forked from mindspore-Ecosystem/mindspore
Move googlenet into ModelZoo and add superlink in README
This commit is contained in:
parent
f5e8abbba3
commit
42b2dbec9d
|
|
@ -1,106 +0,0 @@
|
|||
# Googlenet Example
|
||||
|
||||
## Description
|
||||
|
||||
This example is for Googlenet model training and evaluation.
|
||||
|
||||
## Requirements
|
||||
|
||||
- Install [MindSpore](https://www.mindspore.cn/install/en).
|
||||
|
||||
- Download the CIFAR-10 binary version dataset.
|
||||
|
||||
> Unzip the CIFAR-10 dataset to any path you want and the folder structure should be as follows:
|
||||
> ```
|
||||
> .
|
||||
> ├── cifar-10-batches-bin # train dataset
|
||||
> └── cifar-10-verify-bin # infer dataset
|
||||
> ```
|
||||
|
||||
## Running the Example
|
||||
|
||||
### Training
|
||||
|
||||
```
|
||||
python train.py --data_path=your_data_path --device_id=6 > out.train.log 2>&1 &
|
||||
```
|
||||
The python command above will run in the background, you can view the results through the file `out.train.log`.
|
||||
|
||||
After training, you'll get some checkpoint files under the script folder by default.
|
||||
|
||||
You will get the loss value as following:
|
||||
```
|
||||
# grep "loss is " out.train.log
|
||||
epoch: 1 step: 390, loss is 1.4842823
|
||||
epcoh: 2 step: 390, loss is 1.0897788
|
||||
...
|
||||
```
|
||||
|
||||
### Evaluation
|
||||
|
||||
```
|
||||
python eval.py --data_path=your_data_path --device_id=6 --checkpoint_path=./train_googlenet_cifar10-125-390.ckpt > out.eval.log 2>&1 &
|
||||
```
|
||||
The above python command will run in the background, you can view the results through the file `out.eval.log`.
|
||||
|
||||
You will get the accuracy as following:
|
||||
```
|
||||
# grep "result: " out.eval.log
|
||||
result: {'acc': 0.934}
|
||||
```
|
||||
|
||||
### Distribute Training
|
||||
```
|
||||
sh run_distribute_train.sh rank_table.json your_data_path
|
||||
```
|
||||
The above shell script will run distribute training in the background, you can view the results through the file `train_parallel[X]/log`.
|
||||
|
||||
You will get the loss value as following:
|
||||
```
|
||||
# grep "result: " train_parallel*/log
|
||||
train_parallel0/log:epoch: 1 step: 48, loss is 1.4302931
|
||||
train_parallel0/log:epcoh: 2 step: 48, loss is 1.4023874
|
||||
...
|
||||
train_parallel1/log:epoch: 1 step: 48, loss is 1.3458025
|
||||
train_parallel1/log:epcoh: 2 step: 48, loss is 1.3729336
|
||||
...
|
||||
...
|
||||
```
|
||||
> About rank_table.json, you can refer to the [distributed training tutorial](https://www.mindspore.cn/tutorial/en/master/advanced_use/distributed_training.html).
|
||||
|
||||
## Usage:
|
||||
|
||||
### Training
|
||||
```
|
||||
usage: train.py [--device_target TARGET][--data_path DATA_PATH]
|
||||
[--device_id DEVICE_ID]
|
||||
|
||||
parameters/options:
|
||||
--device_target the training backend type, default is Ascend.
|
||||
--data_path the storage path of dataset
|
||||
--device_id the device which used to train model.
|
||||
|
||||
```
|
||||
|
||||
### Evaluation
|
||||
|
||||
```
|
||||
usage: eval.py [--device_target TARGET][--data_path DATA_PATH]
|
||||
[--device_id DEVICE_ID][--checkpoint_path CKPT_PATH]
|
||||
|
||||
parameters/options:
|
||||
--device_target the evaluation backend type, default is Ascend.
|
||||
--data_path the storage path of datasetd
|
||||
--device_id the device which used to evaluate model.
|
||||
--checkpoint_path the checkpoint file path used to evaluate model.
|
||||
```
|
||||
|
||||
### Distribute Training
|
||||
|
||||
```
|
||||
Usage: sh run_distribute_train.sh [MINDSPORE_HCCL_CONFIG_PATH] [DATA_PATH]
|
||||
|
||||
parameters/options:
|
||||
MINDSPORE_HCCL_CONFIG_PATH HCCL configuration file path.
|
||||
DATA_PATH the storage path of dataset.
|
||||
```
|
||||
|
|
@ -0,0 +1,306 @@
|
|||

|
||||
|
||||
|
||||
# Welcome to the Model Zoo for MindSpore
|
||||
|
||||
In order to facilitate developers to enjoy the benefits of MindSpore framework and Huawei chips, we will continue to add typical networks and models . If you have needs for the model zoo, you can file an issue on [gitee](https://gitee.com/mindspore/mindspore/issues) or [MindSpore](https://bbs.huaweicloud.com/forum/forum-1076-1.html), We will consider it in time.
|
||||
|
||||
- SOTA models using the latest MindSpore APIs
|
||||
|
||||
- The best benefits from MindSpore and Huawei chips
|
||||
|
||||
- Officially maintained and supported
|
||||
|
||||
|
||||
|
||||
# Table of Contents
|
||||
|
||||
- [Models and Implementations](#models-and-implementations)
|
||||
- [Computer Vision](#computer-vision)
|
||||
- [Image Classification](#image-classification)
|
||||
- [GoogleNet](#googlenet)
|
||||
- [ResNet50[benchmark]](#resnet50)
|
||||
- [ResNet101](#resnet101)
|
||||
- [VGG16](#vgg16)
|
||||
- [AlexNet](#alexnet)
|
||||
- [LeNet](#lenet)
|
||||
- [Object Detection and Segmentation](#object-detection-and-segmentation)
|
||||
- [YoloV3](#yolov3)
|
||||
- [MobileNetV2](#mobilenetv2)
|
||||
- [MobileNetV3](#mobilenetv3)
|
||||
- [SSD](#ssd)
|
||||
- [Natural Language Processing](#natural-language-processing)
|
||||
- [BERT](#bert)
|
||||
- [MASS](#mass)
|
||||
|
||||
|
||||
# Announcements
|
||||
| Date | News |
|
||||
| ------------ | ------------------------------------------------------------ |
|
||||
| May 31, 2020 | Support [MindSpore v0.3.0-alpha](https://www.mindspore.cn/news/newschildren?id=215) |
|
||||
|
||||
|
||||
# Models and Implementations
|
||||
|
||||
## Computer Vision
|
||||
|
||||
### Image Classification
|
||||
|
||||
#### [GoogleNet](#table-of-contents)
|
||||
| Parameters | GoogleNet |
|
||||
| -------------------------- | ------------------------------------------------------------ |
|
||||
| Published Year | 2014 |
|
||||
| Paper | [Going Deeper with Convolutions](https://arxiv.org/abs/1409.4842) |
|
||||
| Resource | Ascend 910 |
|
||||
| Features | • Mixed Precision • Multi-GPU training support with Ascend |
|
||||
| MindSpore Version | 0.3.0-alpha |
|
||||
| Dataset | CIFAR-10 |
|
||||
| Training Parameters | epoch=125, batch_size = 128, lr=0.1 |
|
||||
| Optimizer | Momentum |
|
||||
| Loss Function | Softmax Cross Entropy |
|
||||
| Accuracy | 1pc: 93.4%; 8pcs: 92.17% |
|
||||
| Speed | 79 ms/Step |
|
||||
| Loss | 0.0016 |
|
||||
| Params (M) | 6.8 |
|
||||
| Checkpoint for Fine tuning | 43.07M (.ckpt file) |
|
||||
| Model for inference | 21.50M (.onnx file), 21.60M(.geir file) |
|
||||
| Scripts | https://gitee.com/mindspore/mindspore/tree/master/model_zoo/googlenet |
|
||||
|
||||
#### [ResNet50](#table-of-contents)
|
||||
|
||||
| Parameters | ResNet50 |
|
||||
| -------------------------- | -------- |
|
||||
| Published Year | |
|
||||
| Paper | |
|
||||
| Resource | |
|
||||
| Features | |
|
||||
| MindSpore Version | |
|
||||
| Dataset | |
|
||||
| Training Parameters | |
|
||||
| Optimizer | |
|
||||
| Loss Function | |
|
||||
| Accuracy | |
|
||||
| Speed | |
|
||||
| Loss | |
|
||||
| Params (M) | |
|
||||
| Checkpoint for Fine tuning | |
|
||||
| Model for inference | |
|
||||
| Scripts | |
|
||||
|
||||
#### [ResNet101](#table-of-contents)
|
||||
|
||||
| Parameters | ResNet101 |
|
||||
| -------------------------- | --------- |
|
||||
| Published Year | |
|
||||
| Paper | |
|
||||
| Resource | |
|
||||
| Features | |
|
||||
| MindSpore Version | |
|
||||
| Dataset | |
|
||||
| Training Parameters | |
|
||||
| Optimizer | |
|
||||
| Loss Function | |
|
||||
| Accuracy | |
|
||||
| Speed | |
|
||||
| Loss | |
|
||||
| Params (M) | |
|
||||
| Checkpoint for Fine tuning | |
|
||||
| Model for inference | |
|
||||
| Scripts | |
|
||||
|
||||
#### [VGG16](#table-of-contents)
|
||||
|
||||
| Parameters | VGG16 |
|
||||
| -------------------------- | ----- |
|
||||
| Published Year | |
|
||||
| Paper | |
|
||||
| Resource | |
|
||||
| Features | |
|
||||
| MindSpore Version | |
|
||||
| Dataset | |
|
||||
| Training Parameters | |
|
||||
| Optimizer | |
|
||||
| Loss Function | |
|
||||
| Accuracy | |
|
||||
| Speed | |
|
||||
| Loss | |
|
||||
| Params (M) | |
|
||||
| Checkpoint for Fine tuning | |
|
||||
| Model for inference | |
|
||||
| Scripts | |
|
||||
|
||||
#### [AlexNet](#table-of-contents)
|
||||
|
||||
| Parameters | AlexNet |
|
||||
| -------------------------- | ------- |
|
||||
| Published Year | |
|
||||
| Paper | |
|
||||
| Resource | |
|
||||
| Features | |
|
||||
| MindSpore Version | |
|
||||
| Dataset | |
|
||||
| Training Parameters | |
|
||||
| Optimizer | |
|
||||
| Loss Function | |
|
||||
| Accuracy | |
|
||||
| Speed | |
|
||||
| Loss | |
|
||||
| Params (M) | |
|
||||
| Checkpoint for Fine tuning | |
|
||||
| Model for inference | |
|
||||
| Scripts | |
|
||||
|
||||
#### [LeNet](#table-of-contents)
|
||||
|
||||
| Parameters | LeNet |
|
||||
| -------------------------- | ----- |
|
||||
| Published Year | |
|
||||
| Paper | |
|
||||
| Resource | |
|
||||
| Features | |
|
||||
| MindSpore Version | |
|
||||
| Dataset | |
|
||||
| Training Parameters | |
|
||||
| Optimizer | |
|
||||
| Loss Function | |
|
||||
| Accuracy | |
|
||||
| Speed | |
|
||||
| Loss | |
|
||||
| Params (M) | |
|
||||
| Checkpoint for Fine tuning | |
|
||||
| Model for inference | |
|
||||
| Scripts | |
|
||||
|
||||
### Object Detection and Segmentation
|
||||
|
||||
#### [YoloV3](#table-of-contents)
|
||||
|
||||
| Parameters | YoLoV3 |
|
||||
| -------------------------------- | ------ |
|
||||
| Published Year | |
|
||||
| Paper | |
|
||||
| Resource | |
|
||||
| Features | |
|
||||
| MindSpore Version | |
|
||||
| Dataset | |
|
||||
| Training Parameters | |
|
||||
| Optimizer | |
|
||||
| Loss Function | |
|
||||
| Mean Average Precision (mAP@0.5) | |
|
||||
| Speed | |
|
||||
| Loss | |
|
||||
| Params (M) | |
|
||||
| Checkpoint for Fine tuning | |
|
||||
| Model for inference | |
|
||||
| Scripts | |
|
||||
|
||||
#### [MobileNetV2](#table-of-contents)
|
||||
|
||||
| Parameters | MobileNetV2 |
|
||||
| -------------------------------- | ----------- |
|
||||
| Published Year | |
|
||||
| Paper | |
|
||||
| Resource | |
|
||||
| Features | |
|
||||
| MindSpore Version | |
|
||||
| Dataset | |
|
||||
| Training Parameters | |
|
||||
| Optimizer | |
|
||||
| Loss Function | |
|
||||
| Mean Average Precision (mAP@0.5) | |
|
||||
| Speed | |
|
||||
| Loss | |
|
||||
| Params (M) | |
|
||||
| Checkpoint for Fine tuning | |
|
||||
| Model for inference | |
|
||||
| Scripts | |
|
||||
|
||||
#### [MobileNetV3](#table-of-contents)
|
||||
|
||||
| Parameters | MobileNetV3 |
|
||||
| -------------------------------- | ----------- |
|
||||
| Published Year | |
|
||||
| Paper | |
|
||||
| Resource | |
|
||||
| Features | |
|
||||
| MindSpore Version | |
|
||||
| Dataset | |
|
||||
| Training Parameters | |
|
||||
| Optimizer | |
|
||||
| Loss Function | |
|
||||
| Mean Average Precision (mAP@0.5) | |
|
||||
| Speed | |
|
||||
| Loss | |
|
||||
| Params (M) | |
|
||||
| Checkpoint for Fine tuning | |
|
||||
| Model for inference | |
|
||||
| Scripts | |
|
||||
|
||||
#### [SSD](#table-of-contents)
|
||||
|
||||
| Parameters | SSD |
|
||||
| -------------------------------- | ---- |
|
||||
| Published Year | |
|
||||
| Paper | |
|
||||
| Resource | |
|
||||
| Features | |
|
||||
| MindSpore Version | |
|
||||
| Dataset | |
|
||||
| Training Parameters | |
|
||||
| Optimizer | |
|
||||
| Loss Function | |
|
||||
| Mean Average Precision (mAP@0.5) | |
|
||||
| Speed | |
|
||||
| Loss | |
|
||||
| Params (M) | |
|
||||
| Checkpoint for Fine tuning | |
|
||||
| Model for inference | |
|
||||
| Scripts | |
|
||||
|
||||
## Natural Language Processing
|
||||
|
||||
#### [BERT](#table-of-contents)
|
||||
|
||||
| Parameters | BERT |
|
||||
| -------------------------- | ---- |
|
||||
| Published Year | |
|
||||
| Paper | |
|
||||
| Resource | |
|
||||
| Features | |
|
||||
| MindSpore Version | |
|
||||
| Dataset | |
|
||||
| Training Parameters | |
|
||||
| Optimizer | |
|
||||
| Loss Function | |
|
||||
| GLUE Score | |
|
||||
| Speed | |
|
||||
| Loss | |
|
||||
| Params (M) | |
|
||||
| Checkpoint for Fine tuning | |
|
||||
| Model for inference | |
|
||||
| Scripts | |
|
||||
|
||||
#### [MASS](#table-of-contents)
|
||||
|
||||
| Parameters | MASS |
|
||||
| -------------------------- | ---- |
|
||||
| Published Year | |
|
||||
| Paper | |
|
||||
| Resource | |
|
||||
| Features | |
|
||||
| MindSpore Version | |
|
||||
| Dataset | |
|
||||
| Training Parameters | |
|
||||
| Optimizer | |
|
||||
| Loss Function | |
|
||||
| ROUGE Score | |
|
||||
| Speed | |
|
||||
| Loss | |
|
||||
| Params (M) | |
|
||||
| Checkpoint for Fine tuning | |
|
||||
| Model for inference | |
|
||||
| Scripts | |
|
||||
|
||||
#### License
|
||||
|
||||
[Apache License 2.0](https://github.com/mindspore-ai/mindspore/blob/master/LICENSE)
|
||||
|
|
@ -0,0 +1,324 @@
|
|||
# Contents
|
||||
|
||||
- [GoogleNet Description](#googlenet-description)
|
||||
- [Model Architecture](#model-architecture)
|
||||
- [Dataset](#dataset)
|
||||
- [Features](#features)
|
||||
- [Mixed Precision](#mixed-precision)
|
||||
- [Environment Requirements](#environment-requirements)
|
||||
- [Quick Start](#quick-start)
|
||||
- [Script Description](#script-description)
|
||||
- [Script and Sample Code](#script-and-sample-code)
|
||||
- [Script Parameters](#script-parameters)
|
||||
- [Training Process](#training-process)
|
||||
- [Training](#training)
|
||||
- [Distributed Training](#distributed-training)
|
||||
- [Evaluation Process](#evaluation-process)
|
||||
- [Evaluation](#evaluation)
|
||||
- [Model Description](#model-description)
|
||||
- [Performance](#performance)
|
||||
- [Evaluation Performance](#evaluation-performance)
|
||||
- [Inference Performance](#evaluation-performance)
|
||||
- [How to use](#how-to-use)
|
||||
- [Inference](#inference)
|
||||
- [Continue Training on the Pretrained Model](#continue-training-on-the-pretrained-model)
|
||||
- [Transfer Learning](#transfer-learning)
|
||||
- [Description of Random Situation](#description-of-random-situation)
|
||||
- [ModelZoo Homepage](#modelzoo-homepage)
|
||||
|
||||
|
||||
# [GoogleNet Description](#contents)
|
||||
|
||||
GoogleNet, a 22 layers deep network, was proposed in 2014 and won the first place in the ImageNet Large-Scale Visual Recognition Challenge 2014 (ILSVRC14). GoogleNet, also called Inception v1, has significant improvement over ZFNet (The winner in 2013) and AlexNet (The winner in 2012), and has relatively lower error rate compared to VGGNet. Typically deeper deep learning network means larger number of parameters, which makes it more prone to overfitting. Furthermore, the increased network size leads to increased use of computational resources. To tackle these issues, GoogleNet adopts 1*1 convolution middle of the network to reduce dimension, and thus further reduce the computation. Global average pooling is used at the end of the network, instead of using fully connected layers. Another technique, called inception module, is to have different sizes of convolutions for the same input and stacking all the outputs.
|
||||
|
||||
[Paper](https://arxiv.org/abs/1409.4842): Christian Szegedy, Wei Liu, Yangqing Jia, Pierre Sermanet, Scott Reed, Dragomir Anguelov, Dumitru Erhan, Vincent Vanhoucke, Andrew Rabinovich. "Going deeper with convolutions." *Proceedings of the IEEE conference on computer vision and pattern recognition*. 2015.
|
||||
|
||||
|
||||
# [Model Architecture](#contents)
|
||||
|
||||
The overall network architecture of GoogleNet is shown below:
|
||||
|
||||
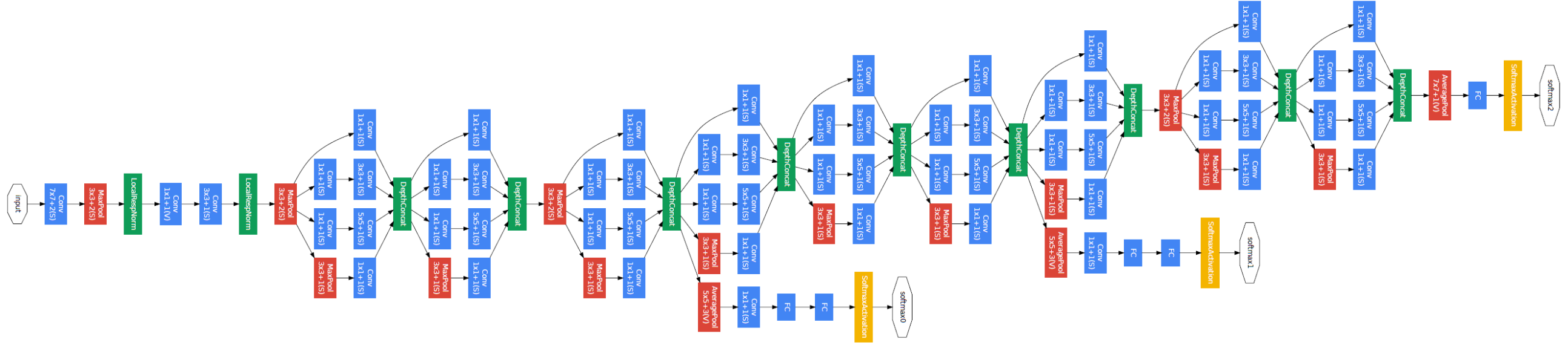
|
||||
|
||||
Specifically, the GoogleNet contains numerous inception modules, which are connected together to go deeper. In general, an inception module with dimensionality reduction consists of **1×1 conv**, **3×3 conv**, **5×5 conv**, and **3×3 max pooling**, which are done altogether for the previous input, and stack together again at output.
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
# [Dataset](#contents)
|
||||
|
||||
Dataset used: [CIFAR-10](<http://www.cs.toronto.edu/~kriz/cifar.html>)
|
||||
|
||||
- Dataset size:175M,60,000 32*32 colorful images in 10 classes
|
||||
- Train:146M,50,000 images
|
||||
- Test:29.3M,10,000 images
|
||||
- Data format:binary files
|
||||
- Note:Data will be processed in dataset.py
|
||||
|
||||
|
||||
|
||||
# [Features](#contents)
|
||||
|
||||
## Mixed Precision
|
||||
|
||||
The [mixed precision](https://www.mindspore.cn/tutorial/zh-CN/master/advanced_use/mixed_precision.html) training method accelerates the deep learning neural network training process by using both the single-precision and half-precision data formats, and maintains the network precision achieved by the single-precision training at the same time. Mixed precision training can accelerate the computation process, reduce memory usage, and enable a larger model or batch size to be trained on specific hardware.
|
||||
For FP16 operators, if the input data type is FP32, the backend of MindSpore will automatically handle it with reduced precision. Users could check the reduced-precision operators by enabling INFO log and then searching ‘reduce precision’.
|
||||
|
||||
|
||||
|
||||
# [Environment Requirements](#contents)
|
||||
|
||||
- Hardware(Ascend/GPU)
|
||||
- Prepare hardware environment with Ascend or GPU processor. If you want to try Ascend , please send the [application form](https://obs-9be7.obs.cn-east-2.myhuaweicloud.com/file/other/Ascend%20Model%20Zoo%E4%BD%93%E9%AA%8C%E8%B5%84%E6%BA%90%E7%94%B3%E8%AF%B7%E8%A1%A8.docx) to ascend@huawei.com. Once approved, you can get the resources.
|
||||
- Framework
|
||||
- [MindSpore](http://10.90.67.50/mindspore/archive/20200506/OpenSource/me_vm_x86/)
|
||||
- For more information, please check the resources below:
|
||||
- [MindSpore tutorials](https://www.mindspore.cn/tutorial/zh-CN/master/index.html)
|
||||
- [MindSpore API](https://www.mindspore.cn/api/zh-CN/master/index.html)
|
||||
|
||||
|
||||
|
||||
# [Quick Start](#contents)
|
||||
|
||||
After installing MindSpore via the official website, you can start training and evaluation as follows:
|
||||
|
||||
```python
|
||||
# run training example
|
||||
python train.py > train.log 2>&1 &
|
||||
|
||||
# run distributed training example
|
||||
sh scripts/run_train.sh rank_table.json
|
||||
|
||||
# run evaluation example
|
||||
python eval.py > eval.log 2>&1 & OR sh run_eval.sh
|
||||
```
|
||||
|
||||
|
||||
|
||||
# [Script Description](#contents)
|
||||
|
||||
## [Script and Sample Code](#contents)
|
||||
|
||||
```
|
||||
├── model_zoo
|
||||
├── README.md // descriptions about all the models
|
||||
├── googlenet
|
||||
├── README.md // descriptions about googlenet
|
||||
├── scripts
|
||||
│ ├──run_train.sh // shell script for distributed
|
||||
│ ├──run_eval.sh // shell script for evaluation
|
||||
├── src
|
||||
│ ├──dataset.py // creating dataset
|
||||
│ ├──googlenet.py // googlenet architecture
|
||||
│ ├──config.py // parameter configuration
|
||||
├── train.py // training script
|
||||
├── eval.py // evaluation script
|
||||
├── export.py // export checkpoint files into geir/onnx
|
||||
```
|
||||
|
||||
## [Script Parameters](#contents)
|
||||
|
||||
```python
|
||||
Major parameters in train.py and config.py are:
|
||||
|
||||
--data_path: The absolute full path to the train and evaluation datasets.
|
||||
--epoch_size: Total training epochs.
|
||||
--batch_size: Training batch size.
|
||||
--lr_init: Initial learning rate.
|
||||
--num_classes: The number of classes in the training set.
|
||||
--weight_decay: Weight decay value.
|
||||
--image_height: Image height used as input to the model.
|
||||
--image_width: Image width used as input the model.
|
||||
--pre_trained: Whether training from scratch or training based on the
|
||||
pre-trained model.Optional values are True, False.
|
||||
--device_target: Device where the code will be implemented. Optional values
|
||||
are "Ascend", "GPU".
|
||||
--device_id: Device ID used to train or evaluate the dataset. Ignore it
|
||||
when you use run_train.sh for distributed training.
|
||||
--checkpoint_path: The absolute full path to the checkpoint file saved
|
||||
after training.
|
||||
--onnx_filename: File name of the onnx model used in export.py.
|
||||
--geir_filename: File name of the geir model used in export.py.
|
||||
```
|
||||
|
||||
|
||||
## [Training Process](#contents)
|
||||
|
||||
### Training
|
||||
|
||||
```
|
||||
python train.py > train.log 2>&1 &
|
||||
```
|
||||
|
||||
The python command above will run in the background, you can view the results through the file `train.log`.
|
||||
|
||||
After training, you'll get some checkpoint files under the script folder by default. The loss value will be achieved as follows:
|
||||
|
||||
```
|
||||
# grep "loss is " train.log
|
||||
epoch: 1 step: 390, loss is 1.4842823
|
||||
epcoh: 2 step: 390, loss is 1.0897788
|
||||
...
|
||||
```
|
||||
|
||||
The model checkpoint will be saved in the current directory.
|
||||
|
||||
### Distributed Training
|
||||
|
||||
```
|
||||
sh scripts/run_train.sh rank_table.json
|
||||
```
|
||||
|
||||
The above shell script will run distribute training in the background. You can view the results through the file `train_parallel[X]/log`. The loss value will be achieved as follows:
|
||||
|
||||
```
|
||||
# grep "result: " train_parallel*/log
|
||||
train_parallel0/log:epoch: 1 step: 48, loss is 1.4302931
|
||||
train_parallel0/log:epcoh: 2 step: 48, loss is 1.4023874
|
||||
...
|
||||
train_parallel1/log:epoch: 1 step: 48, loss is 1.3458025
|
||||
train_parallel1/log:epcoh: 2 step: 48, loss is 1.3729336
|
||||
...
|
||||
...
|
||||
```
|
||||
|
||||
|
||||
## [Evaluation Process](#contents)
|
||||
|
||||
### Evaluation
|
||||
|
||||
Before running the command below, please check the checkpoint path used for evaluation. Please set the checkpoint path to be the absolute full path, e.g., "username/googlenet/train_googlenet_cifar10-125_390.ckpt".
|
||||
|
||||
```
|
||||
python eval.py > eval.log 2>&1 &
|
||||
OR
|
||||
sh scripts/run_eval.sh
|
||||
```
|
||||
|
||||
The above python command will run in the background. You can view the results through the file "eval.log". The accuracy of the test dataset will be as follows:
|
||||
|
||||
```
|
||||
# grep "accuracy: " eval.log
|
||||
accuracy: {'acc': 0.934}
|
||||
```
|
||||
|
||||
Note that for evaluation after distributed training, please set the checkpoint_path to be the last saved checkpoint file such as "username/googlenet/train_parallel0/train_googlenet_cifar10-125_48.ckpt". The accuracy of the test dataset will be as follows:
|
||||
|
||||
```
|
||||
# grep "accuracy: " dist.eval.log
|
||||
accuracy: {'acc': 0.9217}
|
||||
```
|
||||
|
||||
|
||||
# [Model Description](#contents)
|
||||
## [Performance](#contents)
|
||||
|
||||
### Evaluation Performance
|
||||
|
||||
| Parameters | GoogleNet |
|
||||
| -------------------------- | ----------------------------------------------------------- |
|
||||
| Model Version | Inception V1 |
|
||||
| Resource | Ascend 910 ;CPU 2.60GHz,56cores;Memory,314G |
|
||||
| uploaded Date | 06/09/2020 (month/day/year) |
|
||||
| MindSpore Version | 0.3.0-alpha |
|
||||
| Dataset | CIFAR-10 |
|
||||
| Training Parameters | epoch=125, steps=390, batch_size = 128, lr=0.1 |
|
||||
| Optimizer | SGD |
|
||||
| Loss Function | Softmax Cross Entropy |
|
||||
| outputs | probability |
|
||||
| Loss | 0.0016 |
|
||||
| Speed | 1pc: 79 ms/step; 8pcs: 82 ms/step |
|
||||
| Total time | 1pc: 63.85 mins; 8pcs: 11.28 mins |
|
||||
| Parameters (M) | 6.8 |
|
||||
| Checkpoint for Fine tuning | 43.07M (.ckpt file) |
|
||||
| Model for inference | 21.50M (.onnx file), 21.60M(.geir file) |
|
||||
| Scripts | https://gitee.com/mindspore/mindspore/tree/master/model_zoo/googlenet |
|
||||
|
||||
|
||||
### Inference Performance
|
||||
|
||||
| Parameters | GoogleNet |
|
||||
| ------------------- | --------------------------- |
|
||||
| Model Version | Inception V1 |
|
||||
| Resource | Ascend 910 |
|
||||
| Uploaded Date | 06/09/2020 (month/day/year) |
|
||||
| MindSpore Version | 0.3.0-alpha |
|
||||
| Dataset | CIFAR-10, 10,000 images |
|
||||
| batch_size | 128 |
|
||||
| outputs | probability |
|
||||
| Accuracy | 1pc: 93.4%; 8pcs: 92.17% |
|
||||
| Model for inference | 21.50M (.onnx file) |
|
||||
|
||||
## [How to use](#contents)
|
||||
### Inference
|
||||
|
||||
If you need to use the trained model to perform inference on multiple hardware platforms, such as GPU, Ascend 910 or Ascend 310, you can refer to this [Link](https://www.mindspore.cn/tutorial/zh-CN/master/advanced_use/network_migration.html). Following the steps below, this is a simple example:
|
||||
|
||||
```
|
||||
# Load unseen dataset for inference
|
||||
dataset = dataset.create_dataset(cfg.data_path, 1, False)
|
||||
|
||||
# Define model
|
||||
net = GoogleNet(num_classes=cfg.num_classes)
|
||||
opt = Momentum(filter(lambda x: x.requires_grad, net.get_parameters()), 0.01,
|
||||
cfg.momentum, weight_decay=cfg.weight_decay)
|
||||
loss = nn.SoftmaxCrossEntropyWithLogits(sparse=True, reduction='mean',
|
||||
is_grad=False)
|
||||
model = Model(net, loss_fn=loss, optimizer=opt, metrics={'acc'})
|
||||
|
||||
# Load pre-trained model
|
||||
param_dict = load_checkpoint(cfg.checkpoint_path)
|
||||
load_param_into_net(net, param_dict)
|
||||
net.set_train(False)
|
||||
|
||||
# Make predictions on the unseen dataset
|
||||
acc = model.eval(dataset)
|
||||
print("accuracy: ", acc)
|
||||
```
|
||||
|
||||
### Continue Training on the Pretrained Model
|
||||
|
||||
```
|
||||
# Load dataset
|
||||
dataset = create_dataset(cfg.data_path, cfg.epoch_size)
|
||||
batch_num = dataset.get_dataset_size()
|
||||
|
||||
# Define model
|
||||
net = GoogleNet(num_classes=cfg.num_classes)
|
||||
# Continue training if set pre_trained to be True
|
||||
if cfg.pre_trained:
|
||||
param_dict = load_checkpoint(cfg.checkpoint_path)
|
||||
load_param_into_net(net, param_dict)
|
||||
lr = lr_steps(0, lr_max=cfg.lr_init, total_epochs=cfg.epoch_size,
|
||||
steps_per_epoch=batch_num)
|
||||
opt = Momentum(filter(lambda x: x.requires_grad, net.get_parameters()),
|
||||
Tensor(lr), cfg.momentum, weight_decay=cfg.weight_decay)
|
||||
loss = nn.SoftmaxCrossEntropyWithLogits(sparse=True, reduction='mean', is_grad=False)
|
||||
model = Model(net, loss_fn=loss, optimizer=opt, metrics={'acc'},
|
||||
amp_level="O2", keep_batchnorm_fp32=False, loss_scale_manager=None)
|
||||
|
||||
# Set callbacks
|
||||
config_ck = CheckpointConfig(save_checkpoint_steps=batch_num * 5,
|
||||
keep_checkpoint_max=cfg.keep_checkpoint_max)
|
||||
time_cb = TimeMonitor(data_size=batch_num)
|
||||
ckpoint_cb = ModelCheckpoint(prefix="train_googlenet_cifar10", directory="./",
|
||||
config=config_ck)
|
||||
loss_cb = LossMonitor()
|
||||
|
||||
# Start training
|
||||
model.train(cfg.epoch_size, dataset, callbacks=[time_cb, ckpoint_cb, loss_cb])
|
||||
print("train success")
|
||||
```
|
||||
|
||||
### Transfer Learning
|
||||
To be added.
|
||||
|
||||
|
||||
# [Description of Random Situation](#contents)
|
||||
|
||||
In dataset.py, we set the seed inside “create_dataset" function. We also use random seed in train.py.
|
||||
|
||||
|
||||
# [ModelZoo Homepage](#contents)
|
||||
Please check the official [homepage](https://gitee.com/mindspore/mindspore/tree/master/model_zoo).
|
||||
|
|
@ -14,42 +14,32 @@
|
|||
# ============================================================================
|
||||
"""
|
||||
##############test googlenet example on cifar10#################
|
||||
python eval.py --data_path=$DATA_HOME --device_id=$DEVICE_ID
|
||||
python eval.py
|
||||
"""
|
||||
import argparse
|
||||
|
||||
import mindspore.nn as nn
|
||||
from mindspore import context
|
||||
from mindspore.model_zoo.googlenet import GooGLeNet
|
||||
from mindspore.nn.optim.momentum import Momentum
|
||||
from mindspore.train.model import Model
|
||||
from mindspore.train.serialization import load_checkpoint, load_param_into_net
|
||||
|
||||
import dataset
|
||||
from config import cifar_cfg as cfg
|
||||
from src.config import cifar_cfg as cfg
|
||||
from src.dataset import create_dataset
|
||||
from src.googlenet import GoogleNet
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
parser = argparse.ArgumentParser(description='Cifar10 classification')
|
||||
parser.add_argument('--device_target', type=str, default='Ascend', choices=['Ascend', 'GPU'],
|
||||
help='device where the code will be implemented. (Default: Ascend)')
|
||||
parser.add_argument('--data_path', type=str, default='./cifar', help='path where the dataset is saved')
|
||||
parser.add_argument('--checkpoint_path', type=str, default=None, help='checkpoint file path.')
|
||||
parser.add_argument('--device_id', type=int, default=None, help='device id of GPU or Ascend. (Default: None)')
|
||||
args_opt = parser.parse_args()
|
||||
context.set_context(mode=context.GRAPH_MODE, device_target=cfg.device_target)
|
||||
context.set_context(device_id=cfg.device_id)
|
||||
|
||||
context.set_context(mode=context.GRAPH_MODE, device_target=args_opt.device_target)
|
||||
context.set_context(device_id=args_opt.device_id)
|
||||
|
||||
net = GooGLeNet(num_classes=cfg.num_classes)
|
||||
net = GoogleNet(num_classes=cfg.num_classes)
|
||||
opt = Momentum(filter(lambda x: x.requires_grad, net.get_parameters()), 0.01, cfg.momentum,
|
||||
weight_decay=cfg.weight_decay)
|
||||
loss = nn.SoftmaxCrossEntropyWithLogits(sparse=True, reduction='mean', is_grad=False)
|
||||
model = Model(net, loss_fn=loss, optimizer=opt, metrics={'acc'})
|
||||
|
||||
param_dict = load_checkpoint(args_opt.checkpoint_path)
|
||||
param_dict = load_checkpoint(cfg.checkpoint_path)
|
||||
load_param_into_net(net, param_dict)
|
||||
net.set_train(False)
|
||||
dataset = dataset.create_dataset(args_opt.data_path, 1, False)
|
||||
res = model.eval(dataset)
|
||||
print("result: ", res)
|
||||
dataset = create_dataset(cfg.data_path, 1, False)
|
||||
acc = model.eval(dataset)
|
||||
print("accuracy: ", acc)
|
||||
|
|
@ -0,0 +1,36 @@
|
|||
# Copyright 2020 Huawei Technologies Co., Ltd
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
# ============================================================================
|
||||
"""
|
||||
##############export checkpoint file into geir and onnx models#################
|
||||
python export.py
|
||||
"""
|
||||
import numpy as np
|
||||
|
||||
import mindspore as ms
|
||||
from mindspore import Tensor
|
||||
from mindspore.train.serialization import load_checkpoint, load_param_into_net, export
|
||||
|
||||
from src.config import cifar_cfg as cfg
|
||||
from src.googlenet import GoogleNet
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
net = GoogleNet(num_classes=cfg.num_classes)
|
||||
param_dict = load_checkpoint(cfg.checkpoint_path)
|
||||
load_param_into_net(net, param_dict)
|
||||
|
||||
input_arr = Tensor(np.random.uniform(0.0, 1.0, size=[1, 3, 224, 224]), ms.float32)
|
||||
export(net, input_arr, file_name=cfg.onnx_filename, file_format="ONNX")
|
||||
export(net, input_arr, file_name=cfg.geir_filename, file_format="GEIR")
|
||||
|
|
@ -0,0 +1,23 @@
|
|||
#!/bin/bash
|
||||
# Copyright 2020 Huawei Technologies Co., Ltd
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
# ============================================================================
|
||||
|
||||
ulimit -u unlimited
|
||||
|
||||
BASEPATH=$(cd "`dirname $0`" || exit; pwd)
|
||||
export PYTHONPATH=${BASEPATH}:$PYTHONPATH
|
||||
export DEVICE_ID=0
|
||||
|
||||
python ${BASEPATH}/../eval.py > ./eval.log 2>&1 &
|
||||
28
example/googlenet_cifar10/run_distribute_train.sh → model_zoo/googlenet/scripts/run_train.sh
Executable file → Normal file
28
example/googlenet_cifar10/run_distribute_train.sh → model_zoo/googlenet/scripts/run_train.sh
Executable file → Normal file
|
|
@ -14,28 +14,24 @@
|
|||
# limitations under the License.
|
||||
# ============================================================================
|
||||
|
||||
if [ $# != 2 ]
|
||||
then
|
||||
echo "Usage: sh run_distribute_train.sh [MINDSPORE_HCCL_CONFIG_PATH] [DATA_PATH]"
|
||||
if [ $# != 1 ]
|
||||
then
|
||||
echo "Usage: sh run_train.sh [MINDSPORE_HCCL_CONFIG_PATH]"
|
||||
exit 1
|
||||
fi
|
||||
|
||||
if [ ! -f $1 ]
|
||||
then
|
||||
then
|
||||
echo "error: MINDSPORE_HCCL_CONFIG_PATH=$1 is not a file"
|
||||
exit 1
|
||||
fi
|
||||
|
||||
if [ ! -d $2 ]
|
||||
then
|
||||
echo "error: DATA_PATH=$2 is not a directory"
|
||||
exit 1
|
||||
fi
|
||||
fi
|
||||
|
||||
ulimit -u unlimited
|
||||
export DEVICE_NUM=8
|
||||
export RANK_SIZE=8
|
||||
export MINDSPORE_HCCL_CONFIG_PATH=$1
|
||||
MINDSPORE_HCCL_CONFIG_PATH=$(realpath $1)
|
||||
export MINDSPORE_HCCL_CONFIG_PATH
|
||||
echo "MINDSPORE_HCCL_CONFIG_PATH=${MINDSPORE_HCCL_CONFIG_PATH}"
|
||||
|
||||
for((i=0; i<${DEVICE_NUM}; i++))
|
||||
do
|
||||
|
|
@ -43,11 +39,11 @@ do
|
|||
export RANK_ID=$i
|
||||
rm -rf ./train_parallel$i
|
||||
mkdir ./train_parallel$i
|
||||
cp *.py ./train_parallel$i
|
||||
cp *.sh ./train_parallel$i
|
||||
cd ./train_parallel$i || exit
|
||||
cp -r ./src ./train_parallel$i
|
||||
cp ./train.py ./train_parallel$i
|
||||
echo "start training for rank $RANK_ID, device $DEVICE_ID"
|
||||
cd ./train_parallel$i ||exit
|
||||
env > env.log
|
||||
python train.py --data_path=$2 --device_id=$i &> log &
|
||||
python train.py --device_id=$i > log 2>&1 &
|
||||
cd ..
|
||||
done
|
||||
|
|
@ -18,6 +18,7 @@ network config setting, will be used in main.py
|
|||
from easydict import EasyDict as edict
|
||||
|
||||
cifar_cfg = edict({
|
||||
'pre_trained': False,
|
||||
'num_classes': 10,
|
||||
'lr_init': 0.1,
|
||||
'batch_size': 128,
|
||||
|
|
@ -27,5 +28,11 @@ cifar_cfg = edict({
|
|||
'buffer_size': 10,
|
||||
'image_height': 224,
|
||||
'image_width': 224,
|
||||
'keep_checkpoint_max': 10
|
||||
'data_path': './cifar10',
|
||||
'device_target': 'Ascend',
|
||||
'device_id': 4,
|
||||
'keep_checkpoint_max': 10,
|
||||
'checkpoint_path': './train_googlenet_cifar10-125_390.ckpt',
|
||||
'onnx_filename': 'googlenet.onnx',
|
||||
'geir_filename': 'googlenet.geir'
|
||||
})
|
||||
|
|
@ -21,7 +21,7 @@ import mindspore.common.dtype as mstype
|
|||
import mindspore.dataset as ds
|
||||
import mindspore.dataset.transforms.c_transforms as C
|
||||
import mindspore.dataset.transforms.vision.c_transforms as vision
|
||||
from config import cifar_cfg as cfg
|
||||
from src.config import cifar_cfg as cfg
|
||||
|
||||
|
||||
def create_dataset(data_home, repeat_num=1, training=True):
|
||||
|
|
@ -0,0 +1,142 @@
|
|||
# Copyright 2020 Huawei Technologies Co., Ltd
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
# ============================================================================
|
||||
"""GoogleNet"""
|
||||
import mindspore.nn as nn
|
||||
from mindspore.common.initializer import TruncatedNormal
|
||||
from mindspore.ops import operations as P
|
||||
|
||||
|
||||
def weight_variable():
|
||||
"""Weight variable."""
|
||||
return TruncatedNormal(0.02)
|
||||
|
||||
|
||||
class Conv2dBlock(nn.Cell):
|
||||
"""
|
||||
Basic convolutional block
|
||||
Args:
|
||||
in_channles (int): Input channel.
|
||||
out_channels (int): Output channel.
|
||||
kernel_size (int): Input kernel size. Default: 1
|
||||
stride (int): Stride size for the first convolutional layer. Default: 1.
|
||||
padding (int): Implicit paddings on both sides of the input. Default: 0.
|
||||
pad_mode (str): Padding mode. Optional values are "same", "valid", "pad". Default: "same".
|
||||
Returns:
|
||||
Tensor, output tensor.
|
||||
"""
|
||||
|
||||
def __init__(self, in_channels, out_channels, kernel_size=1, stride=1, padding=0, pad_mode="same"):
|
||||
super(Conv2dBlock, self).__init__()
|
||||
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size=kernel_size, stride=stride,
|
||||
padding=padding, pad_mode=pad_mode, weight_init=weight_variable())
|
||||
self.bn = nn.BatchNorm2d(out_channels, eps=0.001)
|
||||
self.relu = nn.ReLU()
|
||||
|
||||
def construct(self, x):
|
||||
x = self.conv(x)
|
||||
x = self.bn(x)
|
||||
x = self.relu(x)
|
||||
return x
|
||||
|
||||
|
||||
class Inception(nn.Cell):
|
||||
"""
|
||||
Inception Block
|
||||
"""
|
||||
|
||||
def __init__(self, in_channels, n1x1, n3x3red, n3x3, n5x5red, n5x5, pool_planes):
|
||||
super(Inception, self).__init__()
|
||||
self.b1 = Conv2dBlock(in_channels, n1x1, kernel_size=1)
|
||||
self.b2 = nn.SequentialCell([Conv2dBlock(in_channels, n3x3red, kernel_size=1),
|
||||
Conv2dBlock(n3x3red, n3x3, kernel_size=3, padding=0)])
|
||||
self.b3 = nn.SequentialCell([Conv2dBlock(in_channels, n5x5red, kernel_size=1),
|
||||
Conv2dBlock(n5x5red, n5x5, kernel_size=3, padding=0)])
|
||||
self.maxpool = P.MaxPoolWithArgmax(ksize=3, strides=1, padding="same")
|
||||
self.b4 = Conv2dBlock(in_channels, pool_planes, kernel_size=1)
|
||||
self.concat = P.Concat(axis=1)
|
||||
|
||||
def construct(self, x):
|
||||
branch1 = self.b1(x)
|
||||
branch2 = self.b2(x)
|
||||
branch3 = self.b3(x)
|
||||
cell, argmax = self.maxpool(x)
|
||||
branch4 = self.b4(cell)
|
||||
_ = argmax
|
||||
return self.concat((branch1, branch2, branch3, branch4))
|
||||
|
||||
|
||||
class GoogleNet(nn.Cell):
|
||||
"""
|
||||
Googlenet architecture
|
||||
"""
|
||||
|
||||
def __init__(self, num_classes):
|
||||
super(GoogleNet, self).__init__()
|
||||
self.conv1 = Conv2dBlock(3, 64, kernel_size=7, stride=2, padding=0)
|
||||
self.maxpool1 = P.MaxPoolWithArgmax(ksize=3, strides=2, padding="same")
|
||||
|
||||
self.conv2 = Conv2dBlock(64, 64, kernel_size=1)
|
||||
self.conv3 = Conv2dBlock(64, 192, kernel_size=3, padding=0)
|
||||
self.maxpool2 = P.MaxPoolWithArgmax(ksize=3, strides=2, padding="same")
|
||||
|
||||
self.block3a = Inception(192, 64, 96, 128, 16, 32, 32)
|
||||
self.block3b = Inception(256, 128, 128, 192, 32, 96, 64)
|
||||
self.maxpool3 = P.MaxPoolWithArgmax(ksize=3, strides=2, padding="same")
|
||||
|
||||
self.block4a = Inception(480, 192, 96, 208, 16, 48, 64)
|
||||
self.block4b = Inception(512, 160, 112, 224, 24, 64, 64)
|
||||
self.block4c = Inception(512, 128, 128, 256, 24, 64, 64)
|
||||
self.block4d = Inception(512, 112, 144, 288, 32, 64, 64)
|
||||
self.block4e = Inception(528, 256, 160, 320, 32, 128, 128)
|
||||
self.maxpool4 = P.MaxPoolWithArgmax(ksize=2, strides=2, padding="same")
|
||||
|
||||
self.block5a = Inception(832, 256, 160, 320, 32, 128, 128)
|
||||
self.block5b = Inception(832, 384, 192, 384, 48, 128, 128)
|
||||
|
||||
self.mean = P.ReduceMean(keep_dims=True)
|
||||
self.dropout = nn.Dropout(keep_prob=0.8)
|
||||
self.flatten = nn.Flatten()
|
||||
self.classifier = nn.Dense(1024, num_classes, weight_init=weight_variable(),
|
||||
bias_init=weight_variable())
|
||||
|
||||
|
||||
def construct(self, x):
|
||||
x = self.conv1(x)
|
||||
x, argmax = self.maxpool1(x)
|
||||
|
||||
x = self.conv2(x)
|
||||
x = self.conv3(x)
|
||||
x, argmax = self.maxpool2(x)
|
||||
|
||||
x = self.block3a(x)
|
||||
x = self.block3b(x)
|
||||
x, argmax = self.maxpool3(x)
|
||||
|
||||
x = self.block4a(x)
|
||||
x = self.block4b(x)
|
||||
x = self.block4c(x)
|
||||
x = self.block4d(x)
|
||||
x = self.block4e(x)
|
||||
x, argmax = self.maxpool4(x)
|
||||
|
||||
x = self.block5a(x)
|
||||
x = self.block5b(x)
|
||||
|
||||
x = self.mean(x, (2, 3))
|
||||
x = self.flatten(x)
|
||||
x = self.classifier(x)
|
||||
|
||||
_ = argmax
|
||||
return x
|
||||
|
|
@ -14,7 +14,7 @@
|
|||
# ============================================================================
|
||||
"""
|
||||
#################train googlent example on cifar10########################
|
||||
python train.py --data_path=$DATA_HOME --device_id=$DEVICE_ID
|
||||
python train.py
|
||||
"""
|
||||
import argparse
|
||||
import os
|
||||
|
|
@ -26,14 +26,14 @@ import mindspore.nn as nn
|
|||
from mindspore import Tensor
|
||||
from mindspore import context
|
||||
from mindspore.communication.management import init
|
||||
from mindspore.model_zoo.googlenet import GooGLeNet
|
||||
from mindspore.nn.optim.momentum import Momentum
|
||||
from mindspore.train.callback import ModelCheckpoint, CheckpointConfig, LossMonitor, TimeMonitor
|
||||
from mindspore.train.model import Model, ParallelMode
|
||||
from mindspore.train.serialization import load_checkpoint, load_param_into_net
|
||||
|
||||
|
||||
from dataset import create_dataset
|
||||
from config import cifar_cfg as cfg
|
||||
from src.config import cifar_cfg as cfg
|
||||
from src.dataset import create_dataset
|
||||
from src.googlenet import GoogleNet
|
||||
|
||||
random.seed(1)
|
||||
np.random.seed(1)
|
||||
|
|
@ -62,14 +62,14 @@ def lr_steps(global_step, lr_max=None, total_epochs=None, steps_per_epoch=None):
|
|||
|
||||
if __name__ == '__main__':
|
||||
parser = argparse.ArgumentParser(description='Cifar10 classification')
|
||||
parser.add_argument('--device_target', type=str, default='Ascend', choices=['Ascend', 'GPU'],
|
||||
help='device where the code will be implemented. (Default: Ascend)')
|
||||
parser.add_argument('--data_path', type=str, default='./cifar', help='path where the dataset is saved')
|
||||
parser.add_argument('--device_id', type=int, default=None, help='device id of GPU or Ascend. (Default: None)')
|
||||
args_opt = parser.parse_args()
|
||||
|
||||
context.set_context(mode=context.GRAPH_MODE, device_target=args_opt.device_target)
|
||||
context.set_context(device_id=args_opt.device_id)
|
||||
context.set_context(mode=context.GRAPH_MODE, device_target=cfg.device_target)
|
||||
if args_opt.device_id is not None:
|
||||
context.set_context(device_id=args_opt.device_id)
|
||||
else:
|
||||
context.set_context(device_id=cfg.device_id)
|
||||
|
||||
device_num = int(os.environ.get("DEVICE_NUM", 1))
|
||||
if device_num > 1:
|
||||
|
|
@ -78,10 +78,14 @@ if __name__ == '__main__':
|
|||
mirror_mean=True)
|
||||
init()
|
||||
|
||||
dataset = create_dataset(args_opt.data_path, cfg.epoch_size)
|
||||
dataset = create_dataset(cfg.data_path, cfg.epoch_size)
|
||||
batch_num = dataset.get_dataset_size()
|
||||
|
||||
net = GooGLeNet(num_classes=cfg.num_classes)
|
||||
net = GoogleNet(num_classes=cfg.num_classes)
|
||||
# Continue training if set pre_trained to be True
|
||||
if cfg.pre_trained:
|
||||
param_dict = load_checkpoint(cfg.checkpoint_path)
|
||||
load_param_into_net(net, param_dict)
|
||||
lr = lr_steps(0, lr_max=cfg.lr_init, total_epochs=cfg.epoch_size, steps_per_epoch=batch_num)
|
||||
opt = Momentum(filter(lambda x: x.requires_grad, net.get_parameters()), Tensor(lr), cfg.momentum,
|
||||
weight_decay=cfg.weight_decay)
|
||||
Loading…
Reference in New Issue