51ce7 ("svcrdma: Fix send_reply() scatter/gather set-up")
Signed-off-by: Chuck Lever <chuck.lever@oracle.com>
Signed-off-by: J. Bruce Fields <bfields@redhat.com>
When using GPIO irqchip helpers to setup irqchip for a gpiolib based
driver, it is not possible to select which GPIOs to add to the IRQ domain.
Instead it just adds all GPIOs which is not always desired. For example
there might be GPIOs that for some reason cannot generated normal
interrupts at all.
To support this we add a flag irq_need_valid_mask to struct gpio_chip. When
this flag is set the core allocates irq_valid_mask that holds one bit for
each GPIO the chip has. By default all bits are set but drivers can
manipulate this using set_bit() and clear_bit() accordingly.
Then when gpiochip_irqchip_add() is called, this mask is checked and all
GPIOs with bit is set are added to the IRQ domain created for the GPIO
chip.
Suggested-by: Linus Walleij <linus.walleij@linaro.org>
Signed-off-by: Mika Westerberg <mika.westerberg@linux.intel.com>
Signed-off-by: Linus Walleij <linus.walleij@linaro.org>
-----BEGIN PGP SIGNATURE-----
iQEcBAABCgAGBQJX45B3AAoJED07qiWsqSVqw34H/060v5lUgOYtRU4Eq2v9PJ9K
S+zTHFObExqHB2CdIqoYoWROG8HT0KcaDI7R1Ua62lM0kM9JucbMUghDALdQiSSE
GG2n7VWgAwpDTh+HL9FCX4sRSjgJ5efRCcGV/x+W/bc9lpFdjCY2G41S3od2Ts6v
m54uXaUPAK29G2rMOUIFKX8IqWcG+OvUCnt+iDeijHRgzwDvNV1vNW9sTPJQjLdN
z1jwSVHelrG/7bBJ5ZuVQVCnF564cTRCr+ZKuwCFXI6fp7DLzup4pqzS/+S0hiVP
MPfuDYoYE1lOVaYgzbR9QSo11TGhCRfnFgYUF9hgklDW+iOQ9heVMXhZ6TRKbBA=
=8O8M
-----END PGP SIGNATURE-----
Merge tag 'linux-can-fixes-for-4.8-20160922' of git://git.kernel.org/pub/scm/linux/kernel/git/mkl/linux-can
Marc Kleine-Budde says:
====================
pull-request: can 2016-09-22
this is a pull request of one patch for the upcoming linux-4.8 release.
The patch by Sergei Miroshnichenko fixes a potential deadlock in the generic
CAN device code that cann occour after a bus-off.
====================
Signed-off-by: David S. Miller <davem@davemloft.net>
Provide a nand_cleanup() function to free all nand related resources
without unregistering the mtd device.
This should allow drivers to call mtd_device_unregister() and handle
its return value and still being able to cleanup all nand related
resources.
Signed-off-by: Richard Weinberger <richard@nod.at>
Signed-off-by: Daniel Walter <dwalter@sigma-star.at>
Signed-off-by: Boris Brezillon <boris.brezillon@free-electrons.com>
The generic NAND DT bindings allows one to tweak the ECC strength and
step size to their need. It can be used to lower the ECC strength to
match a bootloader/firmware config, but might also be used to get a better
reliability.
In the latter case, the user might want to use the maximum ECC strength
without having to explicitly calculate the exact value (this value not
only depends on the OOB size, but also on the NAND controller, and can
be tricky to extract).
Add a generic 'nand-ecc-maximize' DT property and the associated
NAND_ECC_MAXIMIZE flag, to let ECC controller drivers select the best
ECC strength and step-size on their own.
Signed-off-by: Boris Brezillon <boris.brezillon@free-electrons.com>
Acked-by: Rob Herring <robh@kernel.org>
The NAND framework provides several helpers to query timing modes supported
by a NAND chip, but this implies that all NAND controller drivers have
to implement the same timings selection dance. Also currently NAND
devices can be resetted at arbitrary places which also resets the timing
for ONFI chips to timing mode 0.
Provide a common logic to select the best timings based on ONFI or
->onfi_timing_mode_default information. Hook this into nand_reset()
to make sure the new timing is applied each time during a reset.
NAND controller willing to support timings adjustment should just
implement the ->setup_data_interface() method.
Signed-off-by: Boris Brezillon <boris.brezillon@free-electrons.com>
Signed-off-by: Sascha Hauer <s.hauer@pengutronix.de>
The nand layer will need ONFI mode 0 to use it as timing mode
before and right after reset.
Signed-off-by: Sascha Hauer <s.hauer@pengutronix.de>
Signed-off-by: Boris Brezillon <boris.brezillon@free-electrons.com>
onfi_init_data_interface() initializes a data interface with
values from a given ONFI mode.
Signed-off-by: Sascha Hauer <s.hauer@pengutronix.de>
Signed-off-by: Boris Brezillon <boris.brezillon@free-electrons.com>
Currently we have no data structure to fully describe a NAND timing.
We only have struct nand_sdr_timings for NAND timings in SDR mode,
but nothing for DDR mode and also no container to store both types
of timing.
This patch adds struct nand_data_interface which stores the timing
type and a union of different timings. This can be used to pass to
drivers in order to configure the timing.
Add kerneldoc for struct nand_sdr_timings while touching it anyway.
Signed-off-by: Sascha Hauer <s.hauer@pengutronix.de>
Signed-off-by: Boris Brezillon <boris.brezillon@free-electrons.com>
When NAND devices are resetted some initialization may have to be done,
like for example they have to be configured for the timing mode that
shall be used. To get a common place where this initialization can be
implemented create a nand_reset() function. This currently only issues
a NAND_CMD_RESET to the NAND device. The places issuing this command
manually are replaced with a call to nand_reset().
Signed-off-by: Sascha Hauer <s.hauer@pengutronix.de>
Signed-off-by: Boris Brezillon <boris.brezillon@free-electrons.com>
'extern' is not necessary for function declarations. To prevent
people from adding the keyword to new declarations remove the
existing ones.
Signed-off-by: Sascha Hauer <s.hauer@pengutronix.de>
Signed-off-by: Boris Brezillon <boris.brezillon@free-electrons.com>
The code to initialize a struct nand_hw_control is duplicated across
several drivers. Factorize it using an inline function.
Signed-off-by: Marc Gonzalez <marc_gonzalez@sigmadesigns.com>
Signed-off-by: Boris Brezillon <boris.brezillon@free-electrons.com>
From: Andrey Vagin <avagin@openvz.org>
Each namespace has an owning user namespace and now there is not way
to discover these relationships.
Pid and user namepaces are hierarchical. There is no way to discover
parent-child relationships too.
Why we may want to know relationships between namespaces?
One use would be visualization, in order to understand the running
system. Another would be to answer the question: what capability does
process X have to perform operations on a resource governed by namespace
Y?
One more use-case (which usually called abnormal) is checkpoint/restart.
In CRIU we are going to dump and restore nested namespaces.
There [1] was a discussion about which interface to choose to determing
relationships between namespaces.
Eric suggested to add two ioctl-s [2]:
> Grumble, Grumble. I think this may actually a case for creating ioctls
> for these two cases. Now that random nsfs file descriptors are bind
> mountable the original reason for using proc files is not as pressing.
>
> One ioctl for the user namespace that owns a file descriptor.
> One ioctl for the parent namespace of a namespace file descriptor.
Here is an implementaions of these ioctl-s.
$ man man7/namespaces.7
...
Since Linux 4.X, the following ioctl(2) calls are supported for
namespace file descriptors. The correct syntax is:
fd = ioctl(ns_fd, ioctl_type);
where ioctl_type is one of the following:
NS_GET_USERNS
Returns a file descriptor that refers to an owning user names‐
pace.
NS_GET_PARENT
Returns a file descriptor that refers to a parent namespace.
This ioctl(2) can be used for pid and user namespaces. For
user namespaces, NS_GET_PARENT and NS_GET_USERNS have the same
meaning.
In addition to generic ioctl(2) errors, the following specific ones
can occur:
EINVAL NS_GET_PARENT was called for a nonhierarchical namespace.
EPERM The requested namespace is outside of the current namespace
scope.
[1] https://lkml.org/lkml/2016/7/6/158
[2] https://lkml.org/lkml/2016/7/9/101
Changes for v2:
* don't return ENOENT for init_user_ns and init_pid_ns. There is nothing
outside of the init namespace, so we can return EPERM in this case too.
> The fewer special cases the easier the code is to get
> correct, and the easier it is to read. // Eric
Changes for v3:
* rename ns->get_owner() to ns->owner(). get_* usually means that it
grabs a reference.
Cc: "Eric W. Biederman" <ebiederm@xmission.com>
Cc: James Bottomley <James.Bottomley@HansenPartnership.com>
Cc: "Michael Kerrisk (man-pages)" <mtk.manpages@gmail.com>
Cc: "W. Trevor King" <wking@tremily.us>
Cc: Alexander Viro <viro@zeniv.linux.org.uk>
Cc: Serge Hallyn <serge.hallyn@canonical.com>
Pid and user namepaces are hierarchical. There is no way to discover
parent-child relationships.
In a future we will use this interface to dump and restore nested
namespaces.
Acked-by: Serge Hallyn <serge@hallyn.com>
Signed-off-by: Andrei Vagin <avagin@openvz.org>
Signed-off-by: Eric W. Biederman <ebiederm@xmission.com>
Return -EPERM if an owning user namespace is outside of a process
current user namespace.
v2: In a first version ns_get_owner returned ENOENT for init_user_ns.
This special cases was removed from this version. There is nothing
outside of init_user_ns, so we can return EPERM.
v3: rename ns->get_owner() to ns->owner(). get_* usually means that it
grabs a reference.
Acked-by: Serge Hallyn <serge@hallyn.com>
Signed-off-by: Andrei Vagin <avagin@openvz.org>
Signed-off-by: Eric W. Biederman <ebiederm@xmission.com>
PCIe hotplug supports optional Attention and Power Indicators, which are
used internally by pciehp. Users can't control the Power Indicator, but
they can control the Attention Indicator by writing to a sysfs "attention"
file.
The Slot Control register has two bits for each indicator, and the PCIe
spec defines the encodings for each as (Reserved/On/Blinking/Off). For
sysfs "attention" writes, pciehp_set_attention_status() maps into these
encodings, so the only useful write values are 0 (Off), 1 (On), and 2
(Blinking).
However, some platforms use all four bits for platform-specific indicators,
and they need to allow direct user control of them while preventing pciehp
from using them at all.
Add a "hotplug_user_indicators" flag to the pci_dev structure. When set,
pciehp does not use either the Attention Indicator or the Power Indicator,
and the low four bits (values 0x0 - 0xf) of sysfs "attention" write values
are written directly to the Attention Indicator Control and Power Indicator
Control fields.
[bhelgaas: changelog, rename flag and accessors to s/attention/indicator/]
Signed-off-by: Keith Busch <keith.busch@intel.com>
Signed-off-by: Bjorn Helgaas <bhelgaas@google.com>
If a driver sets BLK_MQ_F_BLOCKING, it is allowed to block in its
->queue_rq() handler. For that case, blk-mq ensures that we always
calls it from a safe context.
Signed-off-by: Jens Axboe <axboe@fb.com>
Tested-by: Josef Bacik <jbacik@fb.com>
Add a waitqueue head to the client structure. Have clients set a wait
on that queue prior to requesting a lock from the server. If the lock
is blocked, then we can use that to wait for wakeups.
Note that we do need to do this "manually" since we need to set the
wait on the waitqueue prior to requesting the lock, but requesting a
lock can involve activities that can block.
However, only do that for NFSv4.1 locks, either by compiling out
all of the waitqueue handling when CONFIG_NFS_V4_1 is disabled, or
skipping all of it at runtime if we're dealing with v4.0, or v4.1
servers that don't send lock callbacks.
Note too that even when we expect to get a lock callback, RFC5661
section 20.11.4 is pretty clear that we still need to poll for them,
so we do still sleep on a timeout. We do however always poll at the
longest interval in that case.
Signed-off-by: Jeff Layton <jlayton@redhat.com>
[Anna: nfs4_retry_setlk() "status" should default to -ERESTARTSYS]
Signed-off-by: Anna Schumaker <Anna.Schumaker@Netapp.com>
asm-generic is only intended for architecture defaults, and we can simply
kill it off by moving the two defintions directly to <linux/libata.h>.
Signed-off-by: Christoph Hellwig <hch@lst.de>
Signed-off-by: Tejun Heo <tj@kernel.org>
Replace the block-mq notifier list management with the multi instance
facility in the cpu hotplug state machine.
Signed-off-by: Thomas Gleixner <tglx@linutronix.de>
Cc: Peter Zijlstra <peterz@infradead.org>
Cc: linux-block@vger.kernel.org
Cc: rt@linutronix.de
Cc: Christoph Hellwing <hch@lst.de>
Signed-off-by: Jens Axboe <axboe@fb.com>
bio_free_pages is introduced in commit 1dfa0f68c0
("block: add a helper to free bio bounce buffer pages"),
we can reuse the func in other modules after it was
imported.
Cc: Christoph Hellwig <hch@infradead.org>
Cc: Jens Axboe <axboe@fb.com>
Cc: Mike Snitzer <snitzer@redhat.com>
Cc: Shaohua Li <shli@fb.com>
Signed-off-by: Guoqing Jiang <gqjiang@suse.com>
Acked-by: Kent Overstreet <kent.overstreet@gmail.com>
Signed-off-by: Jens Axboe <axboe@fb.com>
It is now unused, remove it before someone else thinks its a good idea
to use this.
Signed-off-by: Peter Zijlstra (Intel) <peterz@infradead.org>
Cc: Linus Torvalds <torvalds@linux-foundation.org>
Cc: Peter Zijlstra <peterz@infradead.org>
Cc: Thomas Gleixner <tglx@linutronix.de>
Cc: linux-kernel@vger.kernel.org
Signed-off-by: Ingo Molnar <mingo@kernel.org>
stop_two_cpus() and stop_cpus() use stop_cpus_lock to avoid the deadlock,
we need to ensure that the stopper functions can't be queued "backwards"
from one another. This doesn't look nice; if we use lglock then we do not
really need stopper->lock, cpu_stop_queue_work() could use lg_local_lock()
under local_irq_save().
OTOH it would be even better to avoid lglock in stop_machine.c and remove
lg_double_lock(). This patch adds "bool stop_cpus_in_progress" set/cleared
by queue_stop_cpus_work(), and changes cpu_stop_queue_two_works() to busy
wait until it is cleared.
queue_stop_cpus_work() sets stop_cpus_in_progress = T lockless, but after
it queues a work on CPU1 it must be visible to stop_two_cpus(CPU1, CPU2)
which checks it under the same lock. And since stop_two_cpus() holds the
2nd lock too, queue_stop_cpus_work() can not clear stop_cpus_in_progress
if it is also going to queue a work on CPU2, it needs to take that 2nd
lock to do this.
Signed-off-by: Oleg Nesterov <oleg@redhat.com>
Signed-off-by: Peter Zijlstra (Intel) <peterz@infradead.org>
Cc: Linus Torvalds <torvalds@linux-foundation.org>
Cc: Peter Zijlstra <peterz@infradead.org>
Cc: Rik van Riel <riel@redhat.com>
Cc: Tejun Heo <tj@kernel.org>
Cc: Thomas Gleixner <tglx@linutronix.de>
Link: http://lkml.kernel.org/r/20151121181148.GA433@redhat.com
Signed-off-by: Ingo Molnar <mingo@kernel.org>
Provide a down_read()/up_read() variant that keeps preemption disabled
over the whole thing, when possible.
This avoids a needless preemption point for constructs such as:
percpu_down_read(&global_rwsem);
spin_lock(&lock);
...
spin_unlock(&lock);
percpu_up_read(&global_rwsem);
Which perturbs timings. In particular it was found to cure a
performance regression in a follow up patch in fs/locks.c
Signed-off-by: Peter Zijlstra (Intel) <peterz@infradead.org>
Cc: Linus Torvalds <torvalds@linux-foundation.org>
Cc: Peter Zijlstra <peterz@infradead.org>
Cc: Thomas Gleixner <tglx@linutronix.de>
Cc: linux-kernel@vger.kernel.org
Signed-off-by: Ingo Molnar <mingo@kernel.org>
On fully preemptible kernels _cond_resched() is pointless, so avoid
emitting any code for it.
Signed-off-by: Peter Zijlstra (Intel) <peterz@infradead.org>
Cc: Linus Torvalds <torvalds@linux-foundation.org>
Cc: Mikulas Patocka <mpatocka@redhat.com>
Cc: Oleg Nesterov <oleg@redhat.com>
Cc: Peter Zijlstra <peterz@infradead.org>
Cc: Thomas Gleixner <tglx@linutronix.de>
Cc: linux-kernel@vger.kernel.org
Signed-off-by: Ingo Molnar <mingo@kernel.org>
Oleg noted that by making do_exit() use __schedule() for the TASK_DEAD
context switch, we can avoid the TASK_DEAD special case currently in
__schedule() because that avoids the extra preempt_disable() from
schedule().
In order to facilitate this, create a do_task_dead() helper which we
place in the scheduler code, such that it can access __schedule().
Also add some __noreturn annotations to the functions, there's no
coming back from do_exit().
Suggested-by: Oleg Nesterov <oleg@redhat.com>
Signed-off-by: Peter Zijlstra (Intel) <peterz@infradead.org>
Cc: Cheng Chao <cs.os.kernel@gmail.com>
Cc: Linus Torvalds <torvalds@linux-foundation.org>
Cc: Peter Zijlstra <peterz@infradead.org>
Cc: Thomas Gleixner <tglx@linutronix.de>
Cc: akpm@linux-foundation.org
Cc: chris@chris-wilson.co.uk
Cc: tj@kernel.org
Link: http://lkml.kernel.org/r/20160913163729.GB5012@twins.programming.kicks-ass.net
Signed-off-by: Ingo Molnar <mingo@kernel.org>
adds PHY-mode "trgmii" as an extension for the operation
mode of the PHY interface for PHY_INTERFACE_MODE_TRGMII.
and adds a variable trgmii inside mtk_mac as the indication
to make the difference between the MAC connected to internal
switch or connected to external PHY by the given configuration
on the board and then to perform the corresponding setup on
TRGMII hardware module.
Signed-off-by: Sean Wang <sean.wang@mediatek.com>
Cc: Florian Fainelli <f.fainelli@gmail.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
-----BEGIN PGP SIGNATURE-----
iQIVAwUAV+OQV/Sw1s6N8H32AQK/Gw//TF7n19v+gqUenh5m6xPYkVlZl6d/TRi+
3JoG5pdNORxTDU7UgzkeuCywDTk5XUYsJs3TOzInRAdDedwfgIiwF3ZKw3Bo30vR
cVUfG7GK4o+CLWifL3BILYMTJfkOnUS4sllylSqX/EOlPDEEspSRWTxXq+DCOGNZ
1APBRD8XfA+IIC3fleMh+zSpKZ3ffc2c7djelzo2nCG3ku78U57B23TCyzp2tQNQ
6ClvhOAwL2nMXF5vebtIU7ou6LUV/TdC4qTkQuz3du/+k+LOG/c8/6s6k70MgXQU
L3DW3rcnrWxkyzDb5oQoGYSWG5x4gp/TazHbJE2kuUVhQma8eDbOAGRWJoxlSzoC
LqHE+6q3KnwwXpbYd3DJ+jUI7pu7pUvub1cvJr0uxPcjRb4CzhHT/1OBUb9p4CJX
/n8NFNXk+5qWsvLaPuNNBPs4pc2xgz/cotjKBYUznqObiq2xgeivZpbsEBOpSIT1
2hl0EuyAi1Gwpi6qfW8oM6EGrlAzuG77cLcLnxrDz+GsHcgqUvdSuTh0P26eOh7D
1V03kkfX9dIqkOc5xA9xAckopfG5BhQDiFsMV+5McZ2x8GtUdnMw8E7dsG8xIeY5
yDzk9m6tD79PlqS7HJ7Fzj6owzqLUeJOI08y9EUSacBFKzNak1NVmcYcXd10rDFj
duNM4rDi6zA=
=3zfm
-----END PGP SIGNATURE-----
Merge tag 'rxrpc-rewrite-20160922-v2' of git://git.kernel.org/pub/scm/linux/kernel/git/dhowells/linux-fs
David Howells says:
====================
rxrpc: Preparation for slow-start algorithm [ver #2]
Here are some patches that prepare for improvements in ACK generation and
for the implementation of the slow-start part of the protocol:
(1) Stop storing the protocol header in the Tx socket buffers, but rather
generate it on the fly. This potentially saves a little space and
makes it easier to alter the header just before transmission (the
flags may get altered and the serial number has to be changed).
(2) Mask off the Tx buffer annotations and add a flag to record which ones
have already been resent.
(3) Track RTT on a per-peer basis for use in future changes. Tracepoints
are added to log this.
(4) Send PING ACKs in response to incoming calls to elicit a PING-RESPONSE
ACK from which RTT data can be calculated. The response also carries
other useful information.
(5) Expedite PING-RESPONSE ACK generation from sendmsg. If we're actively
using sendmsg, this allows us, under some circumstances, to avoid
having to rely on the background work item to run to generate this
ACK.
This requires ktime_sub_ms() to be added.
(6) Set the REQUEST-ACK flag on some DATA packets to elicit ACK-REQUESTED
ACKs from which RTT data can be calculated.
(7) Limit the use of pings and ACK requests for RTT determination.
Changes:
(V2) Don't use the C division operator for 64-bit division. One instance
should use do_div() and the other should be using nsecs_to_jiffies().
The last two patches got transposed, leading to an undefined symbol
in one of them.
Reported-by: kbuild test robot <lkp@intel.com>
====================
Signed-off-by: David S. Miller <davem@davemloft.net>
inode_change_ok() will be resposible for clearing capabilities and IMA
extended attributes and as such will need dentry. Give it as an argument
to inode_change_ok() instead of an inode. Also rename inode_change_ok()
to setattr_prepare() to better relect that it does also some
modifications in addition to checks.
Reviewed-by: Christoph Hellwig <hch@lst.de>
Signed-off-by: Jan Kara <jack@suse.cz>
When file permissions are modified via chmod(2) and the user is not in
the owning group or capable of CAP_FSETID, the setgid bit is cleared in
inode_change_ok(). Setting a POSIX ACL via setxattr(2) sets the file
permissions as well as the new ACL, but doesn't clear the setgid bit in
a similar way; this allows to bypass the check in chmod(2). Fix that.
References: CVE-2016-7097
Reviewed-by: Christoph Hellwig <hch@lst.de>
Reviewed-by: Jeff Layton <jlayton@redhat.com>
Signed-off-by: Jan Kara <jack@suse.cz>
Signed-off-by: Andreas Gruenbacher <agruenba@redhat.com>
A timer was used to restart after the bus-off state, leading to a
relatively large can_restart() executed in an interrupt context,
which in turn sets up pinctrl. When this happens during system boot,
there is a high probability of grabbing the pinctrl_list_mutex,
which is locked already by the probe() of other device, making the
kernel suspect a deadlock condition [1].
To resolve this issue, the restart_timer is replaced by a delayed
work.
[1] https://github.com/victronenergy/venus/issues/24
Signed-off-by: Sergei Miroshnichenko <sergeimir@emcraft.com>
Cc: linux-stable <stable@vger.kernel.org>
Signed-off-by: Marc Kleine-Budde <mkl@pengutronix.de>
Drivers must be ready to accept NULL from ptp_clock_register() if the
PTP clock subsystem is configured out.
This patch documents that and ensures that all drivers cope well
with a NULL return.
Signed-off-by: Nicolas Pitre <nico@linaro.org>
Reviewed-by: Eugenia Emantayev <eugenia@mellanox.com>
Acked-by: Richard Cochran <richardcochran@gmail.com>
Acked-by: Edward Cree <ecree@solarflare.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
This exports the functionality of extracting the tag from the payload,
without moving next vlan tag into hw accel tag.
Signed-off-by: Shmulik Ladkani <shmulik.ladkani@gmail.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Advanced JIT compilers and translators may want to use
eBPF verifier as a base for parsers or to perform custom
checks and validations.
Add ability for external users to invoke the verifier
and provide callbacks to be invoked for every intruction
checked. For now only add most basic callback for
per-instruction pre-interpretation checks is added. More
advanced users may also like to have per-instruction post
callback and state comparison callback.
Signed-off-by: Jakub Kicinski <jakub.kicinski@netronome.com>
Acked-by: Alexei Starovoitov <ast@kernel.org>
Signed-off-by: David S. Miller <davem@davemloft.net>
Move verifier's internal structures to a header file and
prefix their names with bpf_ to avoid potential namespace
conflicts. Those structures will soon be used by external
analyzers.
Signed-off-by: Jakub Kicinski <jakub.kicinski@netronome.com>
Acked-by: Alexei Starovoitov <ast@kernel.org>
Acked-by: Daniel Borkmann <daniel@iogearbox.net>
Signed-off-by: David S. Miller <davem@davemloft.net>
This patch adds hardware offload capability to cls_bpf classifier,
similar to what have been done with U32 and flower.
Signed-off-by: Jakub Kicinski <jakub.kicinski@netronome.com>
Acked-by: Daniel Borkmann <daniel@iogearbox.net>
Signed-off-by: David S. Miller <davem@davemloft.net>
Optimize RAID6 recovery functions to take advantage of
the 512-bit ZMM integer instructions introduced in AVX512.
AVX512 optimized recovery functions, which is simply based
on recov_avx2.c written by Jim Kukunas
This patch was tested and benchmarked before submission on
a hardware that has AVX512 flags to support such instructions
Cc: Jim Kukunas <james.t.kukunas@linux.intel.com>
Cc: H. Peter Anvin <hpa@zytor.com>
Cc: Fenghua Yu <fenghua.yu@intel.com>
Signed-off-by: Megha Dey <megha.dey@linux.intel.com>
Signed-off-by: Gayatri Kammela <gayatri.kammela@intel.com>
Reviewed-by: Fenghua Yu <fenghua.yu@intel.com>
Signed-off-by: Shaohua Li <shli@fb.com>
Optimize RAID6 gen_syndrom functions to take advantage of
the 512-bit ZMM integer instructions introduced in AVX512.
AVX512 optimized gen_syndrom functions, which is simply based
on avx2.c written by Yuanhan Liu and sse2.c written by hpa.
The patch was tested and benchmarked before submission on
a hardware that has AVX512 flags to support such instructions
Cc: H. Peter Anvin <hpa@zytor.com>
Cc: Jim Kukunas <james.t.kukunas@linux.intel.com>
Cc: Fenghua Yu <fenghua.yu@intel.com>
Signed-off-by: Megha Dey <megha.dey@linux.intel.com>
Signed-off-by: Gayatri Kammela <gayatri.kammela@intel.com>
Reviewed-by: Fenghua Yu <fenghua.yu@intel.com>
Signed-off-by: Shaohua Li <shli@fb.com>
For a host to access an Open-Channel SSD, it has to know its geometry,
so that it writes and reads at the appropriate device bounds.
Currently, the geometry information is kept within the kernel, and not
exported to user-space for consumption. This patch exposes the
configuration through sysfs and enables user-space libraries, such as
liblightnvm, to use the sysfs implementation to get the geometry of an
Open-Channel SSD.
The sysfs entries are stored within the device hierarchy, and can be
found using the "lightnvm" device type.
An example configuration looks like this:
/sys/class/nvme/
└── nvme0n1
├── capabilities: 3
├── device_mode: 1
├── erase_max: 1000000
├── erase_typ: 1000000
├── flash_media_type: 0
├── media_capabilities: 0x00000001
├── media_type: 0
├── multiplane: 0x00010101
├── num_blocks: 1022
├── num_channels: 1
├── num_luns: 4
├── num_pages: 64
├── num_planes: 1
├── page_size: 4096
├── prog_max: 100000
├── prog_typ: 100000
├── read_max: 10000
├── read_typ: 10000
├── sector_oob_size: 0
├── sector_size: 4096
├── media_manager: gennvm
├── ppa_format: 0x380830082808001010102008
├── vendor_opcode: 0
├── max_phys_secs: 64
└── version: 1
Signed-off-by: Simon A. F. Lund <slund@cnexlabs.com>
Signed-off-by: Matias Bjørling <m@bjorling.me>
Signed-off-by: Jens Axboe <axboe@fb.com>
LightNVM compatible device drivers does not have a method to expose
LightNVM specific sysfs entries.
To enable LightNVM sysfs entries to be exposed, lightnvm device
drivers require a struct device to attach it to. To allow both the
actual device driver and lightnvm sysfs entries to coexist, the device
driver tracks the lifetime of the nvm_dev structure.
This patch refactors NVMe and null_blk to handle the lifetime of struct
nvm_dev, which eliminates the need for struct gendisk when a lightnvm
compatible device is provided.
Signed-off-by: Matias Bjørling <m@bjorling.me>
Signed-off-by: Jens Axboe <axboe@fb.com>
Enable devices without a gendisk instance to register itself with blk-mq
and expose the associated multi-queue sysfs entries.
Signed-off-by: Matias Bjørling <m@bjorling.me>
Signed-off-by: Jens Axboe <axboe@fb.com>
This patch introduces an accessor which can be used
by the users of debugfs (drivers, fs, ...) to get the
original file_operations struct. It also removes the
REAL_FOPS_DEREF macro in file.c and converts the code
to use the public version.
Previously, REAL_FOPS_DEREF was only available within
the file.c of debugfs. But having a public getter
available for debugfs users is important as some
drivers (carl9170 and b43) use the pointer of the
original file_operations in conjunction with container_of()
within their debugfs implementations.
Reviewed-by: Nicolai Stange <nicstange@gmail.com>
Signed-off-by: Christian Lamparter <chunkeey@gmail.com>
Cc: stable <stable@vger.kernel.org> # 4.7+
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
This commit export two new fields in struct tcp_info:
tcpi_delivery_rate: The most recent goodput, as measured by
tcp_rate_gen(). If the socket is limited by the sending
application (e.g., no data to send), it reports the highest
measurement instead of the most recent. The unit is bytes per
second (like other rate fields in tcp_info).
tcpi_delivery_rate_app_limited: A boolean indicating if the goodput
was measured when the socket's throughput was limited by the
sending application.
This delivery rate information can be useful for applications that
want to know the current throughput the TCP connection is seeing,
e.g. adaptive bitrate video streaming. It can also be very useful for
debugging or troubleshooting.
Signed-off-by: Van Jacobson <vanj@google.com>
Signed-off-by: Neal Cardwell <ncardwell@google.com>
Signed-off-by: Yuchung Cheng <ycheng@google.com>
Signed-off-by: Nandita Dukkipati <nanditad@google.com>
Signed-off-by: Eric Dumazet <edumazet@google.com>
Signed-off-by: Soheil Hassas Yeganeh <soheil@google.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
This commit adds code to track whether the delivery rate represented
by each rate_sample was limited by the application.
Upon each transmit, we store in the is_app_limited field in the skb a
boolean bit indicating whether there is a known "bubble in the pipe":
a point in the rate sample interval where the sender was
application-limited, and did not transmit even though the cwnd and
pacing rate allowed it.
This logic marks the flow app-limited on a write if *all* of the
following are true:
1) There is less than 1 MSS of unsent data in the write queue
available to transmit.
2) There is no packet in the sender's queues (e.g. in fq or the NIC
tx queue).
3) The connection is not limited by cwnd.
4) There are no lost packets to retransmit.
The tcp_rate_check_app_limited() code in tcp_rate.c determines whether
the connection is application-limited at the moment. If the flow is
application-limited, it sets the tp->app_limited field. If the flow is
application-limited then that means there is effectively a "bubble" of
silence in the pipe now, and this silence will be reflected in a lower
bandwidth sample for any rate samples from now until we get an ACK
indicating this bubble has exited the pipe: specifically, until we get
an ACK for the next packet we transmit.
When we send every skb we record in scb->tx.is_app_limited whether the
resulting rate sample will be application-limited.
The code in tcp_rate_gen() checks to see when it is safe to mark all
known application-limited bubbles of silence as having exited the
pipe. It does this by checking to see when the delivered count moves
past the tp->app_limited marker. At this point it zeroes the
tp->app_limited marker, as all known bubbles are out of the pipe.
We make room for the tx.is_app_limited bit in the skb by borrowing a
bit from the in_flight field used by NV to record the number of bytes
in flight. The receive window in the TCP header is 16 bits, and the
max receive window scaling shift factor is 14 (RFC 1323). So the max
receive window offered by the TCP protocol is 2^(16+14) = 2^30. So we
only need 30 bits for the tx.in_flight used by NV.
Signed-off-by: Van Jacobson <vanj@google.com>
Signed-off-by: Neal Cardwell <ncardwell@google.com>
Signed-off-by: Yuchung Cheng <ycheng@google.com>
Signed-off-by: Nandita Dukkipati <nanditad@google.com>
Signed-off-by: Eric Dumazet <edumazet@google.com>
Signed-off-by: Soheil Hassas Yeganeh <soheil@google.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
This patch generates data delivery rate (throughput) samples on a
per-ACK basis. These rate samples can be used by congestion control
modules, and specifically will be used by TCP BBR in later patches in
this series.
Key state:
tp->delivered: Tracks the total number of data packets (original or not)
delivered so far. This is an already-existing field.
tp->delivered_mstamp: the last time tp->delivered was updated.
Algorithm:
A rate sample is calculated as (d1 - d0)/(t1 - t0) on a per-ACK basis:
d1: the current tp->delivered after processing the ACK
t1: the current time after processing the ACK
d0: the prior tp->delivered when the acked skb was transmitted
t0: the prior tp->delivered_mstamp when the acked skb was transmitted
When an skb is transmitted, we snapshot d0 and t0 in its control
block in tcp_rate_skb_sent().
When an ACK arrives, it may SACK and ACK some skbs. For each SACKed
or ACKed skb, tcp_rate_skb_delivered() updates the rate_sample struct
to reflect the latest (d0, t0).
Finally, tcp_rate_gen() generates a rate sample by storing
(d1 - d0) in rs->delivered and (t1 - t0) in rs->interval_us.
One caveat: if an skb was sent with no packets in flight, then
tp->delivered_mstamp may be either invalid (if the connection is
starting) or outdated (if the connection was idle). In that case,
we'll re-stamp tp->delivered_mstamp.
At first glance it seems t0 should always be the time when an skb was
transmitted, but actually this could over-estimate the rate due to
phase mismatch between transmit and ACK events. To track the delivery
rate, we ensure that if packets are in flight then t0 and and t1 are
times at which packets were marked delivered.
If the initial and final RTTs are different then one may be corrupted
by some sort of noise. The noise we see most often is sending gaps
caused by delayed, compressed, or stretched acks. This either affects
both RTTs equally or artificially reduces the final RTT. We approach
this by recording the info we need to compute the initial RTT
(duration of the "send phase" of the window) when we recorded the
associated inflight. Then, for a filter to avoid bandwidth
overestimates, we generalize the per-sample bandwidth computation
from:
bw = delivered / ack_phase_rtt
to the following:
bw = delivered / max(send_phase_rtt, ack_phase_rtt)
In large-scale experiments, this filtering approach incorporating
send_phase_rtt is effective at avoiding bandwidth overestimates due to
ACK compression or stretched ACKs.
Signed-off-by: Van Jacobson <vanj@google.com>
Signed-off-by: Neal Cardwell <ncardwell@google.com>
Signed-off-by: Yuchung Cheng <ycheng@google.com>
Signed-off-by: Nandita Dukkipati <nanditad@google.com>
Signed-off-by: Eric Dumazet <edumazet@google.com>
Signed-off-by: Soheil Hassas Yeganeh <soheil@google.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Count the number of packets that a TCP connection marks lost.
Congestion control modules can use this loss rate information for more
intelligent decisions about how fast to send.
Specifically, this is used in TCP BBR policer detection. BBR uses a
high packet loss rate as one signal in its policer detection and
policer bandwidth estimation algorithm.
The BBR policer detection algorithm cannot simply track retransmits,
because a retransmit can be (and often is) an indicator of packets
lost long, long ago. This is particularly true in a long CA_Loss
period that repairs the initial massive losses when a policer kicks
in.
Signed-off-by: Van Jacobson <vanj@google.com>
Signed-off-by: Neal Cardwell <ncardwell@google.com>
Signed-off-by: Yuchung Cheng <ycheng@google.com>
Signed-off-by: Nandita Dukkipati <nanditad@google.com>
Signed-off-by: Eric Dumazet <edumazet@google.com>
Signed-off-by: Soheil Hassas Yeganeh <soheil@google.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Refactor the TCP min_rtt code to reuse the new win_minmax library in
lib/win_minmax.c to simplify the TCP code.
This is a pure refactor: the functionality is exactly the same. We
just moved the windowed min code to make TCP easier to read and
maintain, and to allow other parts of the kernel to use the windowed
min/max filter code.
Signed-off-by: Van Jacobson <vanj@google.com>
Signed-off-by: Neal Cardwell <ncardwell@google.com>
Signed-off-by: Yuchung Cheng <ycheng@google.com>
Signed-off-by: Nandita Dukkipati <nanditad@google.com>
Signed-off-by: Eric Dumazet <edumazet@google.com>
Signed-off-by: Soheil Hassas Yeganeh <soheil@google.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
This commit introduces a generic library to estimate either the min or
max value of a time-varying variable over a recent time window. This
is code originally from Kathleen Nichols. The current form of the code
is from Van Jacobson.
A single struct minmax_sample will track the estimated windowed-max
value of the series if you call minmax_running_max() or the estimated
windowed-min value of the series if you call minmax_running_min().
Nearly equivalent code is already in place for minimum RTT estimation
in the TCP stack. This commit extracts that code and generalizes it to
handle both min and max. Moving the code here reduces the footprint
and complexity of the TCP code base and makes the filter generally
available for other parts of the codebase, including an upcoming TCP
congestion control module.
This library works well for time series where the measurements are
smoothly increasing or decreasing.
Signed-off-by: Van Jacobson <vanj@google.com>
Signed-off-by: Neal Cardwell <ncardwell@google.com>
Signed-off-by: Yuchung Cheng <ycheng@google.com>
Signed-off-by: Nandita Dukkipati <nanditad@google.com>
Signed-off-by: Eric Dumazet <edumazet@google.com>
Signed-off-by: Soheil Hassas Yeganeh <soheil@google.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
This work implements direct packet access for helpers and direct packet
write in a similar fashion as already available for XDP types via commits
4acf6c0b84 ("bpf: enable direct packet data write for xdp progs") and
6841de8b0d ("bpf: allow helpers access the packet directly"), and as a
complementary feature to the already available direct packet read for tc
(cls/act) programs.
For enabling this, we need to introduce two helpers, bpf_skb_pull_data()
and bpf_csum_update(). The first is generally needed for both, read and
write, because they would otherwise only be limited to the current linear
skb head. Usually, when the data_end test fails, programs just bail out,
or, in the direct read case, use bpf_skb_load_bytes() as an alternative
to overcome this limitation. If such data sits in non-linear parts, we
can just pull them in once with the new helper, retest and eventually
access them.
At the same time, this also makes sure the skb is uncloned, which is, of
course, a necessary condition for direct write. As this needs to be an
invariant for the write part only, the verifier detects writes and adds
a prologue that is calling bpf_skb_pull_data() to effectively unclone the
skb from the very beginning in case it is indeed cloned. The heuristic
makes use of a similar trick that was done in 233577a220 ("net: filter:
constify detection of pkt_type_offset"). This comes at zero cost for other
programs that do not use the direct write feature. Should a program use
this feature only sparsely and has read access for the most parts with,
for example, drop return codes, then such write action can be delegated
to a tail called program for mitigating this cost of potential uncloning
to a late point in time where it would have been paid similarly with the
bpf_skb_store_bytes() as well. Advantage of direct write is that the
writes are inlined whereas the helper cannot make any length assumptions
and thus needs to generate a call to memcpy() also for small sizes, as well
as cost of helper call itself with sanity checks are avoided. Plus, when
direct read is already used, we don't need to cache or perform rechecks
on the data boundaries (due to verifier invalidating previous checks for
helpers that change skb->data), so more complex programs using rewrites
can benefit from switching to direct read plus write.
For direct packet access to helpers, we save the otherwise needed copy into
a temp struct sitting on stack memory when use-case allows. Both facilities
are enabled via may_access_direct_pkt_data() in verifier. For now, we limit
this to map helpers and csum_diff, and can successively enable other helpers
where we find it makes sense. Helpers that definitely cannot be allowed for
this are those part of bpf_helper_changes_skb_data() since they can change
underlying data, and those that write into memory as this could happen for
packet typed args when still cloned. bpf_csum_update() helper accommodates
for the fact that we need to fixup checksum_complete when using direct write
instead of bpf_skb_store_bytes(), meaning the programs can use available
helpers like bpf_csum_diff(), and implement csum_add(), csum_sub(),
csum_block_add(), csum_block_sub() equivalents in eBPF together with the
new helper. A usage example will be provided for iproute2's examples/bpf/
directory.
Signed-off-by: Daniel Borkmann <daniel@iogearbox.net>
Acked-by: Alexei Starovoitov <ast@kernel.org>
Signed-off-by: David S. Miller <davem@davemloft.net>
Fix issue with poll_interval being not updated till the previous
interval expired.
Cc: Tony Lindgren <tony@atomide.com>
Cc: Liam Breck <liam@networkimprov.net>
Signed-off-by: Matt Ranostay <matt@ranostay.consulting>
Signed-off-by: Sebastian Reichel <sre@kernel.org>
There where still a few lingering references to pdata after commit
power: supply: sbs-battery: simplify DT parsing.
Remove pdata from struct·sbs_info and conditional checks to ser if this
was set from the i2c read / write functions.
Instead of call max in each function for incrementing poll_retry_count
do it once in the probe function.
Fixup null pointer dereference in to pdata in sbs_external_power_changed.
Change retry counts to u32 to avoid need for max.
Signed-off-by: Phil Reid <preid@electromag.com.au>
Signed-off-by: Sebastian Reichel <sre@kernel.org>
Switching iov_iter fault-in to multipages variants has exposed an old
bug in underlying fault_in_multipages_...(); they break if the range
passed to them wraps around. Normally access_ok() done by callers will
prevent such (and it's a guaranteed EFAULT - ERR_PTR() values fall into
such a range and they should not point to any valid objects).
However, on architectures where userland and kernel live in different
MMU contexts (e.g. s390) access_ok() is a no-op and on those a range
with a wraparound can reach fault_in_multipages_...().
Since any wraparound means EFAULT there, the fix is trivial - turn
those
while (uaddr <= end)
...
into
if (unlikely(uaddr > end))
return -EFAULT;
do
...
while (uaddr <= end);
Reported-by: Jan Stancek <jstancek@redhat.com>
Tested-by: Jan Stancek <jstancek@redhat.com>
Cc: stable@vger.kernel.org # v3.5+
Signed-off-by: Al Viro <viro@zeniv.linux.org.uk>
Signed-off-by: Linus Torvalds <torvalds@linux-foundation.org>
Currently the AER severity is being translated twice in the code flow for
PCIe errors. It is first translated in ghes_do_proc() before calling into
the AER driver. Then it is translated again when the AER driver calls
cper_print_aer(). This causes the severity that is used in
cper_print_aer() to be incorrect.
Remove the second translation that is in cper_print_aer() since this
function is already receiving the correct AER severity.
Signed-off-by: Tyler Baicar <tbaicar@codeaurora.org>
Signed-off-by: Bjorn Helgaas <bhelgaas@google.com>
Reviewed-by: Borislav Petkov <bp@suse.de>
PARISC was the only architecture which selected the BROKEN_RODATA config
option. Drop it and remove the special handling from init.h as well.
Signed-off-by: Helge Deller <deller@gmx.de>
This patch only reserves two CPU hotplug states for block/mq so the block tree
can apply the conversion patches.
Signed-off-by: Sebastian Andrzej Siewior <bigeasy@linutronix.de>
Cc: Peter Zijlstra <peterz@infradead.org>
Cc: Jens Axboe <axboe@kernel.dk>
Cc: rt@linutronix.de
Link: http://lkml.kernel.org/r/20160906170457.32393-20-bigeasy@linutronix.de
Signed-off-by: Thomas Gleixner <tglx@linutronix.de>
The insecure_elasticity setting is an ugly wart brought out by
users who need to insert duplicate objects (that is, distinct
objects with identical keys) into the same table.
In fact, those users have a much bigger problem. Once those
duplicate objects are inserted, they don't have an interface to
find them (unless you count the walker interface which walks
over the entire table).
Some users have resorted to doing a manual walk over the hash
table which is of course broken because they don't handle the
potential existence of multiple hash tables. The result is that
they will break sporadically when they encounter a hash table
resize/rehash.
This patch provides a way out for those users, at the expense
of an extra pointer per object. Essentially each object is now
a list of objects carrying the same key. The hash table will
only see the lists so nothing changes as far as rhashtable is
concerned.
To use this new interface, you need to insert a struct rhlist_head
into your objects instead of struct rhash_head. While the hash
table is unchanged, for type-safety you'll need to use struct
rhltable instead of struct rhashtable. All the existing interfaces
have been duplicated for rhlist, including the hash table walker.
One missing feature is nulls marking because AFAIK the only potential
user of it does not need duplicate objects. Should anyone need
this it shouldn't be too hard to add.
Signed-off-by: Herbert Xu <herbert@gondor.apana.org.au>
Acked-by: Thomas Graf <tgraf@suug.ch>
Signed-off-by: David S. Miller <davem@davemloft.net>
fanotify_get_response() calls fsnotify_remove_event() when it finds that
group is being released from fanotify_release() (bypass_perm is set).
However the event it removes need not be only in the group's notification
queue but it can have already moved to access_list (userspace read the
event before closing the fanotify instance fd) which is protected by a
different lock. Thus when fsnotify_remove_event() races with
fanotify_release() operating on access_list, the list can get corrupted.
Fix the problem by moving all the logic removing permission events from
the lists to one place - fanotify_release().
Fixes: 5838d4442b ("fanotify: fix double free of pending permission events")
Link: http://lkml.kernel.org/r/1473797711-14111-3-git-send-email-jack@suse.cz
Signed-off-by: Jan Kara <jack@suse.cz>
Reported-by: Miklos Szeredi <mszeredi@redhat.com>
Tested-by: Miklos Szeredi <mszeredi@redhat.com>
Reviewed-by: Miklos Szeredi <mszeredi@redhat.com>
Cc: <stable@vger.kernel.org>
Signed-off-by: Andrew Morton <akpm@linux-foundation.org>
Signed-off-by: Linus Torvalds <torvalds@linux-foundation.org>
Implement a function that can be called when a group is being shutdown
to stop queueing new events to the group. Fanotify will use this.
Fixes: 5838d4442b ("fanotify: fix double free of pending permission events")
Link: http://lkml.kernel.org/r/1473797711-14111-2-git-send-email-jack@suse.cz
Signed-off-by: Jan Kara <jack@suse.cz>
Reviewed-by: Miklos Szeredi <mszeredi@redhat.com>
Cc: <stable@vger.kernel.org>
Signed-off-by: Andrew Morton <akpm@linux-foundation.org>
Signed-off-by: Linus Torvalds <torvalds@linux-foundation.org>
Install the callbacks via the state machine.
[ tglx: Renamed the state to MIPS_SOC_PREPARE so it can be reused by other
SOCs ]
Signed-off-by: Sebastian Andrzej Siewior <bigeasy@linutronix.de>
Acked-by: Ralf Baechle <ralf@linux-mips.org>
Cc: linux-mips@linux-mips.org
Cc: Peter Zijlstra <peterz@infradead.org>
Cc: rt@linutronix.de
Link: http://lkml.kernel.org/r/20160906170457.32393-16-bigeasy@linutronix.de
Signed-off-by: Thomas Gleixner <tglx@linutronix.de>
Install the callbacks via the state machine.
This is just a temporary vehicle to keep the interface working for now,
It'll be replaced by the sysfs interface which allows to step through the
hotplug state machine step by step.
Signed-off-by: Sebastian Andrzej Siewior <bigeasy@linutronix.de>
Cc: Peter Zijlstra <peterz@infradead.org>
Cc: Akinobu Mita <akinobu.mita@gmail.com>
Cc: rt@linutronix.de
Link: http://lkml.kernel.org/r/20160906170457.32393-15-bigeasy@linutronix.de
Signed-off-by: Thomas Gleixner <tglx@linutronix.de>
Install the callbacks via the state machine. CPU-hotplug multinstance support
is used with the nocalls() version. Maybe parts of padata_alloc() could be
moved into the online callback so that we could invoke ->startup callback for
instance and drop get_online_cpus().
Signed-off-by: Sebastian Andrzej Siewior <bigeasy@linutronix.de>
Cc: Steffen Klassert <steffen.klassert@secunet.com>
Cc: Peter Zijlstra <peterz@infradead.org>
Cc: linux-crypto@vger.kernel.org
Cc: rt@linutronix.de
Link: http://lkml.kernel.org/r/20160906170457.32393-14-bigeasy@linutronix.de
Signed-off-by: Thomas Gleixner <tglx@linutronix.de>
Install the callbacks via the state machine. It uses the multi instance
infrastructure of the hotplug code to handle each interface.
virtscsi_set_affinity() is removed from virtscsi_init() because
virtscsi_cpu_notif_add() (the function which registers the instance) is invoked
right after it and the cpuhp_state_add_instance() functions invokes the startup
callback on all online CPUs.
The same thing can not be applied virtscsi_cpu_notif_remove() because
virtscsi_remove_vqs() invokes virtscsi_set_affinity() with affinity = false as
argument but the old CPU_DEAD state invoked the function with affinity = true
(which does not match the DEAD callback).
Signed-off-by: Sebastian Andrzej Siewior <bigeasy@linutronix.de>
Cc: "James E.J. Bottomley" <jejb@linux.vnet.ibm.com>
Cc: linux-scsi@vger.kernel.org
Cc: "Martin K. Petersen" <martin.petersen@oracle.com>
Cc: "Michael S. Tsirkin" <mst@redhat.com>
Cc: Peter Zijlstra <peterz@infradead.org>
Cc: virtualization@lists.linux-foundation.org
Cc: rt@linutronix.de
Link: http://lkml.kernel.org/r/20160906170457.32393-11-bigeasy@linutronix.de
Signed-off-by: Thomas Gleixner <tglx@linutronix.de>
Right now LSM_AUDIT_DATA_PATH type contains "struct path" in union "u"
of common_audit_data. This information is used to print path of file
at the same time it is also used to get to dentry and inode. And this
inode information is used to get to superblock and device and print
device information.
This does not work well for layered filesystems like overlay where dentry
contained in path is overlay dentry and not the real dentry of underlying
file system. That means inode retrieved from dentry is also overlay
inode and not the real inode.
SELinux helpers like file_path_has_perm() are doing checks on inode
retrieved from file_inode(). This returns the real inode and not the
overlay inode. That means we are doing check on real inode but for audit
purposes we are printing details of overlay inode and that can be
confusing while debugging.
Hence, introduce a new type LSM_AUDIT_DATA_FILE which carries file
information and inode retrieved is real inode using file_inode(). That
way right avc denied information is given to user.
For example, following is one example avc before the patch.
type=AVC msg=audit(1473360868.399:214): avc: denied { read open } for
pid=1765 comm="cat"
path="/root/.../overlay/container1/merged/readfile"
dev="overlay" ino=21443
scontext=unconfined_u:unconfined_r:test_overlay_client_t:s0:c10,c20
tcontext=unconfined_u:object_r:test_overlay_files_ro_t:s0
tclass=file permissive=0
It looks as follows after the patch.
type=AVC msg=audit(1473360017.388:282): avc: denied { read open } for
pid=2530 comm="cat"
path="/root/.../overlay/container1/merged/readfile"
dev="dm-0" ino=2377915
scontext=unconfined_u:unconfined_r:test_overlay_client_t:s0:c10,c20
tcontext=unconfined_u:object_r:test_overlay_files_ro_t:s0
tclass=file permissive=0
Notice that now dev information points to "dm-0" device instead of
"overlay" device. This makes it clear that check failed on underlying
inode and not on the overlay inode.
Signed-off-by: Vivek Goyal <vgoyal@redhat.com>
[PM: slight tweaks to the description to make checkpatch.pl happy]
Signed-off-by: Paul Moore <paul@paul-moore.com>
Currently, the layout driver selection code always chooses the first one
from the list. That's not really ideal however, as the server can send
the list of layout types in any order that it likes. It's up to the
client to select the best one for its needs.
This patch adds an ordered list of preferred driver types and has the
selection code sort the list of available layout drivers according to it.
Any unrecognized layout type is sorted to the end of the list.
For now, the order of preference is hardcoded, but it should be possible
to make this configurable in the future.
Signed-off-by: Jeff Layton <jlayton@redhat.com>
Reviewed-by: J. Bruce Fields <bfields@fieldses.org>
Signed-off-by: Anna Schumaker <Anna.Schumaker@Netapp.com>
The Version One default inline threshold is still 1KB. But allow
testing with thresholds up to 64KB.
This maximum is somewhat arbitrary. There's no fundamental
architectural limit I'm aware of, but it's good to keep the size of
Receive buffers reasonable. Now that Send can use a s/g list, a
Send buffer is only as large as each RPC requires. Receive buffers
are always the size of the inline threshold, however.
Signed-off-by: Chuck Lever <chuck.lever@oracle.com>
Signed-off-by: Anna Schumaker <Anna.Schumaker@Netapp.com>
Send an RDMA-CM private message on connect, and look for one during
a connection-established event.
Both sides can communicate their various implementation limits.
Implementations that don't support this sideband protocol ignore it.
Once the client knows the server's inline threshold maxima, it can
adjust the use of Reply chunks, and eliminate most use of Position
Zero Read chunks. Moderately-sized I/O can be done using a pure
inline RDMA Send instead of RDMA operations that require memory
registration.
Signed-off-by: Chuck Lever <chuck.lever@oracle.com>
Signed-off-by: Anna Schumaker <Anna.Schumaker@Netapp.com>
Introduce data structure used by both client and server to exchange
implementation details during RDMA/CM connection establishment.
This is an experimental out-of-band exchange between Linux
RPC-over-RDMA Version One implementations, replacing the deprecated
CCP (see RFC 5666bis). The purpose of this extension is to enable
prototyping of features that might be introduced in a subsequent
version of RPC-over-RDMA.
Suggested by Christoph Hellwig and Devesh Sharma.
Signed-off-by: Chuck Lever <chuck.lever@oracle.com>
Reviewed-by: Sagi Grimberg <sagi@grimberg.me>
Signed-off-by: Anna Schumaker <Anna.Schumaker@Netapp.com>
Currently there's a hidden and indirect mechanism for finding the
rpcrdma_req that goes with an rpc_rqst. It depends on getting from
the rq_buffer pointer in struct rpc_rqst to the struct
rpcrdma_regbuf that controls that buffer, and then to the struct
rpcrdma_req it goes with.
This was done back in the day to avoid the need to add a per-rqst
pointer or to alter the buf_free API when support for RPC-over-RDMA
was introduced.
I'm about to change the way regbuf's work to support larger inline
thresholds. Now is a good time to replace this indirect mechanism
with something that is more straightforward. I guess this should be
considered a clean up.
Signed-off-by: Chuck Lever <chuck.lever@oracle.com>
Signed-off-by: Anna Schumaker <Anna.Schumaker@Netapp.com>
For xprtrdma, the RPC Call and Reply buffers are involved in real
I/O operations.
To start with, the DMA direction of the I/O for a Call is opposite
that of a Reply.
In the current arrangement, the Reply buffer address is on a
four-byte alignment just past the call buffer. Would be friendlier
on some platforms if that was at a DMA cache alignment instead.
Because the current arrangement allocates a single memory region
which contains both buffers, the RPC Reply buffer often contains a
page boundary in it when the Call buffer is large enough (which is
frequent).
It would be a little nicer for setting up DMA operations (and
possible registration of the Reply buffer) if the two buffers were
separated, well-aligned, and contained as few page boundaries as
possible.
Now, I could just pad out the single memory region used for the pair
of buffers. But frequently that would mean a lot of unused space to
ensure the Reply buffer did not have a page boundary.
Add a separate pointer to rpc_rqst that points right to the RPC
Reply buffer. This makes no difference to xprtsock, but it will help
xprtrdma in subsequent patches.
Signed-off-by: Chuck Lever <chuck.lever@oracle.com>
Signed-off-by: Anna Schumaker <Anna.Schumaker@Netapp.com>
xprtrdma needs to allocate the Call and Reply buffers separately.
TBH, the reliance on using a single buffer for the pair of XDR
buffers is transport implementation-specific.
Instead of passing just the rq_buffer into the buf_free method, pass
the task structure and let buf_free take care of freeing both
XDR buffers at once.
There's a micro-optimization here. In the common case, both
xprt_release and the transport's buf_free method were checking if
rq_buffer was NULL. Now the check is done only once per RPC.
Signed-off-by: Chuck Lever <chuck.lever@oracle.com>
Signed-off-by: Anna Schumaker <Anna.Schumaker@Netapp.com>
xprtrdma needs to allocate the Call and Reply buffers separately.
TBH, the reliance on using a single buffer for the pair of XDR
buffers is transport implementation-specific.
Transports that want to allocate separate Call and Reply buffers
will ignore the "size" argument anyway. Don't bother passing it.
The buf_alloc method can't return two pointers. Instead, make the
method's return value an error code, and set the rq_buffer pointer
in the method itself.
This gives call_allocate an opportunity to terminate an RPC instead
of looping forever when a permanent problem occurs. If a request is
just bogus, or the transport is in a state where it can't allocate
resources for any request, there needs to be a way to kill the RPC
right there and not loop.
This immediately fixes a rare problem in the backchannel send path,
which loops if the server happens to send a CB request whose
call+reply size is larger than a page (which it shouldn't do yet).
One more issue: looks like xprt_inject_disconnect was incorrectly
placed in the failure path in call_allocate. It needs to be in the
success path, as it is for other call-sites.
Signed-off-by: Chuck Lever <chuck.lever@oracle.com>
Signed-off-by: Anna Schumaker <Anna.Schumaker@Netapp.com>
Clean up: there is some XDR initialization logic that is common
to the forward channel and backchannel. Move it to an XDR header
so it can be shared.
rpc_rqst::rq_buffer points to a buffer containing big-endian data.
Update its annotation as part of the clean up.
Signed-off-by: Chuck Lever <chuck.lever@oracle.com>
Signed-off-by: Anna Schumaker <Anna.Schumaker@Netapp.com>
Use a setup function to call into the NFS layer to test an rpc_xprt
for session trunking so as to not leak the rpc_xprt_switch into
the nfs layer.
Search for the address in the rpc_xprt_switch first so as not to
put an unnecessary EXCHANGE_ID on the wire.
Signed-off-by: Andy Adamson <andros@netapp.com>
Signed-off-by: Anna Schumaker <Anna.Schumaker@Netapp.com>
Give the NFS layer access to the rpc_xprt_switch_add_xprt function
Signed-off-by: Andy Adamson <andros@netapp.com>
Signed-off-by: Anna Schumaker <Anna.Schumaker@Netapp.com>
Give the NFS layer access to the xprt_switch_put function
Signed-off-by: Andy Adamson <andros@netapp.com>
Signed-off-by: Anna Schumaker <Anna.Schumaker@Netapp.com>
Current NFSv4.1/pNFS client assumes that MDS supports only one layout
type. While it's true for most existing servers, nevertheless, this can
be change in the near future.
For now, this patch just plumbs in the ability to track a list of
layouts in the fsinfo structure. The existing behavior of the client
is preserved, by having it just select the first entry in the list.
Signed-off-by: Tigran Mkrtchyan <tigran.mkrtchyan@desy.de>
Signed-off-by: Jeff Layton <jlayton@poochiereds.net>
Reviewed-by: J. Bruce Fields <bfields@fieldses.org>
Signed-off-by: Anna Schumaker <Anna.Schumaker@Netapp.com>
Add _nf_register_hooks() and _nf_unregister_hooks() calls which allow
caller to hold RTNL mutex.
Signed-off-by: Mahesh Bandewar <maheshb@google.com>
CC: Pablo Neira Ayuso <pablo@netfilter.org>
Signed-off-by: David S. Miller <davem@davemloft.net>
Add a new ndo to return statistics for offloaded operation.
Since there can be many different offloaded operation with many
stats types, the ndo gets an attribute id by which it knows which
stats are wanted. The ndo also gets a void pointer to be cast according
to the attribute id.
Signed-off-by: Nogah Frankel <nogahf@mellanox.com>
Signed-off-by: Jiri Pirko <jiri@mellanox.com>
Reviewed-by: Nikolay Aleksandrov <nikolay@cumulusnetworks.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Very similar to the existing dax_fault function, but instead of using
the get_block callback we rely on the iomap_ops vector from iomap.c.
That also avoids having to do two calls into the file system for write
faults.
Signed-off-by: Christoph Hellwig <hch@lst.de>
Reviewed-by: Ross Zwisler <ross.zwisler@linux.intel.com>
Signed-off-by: Dave Chinner <david@fromorbit.com>
This is a much simpler implementation of the DAX read/write path
that makes use of the iomap infrastructure. It does not try to
mirror the direct I/O calling conventions and thus doesn't have to
deal with i_dio_count or the end_io handler, but instead leaves
locking and filesystem-specific I/O completion to the caller.
Signed-off-by: Christoph Hellwig <hch@lst.de>
Reviewed-by: Ross Zwisler <ross.zwisler@linux.intel.com>
Signed-off-by: Dave Chinner <david@fromorbit.com>
Signed-off-by: Christoph Hellwig <hch@lst.de>
Reviewed-by: Ross Zwisler <ross.zwisler@linux.intel.com>
Signed-off-by: Dave Chinner <david@fromorbit.com>
Originally-From: Christoph Hellwig <hch@lst.de>
This function uses the iomap infrastructure to re-write all pages
in a given range. This is useful for doing a copy-up of COW ranges,
and might be useful for scrubbing in the future.
Signed-off-by: Christoph Hellwig <hch@lst.de>
Reviewed-by: Dave Chinner <dchinner@redhat.com>
Signed-off-by: Dave Chinner <david@fromorbit.com>
Pull SMP build fixlet from Thomas Gleixner:
"Add a missing include in cpuhotplug.h"
* 'smp-urgent-for-linus' of git://git.kernel.org/pub/scm/linux/kernel/git/tip/tip:
cpu/hotplug: Include linux/types.h in linux/cpuhotplug.h
Pull irq fixes from Thomas Gleixner:
"Two patches from Boris which address a potential deadlock in the atmel
irq chip driver"
* 'irq-urgent-for-linus' of git://git.kernel.org/pub/scm/linux/kernel/git/tip/tip:
irqchip/atmel-aic: Fix potential deadlock in ->xlate()
genirq: Provide irq_gc_{lock_irqsave,unlock_irqrestore}() helpers
... by turning it into what used to be multipages counterpart
Cc: stable@vger.kernel.org
Signed-off-by: Al Viro <viro@zeniv.linux.org.uk>
Signed-off-by: Linus Torvalds <torvalds@linux-foundation.org>
Again, there's no point in passing this in every time. Make it part of
struct sbitmap_queue and clean up the API.
Signed-off-by: Omar Sandoval <osandov@fb.com>
Signed-off-by: Jens Axboe <axboe@fb.com>
Allocating your own per-cpu allocation hint separately makes for an
awkward API. Instead, allocate the per-cpu hint as part of the struct
sbitmap_queue. There's no point for a struct sbitmap_queue without the
cache, but you can still use a bare struct sbitmap.
Signed-off-by: Omar Sandoval <osandov@fb.com>
Signed-off-by: Jens Axboe <axboe@fb.com>
This is a generally useful data structure, so make it available to
anyone else who might want to use it. It's also a nice cleanup
separating the allocation logic from the rest of the tag handling logic.
The code is behind a new Kconfig option, CONFIG_SBITMAP, which is only
selected by CONFIG_BLOCK for now.
This should be a complete noop functionality-wise.
Signed-off-by: Omar Sandoval <osandov@fb.com>
Signed-off-by: Jens Axboe <axboe@fb.com>
Major changes:
iwlwifi
* preparation for new a000 HW continues
* some DQA improvements
* add support for GMAC
* add support for 9460, 9270 and 9170 series
mwifiex
* support random MAC address for scanning
* add HT aggregation support for adhoc mode
* add custom regulatory domain support
* add manufacturing mode support via nl80211 testmode interface
bcma
* support BCM53573 series of wireless SoCs
bitfield.h
* add FIELD_PREP() and FIELD_GET() macros
mt7601u
* convert to use the new bitfield.h macros
brcmfmac
* add support for bcm4339 chip with modalias sdio:c00v02D0d4339
ath10k
* add nl80211 testmode support for 10.4 firmware
* hide kernel addresses from logs using %pK format specifier
* implement NAPI support
* enable peer stats by default
ath9k
* use ieee80211_tx_status_noskb where possible
wil6210
* extract firmware capabilities from the firmware file
ath6kl
* enable firmware crash dumps on the AR6004
ath-current is also merged to fix a conflict in ath10k.
-----BEGIN PGP SIGNATURE-----
Version: GnuPG v1.4.11 (GNU/Linux)
iQEcBAABAgAGBQJX2rF7AAoJEG4XJFUm622bD3EH/icZDT7vVxnb0VPP8jAScA4h
bMNrI3iFxnPohO8Rzp+edWSdxEZoxwrBVk/6BHXO9PHHZwPX7/b8/OOXmLWB2X1c
ffj1jt83RENcsZFvd5OJfDYxIq89uOkWybdD6nIUd3umKC9KeFOI5nCju31fEZrQ
ZptqvKGIV36bbx07K8Y/PQRL2SA6T+09WqvuljLHZD5hfPGZ+GWXV2p+HAm3Moos
iy6HUx5+pYfC+zlcmvJvL47Wxj+HppS/48ujyQ68DD2UkjOtF620YJjVy3o+njip
GNJtCgWFDp2ar3uvRP2BfBd9FtseDTKsKusxJQvNGoSR0ON+uGIzURCznQ+2PCM=
=FyXw
-----END PGP SIGNATURE-----
Merge tag 'wireless-drivers-next-for-davem-2016-09-15' of git://git.kernel.org/pub/scm/linux/kernel/git/kvalo/wireless-drivers-next
Kalle Valo says:
====================
wireless-drivers-next patches for 4.9
Major changes:
iwlwifi
* preparation for new a000 HW continues
* some DQA improvements
* add support for GMAC
* add support for 9460, 9270 and 9170 series
mwifiex
* support random MAC address for scanning
* add HT aggregation support for adhoc mode
* add custom regulatory domain support
* add manufacturing mode support via nl80211 testmode interface
bcma
* support BCM53573 series of wireless SoCs
bitfield.h
* add FIELD_PREP() and FIELD_GET() macros
mt7601u
* convert to use the new bitfield.h macros
brcmfmac
* add support for bcm4339 chip with modalias sdio:c00v02D0d4339
ath10k
* add nl80211 testmode support for 10.4 firmware
* hide kernel addresses from logs using %pK format specifier
* implement NAPI support
* enable peer stats by default
ath9k
* use ieee80211_tx_status_noskb where possible
wil6210
* extract firmware capabilities from the firmware file
ath6kl
* enable firmware crash dumps on the AR6004
ath-current is also merged to fix a conflict in ath10k.
====================
Signed-off-by: David S. Miller <davem@davemloft.net>
Add a new helper function pci_find_resource() that can be used to find out
whether a given resource (for example from a child device) is contained
within given PCI device's standard resources.
Signed-off-by: Mika Westerberg <mika.westerberg@linux.intel.com>
Acked-by: Bjorn Helgaas <bhelgaas@google.com>
Signed-off-by: Rafael J. Wysocki <rafael.j.wysocki@intel.com>
The new op is analogous to set_voltage_time_sel. It can be used by
regulators which don't have a table of discrete voltages. The function
returns the time for the regulator output voltage to stabilize after
being set to a new value, in microseconds. If the op is not set a
default implementation is used to calculate the delay.
This change also removes the ramp_delay calculation in the PWM
regulator, since the driver now uses the core code for the calculation
of the delay.
Signed-off-by: Matthias Kaehlcke <mka@chromium.org>
Signed-off-by: Mark Brown <broonie@kernel.org>
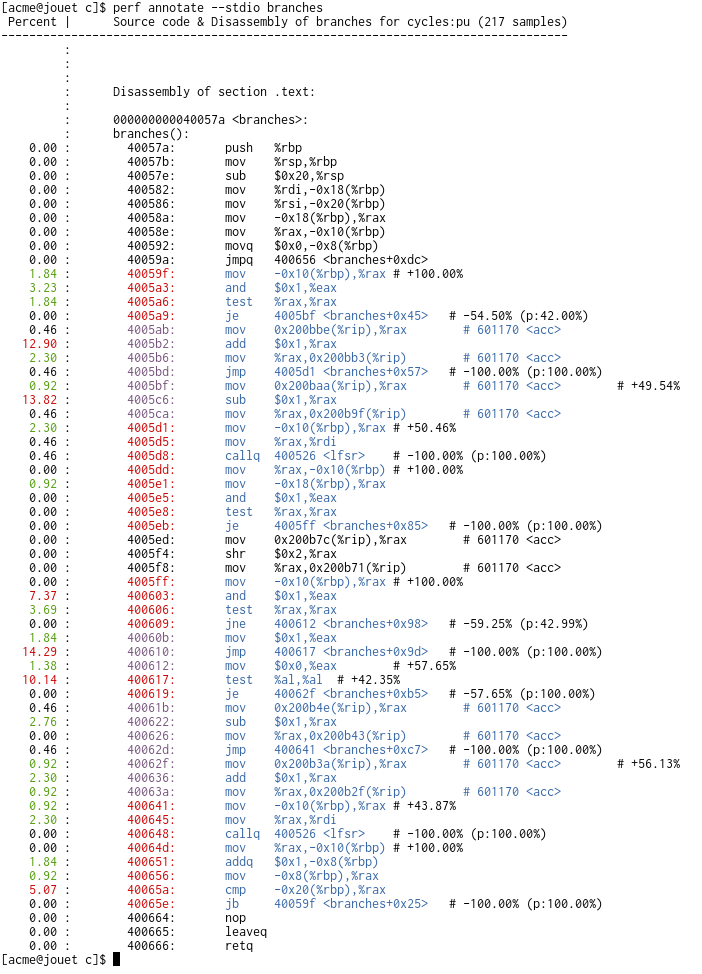{kind=link}