The big change is the addition of the hwlat tracer. It not only detects
SMIs, but also other latency that's caused by the hardware. I have detected
some latency from large boxes having bus contention.
-----BEGIN PGP SIGNATURE-----
Version: GnuPG v1
iQEcBAABAgAGBQJX9a77AAoJEKKk/i67LK/8UPEH/jcqMmOMhQYVQsNaJViA5uJM
SV96gaLCc9cxXY04Hf7vx8RkVIyIqTCCQZ+RVZt4RSeqpsB2IzZ1u0CNKs2Z0MTv
MdvQJoazRoDgVuPzKAsdAlDd0ykqHEFA5ayF3XDK4P2J97La+B4rQIqEiJX/aDrz
i0NQQFg2ZF46mXJXn4oXe6nmr6WnbiEduawVjd7JvgILJO2hojDicOTQlNG41Nys
68fOV8mLk0OL7sFRjySLGcbdbKhP2YbNhxILXl8geLgS9+CFZXkE8oTRjjy9IMNA
XrqbFLMWaRVv+Nig7bHIWKE8ZErC5WCYUw4LD2GTLMDx5AkAVLGFFp6TOiO4SG8=
=ke23
-----END PGP SIGNATURE-----
Merge tag 'trace-v4.9' of git://git.kernel.org/pub/scm/linux/kernel/git/rostedt/linux-trace
Pull tracing updates from Steven Rostedt:
"This release cycle is rather small. Just a few fixes to tracing.
The big change is the addition of the hwlat tracer. It not only
detects SMIs, but also other latency that's caused by the hardware. I
have detected some latency from large boxes having bus contention"
* tag 'trace-v4.9' of git://git.kernel.org/pub/scm/linux/kernel/git/rostedt/linux-trace:
tracing: Call traceoff trigger after event is recorded
ftrace/scripts: Add helper script to bisect function tracing problem functions
tracing: Have max_latency be defined for HWLAT_TRACER as well
tracing: Add NMI tracing in hwlat detector
tracing: Have hwlat trace migrate across tracing_cpumask CPUs
tracing: Add documentation for hwlat_detector tracer
tracing: Added hardware latency tracer
ftrace: Access ret_stack->subtime only in the function profiler
function_graph: Handle TRACE_BPUTS in print_graph_comment
tracing/uprobe: Drop isdigit() check in create_trace_uprobe
Pull perf updates from Ingo Molnar:
"The main kernel side changes were:
- uprobes enhancements (Masami Hiramatsu)
- Uncore group events enhancements (David Carrillo-Cisneros)
- x86 Intel: Add support for Skylake server uncore PMUs (Kan Liang)
- x86 Intel: LBR cleanups and enhancements, for better branch
annotation tracking (Peter Zijlstra)
- x86 Intel: Add support for PTWRITE and power event tracing
(Alexander Shishkin)
- ... various fixes, cleanups and smaller enhancements.
Lots of tooling changes - a couple of highlights:
- Support event group view with hierarchy mode in 'perf top' and
'perf report' (Namhyung Kim)
e.g.:
$ perf record -e '{cycles,instructions}' make
$ perf report --hierarchy --stdio
...
# Overhead Command / Shared Object / Symbol
# ...................... ..................................
...
25.74% 27.18%sh
19.96% 24.14%libc-2.24.so
9.55% 14.64%[.] __strcmp_sse2
1.54% 0.00%[.] __tfind
1.07% 1.13%[.] _int_malloc
0.95% 0.00%[.] __strchr_sse2
0.89% 1.39%[.] __tsearch
0.76% 0.00%[.] strlen
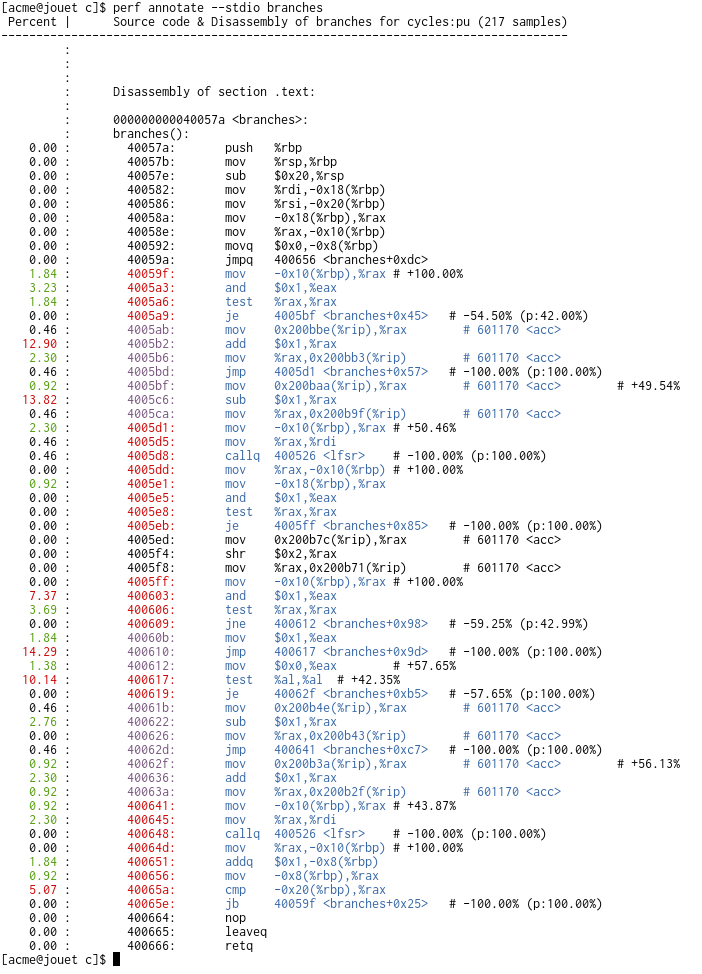
- Add branch stack / basic block info to 'perf annotate --stdio',
where for each branch, we add an asm comment after the instruction
with information on how often it was taken and predicted. See
example with color output at:
http://vger.kernel.org/~acme/perf/annotate_basic_blocks.png
(Peter Zijlstra)
- Add support for using symbols in address filters with Intel PT and
ARM CoreSight (hardware assisted tracing facilities) (Adrian
Hunter, Mathieu Poirier)
- Add support for interacting with Coresight PMU ETMs/PTMs, that are
IP blocks to perform hardware assisted tracing on a ARM CPU core
(Mathieu Poirier)
- Support generating cross arch probes, i.e. if you specify a vmlinux
file for different arch than the one in the host machine,
$ perf probe --definition function_name args
will generate the probe definition string needed to append to the
target machine /sys/kernel/debug/tracing/kprobes_events file, using
scripting (Masami Hiramatsu).
- Allow configuring the default 'perf report -s' sort order in
~/.perfconfig, for instance, "sym,dso" may be more fitting for
kernel developers. (Arnaldo Carvalho de Melo)
- ... plus lots of other changes, refactorings, features and fixes"
* 'perf-core-for-linus' of git://git.kernel.org/pub/scm/linux/kernel/git/tip/tip: (149 commits)
perf tests: Add dwarf unwind test for powerpc
perf probe: Match linkage name with mangled name
perf probe: Fix to cut off incompatible chars from group name
perf probe: Skip if the function address is 0
perf probe: Ignore the error of finding inline instance
perf intel-pt: Fix decoding when there are address filters
perf intel-pt: Enable decoder to handle TIP.PGD with missing IP
perf intel-pt: Read address filter from AUXTRACE_INFO event
perf intel-pt: Record address filter in AUXTRACE_INFO event
perf intel-pt: Add a helper function for processing AUXTRACE_INFO
perf intel-pt: Fix missing error codes processing auxtrace_info
perf intel-pt: Add support for recording the max non-turbo ratio
perf intel-pt: Fix snapshot overlap detection decoder errors
perf probe: Increase debug level of SDT debug messages
perf record: Add support for using symbols in address filters
perf symbols: Add dso__last_symbol()
perf record: Fix error paths
perf record: Rename label 'out_symbol_exit'
perf script: Fix vanished idle symbols
perf evsel: Add support for address filters
...
some issues. This contains one fix by me and one by Al. I'm sure that
he'll come up with more but for now I tested these patches and they
don't appear to have any negative impact on tracing.
-----BEGIN PGP SIGNATURE-----
Version: GnuPG v1
iQEcBAABAgAGBQJX6FvrAAoJEKKk/i67LK/8EuIH/Arf6vJidYsmbe57WQp8PU3I
bldem6ePj6zgZ2ZqPlSGCs1J2DcK4Bh3lPVxdx7rRKVWSd/Zoj+i83hvObusR8M7
Qs1G92bJTvvVO3aPfiN0GvKGdKfGn45L+j0BcBauiTRKqnj3PkhOhIP2/ks0ewSk
qeq7R3xxo/FDs26AHS69Hm0PIIw7btyhXNX4GB3Il7IIA5/nUknw3C+bjVj86tYX
R4iElcHEhplgoSjKuLgNIRZGUnEFtsm/fnohYXpHacLTUKNXnTDY230x/OKc1yyB
1vOfHS/y5s3XSJ1lcgSjYeNc51lK8NiDASaptZSUnOookKSAooUTFELNzpbc0sg=
=+Fr3
-----END PGP SIGNATURE-----
Merge tag 'trace-v4.8-rc7' of git://git.kernel.org/pub/scm/linux/kernel/git/rostedt/linux-trace
Pull tracefs fixes from Steven Rostedt:
"Al Viro has been looking at the tracefs code, and has pointed out some
issues. This contains one fix by me and one by Al. I'm sure that
he'll come up with more but for now I tested these patches and they
don't appear to have any negative impact on tracing"
* tag 'trace-v4.8-rc7' of git://git.kernel.org/pub/scm/linux/kernel/git/rostedt/linux-trace:
fix memory leaks in tracing_buffers_splice_read()
tracing: Move mutex to protect against resetting of seq data
The iter->seq can be reset outside the protection of the mutex. So can
reading of user data. Move the mutex up to the beginning of the function.
Fixes: d7350c3f45 ("tracing/core: make the read callbacks reentrants")
Cc: stable@vger.kernel.org # 2.6.30+
Reported-by: Al Viro <viro@ZenIV.linux.org.uk>
Signed-off-by: Steven Rostedt <rostedt@goodmis.org>
The hwlat tracer uses tr->max_latency, and if it's the only tracer enabled
that uses it, the build will fail. Add max_latency and its file when the
hwlat tracer is enabled.
Link: http://lkml.kernel.org/r/d6c3b7eb-ba95-1ffa-0453-464e1e24262a@infradead.org
Reported-by: Randy Dunlap <rdunlap@infradead.org>
Tested-by: Randy Dunlap <rdunlap@infradead.org>
Acked-by: Randy Dunlap <rdunlap@infradead.org>
Signed-off-by: Steven Rostedt <rostedt@goodmis.org>
The hardware latency tracer has been in the PREEMPT_RT patch for some time.
It is used to detect possible SMIs or any other hardware interruptions that
the kernel is unaware of. Note, NMIs may also be detected, but that may be
good to note as well.
The logic is pretty simple. It simply creates a thread that spins on a
single CPU for a specified amount of time (width) within a periodic window
(window). These numbers may be adjusted by their cooresponding names in
/sys/kernel/tracing/hwlat_detector/
The defaults are window = 1000000 us (1 second)
width = 500000 us (1/2 second)
The loop consists of:
t1 = trace_clock_local();
t2 = trace_clock_local();
Where trace_clock_local() is a variant of sched_clock().
The difference of t2 - t1 is recorded as the "inner" timestamp and also the
timestamp t1 - prev_t2 is recorded as the "outer" timestamp. If either of
these differences are greater than the time denoted in
/sys/kernel/tracing/tracing_thresh then it records the event.
When this tracer is started, and tracing_thresh is zero, it changes to the
default threshold of 10 us.
The hwlat tracer in the PREEMPT_RT patch was originally written by
Jon Masters. I have modified it quite a bit and turned it into a
tracer.
Based-on-code-by: Jon Masters <jcm@redhat.com>
Signed-off-by: Steven Rostedt <rostedt@goodmis.org>
Add README entries for kprobe-events and uprobe-events.
This allows user to check what options can be acceptable
for running kernel.
E.g. perf tools can choose correct types for the kernel.
Signed-off-by: Masami Hiramatsu <mhiramat@kernel.org>
Acked-by: Steven Rostedt <rostedt@goodmis.org>
Cc: Alexander Shishkin <alexander.shishkin@linux.intel.com>
Cc: Hemant Kumar <hemant@linux.vnet.ibm.com>
Cc: Naohiro Aota <naohiro.aota@hgst.com>
Cc: Peter Zijlstra <peterz@infradead.org>
Cc: Wang Nan <wangnan0@huawei.com>
Link: http://lkml.kernel.org/r/147151069524.12957.12957179170304055028.stgit@devbox
Signed-off-by: Arnaldo Carvalho de Melo <acme@redhat.com>
Commit 345ddcc882 ("ftrace: Have set_ftrace_pid use the bitmap like events
do") placed ftrace_init_tracefs into the instance creation, and encapsulated
the top level updating with an if conditional, as the top level only gets
updated at boot up. Unfortunately, this triggers section mismatch errors as
the init functions are called from a function that can be called later, and
the section mismatch logic is unaware of the if conditional that would
prevent it from happening at run time.
To make everyone happy, create a separate ftrace_init_tracefs_toplevel()
routine that only gets called by init functions, and this will be what calls
other init functions for the toplevel directory.
Link: http://lkml.kernel.org/r/20160704102139.19cbc0d9@gandalf.local.home
Reported-by: kbuild test robot <fengguang.wu@intel.com>
Reported-by: Arnd Bergmann <arnd@arndb.de>
Fixes: 345ddcc882 ("ftrace: Have set_ftrace_pid use the bitmap like events do")
Signed-off-by: Steven Rostedt <rostedt@goodmis.org>
# echo 1 > options/stacktrace
# echo 1 > events/sched/sched_switch/enable
# cat trace
<idle>-0 [002] d..2 1982.525169: <stack trace>
=> save_stack_trace
=> __ftrace_trace_stack
=> trace_buffer_unlock_commit_regs
=> event_trigger_unlock_commit
=> trace_event_buffer_commit
=> trace_event_raw_event_sched_switch
=> __schedule
=> schedule
=> schedule_preempt_disabled
=> cpu_startup_entry
=> start_secondary
The above shows that we are seeing 6 functions before ever making it to the
caller of the sched_switch event.
# echo stacktrace > events/sched/sched_switch/trigger
# cat trace
<idle>-0 [002] d..3 2146.335208: <stack trace>
=> trace_event_buffer_commit
=> trace_event_raw_event_sched_switch
=> __schedule
=> schedule
=> schedule_preempt_disabled
=> cpu_startup_entry
=> start_secondary
The stacktrace trigger isn't as bad, because it adds its own skip to the
stacktracing, but still has two events extra.
One issue is that if the stacktrace passes its own "regs" then there should
be no addition to the skip, as the regs will not include the functions being
called. This was an issue that was fixed by commit 7717c6be69 ("tracing:
Fix stacktrace skip depth in trace_buffer_unlock_commit_regs()" as adding
the skip number for kprobes made the probes not have any stack at all.
But since this is only an issue when regs is being used, a skip should be
added if regs is NULL. Now we have:
# echo 1 > options/stacktrace
# echo 1 > events/sched/sched_switch/enable
# cat trace
<idle>-0 [000] d..2 1297.676333: <stack trace>
=> __schedule
=> schedule
=> schedule_preempt_disabled
=> cpu_startup_entry
=> rest_init
=> start_kernel
=> x86_64_start_reservations
=> x86_64_start_kernel
# echo stacktrace > events/sched/sched_switch/trigger
# cat trace
<idle>-0 [002] d..3 1370.759745: <stack trace>
=> __schedule
=> schedule
=> schedule_preempt_disabled
=> cpu_startup_entry
=> start_secondary
And kprobes are not touched.
Reported-by: Peter Zijlstra <peterz@infradead.org>
Signed-off-by: Steven Rostedt <rostedt@goodmis.org>
Currently, the trace_printk code chooses which static buffer to use based
on what type of atomic context (NMI, IRQ, etc) it's in. Simplify the
code and make it more robust: simply count the nesting depth and choose
a buffer based on the current nesting depth.
The new code will only drop an event if we nest more than 4 deep,
and the old code was guaranteed to malfunction if that happened.
Link: http://lkml.kernel.org/r/07ab03aecfba25fcce8f9a211b14c9c5e2865c58.1464289095.git.luto@kernel.org
Acked-by: Namhyung Kim <namhyung@kernel.org>
Signed-off-by: Andy Lutomirski <luto@kernel.org>
Signed-off-by: Steven Rostedt <rostedt@goodmis.org>
Convert set_ftrace_pid to use the bitmap like set_event_pid does. This
allows for instances to use the pid filtering as well, and will allow for
function-fork option to set if the children of a traced function should be
traced or not.
Signed-off-by: Steven Rostedt <rostedt@goodmis.org>
The addition of PIDs into a pid_list via the write operation of
set_event_pid is a bit complex. The same operation will be needed for
function tracing pids. Move the code into its own generic function in
trace.c, so that we can avoid duplication of this code.
Signed-off-by: Steven Rostedt <rostedt@goodmis.org>
To allow other aspects of ftrace to use the pid_list logic, we need to reuse
the seq_file functions. Making the generic part into functions that can be
called by other files will help in this regard.
Signed-off-by: Steven Rostedt <rostedt@goodmis.org>
As the filtered_pid functions are going to be used by function tracer as
well as trace_events, move the code into the generic trace.c file.
The functions moved are:
trace_find_filtered_pid()
trace_ignore_this_task()
trace_filter_add_remove_task()
Kernel Doc text was also added.
Signed-off-by: Steven Rostedt <rostedt@goodmis.org>
Filtering of events requires the data to be written to the ring buffer
before it can be decided to filter or not. This is because the parameters of
the filter are based on the result that is written to the ring buffer and
not on the parameters that are passed into the trace functions.
The ftrace ring buffer is optimized for writing into the ring buffer and
committing. The discard procedure used when filtering decides the event
should be discarded is much more heavy weight. Thus, using a temporary
filter when filtering events can speed things up drastically.
Without a temp buffer we have:
# trace-cmd start -p nop
# perf stat -r 10 hackbench 50
0.790706626 seconds time elapsed ( +- 0.71% )
# trace-cmd start -e all
# perf stat -r 10 hackbench 50
1.566904059 seconds time elapsed ( +- 0.27% )
# trace-cmd start -e all -f 'common_preempt_count==20'
# perf stat -r 10 hackbench 50
1.690598511 seconds time elapsed ( +- 0.19% )
# trace-cmd start -e all -f 'common_preempt_count!=20'
# perf stat -r 10 hackbench 50
1.707486364 seconds time elapsed ( +- 0.30% )
The first run above is without any tracing, just to get a based figure.
hackbench takes ~0.79 seconds to run on the system.
The second run enables tracing all events where nothing is filtered. This
increases the time by 100% and hackbench takes 1.57 seconds to run.
The third run filters all events where the preempt count will equal "20"
(this should never happen) thus all events are discarded. This takes 1.69
seconds to run. This is 10% slower than just committing the events!
The last run enables all events and filters where the filter will commit all
events, and this takes 1.70 seconds to run. The filtering overhead is
approximately 10%. Thus, the discard and commit of an event from the ring
buffer may be about the same time.
With this patch, the numbers change:
# trace-cmd start -p nop
# perf stat -r 10 hackbench 50
0.778233033 seconds time elapsed ( +- 0.38% )
# trace-cmd start -e all
# perf stat -r 10 hackbench 50
1.582102692 seconds time elapsed ( +- 0.28% )
# trace-cmd start -e all -f 'common_preempt_count==20'
# perf stat -r 10 hackbench 50
1.309230710 seconds time elapsed ( +- 0.22% )
# trace-cmd start -e all -f 'common_preempt_count!=20'
# perf stat -r 10 hackbench 50
1.786001924 seconds time elapsed ( +- 0.20% )
The first run is again the base with no tracing.
The second run is all tracing with no filtering. It is a little slower, but
that may be well within the noise.
The third run shows that discarding all events only took 1.3 seconds. This
is a speed up of 23%! The discard is much faster than even the commit.
The one downside is shown in the last run. Events that are not discarded by
the filter will take longer to add, this is due to the extra copy of the
event.
Cc: Alexei Starovoitov <ast@kernel.org>
Signed-off-by: Steven Rostedt <rostedt@goodmis.org>
There's no real difference between trace_buffer_unlock_commit() and
trace_buffer_unlock_commit_regs() except that the former passes NULL to
ftrace_stack_trace() instead of regs. Have the former be a static inline of
the latter which passes NULL for regs.
Signed-off-by: Steven Rostedt <rostedt@goodmis.org>
The functions trace_buffer_unlock_commit() and the _regs() version are only
used within the kernel/trace directory. Move them to the local header and
remove the export as well.
Signed-off-by: Steven Rostedt <rostedt@goodmis.org>
The function filter_check_discard() is small and only called by one user,
its code can be folded into that one caller and make the code a bit less
comlplex.
Signed-off-by: Steven Rostedt <rostedt@goodmis.org>
Nothing outside of the tracing directory calls filter_check_discard() or
check_filter_check_discard(). They should not be called by modules. Move
their prototypes into the local tracing header and remove their
EXPORT_SYMBOL() macros.
Signed-off-by: Steven Rostedt <rostedt@goodmis.org>
With the following code snippet:
...
char buf[64];
...
if (copy_from_user(&buf, ubuf, cnt))
...
Even though the value of "&buf" equals "buf", but there is no need
to get the address of the "buf" again. Use "buf" instead of "&buf".
Link: http://lkml.kernel.org/r/20160418152329.18b72bea@debian
Signed-off-by: Wang Xiaoqiang <wangxq10@lzu.edu.cn>
Signed-off-by: Steven Rostedt <rostedt@goodmis.org>
As the event-fork option requires doing work when enabled and disabled, it
can not be passed down to created instances. The instance must clear this
flag when it is created, and must clear it when its removed.
As more options may be created with this need, a macro ZEROED_TRACE_FLAGS is
created that holds the flags that must not be inherited by the top level
instance, and must be cleared on removal of instances.
Signed-off-by: Steven Rostedt <rostedt@goodmis.org>
Allow users to define 'named' hist triggers. All triggers created
with the same 'name=xxx' option will update the same shared histogram
data.
This expands the hist trigger syntax from this:
# echo hist:keys=xxx ... [ if filter] > event/trigger
to this:
# echo hist:name=xxx:keys=xxx ... [ if filter] > event/trigger
Named histograms must use a 'compatible' set of keys and values, which
means each event added to a set of named triggers must have the same
names and types.
Reading the 'hist' file of any of the participating events will
produce the same output as any other participating event, which is to
be expected since they share the same data.
Link: http://lkml.kernel.org/r/1dbc84ee3322a75daaf5b3ef1d0cc0a2fb682fc7.1457029949.git.tom.zanussi@linux.intel.com
Signed-off-by: Tom Zanussi <tom.zanussi@linux.intel.com>
Tested-by: Masami Hiramatsu <masami.hiramatsu.pt@hitachi.com>
Reviewed-by: Namhyung Kim <namhyung@kernel.org>
Signed-off-by: Steven Rostedt <rostedt@goodmis.org>
Allow users to define any number of hist triggers per trace event.
Any number of hist triggers may be added for a given event, which may
differ by key, value, or filter.
Reading the event's 'hist' file will display the output of all the
hist triggers defined on an event concatenated in the order they were
defined.
Link: http://lkml.kernel.org/r/48a0c8dd34c344571de880fb35e211c6d9a28961.1457029949.git.tom.zanussi@linux.intel.com
Signed-off-by: Tom Zanussi <tom.zanussi@linux.intel.com>
Tested-by: Masami Hiramatsu <masami.hiramatsu.pt@hitachi.com>
Reviewed-by: Namhyung Kim <namhyung@kernel.org>
Signed-off-by: Steven Rostedt <rostedt@goodmis.org>
Similar to enable_event/disable_event triggers, these triggers enable
and disable the aggregation of events into maps rather than enabling
and disabling their writing into the trace buffer.
They can be used to automatically start and stop hist triggers based
on a matching filter condition.
If there's a paused hist trigger on system:event, the following would
start it when the filter condition was hit:
# echo enable_hist:system:event [ if filter] > event/trigger
And the following would disable a running system:event hist trigger:
# echo disable_hist:system:event [ if filter] > event/trigger
See Documentation/trace/events.txt for real examples.
Link: http://lkml.kernel.org/r/f812f086e52c8b7c8ad5443487375e03c96a601f.1457029949.git.tom.zanussi@linux.intel.com
Signed-off-by: Tom Zanussi <tom.zanussi@linux.intel.com>
Tested-by: Masami Hiramatsu <masami.hiramatsu.pt@hitachi.com>
Reviewed-by: Namhyung Kim <namhyung@kernel.org>
Signed-off-by: Steven Rostedt <rostedt@goodmis.org>
It's often useful to be able to use a stacktrace as a hash key, for
keeping a count of the number of times a particular call path resulted
in a trace event, for instance. Add a special key named 'stacktrace'
which can be used as key in a 'keys=' param for this purpose:
# echo hist:keys=stacktrace ... \
[ if filter] > event/trigger
Link: http://lkml.kernel.org/r/87515e90b3785232a874a12156174635a348edb1.1457029949.git.tom.zanussi@linux.intel.com
Signed-off-by: Tom Zanussi <tom.zanussi@linux.intel.com>
Tested-by: Masami Hiramatsu <masami.hiramatsu.pt@hitachi.com>
Reviewed-by: Namhyung Kim <namhyung@kernel.org>
Signed-off-by: Steven Rostedt <rostedt@goodmis.org>
Allow users to have syscall id fields displayed as syscall names in
the output by appending '.syscall' to field names:
# echo hist:keys=aaa.syscall ... \
[ if filter] > event/trigger
Link: http://lkml.kernel.org/r/2bab1e59933d76a14b545bd2e02f80b8b08ac4d3.1457029949.git.tom.zanussi@linux.intel.com
Signed-off-by: Tom Zanussi <tom.zanussi@linux.intel.com>
Tested-by: Masami Hiramatsu <masami.hiramatsu.pt@hitachi.com>
Reviewed-by: Namhyung Kim <namhyung@kernel.org>
Signed-off-by: Steven Rostedt <rostedt@goodmis.org>
Allow users to have common_pid field values displayed as program names
in the output by appending '.execname' to a common_pid field name:
# echo hist:keys=common_pid.execname ... \
[ if filter] > event/trigger
Link: http://lkml.kernel.org/r/e172e81f10f5b8d1f08450e3763c850f39fbf698.1457029949.git.tom.zanussi@linux.intel.com
Signed-off-by: Tom Zanussi <tom.zanussi@linux.intel.com>
Tested-by: Masami Hiramatsu <masami.hiramatsu.pt@hitachi.com>
Reviewed-by: Namhyung Kim <namhyung@kernel.org>
Signed-off-by: Steven Rostedt <rostedt@goodmis.org>
Allow users to have address fields displayed as symbols in the output
by appending '.sym' or 'sym-offset' to field names:
# echo hist:keys=aaa.sym,bbb.sym-offset ... \
[ if filter] > event/trigger
Link: http://lkml.kernel.org/r/87d4935821491c0275513f0fbfb9bab8d3d3f079.1457029949.git.tom.zanussi@linux.intel.com
Signed-off-by: Tom Zanussi <tom.zanussi@linux.intel.com>
Tested-by: Masami Hiramatsu <masami.hiramatsu.pt@hitachi.com>
Reviewed-by: Namhyung Kim <namhyung@kernel.org>
Signed-off-by: Steven Rostedt <rostedt@goodmis.org>
Allow users to have numeric fields displayed as hex values in the
output by appending '.hex' to field names:
# echo hist:keys=aaa,bbb.hex:vals=ccc.hex ... \
[ if filter] > event/trigger
Link: http://lkml.kernel.org/r/67bd431edda2af5798d7694818f7e8d71b6b3463.1457029949.git.tom.zanussi@linux.intel.com
Signed-off-by: Tom Zanussi <tom.zanussi@linux.intel.com>
Tested-by: Masami Hiramatsu <masami.hiramatsu.pt@hitachi.com>
Reviewed-by: Namhyung Kim <namhyung@kernel.org>
Signed-off-by: Steven Rostedt <rostedt@goodmis.org>
Allow users to append 'clear' to an existing trigger in order to have
the hash table cleared.
This expands the hist trigger syntax from this:
# echo hist:keys=xxx:vals=yyy:sort=zzz.descending:pause/cont \
[ if filter] >> event/trigger
to this:
# echo hist:keys=xxx:vals=yyy:sort=zzz.descending:pause/cont/clear \
[ if filter] >> event/trigger
Link: http://lkml.kernel.org/r/ae15dd0d9b2f7af07a37c1ff682063e2dbcdf160.1457029949.git.tom.zanussi@linux.intel.com
Signed-off-by: Tom Zanussi <tom.zanussi@linux.intel.com>
Tested-by: Masami Hiramatsu <masami.hiramatsu.pt@hitachi.com>
Reviewed-by: Namhyung Kim <namhyung@kernel.org>
Signed-off-by: Steven Rostedt <rostedt@goodmis.org>
Allow users to append 'pause' or 'continue' to an existing trigger in
order to have it paused or to have a paused trace continue.
This expands the hist trigger syntax from this:
# echo hist:keys=xxx:vals=yyy:sort=zzz.descending \
[ if filter] >> event/trigger
to this:
# echo hist:keys=xxx:vals=yyy:sort=zzz.descending:pause or cont \
[ if filter] >> event/trigger
Link: http://lkml.kernel.org/r/b672a92c14702cb924cdf6fc27ea1809bed04907.1457029949.git.tom.zanussi@linux.intel.com
Signed-off-by: Tom Zanussi <tom.zanussi@linux.intel.com>
Tested-by: Masami Hiramatsu <masami.hiramatsu.pt@hitachi.com>
Reviewed-by: Namhyung Kim <namhyung@kernel.org>
Signed-off-by: Steven Rostedt <rostedt@goodmis.org>
Allow users to specify keys and/or values to sort on. With this
addition, keys and values specified using the 'keys=' and 'vals='
keywords can be used to sort the hist trigger output via a new 'sort='
keyword. If multiple sort keys are specified, the output will be
sorted using the second key as a secondary sort key, etc. The default
sort order is ascending; if the user wants a different sort order,
'.descending' can be appended to the specific sort key. Before this
addition, output was always sorted by 'hitcount' in ascending order.
This expands the hist trigger syntax from this:
# echo hist:keys=xxx:vals=yyy \
[ if filter] > event/trigger
to this:
# echo hist:keys=xxx:vals=yyy:sort=zzz.descending \
[ if filter] > event/trigger
Link: http://lkml.kernel.org/r/b30a41db66ba486979c4f987aff5fab500ea53b3.1457029949.git.tom.zanussi@linux.intel.com
Signed-off-by: Tom Zanussi <tom.zanussi@linux.intel.com>
Tested-by: Masami Hiramatsu <masami.hiramatsu.pt@hitachi.com>
Reviewed-by: Namhyung Kim <namhyung@kernel.org>
Signed-off-by: Steven Rostedt <rostedt@goodmis.org>
Allow users to specify multiple trace event fields to use in keys by
allowing multiple fields in the 'keys=' keyword. With this addition,
any unique combination of any of the fields named in the 'keys'
keyword will result in a new entry being added to the hash table.
Link: http://lkml.kernel.org/r/0cfa24e6ac3b0dcece7737d94aa1f322ae3afc4b.1457029949.git.tom.zanussi@linux.intel.com
Signed-off-by: Tom Zanussi <tom.zanussi@linux.intel.com>
Tested-by: Masami Hiramatsu <masami.hiramatsu.pt@hitachi.com>
Reviewed-by: Namhyung Kim <namhyung@kernel.org>
Signed-off-by: Steven Rostedt <rostedt@goodmis.org>
Allow users to specify trace event fields to use in aggregated sums
via a new 'vals=' keyword. Before this addition, the only aggregated
sum supported was the implied value 'hitcount'. With this addition,
'hitcount' is also supported as an explicit value field, as is any
numeric trace event field.
This expands the hist trigger syntax from this:
# echo hist:keys=xxx [ if filter] > event/trigger
to this:
# echo hist:keys=xxx:vals=yyy [ if filter] > event/trigger
Link: http://lkml.kernel.org/r/2a5d1adb5ba6c65d7bb2148e379f2fed47f29a68.1457029949.git.tom.zanussi@linux.intel.com
Signed-off-by: Tom Zanussi <tom.zanussi@linux.intel.com>
Tested-by: Masami Hiramatsu <masami.hiramatsu.pt@hitachi.com>
Reviewed-by: Namhyung Kim <namhyung@kernel.org>
Signed-off-by: Steven Rostedt <rostedt@goodmis.org>
'hist' triggers allow users to continually aggregate trace events,
which can then be viewed afterwards by simply reading a 'hist' file
containing the aggregation in a human-readable format.
The basic idea is very simple and boils down to a mechanism whereby
trace events, rather than being exhaustively dumped in raw form and
viewed directly, are automatically 'compressed' into meaningful tables
completely defined by the user.
This is done strictly via single-line command-line commands and
without the aid of any kind of programming language or interpreter.
A surprising number of typical use cases can be accomplished by users
via this simple mechanism. In fact, a large number of the tasks that
users typically do using the more complicated script-based tracing
tools, at least during the initial stages of an investigation, can be
accomplished by simply specifying a set of keys and values to be used
in the creation of a hash table.
The Linux kernel trace event subsystem happens to provide an extensive
list of keys and values ready-made for such a purpose in the form of
the event format files associated with each trace event. By simply
consulting the format file for field names of interest and by plugging
them into the hist trigger command, users can create an endless number
of useful aggregations to help with investigating various properties
of the system. See Documentation/trace/events.txt for examples.
hist triggers are implemented on top of the existing event trigger
infrastructure, and as such are consistent with the existing triggers
from a user's perspective as well.
The basic syntax follows the existing trigger syntax. Users start an
aggregation by writing a 'hist' trigger to the event of interest's
trigger file:
# echo hist:keys=xxx [ if filter] > event/trigger
Once a hist trigger has been set up, by default it continually
aggregates every matching event into a hash table using the event key
and a value field named 'hitcount'.
To view the aggregation at any point in time, simply read the 'hist'
file in the same directory as the 'trigger' file:
# cat event/hist
The detailed syntax provides additional options for user control, and
is described exhaustively in Documentation/trace/events.txt and in the
virtual tracing/README file in the tracing subsystem.
Link: http://lkml.kernel.org/r/72d263b5e1853fe9c314953b65833c3aa75479f2.1457029949.git.tom.zanussi@linux.intel.com
Signed-off-by: Tom Zanussi <tom.zanussi@linux.intel.com>
Tested-by: Masami Hiramatsu <masami.hiramatsu.pt@hitachi.com>
Reviewed-by: Namhyung Kim <namhyung@kernel.org>
Signed-off-by: Steven Rostedt <rostedt@goodmis.org>
Add the infrastructure needed to have the PIDs in set_event_pid to
automatically add PIDs of the children of the tasks that have their PIDs in
set_event_pid. This will also remove PIDs from set_event_pid when a task
exits
This is implemented by adding hooks into the fork and exit tracepoints. On
fork, the PIDs are added to the list, and on exit, they are removed.
Add a new option called event_fork that when set, PIDs in set_event_pid will
automatically get their children PIDs added when they fork, as well as any
task that exits will have its PID removed from set_event_pid.
This works for instances as well.
Signed-off-by: Steven Rostedt <rostedt@goodmis.org>
Some visible changes:
A new flag was added to distinguish traces done in NMI context.
Preempt tracer now shows functions where preemption is disabled but
interrupts are still enabled.
Other notes:
Updates were done to function tracing to allow better performance
with perf.
Infrastructure code has been added to allow for a new histogram
feature for recording live trace event histograms that can be
configured by simple user commands. The feature itself was just
finished, but needs a round in linux-next before being pulled.
This only includes some infrastructure changes that will be needed.
-----BEGIN PGP SIGNATURE-----
Version: GnuPG v1
iQEcBAABAgAGBQJW8/WPAAoJEKKk/i67LK/8wrAH/j2gU9ZfjVxTu8068TBGWRJP
yvvzq0cK5evB3dsVuUmKKRfU52nSv4J1WcFF569X0RulSLylR0dHlcxFJMn4kkgR
bm0AHRrqOf87ub3VimcpG146iVQij37l5A0SRoFbvSPLQx1KUW18v99x41Ji8dv6
oWXRc6/YhdzEE7l0nUsVjmScQ4b2emsems3cxZzXOY+nRJsiim6i+VaDeatdyey1
csLVqtRCs+x62TVtxG3+GhcLdRoPRbnHAGzrKDFIn1SrQaRXCc54wN5d2hWxjgNI
1laOwaj070lnJiWfBLIP/K+lx+VKRx5/O0rKZX35foLUTqJJKSyjAbKXuMCcSAM=
=2h2K
-----END PGP SIGNATURE-----
Merge tag 'trace-v4.6' of git://git.kernel.org/pub/scm/linux/kernel/git/rostedt/linux-trace
Pull tracing updates from Steven Rostedt:
"Nothing major this round. Mostly small clean ups and fixes.
Some visible changes:
- A new flag was added to distinguish traces done in NMI context.
- Preempt tracer now shows functions where preemption is disabled but
interrupts are still enabled.
Other notes:
- Updates were done to function tracing to allow better performance
with perf.
- Infrastructure code has been added to allow for a new histogram
feature for recording live trace event histograms that can be
configured by simple user commands. The feature itself was just
finished, but needs a round in linux-next before being pulled.
This only includes some infrastructure changes that will be needed"
* tag 'trace-v4.6' of git://git.kernel.org/pub/scm/linux/kernel/git/rostedt/linux-trace: (22 commits)
tracing: Record and show NMI state
tracing: Fix trace_printk() to print when not using bprintk()
tracing: Remove redundant reset per-CPU buff in irqsoff tracer
x86: ftrace: Fix the misleading comment for arch/x86/kernel/ftrace.c
tracing: Fix crash from reading trace_pipe with sendfile
tracing: Have preempt(irqs)off trace preempt disabled functions
tracing: Fix return while holding a lock in register_tracer()
ftrace: Use kasprintf() in ftrace_profile_tracefs()
ftrace: Update dynamic ftrace calls only if necessary
ftrace: Make ftrace_hash_rec_enable return update bool
tracing: Fix typoes in code comment and printk in trace_nop.c
tracing, writeback: Replace cgroup path to cgroup ino
tracing: Use flags instead of bool in trigger structure
tracing: Add an unreg_all() callback to trigger commands
tracing: Add needs_rec flag to event triggers
tracing: Add a per-event-trigger 'paused' field
tracing: Add get_syscall_name()
tracing: Add event record param to trigger_ops.func()
tracing: Make event trigger functions available
tracing: Make ftrace_event_field checking functions available
...
Use the more common logging method with the eventual goal of removing
pr_warning altogether.
Miscellanea:
- Realign arguments
- Coalesce formats
- Add missing space between a few coalesced formats
Signed-off-by: Joe Perches <joe@perches.com>
Acked-by: Rafael J. Wysocki <rafael.j.wysocki@intel.com> [kernel/power/suspend.c]
Signed-off-by: Andrew Morton <akpm@linux-foundation.org>
Signed-off-by: Linus Torvalds <torvalds@linux-foundation.org>
The latency tracer format has a nice column to indicate IRQ state, but
this is not able to tell us about NMI state.
When tracing perf interrupt handlers (which often run in NMI context)
it is very useful to see how the events nest.
Link: http://lkml.kernel.org/r/20160318153022.105068893@infradead.org
Signed-off-by: Peter Zijlstra (Intel) <peterz@infradead.org>
Signed-off-by: Steven Rostedt <rostedt@goodmis.org>
If tracing contains data and the trace_pipe file is read with sendfile(),
then it can trigger a NULL pointer dereference and various BUG_ON within the
VM code.
There's a patch to fix this in the splice_to_pipe() code, but it's also a
good idea to not let that happen from trace_pipe either.
Link: http://lkml.kernel.org/r/1457641146-9068-1-git-send-email-rabin@rab.in
Cc: stable@vger.kernel.org # 2.6.30+
Reported-by: Rabin Vincent <rabin.vincent@gmail.com>
Signed-off-by: Steven Rostedt <rostedt@goodmis.org>
commit d39cdd2036 ("tracing: Make tracer_flags use the right set_flag
callback") introduces a potential mutex deadlock issue, as it forgets to
free the mutex when allocaing the tracer_flags gets fail.
The issue was found by Dan Carpenter through Smatch static code check tool.
Link: http://lkml.kernel.org/r/1457958941-30265-1-git-send-email-chuhu@redhat.com
Fixes: d39cdd2036 ("tracing: Make tracer_flags use the right set_flag callback")
Reported-by: Dan Carpenter <dan.carpenter@oracle.com>
Signed-off-by: Chunyu Hu <chuhu@redhat.com>
Signed-off-by: Steven Rostedt <rostedt@goodmis.org>
When I was updating the ftrace_stress test of ltp. I encountered
a strange phenomemon, excute following steps:
echo nop > /sys/kernel/debug/tracing/current_tracer
echo 0 > /sys/kernel/debug/tracing/options/funcgraph-cpu
bash: echo: write error: Invalid argument
check dmesg:
[ 1024.903855] nop_test_refuse flag set to 0: we refuse.Now cat trace_options to see the result
The reason is that the trace option test will randomly setup trace
option under tracing/options no matter what the current_tracer is.
but the set_tracer_option is always using the set_flag callback
from the current_tracer. This patch adds a pointer to tracer_flags
and make it point to the tracer it belongs to. When the option is
setup, the set_flag of the right tracer will be used no matter
what the the current_tracer is.
And the old dummy_tracer_flags is used for all the tracers which
doesn't have a tracer_flags, having issue to use it to save the
pointer of a tracer. So remove it and use dynamic dummy tracer_flags
for tracers needing a dummy tracer_flags, as a result, there are no
tracers sharing tracer_flags, so remove the check code.
And save the current tracer to trace_option_dentry seems not good as
it may waste mem space when mount the debug/trace fs more than one time.
Link: http://lkml.kernel.org/r/1457444222-8654-1-git-send-email-chuhu@redhat.com
Signed-off-by: Chunyu Hu <chuhu@redhat.com>
[ Fixed up function tracer options to work with the change ]
Signed-off-by: Steven Rostedt <rostedt@goodmis.org>
tracing_max_lat_fops is used only when TRACER_MAX_TRACE enabled, so also
swith the related code. The related warning with defconfig under x86_64:
CC kernel/trace/trace.o
kernel/trace/trace.c:5466:37: warning: ‘tracing_max_lat_fops’ defined but not used [-Wunused-const-variable]
static const struct file_operations tracing_max_lat_fops = {
Signed-off-by: Chen Gang <gang.chen.5i5j@gmail.com>
Signed-off-by: Steven Rostedt <rostedt@goodmis.org>
Since the ring buffer is lockless, there is no need to disable ftrace on
CPU. And no one doing so: after commit 68179686ac ("tracing: Remove
ftrace_disable/enable_cpu()") ftrace_cpu_disabled stays the same after
initialization, nothing changes it.
ftrace_cpu_disabled shouldn't be used by any external module since it
disables only function and graph_function tracers but not any other
tracer.
Link: http://lkml.kernel.org/r/1446836846-22239-1-git-send-email-0x7f454c46@gmail.com
Signed-off-by: Dmitry Safonov <0x7f454c46@gmail.com>
Signed-off-by: Steven Rostedt <rostedt@goodmis.org>
{kind=link}